Del Lakehouse a la mente digital: Arquitectura de un ecosistema de IA multiagente en Databricks Agent Bricks
Descubre cómo Edmunds transformó su data lakehouse en una plataforma de IA multiagente inteligente con Agent Bricks para la activación, la automatización y la innovación continua.
por Gregory Rokita
- Edmunds creó un ecosistema multiagente nativo de IA en Databricks Agent Bricks, pasando del almacenamiento de datos pasivo a una automatización inteligente en tiempo real en todas las funciones de compra de automóviles.
- Agentes especializados como DataDave logran un 95 % de precisión en análisis complejos, mientras que las ofertas de marketing mejoran las tasas de conversión gracias a la información del lakehouse unificado.
- La arquitectura permite una automatización escalable, la colaboración entre agentes y experiencias proactivas y personalizadas tanto para los equipos internos como para los compradores de automóviles.
En las empresas actuales, contar con un data lakehouse amplio y unificado es fundamental para activar los datos. Con un lakehouse, las organizaciones pueden transformar un repositorio pasivo en un motor dinámico e inteligente que anticipa necesidades, automatiza el conocimiento especializado y fomenta la toma de decisiones más informadas. En Edmunds, esta prioridad llevó al lanzamiento de Edmunds Mind, nuestra iniciativa para crear un sofisticado ecosistema de AI multiagente directamente en Databricks Data Intelligence Platform.
Esta evolución arquitectónica está impulsada por un momento crucial en la industria automotriz. Tres tendencias clave han convergido:
- El auge de los modelos de lenguaje grande (LLM) como potentes motores de razonamiento
- La escalabilidad y el gobierno de plataformas como Databricks como una base segura
- La aparición de marcos de trabajo de agentes robustos para orquestar la automatización. Estos factores hacen posibles sistemas que habrían parecido inimaginables hace solo unos años
Esta transformación no se trata solo de agregar otra herramienta de AI, sino también de rediseñar fundamentalmente nuestra organización para operar de manera nativa en AI. Los principios, componentes y estrategias detrás de este núcleo inteligente se detallan en nuestro diseño arquitectónico a continuación.
“Databricks nos brinda una base segura y gobernada para ejecutar múltiples modelos como GPT-4o, Claude y Llama, y cambiar de proveedor a medida que evolucionan nuestras necesidades, todo mientras mantenemos los costos bajo control. Esa flexibilidad nos permite automatizar la moderación de reseñas y mejorar la calidad del contenido más rápido, para que los compradores de autos obtengan información confiable antes”.—Gregory Rokita, VP de Tecnología, Edmunds
Transformación de una empresa rica en datos a una impulsada por información
Nuestra visión es evolucionar de una empresa rica en datos a una organización impulsada por información. Aprovechamos la AI para crear la experiencia de compra de autos más confiable, personalizada y predictiva de la industria.
Esto se logra a través de cuatro pilares estratégicos clave:
- Activar datos a escala: Transición de paneles estáticos a una interacción dinámica y conversacional con los datos.
- Automatizar la experiencia: Codificar la invaluable lógica de nuestros expertos de dominio en agentes autónomos y reutilizables.
- Acelerar la innovación de productos: Proporcionar a nuestros equipos un conjunto de herramientas de agentes inteligentes para crear funciones de próxima generación.
- Optimizar las operaciones internas: Impulsar mejoras significativas de eficiencia mediante la automatización de flujos de trabajo internos complejos.
En el corazón de esta visión se encuentra nuestra ventaja competitiva más importante: el Edmunds Data Moat. Esta sólida base de datos automotrices está liderada por nuestro inventario de vehículos usados líder en la industria, el conjunto más completo de reseñas de expertos y la mejor inteligencia de precios de su clase, complementado por amplias reseñas de consumidores y listados de vehículos nuevos. Todo este ecosistema está unificado y se gestiona dentro de nuestro entorno de Databricks, lo que crea un activo único y potente. Edmunds Mind es el motor que hemos creado para liberar todo su potencial.
