LogSentinel: cómo Databricks usa Databricks para la detección y la gobernanza de PII con tecnología de LLM
Un análisis profundo de LogSentinel: cómo aprovechamos internamente los LLM para automatizar el descubrimiento y la gobernanza de la PII
- Utilizamos LLM en Databricks para detectar y clasificar automáticamente datos confidenciales en registros y bases de datos.
- Nuestro sistema LogSentinel aplica una clasificación jerárquica, sensible a la residencia y multimodelo para un etiquetado preciso, técnicas que se están integrando directamente en el producto Data Classification.
- Al preetiquetar las columnas y detectar continuamente la variación del etiquetado, LogSentinel permite la detección fiable de PII, la aplicación automatizada de políticas y flujos de trabajo de cumplimiento mucho más rápidos a escala.
Databricks opera a una escala en la que nuestros registros internos y datasets cambian constantemente: los esquemas evolucionan, aparecen nuevas columnas y la semántica de los datos varía. En este blog, analizamos cómo usamos Databricks internamente en Databricks para mantener la PII y otros datos confidenciales correctamente etiquetados a medida que nuestra plataforma cambia.
Para ello, creamos LogSentinel, un sistema de clasificación de datos basado en LLM en Databricks que realiza un seguimiento de la evolución de los esquemas, detecta la variación del etiquetado y aporta etiquetas de alta calidad a nuestros controles de gobernanza y seguridad. Usamos MLflow para realizar un seguimiento de los experimentos y monitorear el rendimiento a lo largo del tiempo, y estamos integrando las mejores ideas de LogSentinel de nuevo en el producto Databricks Data Classification para que los clientes puedan beneficiarse del mismo enfoque.
