Acelera tu modelado de datos con los modelos de datos de la industria de Databricks
Modelos de datos preconstruidos, validados por reglas y listos para la capa Silver para los 40 sectores más grandes del mundo, listos para ser desplegados y gobernados en la plataforma de Databricks.
por Amr Ali, Drew Triplett, Franco Patano y Shelley Shaffery
- Más de 40 modelos de datos sectoriales listos hoy mismo. Modelos preconstruidos y validados por reglas para la capa Silver en 40 sectores, en dos alcances (MVM y ECM): despliégalos tal cual o personalízalos.
- Un conjunto completo y gobernado de artefactos. Se entrega como un único model.json (más SQL DDL, DBML y ontología) que se despliega en Unity Catalog con tablas Delta, claves foráneas, etiquetas de clasificación y vistas de métricas.
- Despliega en horas. Apunta model.json a un Unity Catalog, elige un estilo de catalogación y obtén una capa Silver clasificada y validada por FK.
El problema del modelo de datos de la industria
Durante tres décadas, a los sectores regulados y con gran volumen de datos se les ha vendido el mismo atajo: comprar un modelo de datos de la industria. ACORD para seguros. FHIR y HL7 para el sector salud. ARTS para el comercio minorista. Cientos, a veces miles, de tablas publicadas por un organismo de normalización o un proveedor, presentadas como un año de trabajo en una sola licencia.
La propuesta es atractiva. La realidad es más dolorosa. Un modelo de datos de la industria es el promedio de todas las empresas de un sector. No conoce sus líneas de productos, sus geografías, su huella regulatoria, sus limitaciones de sistemas heredados, sus costumbres de nomenclatura ni su estructura organizativa; no sabe qué diferencia a su negocio. Los equipos heredan cientos de tablas que nunca completarán, convenciones de nomenclatura que no coinciden con su terminología y direcciones de relación que sus cargas de trabajo no necesitan. La mayor parte del valor de comprar una plantilla se gasta en recortarla, renombrarla y reorganizarla, que es exactamente el trabajo que la plantilla debía ahorrar.
Un modelo de datos analítico sólido, del tipo que realmente ejecuta análisis de producción y ML, históricamente ha tardado de meses a años en construirse.
Estamos publicando algo diferente. Una biblioteca de modelos de datos de la industria para Lakehouse prediseñados, disponibles hoy en un repositorio público, listos para implementarse como la capa Silver de su Databricks para las 40 industrias más grandes del mundo. Cada modelo de datos de la industria se entrega en dos alcances y se basa en un conjunto estricto de reglas estructurales que abarca más de 200 reglas en 14 dominios de modelado diferentes que hacen que el resultado sea apto para producción desde el primer día, y la buena noticia es que no son modelos de datos rígidos o fijos, tiene los medios para evolucionarlos y personalizarlos para que se adapten a su organización según sea necesario.
Dónde se ubican estos modelos de datos en el Lakehouse
En una arquitectura de medallón de Databricks, Bronze contiene datos brutos, Silver contiene el modelo base analítico adaptado del que leen todos los analistas, herramientas de BI y científicos de datos, y Gold contiene métricas derivadas, KPIs y agregados.
Estos modelos de datos base son la capa Silver. Lakeflow y Auto Loader se encargan de la ingesta. Cada modelo se entrega con métricas precalculadas como churn_score o monthly_revenue_summary. El modelo base es la base analítica: el lugar donde los conceptos del negocio se convierten en tablas confiables, listas para herramientas de BI, canalizaciones de características y agregados descendentes.