Dentro del marco de trabajo de agentes digitales
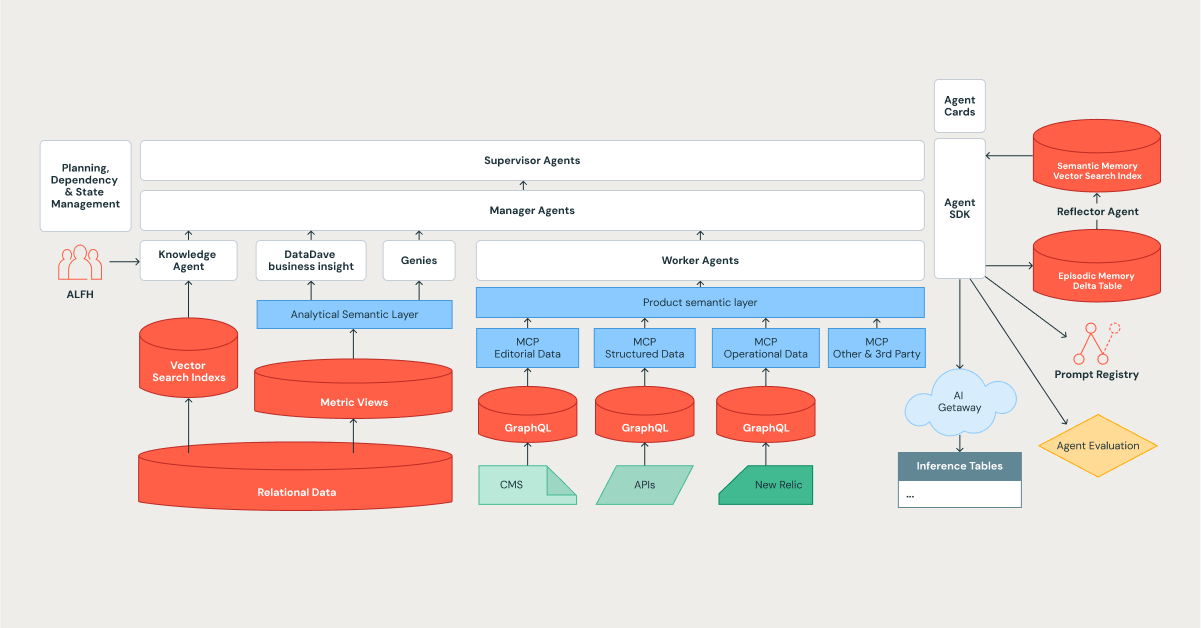
La arquitectura de Edmunds Mind es un sistema cognitivo y jerárquico diseñado para la complejidad, el aprendizaje y la escala, con la plataforma de Databricks como su base.
La jerarquía de agentes: una organización de especialistas digitales
Diseñamos nuestro sistema para reflejar una organización eficiente, utilizando una estructura escalonada donde las tareas se descomponen y se delegan. Esto se alinea perfectamente con los patrones de orquestador en los marcos de trabajo modernos, como Databricks Agent Bricks.
- Agentes supervisores: Los líderes estratégicos. Realizan la planificación a largo plazo, gestionan las dependencias y orquestan tareas complejas de múltiples etapas.
- Agentes gerentes: Los líderes de equipo. Coordinan un equipo de agentes especializados para lograr un objetivo específico y bien definido.
- Agentes trabajadores y especializados: Estos son los colaboradores individuales que aportan experiencia especializada. Son el motor del sistema e incluyen una lista creciente de especialistas, como Knowledge Assistant, DataDave y varios Genies.
La comunicación entre agentes se rige por un protocolo estandarizado, lo que garantiza que las delegaciones de tareas y las transferencias de datos estén estructuradas, tipificadas y sean auditables, lo cual es fundamental para mantener la confiabilidad a escala.
La jerarquía también está diseñada para una tolerancia a fallos fluida. Cuando un agente gerente determina que su equipo de especialistas no puede resolver una tarea, escala todo el contexto de la tarea de vuelta al supervisor, incluidos los intentos fallidos almacenados en su memoria episódica. Luego, el supervisor puede volver a planificar con una estrategia diferente o, lo que es más importante, marcar esto como un problema nuevo que requiere intervención humana para desarrollar una nueva capacidad. Esto hace que el sistema sea robusto y una herramienta de aprendizaje que nos ayuda a identificar los límites de su competencia.