Por qué es importante este sistema
Este sistema está diseñado para impulsar tres palancas de negocio concretas para los equipos de plataforma, datos y seguridad:
- Ciclos de cumplimiento más cortos: las tareas de revisión recurrentes que antes llevaban semanas de trabajo de los analistas ahora se completan en horas porque las columnas se preetiquetan y se clasifican previamente antes de que una persona las revise.
- Menor riesgo operativo: el sistema detecta continuamente el desvío de etiquetado y los cambios de esquema, de modo que es menos probable que los campos confidenciales pasen desapercibidos con etiquetas incorrectas o faltantes.
- Aplicación de políticas más sólida: las etiquetas fiables ahora impulsan directamente las reglas de enmascaramiento, control de acceso, retención y residencia, lo que convierte lo que solía ser una “gobernanza de mejor esfuerzo” en una política ejecutable.
En la práctica, los equipos pueden conectar nuevas tablas a un pipeline estándar, supervisar las métricas de variación y las excepciones, y confiar en el sistema para aplicar las restricciones de PII y residencia sin crear un clasificador a medida para cada dominio.
Un vistazo a la arquitectura del sistema
Creamos un sistema de clasificación de columnas basado en LLM en Databricks que anota continuamente las tablas utilizando nuestra taxonomía de datos interna, detecta la variación del etiquetado y abre tickets de remediación cuando algo parece incorrecto. Los diversos componentes que forman parte del sistema se describen a continuación (seguidos y evaluados con MLflow):
- Ingesta de datos: ingesta de diversas fuentes de datos (incluidos los datos de las columnas de Unity Catalog, los datos de la taxonomía de etiquetas y los datos de referencia)