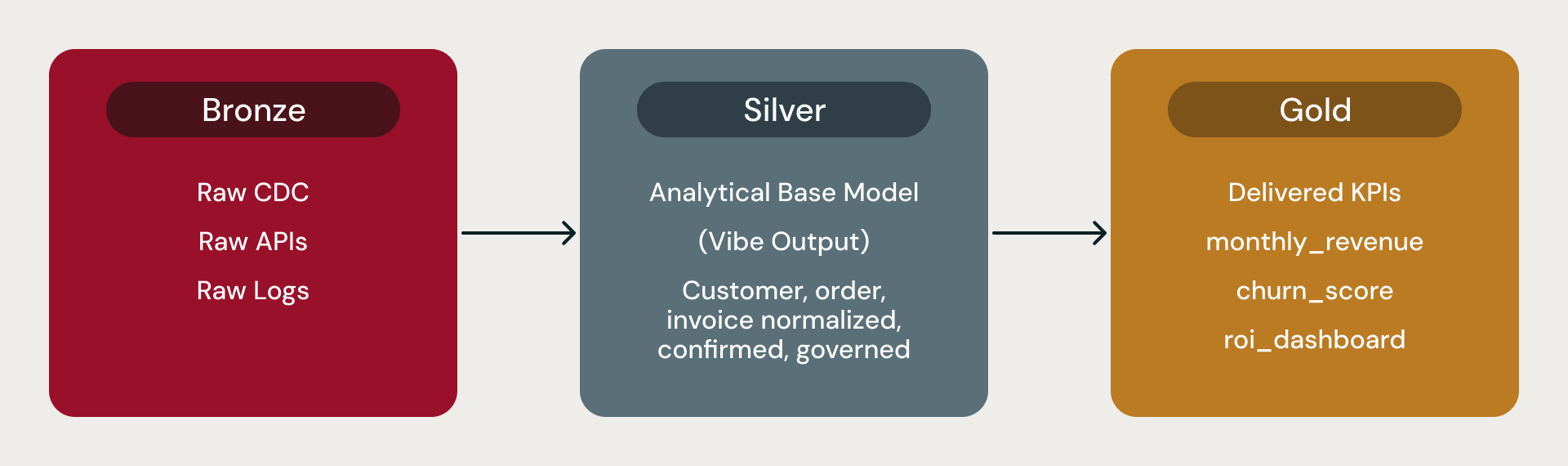
Bronze, Silver, Gold
Dos alcances: MVM y ECM
Cada modelo base se publica en dos alcances. Ambos se implementan desde el mismo archivo lógico model.json; ambos siguen las mismas reglas; ambos tienen la misma profundidad de atributos por tabla. La diferencia es la amplitud.
Modelo Mínimo Viable (MVM). Del treinta al cincuenta por ciento del recuento de tablas de ECM. Solo funciones comerciales esenciales. Ideal para SMBs, implementaciones rápidas, pruebas de concepto y MVPs. Un MVM no es un esqueleto ni un juguete de demostración: cada tabla tiene la misma riqueza de atributos que su contraparte de ECM. La ligereza proviene de tener menos dominios y menos tablas, nunca de tablas más delgadas.
Modelo de Cobertura Ampliada (ECM). Cobertura completa. Todas las divisiones, incluido el back office corporativo. Todos los dominios que esperaría un modelo de Fortune 100. Amplitud máxima.
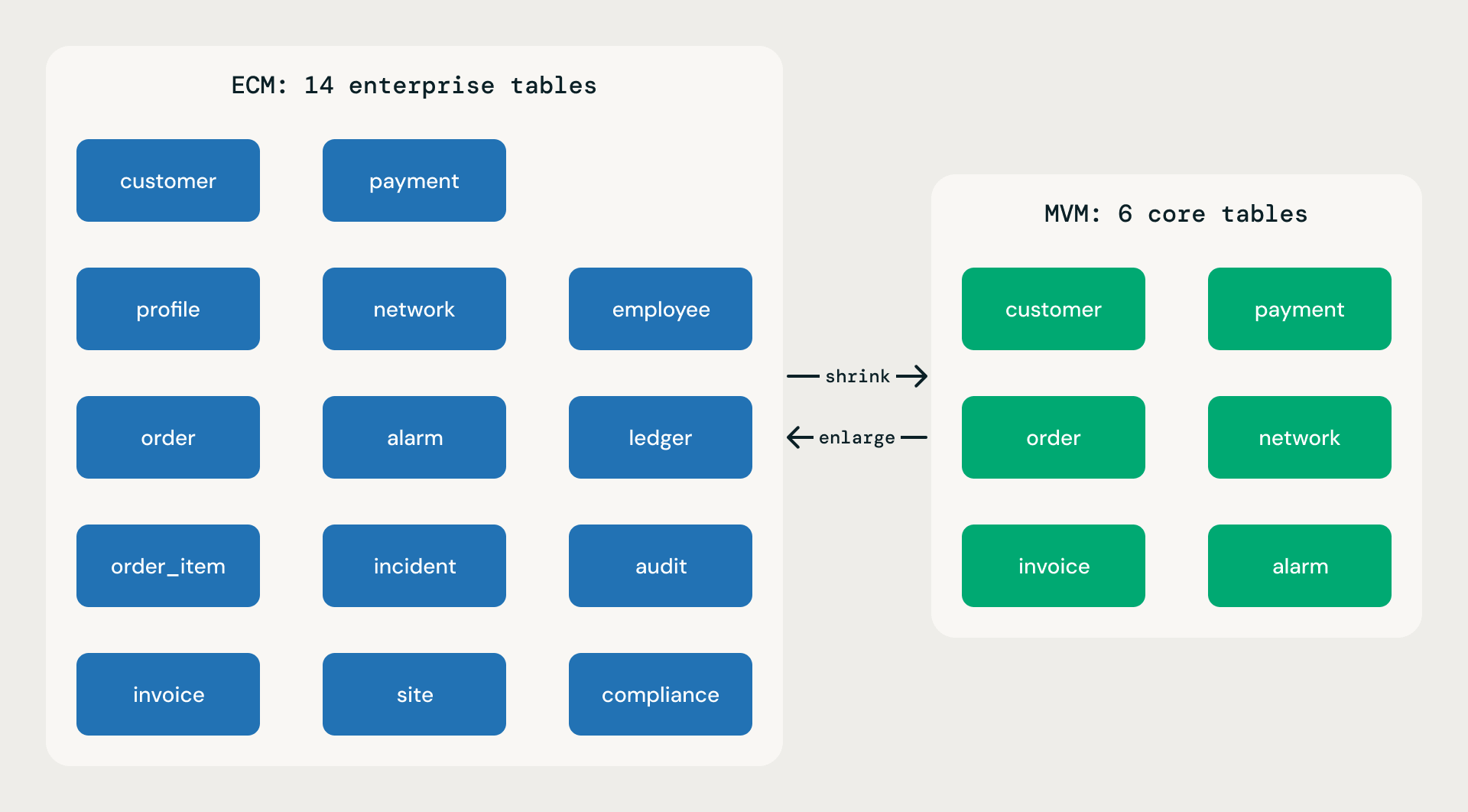
Alcance de MVM frente a ECM
¿Por qué son importantes ambos alcances? El objetivo no es que las organizaciones pasen tiempo adaptando el modelo a sus datos de negocio, sino comenzar rápidamente con la analítica en el Lakehouse, por lo que empezar con el alcance adecuado ya es un ahorro de tiempo.
Los dos alcances no son líneas de mantenimiento separadas. Cualquiera de los dos puede derivarse del otro mediante una única transformación: shrink ecm produce un subconjunto de MVM que protege los productos principales y mantiene las claves externas esenciales; enlarge mvm hace lo contrario. Ninguna versión se sobrescribe jamás: ambas operaciones crean una nueva versión numerada junto a la original.
Qué hace que estos modelos sean diferentes
Los modelos base que estamos publicando no son plantillas de la industria estándar de comités con otro nombre. Son producidos por un agente de AI disciplinado y guiado por reglas que impone la calidad estructural en cada paso del modelado. Algunos aspectos destacados:
Dimensionamiento por niveles de la industria. Cada modelo está dimensionado para la complejidad real de su sector. El clasificador utiliza siete dimensiones (densidad regulatoria, complejidad de las partes, profundidad de la jerarquía de productos, gestión de infraestructura, modelo canónico de la industria, complejidad de las transacciones y panorama del sistema operativo) para ubicar a cada industria en uno de los cinco niveles, lo que luego determina la cantidad de dominios, productos por dominio y profundidad de atributos.