Análisis profundo 1: Flujo de trabajo automatizado de enriquecimiento de datos
Históricamente, resolver las imprecisiones en los datos de los vehículos, como colores incorrectos en una página de detalles del vehículo, era un proceso laborioso que requería coordinación manual entre múltiples equipos. Hoy en día, el ecosistema de AI de Edmunds Mind automatiza y resuelve estos desafíos casi en tiempo real. Esta eficiencia operativa se logra a través de nuestro Model Serving centralizado, que consolida nuestras diversas capacidades de agentes de AI en un único entorno cohesivo que se escala automáticamente según la demanda. Esta arquitectura libera a nuestros equipos de la sobrecarga operativa, lo que les permite concentrarse en ofrecer valor a nuestros usuarios rápidamente.
El proceso de resolución se ejecuta a través de un flujo de trabajo multiagente gobernado. Cuando un usuario o un monitor automatizado detecta una posible discrepancia de datos, un agente supervisor clasifica inmediatamente el evento. Evalúa el problema, lo dirige al equipo especializado adecuado y valida los permisos de la tarea a través de Unity Catalog para un gobierno de datos sólido. Luego, un agente gerente dedicado orquesta una secuencia de agentes trabajadores especializados para realizar tareas que van desde la decodificación de VIN y la recuperación de imágenes hasta el análisis de color impulsado por AI y las actualizaciones finales de la base de datos. Los administradores de datos humanos siguen siendo fundamentales para la revisión crítica, cambiando su enfoque de la intervención manual a la etapa de aprobación de alto valor. Cada interacción y decisión se registra sistemáticamente, construyendo una base integral para el aprendizaje continuo y la optimización futura de los procesos.
Este ejemplo ilustra cómo todo el ecosistema maneja una tarea de enriquecimiento y calidad de datos del mundo real de extremo a extremo.
- Activador del evento: Una queja de un usuario o un monitor automatizado detecta un posible problema de calidad de los datos (por ejemplo, un color de vehículo incorrecto) en una página de descripción del vehículo.
- Clasificación y orquestación: Un agente supervisor recibe el evento, crea una tarea de la que se puede hacer un seguimiento y evalúa su prioridad según reglas comerciales predefinidas.
- Delegación al gerente: El supervisor delega la tarea al agente gerente de datos de vehículos después de confirmar sus permisos para acceder y modificar los datos de los vehículos en Unity Catalog.
- Ejecución coordinada de tareas: El agente gerente orquesta una secuencia de agentes trabajadores especializados para resolver el problema: un agente de decodificación de VIN, un agente de recuperación de imágenes para extraer fotos de nuestra biblioteca de medios, un agente de análisis de color impulsado por AI para determinar el color correcto a partir de las imágenes y un agente de corrección de datos para actualizar la base de datos de fabricación de vehículos.
- Revisión con intervención humana (Human-in-the-Loop): Antes de que el cambio se publique, el agente gerente marca el cambio automatizado y notifica a un administrador de datos humano a través de una integración de Slack para su validación final.
- Aprendizaje y cierre: Una vez que el administrador aprueba la tarea, el supervisor la marca como completada. Toda la interacción, incluida la aprobación humana final, se rastrea y se registra en la memoria a largo plazo para futuros aprendizajes y auditorías.
Análisis profundo 2: Knowledge Assistant: respuestas en tiempo real, voz de marca confiable
Donde antes los clientes navegaban por múltiples paneles de Edmunds o se comunicaban con el soporte de Edmunds para obtener respuestas, ahora el Knowledge Assistant ofrece respuestas conversacionales e instantáneas al aprovechar todo el espectro de datos de Edmunds. Este agente RAG está adaptado a la voz de la marca Edmunds, entrelazando información de reseñas de expertos y consumidores, especificaciones de vehículos, medios y precios en tiempo real. Como resultado, los clientes experimentan interacciones más rápidas y satisfactorias, y el personal de soporte dedica menos tiempo a responder solicitudes básicas.