- Aumento de datos: aumento de datos mediante Databricks AI Search y la generación de comentarios con IA
- Orquestación de LLM
- Sistema de etiquetado por niveles
- Versionado de modelos: ejecución de múltiples modelos en paralelo
- Predicción de etiquetas: predicción de la etiqueta final mediante el enfoque de mezcla de expertos (MoE)
- Creación de tickets: detección de infracciones y generación de tickets de JIRA
El flujo de trabajo de extremo a extremo se muestra en la siguiente figura
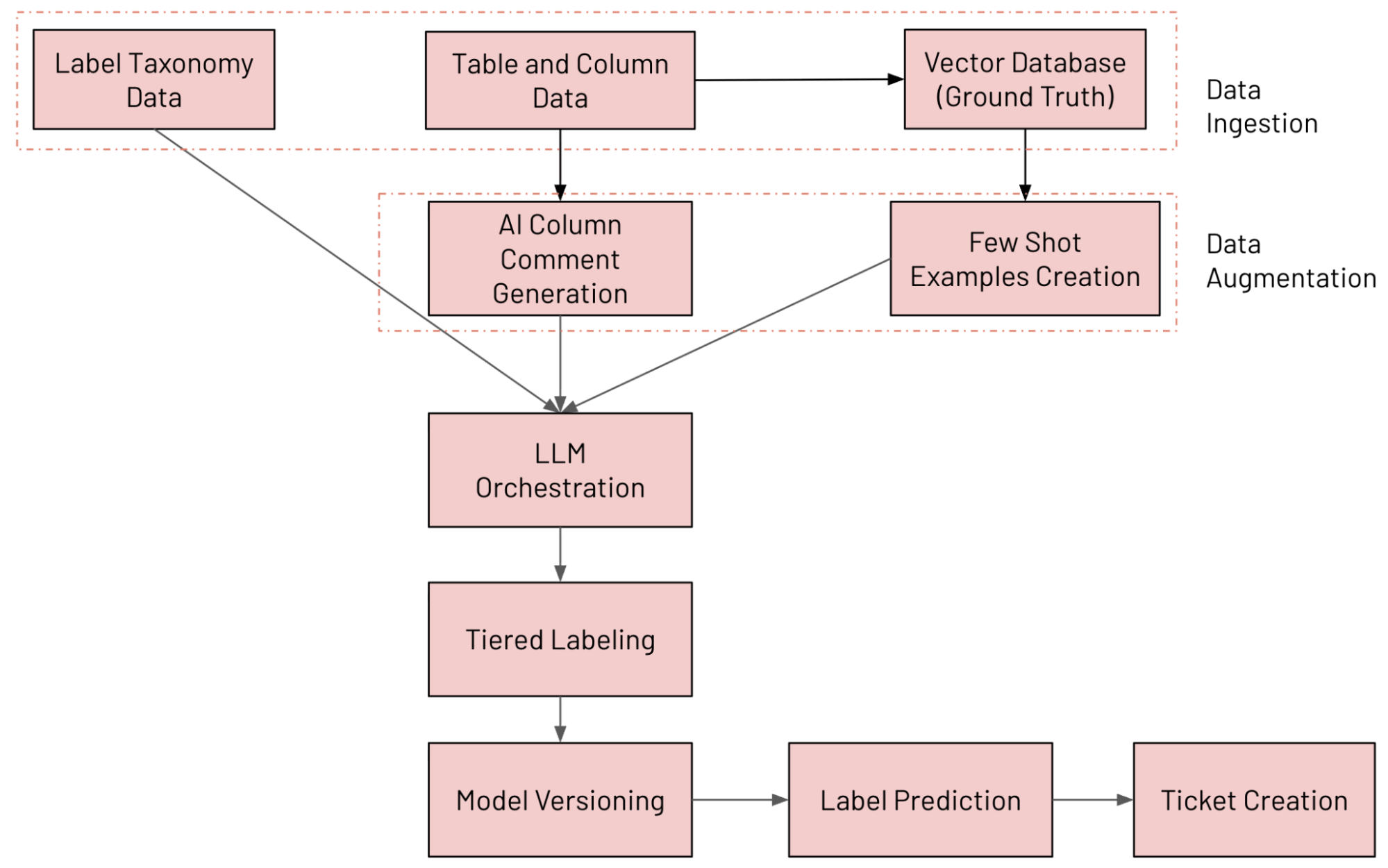
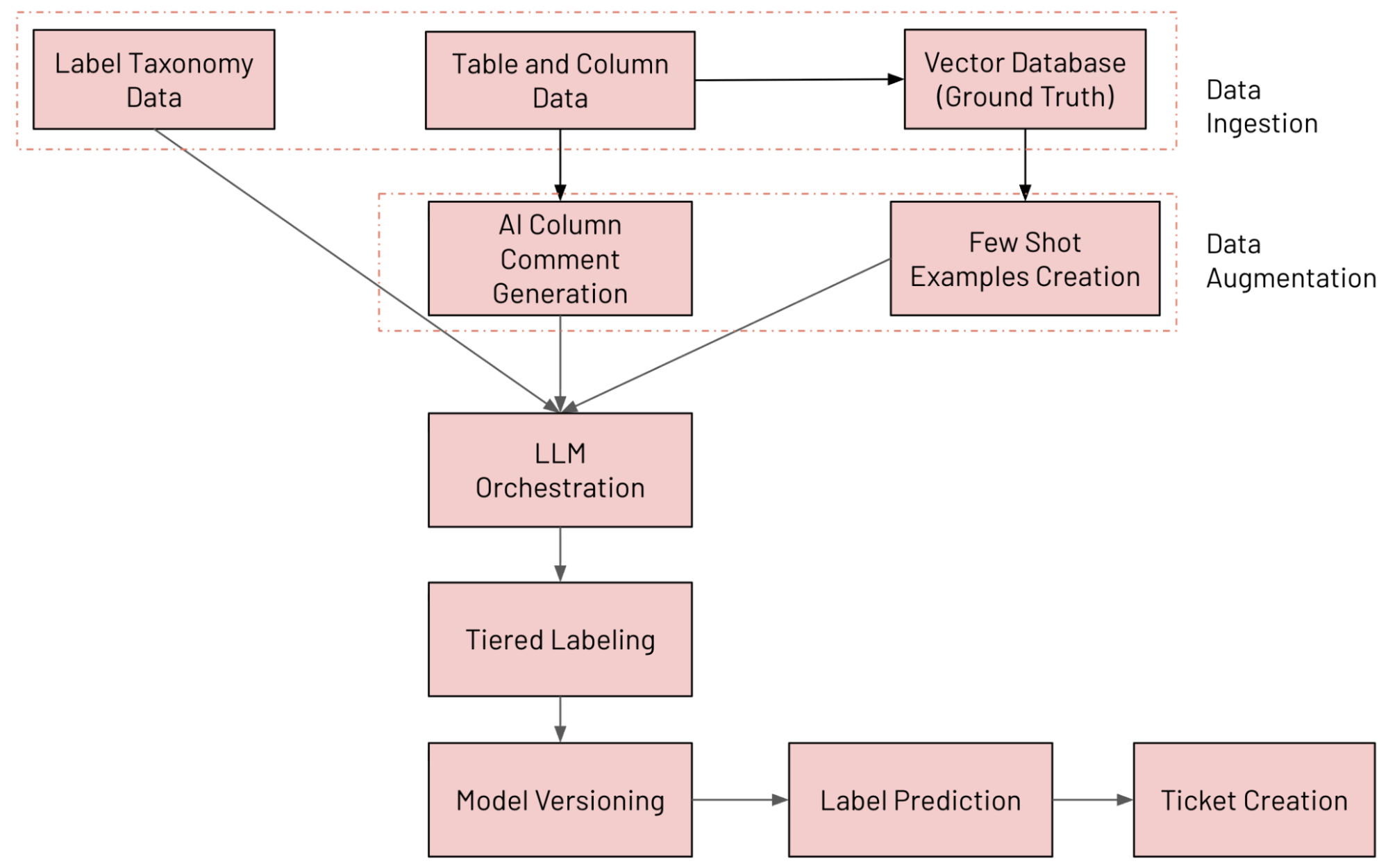{kind=link}
Ingesta de datos
Para cada tipo de registro o conjunto de datos que se va a anotar, tomamos muestras de valores al azar de cada columna y enviamos los siguientes metadatos al sistema: nombre de la tabla, nombre de la columna, tipo, comentario existente y una pequeña muestra de valores. Para reducir el costo de los LLM y mejorar el rendimiento, se agrupan varias columnas de la misma tabla en una sola solicitud.
Nuestra taxonomía se define mediante Protocol Buffers y actualmente incluye más de 100 etiquetas de datos jerárquicas, con espacio para extensiones personalizadas cuando los equipos necesitan categorías adicionales. Esto proporciona a las partes interesadas de la gobernanza y la plataforma un contrato compartido sobre lo que significan “PII” y “confidencial” más allá de un puñado de regex.
Aumento de datos
Dos estrategias de aumento mejoran significativamente la calidad de la clasificación:
- Generación de comentarios de columnas con IA: cuando faltan comentarios, usamos los comentarios generados por IA de Databricks para sintetizar descripciones concisas y legibles por humanos que ayudan tanto al LLM como a los futuros consumidores de la tabla.