| Nivel | Etiqueta | Características principales | Dominios de MVM | Productos/Dominio de ECM |
|---|---|---|---|---|
| tier_1 | Ultracomplejo | Banca, seguros, grandes farmacéuticas | 15–22 | 14–28 |
| tier_2 | Complejo | Telecomunicaciones, energía, salud | 12–18 | 14–26 |
| tier_3 | Moderado | Manufactura, comercio minorista | 10–15 | 12–24 |
| tier_4 | Estándar | Logística, agricultura | 8–12 | 10–20 |
| tier_5 | Simple | Consultoría, SaaS, medios de comunicación | 5–8 | 8–18 |
Jerga específica de la industria. Cada modelo utiliza la terminología que realmente se habla en su sector. Las telecomunicaciones tienen msisdn, arpu, imsi, cdr. La minería tiene rom, cut_off_grade, jorc. El sector salud tiene icd, cpt, drg. La banca tiene iban. Estos no son detalles secundarios: dan forma a los nombres de las columnas, las convenciones de claves primarias y la estructura de las etiquetas de gobernanza.
El andamiaje de tres divisiones. Cada modelo se organiza en tres anillos concéntricos:
- Operaciones es lo que hace físicamente la empresa: red, flota, planta, infraestructura.
- Negocios es a quién sirve y cómo genera ingresos: cliente, facturación, producto, ventas.
- Corporativo es el andamiaje de soporte: HR, finanzas, cumplimiento.
La proporción se impone mediante reglas (rule G06-R001): Operaciones más Negocios deben representar al menos el 80% de todos los dominios; Corporativo está limitado al 20%. Esto evita el modo de falla más común del modelado sin restricciones: modelos que son mitad HR, finanzas y legal, y deficientes en el núcleo operativo que realmente hace funcionar al negocio.
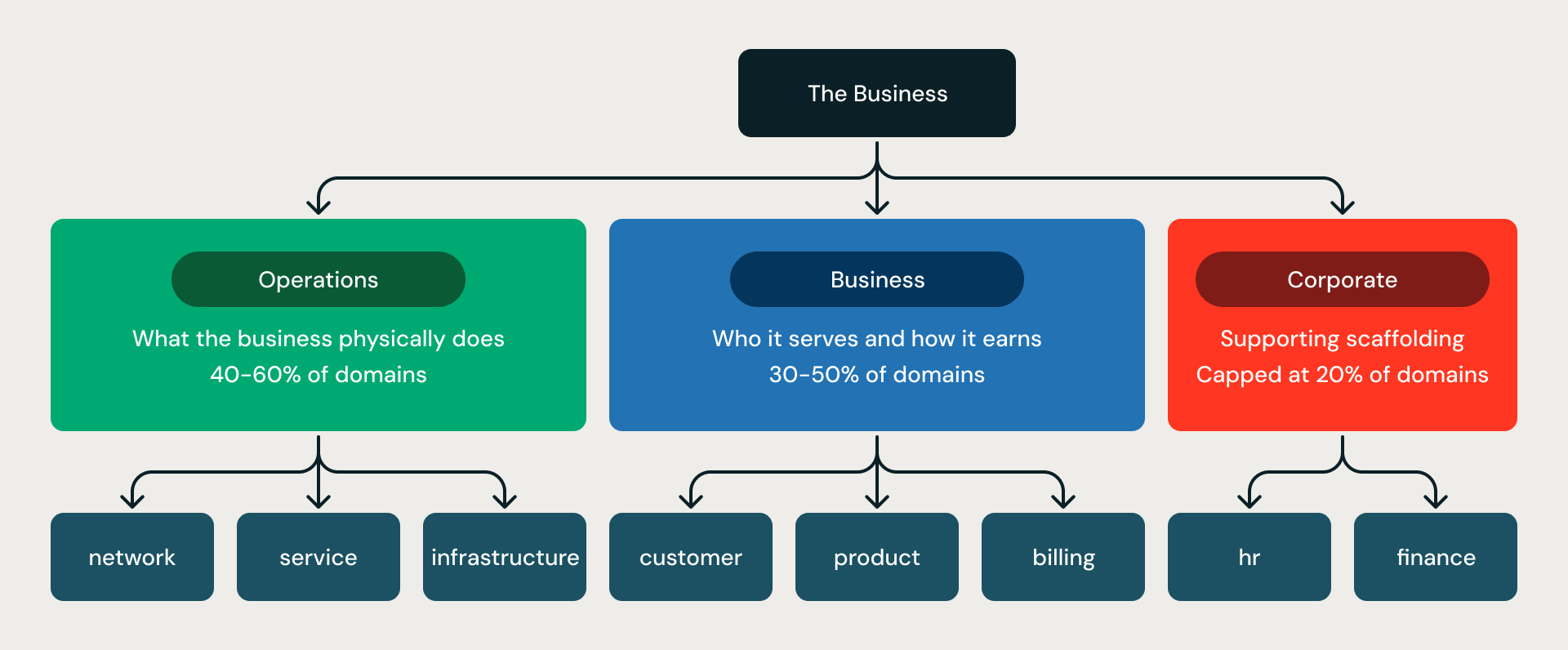
Las tres divisiones
La jerarquía de seis niveles. Cada modelo sigue la misma estructura estricta: Organización → División → Dominio → Subdominio → Producto → Atributo. La jerarquía no es una sugerencia; se impone mediante reglas estructurales, dos niveles de revisión de arquitectos y análisis estático al final de cada canalización.