Las capacidades clave incluyen:
- Personificación de la voz de la marca: El agente está meticulosamente ajustado para comunicarse con la voz viva, servicial y confiable que los clientes de Edmunds conocen desde hace décadas.
- Síntesis de datos en tiempo real: En una sola consulta, el asistente puede recuperar, sintetizar y presentar información de nuestras diversas fuentes de datos en tiempo real, incluyendo reseñas de expertos y consumidores, especificaciones de vehículos, contenido de video transcrito y los últimos precios e incentivos.
- Capacidades avanzadas de RAG: Estamos trabajando activamente con Databricks utilizando AI Search para expandir los límites de nuestra implementación de RAG. Nos enfocamos en mejorar la priorización de la frescura del contenido y el filtrado sofisticado de metadatos para garantizar que la información más relevante y oportuna siempre aparezca primero.
Análisis profundo 3: El flujo de trabajo "generar y criticar" de DataDave
DataDave ahora resuelve análisis complejos que antes dependían de un trabajo manual que requería mucho tiempo. Este agente coordina un flujo de trabajo riguroso, en el que cada etapa es evaluada por un agente especialista, para ofrecer un 95% de precisión en las consultas más difíciles. DataDave puede identificar oportunidades de manera proactiva (como señalar concesionarios desatendidos para el equipo de ventas de Edmunds) al sintetizar el tráfico del sitio web y los datos demográficos. Esto permite al equipo de liderazgo de Edmunds pasar con confianza de reportar “qué pasó” a decidir “qué deberíamos hacer ahora”.
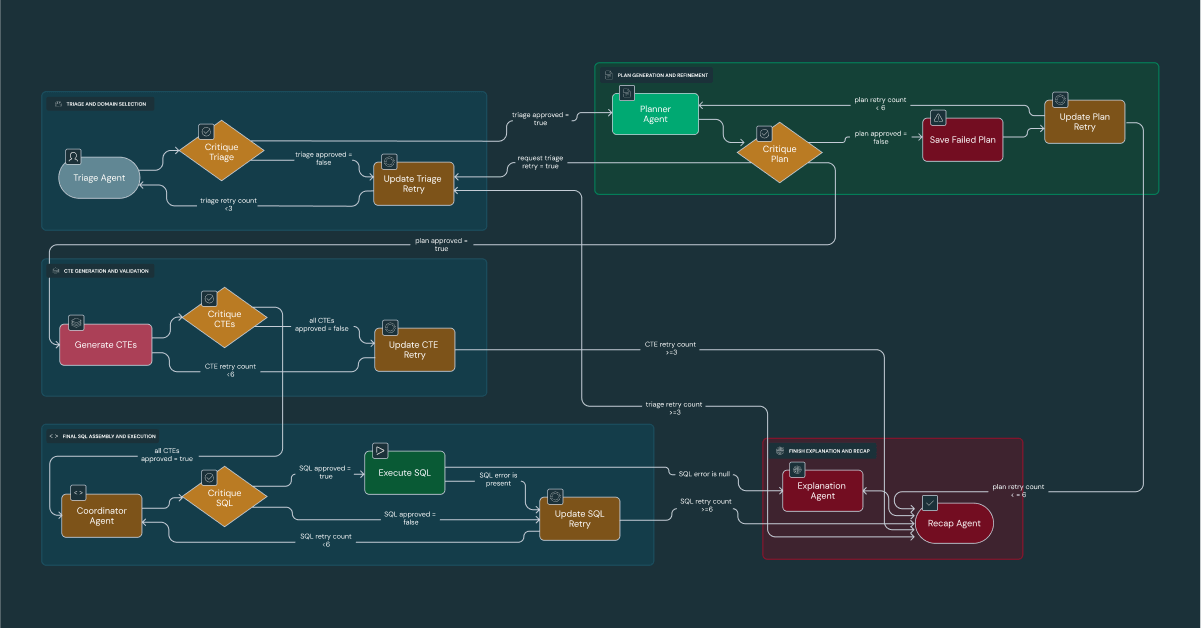
El flujo de trabajo interno es un proceso de cinco fases: triaje, planificación, generación de código, ejecución y síntesis, con un agente de crítica dedicado que valida el resultado de cada fase. Más allá de simplemente analizar las métricas internas, el verdadero poder de DataDave radica en su capacidad para sintetizar nuestros datos patentados con el conocimiento general del mundo para generar recomendaciones estratégicas. Por ejemplo, al correlacionar los datos de tráfico del sitio web de Edmunds con datos geográficos y demográficos, DataDave puede identificar concesionarios en áreas desatendidas y recomendarlos proactivamente a nuestro equipo de ventas como oportunidades fáciles de aprovechar.
Análisis profundo 4: Especialización en precios
En Edmunds, operamos bajo un principio fundamental: un precio no es solo un número; es una conclusión que requiere contexto y justificación para ser confiable. Aprovechando nuestra reputación de ofrecer los precios más precisos en el mercado de EE. UU., nuestra arquitectura de agentes está diseñada para brindar esta confianza a escala.
Nuestra experiencia al transformar un "Pricing Expert" monolítico en un equipo coordinado de especialistas demuestra este principio. Este equipo —coordinado por un Manager Agent e integrado por expertos como un True Market Value Agent, un Depreciation Agent y un Deal Rating Agent— produce más que un simple precio de lista. El resultado final es una historia de precios completa y contextualizada que explica por qué un vehículo se valora de cierta manera.
Esto transforma el rol de nuestros analistas de precios, pasando de la recopilación manual de datos a la supervisión y guía estratégica. Al aprovechar Agent Bricks de Databricks, nuestros estadísticos de precios pueden configurar estos equipos de agentes jerárquicos con un código mínimo, lo que aumenta drásticamente su productividad y reduce los costos de mantenimiento. Esto les permite concentrarse en lo que realmente importa: el "porqué" detrás de los números.
El núcleo cognitivo: una arquitectura para la inteligencia compuesta
Nuestro camino hacia un ecosistema de AI verdaderamente inteligente comenzó con un desafío práctico. Al implementar agentes especializados como DataDave para el análisis de negocios, descubrimos que estaban revelando verdades comerciales críticas y urgentes que permanecían aisladas dentro de su contexto operativo. Por ejemplo, un agente podría detectar una tendencia a la baja inusual en un canal de marketing clave, pero esta información vital debe comunicarse de manera efectiva a otras entidades, tanto agentes como humanos, para activar una respuesta coordinada. Esto resaltó una necesidad fundamental: un sistema de memoria compartida que pudiera capturar estos aprendizajes emergentes y hacerlos accesibles como entrada para todo el sistema de agentes. Imaginamos una capa cognitiva donde este conocimiento pudiera acumularse, crecer y aprovecharse para hacer que todo nuestro ecosistema fuera progresivamente más inteligente. En consecuencia, nuestro pensamiento y diseño más recientes son los siguientes.
- Memoria episódica ("Qué pasó"): Un registro de alta fidelidad de cada acción y observación del agente, que sirve como la verdad de referencia del sistema.
- Memoria semántica ("Qué se aprendió"): Un índice de vectores que contiene información generalizada y estrategias exitosas sintetizadas a partir de eventos episódicos. Esta será la biblioteca de conocimiento práctico.
- Consolidación automática de memoria: Un agente "Reflector" en segundo plano revisa periódicamente la memoria episódica para identificar y consolidar los aprendizajes clave en la memoria semántica.
- Acceso jerárquico a la memoria: Los agentes de mayor nivel pueden acceder a las memorias de sus subordinados, lo que permite a un Manager Agent analizar el rendimiento del equipo y optimizar las estrategias futuras. Este bucle de retroalimentación es fundamental para la antifragilidad de nuestro sistema; cada fallo nuevo escalado por la jerarquía no es solo un problema a resolver, sino una señal que entrena a todo el ecosistema, haciéndolo progresivamente más inteligente y resiliente.