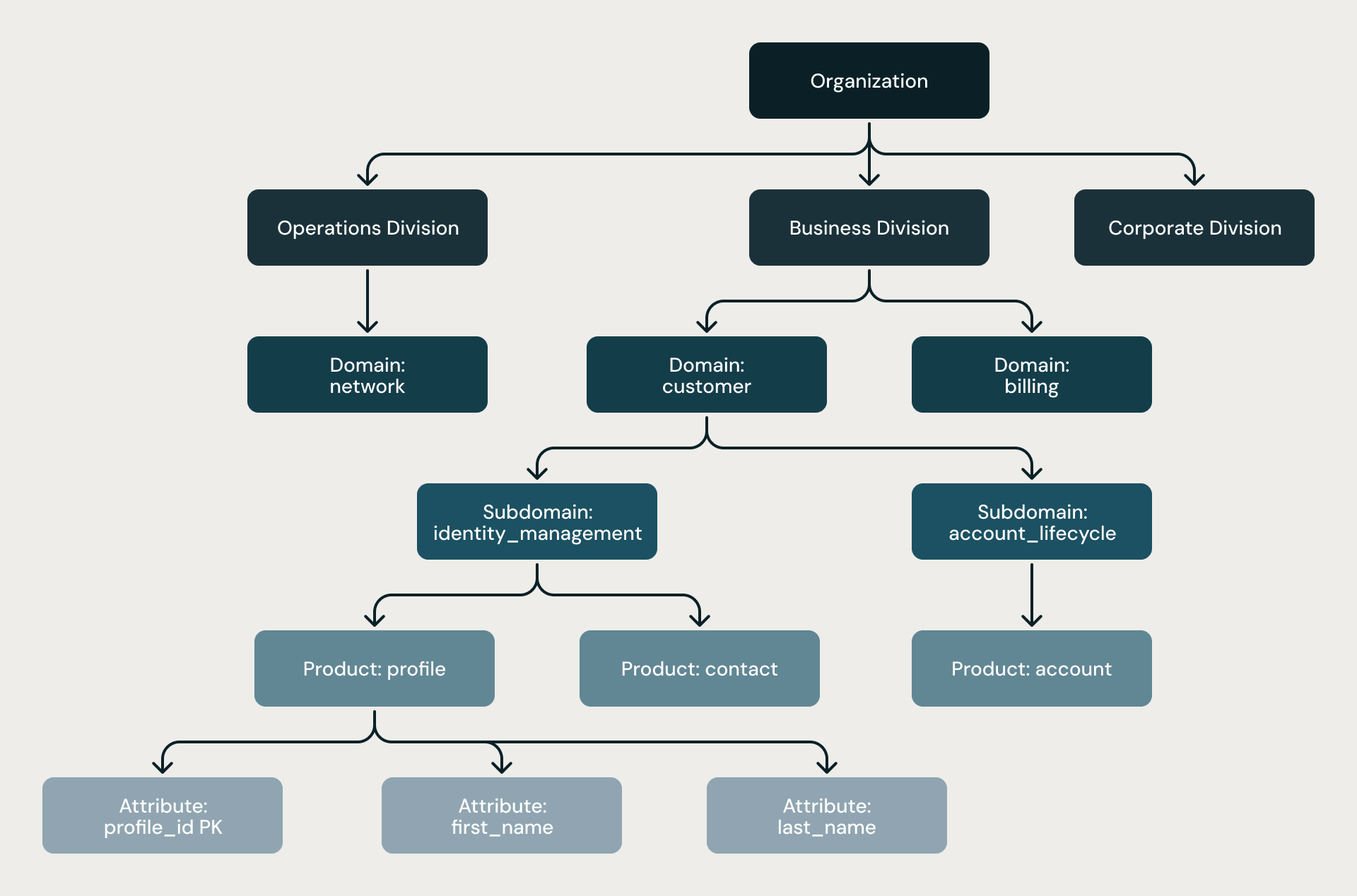
Jerarquía de cuatro niveles
Más de 200 reglas aplicables. Cada modelo base se valida con más de 200 reglas organizadas en más de 14 grupos: convenciones de nomenclatura, deduplicación semántica, claves externas, claves primarias, normalización, estructura de dominio, tipos de datos, etiquetas de clasificación, aplicación de relaciones/DAG, calidad, diseño de productos, restricciones de estilo, implementación de esquemas físicos y dimensionamiento de subdominios. Cada tabla debe tener una clave primaria. Cada clave externa apunta a un destino real. Cada dominio supera la prueba del organigrama: “¿Podría existir en la organización un departamento o equipo real con este nombre?”. Sin ciclos. Sin silos y con una estricta adherencia a la fuente única de verdad (SSOT).
Un modelo lógico, tres diseños físicos. Cada modelo base se entrega como un único archivo model.json que es independiente del entorno. El mismo modelo lógico se implementa limpiamente en Unity Catalog en tres estilos de catalogación: un catálogo (límite de gobernanza único), catálogo por división (Operaciones / Negocios / Corporativo aislados) o catálogo por dominio (compatible con data-mesh). Vuelva a implementarlo en un estilo diferente y no se tocará nada del modelo lógico.
Un ejemplo práctico: El modelo ECM de aerolínea v1
Para que esto sea concreto, aquí está el ECM de aerolínea que se entrega hoy en el repositorio.
| Métrica | Valor |
|---|---|
| Alcance del modelo | ECM v1 |
| Total de dominios | 19 |
| Total de subdominios | 60 |
| Total de productos | 420 |
| Total de atributos | 17,278 |
| Claves primarias | 420 |