Implementación: mem0 + Databricks
Nuestra implementación estará impulsada por Databricks AI Search utilizando un Delta Sync Index, que es totalmente compatible con la interfaz mem0. Dado que mem0 interactúa con bases de datos vectoriales, innovaremos al almacenar tanto la memoria episódica como la semántica dentro de un único y potente backend. Los eventos sin procesar y no resumidos ("qué pasó") y los aprendizajes sintetizados ("qué se aprendió") coexistirán como tipos de vectores distintos dentro de la misma tabla Delta de origen, que luego alimenta de forma automática y sin problemas el índice de AI Search.
Esta arquitectura unificada crea un flujo de trabajo eficiente. El agente Reflector puede consultar el índice para buscar entradas episódicas recientes, realizar su síntesis y escribir los nuevos vectores semánticos generalizados de vuelta en la tabla Delta de origen. Luego, el Delta Sync Index ingiere automáticamente estos nuevos aprendizajes, poniéndolos a disposición para consultas. Al aprovechar la tabla Delta de origen como el único punto de entrada, eliminamos la complejidad de las canalizaciones de datos y obtenemos la base escalable, serverless y de baja latencia necesaria para un sistema de agentes verdaderamente inteligente.
Ejemplo de flujo de trabajo con Edmunds Pulse
- Registro: El agente 'DataDave' detecta una anomalía en las ventas y registra el evento en su memoria episódica a través de la API de mem0. Esta acción escribe una nueva entrada de vector en nuestra tabla Delta de origen.
- Síntesis: El agente Reflector procesa este evento, genera una información generalizada (por ejemplo, "las ventas del Producto X disminuyen los fines de semana") y la convierte en un embedding de vectores.
- Indexación: La nueva información se vuelve a escribir en la tabla Delta de origen, pero se marca como un aprendizaje sintetizado. Databricks AI Search sincroniza automáticamente esta nueva entrada, indexándola en la memoria semántica.
- Entrega: Finalmente, un agente dedicado de Edmunds Pulse, que monitorea constantemente la memoria semántica en busca de información de alta prioridad, entrega proactivamente este hallazgo sintetizado a una parte interesada humana. Trazando un paralelo con el lanzamiento de ChatGPT Pulse, que tiene como objetivo proporcionar un asistente de AI más ambiental y consciente, nuestro Edmunds Pulse actuará como el 'pulso' en vivo del negocio, asegurando que los conocimientos críticos no solo se almacenen, sino que se comuniquen activamente para impulsar acciones oportunas e inteligentes.
La capa de datos y conocimiento: una base de verdad gobernada
Los agentes de AI dependen de la calidad de sus datos. La capa de datos de Edmunds está diseñada específicamente para ofrecer consistencia, gobernanza y flexibilidad, con Unity Catalog como piedra angular para garantizar que toda la información siga siendo precisa y esté bien administrada.
Análisis profundo 5: Patrones de interactividad y acceso a datos de GraphQL
El marco de trabajo Model Context Protocol (MCP) de Edmunds conecta de forma segura a los agentes de AI con el contexto en tiempo real de todas las fuentes de datos principales, como especificaciones de vehículos, reseñas, inventario y métricas operativas de sistemas como New Relic. Esto se logra a través de una puerta de enlace API de GraphQL unificada, que abstrae la complejidad subyacente y ofrece un esquema fuertemente tipado y autodocumentado.
En lugar de que los agentes o ingenieros tengan que lidiar con datos fragmentados, esquemas desalineados o una resolución de problemas lenta, ahora el sistema admite tres patrones de interactividad principales, cada uno optimizado para un caso de uso diferente:
- Introspección dinámica de esquemas: los agentes pueden explorar de forma dinámica consultas nuevas o desconocidas mediante la introspección del propio esquema GraphQL. Cuando un cliente hace una pregunta única (como si el valor de un coche se ve afectado por retiradas de seguridad recientes), el agente puede descubrir nuevos tipos de datos sobre la marcha y diseñar consultas precisas para obtener respuestas relevantes. Esta flexibilidad permite a la organización adaptarse rápidamente a los nuevos requisitos empresariales sin necesidad de realizar cambios manuales en la API.