| Claves externas | 2,877 |
| Promedio de atributos/producto | 41.1 |
| Metric Views | 203 |
Visualizado como un gráfico, el DAG completo se ve así (cada rectángulo es un dominio, cada círculo pequeño es una tabla y cada línea es un enlace FK):

Airline ECM v1 como un DAG conectado
Los diecinueve dominios se dividen claramente en las tres divisiones. Operaciones incluye aeropuerto, tripulación, flota, vuelo, inventario, mantenimiento y ruta. Negocios incluye servicios auxiliares, carga, fidelización, pasajeros, reservas, ingresos, servicio y boletos. Corporativo incluye cumplimiento, finanzas, seguridad y fuerza laboral.

Dominios de aerolíneas por división
Al profundizar en un solo dominio (operaciones de vuelo), la estructura se vuelve legible a nivel operativo. Los subdominios para carga de recursos, operaciones de vuelo y servicios de pasajeros contienen los productos que un analista de operaciones realmente utiliza: leg, flight_plan, oooi_event, atc_clearance, dispatch_release, notam_brief, tech_log, weight_balance, fuel_uplift, pax_segment. (cada círculo es una tabla, cada línea es una relación FK)

Dominio de vuelo
Profundice aún más en un solo producto de datos, la carta de porte aéreo (awb) dentro del dominio de carga, y podrá ver exactamente cómo funcionan los enlaces entre dominios. awb se conecta a corporate_account en el dominio de pasajeros, station en aeropuerto, leg en vuelo, profit_center, ledger_account y company_code en finanzas, y screening_result en cumplimiento. Estas son las uniones (joins) que un analista de ingresos de carga ejecuta todos los días, y están presentes porque el DAG entre dominios se creó para admitirlas.