- Herramientas mapeadas granulares: cada herramienta del agente se mapea directamente a una consulta o mutación de GraphQL específica para operaciones rutinarias. Por ejemplo, actualizar el color de un vehículo es tan sencillo como extraer el VIN y el nuevo color, y el agente se encarga de la mutación. Este enfoque aumenta la fiabilidad y reduce la intervención manual, lo que agiliza las tareas diarias del equipo.
- Consultas persistentes: las funciones de alto tráfico y críticas para el rendimiento, como los cuadros de mando de inventario en tiempo real, aprovechan consultas prerregistradas para lograr la máxima eficiencia. El agente envía un hash ligero y variables, y el sistema devuelve los resultados de forma instantánea con un menor ancho de banda y una mayor seguridad.
Edmunds ha mejorado drásticamente la velocidad, flexibilidad y fiabilidad de las operaciones de datos en las funciones de producto y soporte al proporcionar a los agentes de IA un acceso estructurado a todos los datos empresariales a través de una única y sólida capa de API. Las tareas que antes requerían un desarrollo personalizado o una depuración entre equipos ahora se gestionan en tiempo real, lo que permite a los clientes y a los equipos internos beneficiarse de información más enriquecedora y respuestas más ágiles.
Análisis profundo 6: las capas semántica y de conocimiento
Esta capa crucial sirve de puente entre los datos brutos y la comprensión de los agentes. Abstrae la complejidad de los almacenes de datos subyacentes. Enriquece los datos con contexto empresarial, lo que garantiza que los agentes operen sobre una visión coherente, gobernada y comprensible del universo de Edmunds.
- Unity Catalog: la columna vertebral del gobierno: en el núcleo de nuestro ecosistema de datos, Unity Catalog proporciona gobierno, seguridad y linaje centralizados para todos los activos de datos e IA. Garantiza que cada dato al que accede un agente esté sujeto a controles de acceso detallados y que su recorrido sea totalmente auditable, lo que constituye la base no negociable para una plataforma de IA segura y conforme a las normativas.
- Capa semántica del producto: contexto empresarial en tiempo real: esta capa proporciona a los agentes una visión en tiempo real y orientada a objetos de nuestras entidades de producto principales (por ejemplo, vehículos, concesionarios, reseñas). Fundamentalmente, se alimenta directamente de los mismos esquemas GraphQL que impulsan el sitio web de Edmunds. Esto garantiza una coherencia absoluta; cuando un agente habla de un "vehículo", se refiere al mismo modelo de datos y lógica empresarial que ve un consumidor en el sitio web, lo que elimina cualquier riesgo de desviación de datos entre nuestros productos externos y nuestra IA interna.
- Capa semántica analítica: la única fuente de verdad para los KPI: esta capa proporciona una visión coherente y de confianza de todas las métricas de rendimiento empresarial. Se alimenta directamente de nuestras Delta Metric Views seleccionadas, que es la misma fuente que nutre todos los cuadros de mando ejecutivos y operativos. Esta alineación garantiza que cuando DataDave u otros agentes informen sobre los KPI empresariales (como el tráfico de sesiones, los clientes potenciales o las tasas de tasación), utilicen definiciones y fuentes de datos idénticas a las de nuestras herramientas de inteligencia empresarial establecidas, lo que garantiza una única fuente de verdad en toda la organización.
- Databricks AI Search: el motor para RAG: este componente es el motor de recuperación de alto rendimiento para nuestros datos no estructurados y semiestructurados. Al convertir nuestro vasto corpus de reseñas, artículos y contenido transcrito en incrustaciones vectoriales (vector embeddings), permitimos que agentes como el Asistente de conocimiento realicen búsquedas semánticas ultrarrápidas, recuperando el contexto más relevante para responder a las consultas de los usuarios en un patrón de generación aumentada por recuperación (RAG).
De centro de costes a motor de valor: medición del ROI de nuestra IA
Una arquitectura visionaria es tan buena como su ejecución. Nuestro enfoque se basa en una hoja de ruta por fases y en el firme compromiso de tratar nuestro ecosistema de IA como un motor central de generación de valor. Lo logramos vinculando directamente nuestro marco técnico de observabilidad, gobierno y ética con los resultados empresariales clave. Nuestro objetivo no es solo crear una IA potente, sino cuantificar su impacto en nuestros resultados financieros.
Aceleración de la velocidad empresarial
Hemos creado un sistema holístico para medir ambas partes de la ecuación del ROI. Por el lado del retorno, nuestro marco conecta el rendimiento de la IA directamente con los KPI empresariales. Por ejemplo:
- Nuestro agente DataDave ofrece análisis complejos y listos para la acción en cuestión de minutos, una tarea que antes requería horas de trabajo a los analistas humanos de Edmunds. Esto acelera drásticamente la toma de decisiones basada en datos.
- Nuestros agentes de fijación de precios responden de forma instantánea a las consultas, lo que elimina horas de investigación manual y libera a nuestros equipos para que se concentren en tareas estratégicas y de alto valor.
Aunque todavía estamos cuantificando el impacto preciso en métricas como las tasas de conversión de las campañas, este marco proporciona los datos en tiempo real necesarios para establecer esas correlaciones.
Optimización de costes
Practicamos un gobierno económico inteligente a través de nuestra AI Gateway. Los agentes de alta importancia como DataDave se dirigen a nuestros modelos más potentes para garantizar la precisión, mientras que las tareas rutinarias se asignan automáticamente a modelos más rentables. Esta estrategia de niveles de modelos nos permite gestionar con precisión nuestro gasto en LLM y computación, garantizando que cada dólar invertido esté alineado con el valor empresarial que genera.
“Databricks nos permite ejecutar el modelo adecuado para la tarea adecuada, de forma segura y a escala. Esa flexibilidad impulsa a nuestros agentes y ofrece experiencias de compra de coches más inteligentes”. —Greg Rokita, vicepresidente de tecnología de Edmunds
Habilitación organizativa: empoderar a cada empleado
Para hacer realidad esta visión, estamos fomentando una cultura de innovación en todo Edmunds. Nuestro objetivo es dar soporte a todo el espectro de interacción entre humanos e IA, desde tareas totalmente autónomas hasta revisiones con intervención humana (human-in-the-loop) y resolución de problemas totalmente colaborativa.
Para dar soporte a esto, proporcionamos un sólido SDK de agentes para ingenieros y defendemos un movimiento de "desarrolladores ciudadanos" (Citizen Developers) a través de nuestra plataforma Agent Bricks. Esta iniciativa se puso en marcha con nuestra conferencia tecnológica interna "AI Agents @ Edmunds" y se nutre de un gremio activo de agentes de LLM (LLM Agents Guild), lo que garantiza que cada empleado disponga de las herramientas y el soporte necesarios para contribuir a nuestro futuro impulsado por la IA.
El camino por delante: de la inteligencia proactiva a la verdadera autonomía
Nuestro viaje para convertirnos en una organización verdaderamente nativa de la IA es un maratón, no un esprint. La arquitectura "Edmunds Mind" sirve como nuestra hoja de ruta para ese viaje, y su próximo paso evolutivo es desarrollar agentes proactivos que no solo respondan preguntas, sino que también anticipen las necesidades empresariales. Visualizamos un futuro en el que nuestros agentes identifiquen oportunidades de mercado a partir de flujos de datos en tiempo real y ofrezcan información estratégica a las partes interesadas antes de que siquiera la soliciten.
En última instancia, nuestra hoja de ruta conduce a un sistema en el que los agentes pueden autooptimizarse: proponer nuevas herramientas, perfeccionar los mecanismos de crítica e incluso sugerir mejoras arquitectónicas. Esto marca la transición de un sistema que simplemente operamos a un verdadero socio cognitivo, evolucionando nuestros roles de operadores a supervisores, especialistas en ética y estrategas de una nueva fuerza de trabajo inteligente.
Obtenga más información sobre cómo Edmunds está creando una experiencia de compra de coches impulsada por IA con la ayuda de Databricks.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.