Producto de datos Air Waybill
Qué obtiene al implementar
Cada modelo base se entrega con un conjunto completo de artefactos.
Artefactos lógicos. Un único model.json (el formato de intercambio principal), un archivo readme.md legible por humanos, exportaciones planas de dominios, productos y atributos, exportaciones de Excel y CSV, archivos SQL DDL (uno por dominio más un archivo FK entre dominios), un diagrama de esquema DBML y una ontología RDF/Turtle.
Artefactos físicos al implementar en Unity Catalog. Esquemas de Unity Catalog (uno por dominio o por subdominio, según el estilo de catalogación), tablas Delta para cada producto, restricciones de clave externa aplicadas en orden de dependencia, etiquetas de clasificación de Unity Catalog (PII, restringido, público), vistas de métricas de Databricks para definiciones de KPI reutilizables y datos de muestra sintéticos con referencias FK válidas para una exploración inmediata.
El archivo model.json es la moneda de cambio. Guárdelo en git. Compare dos versiones. Compártalo entre entornos. Entréguelo a un revisor de seguridad sin otorgar acceso a producción. Vuelva a implementarlo en dev, staging y prod bajo tres estilos de catalogación diferentes y obtenga tres entornos cuyo contenido lógico sea idéntico byte por byte.
Dónde destaca este enfoque
- Velocidad. Las bases de la capa Silver que solían tomar meses ahora son solo un paso de implementación.
- Especificidad. Los modelos utilizan el lenguaje del sector: su jerga, su estructura regulatoria y su realidad operativa.
- Cobertura de reglas. Más de 200 reglas aplicables significan una consistencia que la mayoría de los modelos escritos a mano nunca alcanzan.
- Gobernanza. Cada columna con datos sensibles está clasificada y etiquetada. Cada PK/FK sigue una única convención. Cada estilo de catalogación es reproducible.
- Formato dual. El mismo artefacto es un esquema relacional, un diagrama DBML, una ontología de grafo de conocimiento y una implementación física de Unity Catalog.
- Separación lógico-física. Un único model.json, tres estilos de catalogación. Vuelva a implementar con cero retrabajo.
Aspectos a considerar
Los modelos base son un punto de partida, no un producto final. La experiencia en el dominio sigue siendo importante: la revisión de expertos siempre mejorará un modelo de formas que solo un profesional que trabaje dentro de esa empresa puede ver. Las subverticales muy estrechas son menos adaptadas de forma predeterminada que las industrias principales. Y las organizaciones con comités estrictos de aprobación de modelos de datos aún necesitan someter el resultado a revisión; lo que cambia es la velocidad del artefacto, no el requisito de gobernarlo.
Creemos que el equilibrio es el adecuado. Un modelo base que se implementa en horas y es estructuralmente sólido es un mejor punto de partida que una plantilla que tarda un año en adaptarse.
Pruébelo hoy mismo
El repositorio de los 40 modelos de datos de la industria para Lakehouse se encuentra en https://github.com/databricks-industry-solutions/databricks-industry-data-models Cada industria se entrega con un MVM y un ECM. Elija el alcance que se adapte a su organización, apúntelo a un Unity Catalog y tendrá una capa Silver implementada, clasificada y con validación FK lista para el análisis.
Próximamente
Un modelo base es un punto de partida; por eso todos los modelos están en la versión v1, y esa no es la forma final. Cada organización tiene una terminología, divisiones y procesos de negocio que incluso el mejor modelo genérico no reflejará con total exactitud. En una publicación posterior, explicaremos cómo personalizar y hacer evolucionar los modelos v1 utilizando un agente de modelado de IA de lenguaje natural: describiendo los cambios que desea en un lenguaje sencillo y produciendo una versión adaptada (v2, v3, etc.), al tiempo que se preserva el rigor estructural del original.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.