- Generación de ejemplos few-shot: mantenemos un dataset de referencia y utilizamos tanto ejemplos estáticos como dinámicos recuperados a través de AI Search; para cada columna, creamos un embedding a partir del nombre, el tipo, el comentario y el contexto, y luego recuperamos las K columnas etiquetadas más similares para incluirlas en el prompt.
El prompting estático es mejor durante las primeras etapas o cuando los datos etiquetados son limitados, lo que proporciona coherencia y reproducibilidad. El prompting dinámico es más eficaz en sistemas maduros, ya que utiliza la búsqueda vectorial para extraer ejemplos similares y adaptarse a nuevos esquemas y dominios de datos en conjuntos de datos grandes y diversos.
Orquestación de LLM
En el núcleo del sistema hay una capa de orquestación ligera que gestiona las llamadas a los LLM a escala de producción.
Las capacidades clave incluyen:
- Enrutamiento multimodelo a través de LLM alojados internamente (por ejemplo, modelos basados en Llama, Claude y GPT) con conmutación por error automática cuando un modelo no está disponible.
- Lógica de reintentos para fallos transitorios y límites de velocidad con retroceso exponencial.
- Ganchos de validación que detectan etiquetas vacías, no válidas o alucinadas y vuelven a ejecutar esos casos con modelos de respaldo.
- Procesamiento por lotes que anota varias columnas a la vez para optimizar el uso de tokens sin perder el contexto.
Sistema de etiquetado por niveles
Predecimos tres tipos de etiquetas por columna:
- Etiquetas granulares, extraídas de un conjunto de más de 100 opciones detalladas que potencian el enmascaramiento, la redacción y los estrictos controles de acceso.
- Etiquetas jerárquicas, que agregan etiquetas granulares relacionadas en categorías más amplias adecuadas para el monitoreo y la generación de informes.
- Etiquetas de residencia, que indican si los datos deben permanecer en la región o pueden moverse entre regiones, alimentando directamente las políticas de movimiento de datos.
Para mantener la coherencia de las predicciones y reducir las alucinaciones, utilizamos un flujo de dos etapas: un paso de clasificación general asigna una categoría de alto nivel y, a continuación, un paso de refinamiento elige la etiqueta exacta dentro de esa categoría. Esto refleja cómo un revisor humano decidiría primero “estos son datos del espacio de trabajo” y luego elegiría la etiqueta de identificador de espacio de trabajo específica.
Versionado de modelos y predicción de etiquetas
En lugar de depender de una única configuración “óptima”, cada configuración de modelo se trata como un experto que compite por etiquetar una columna.
Varias versiones de modelos se ejecutan en paralelo con diferencias en:
- Opciones de LLM primario y de respaldo.
- Uso de comentarios generados frente a metadatos sin procesar.
- Estrategia de prompting (few-shot estático frente a dinámico).
- Granularidad de las etiquetas y subconjuntos de taxonomía.
Cada experto produce una etiqueta y una puntuación de confianza entre 0 y 100. A continuación, el sistema selecciona la etiqueta del experto con la mayor confianza, un enfoque al estilo de mezcla de expertos (Mixture-of-Experts) que mejora la precisión y reduce el impacto de las predicciones erróneas ocasionales de cualquier configuración.
Este diseño hace que sea seguro experimentar: se pueden introducir nuevos modelos o estrategias de prompt, ejecutarlos junto a los existentes y evaluarlos tanto en función de las métricas como del volumen de tickets posteriores antes de que se conviertan en la opción predeterminada.
Creación de tickets
El pipeline compara continuamente las anotaciones de esquema actuales con las predicciones del LLM para detectar desviaciones significativas.
Los casos típicos incluyen:
- Columnas nuevas agregadas sin ninguna anotación.
- Anotaciones existentes que ya no coinciden con el contenido de la columna.
- Columnas que contienen valores confidenciales que han sido etiquetadas como aptas para el movimiento entre regiones.
Cuando el sistema detecta una infracción, crea una entrada de política y abre un ticket de JIRA para el equipo propietario con contexto sobre la tabla, la columna, la etiqueta propuesta y la confianza. Esto convierte los problemas de clasificación de datos en un flujo de trabajo continuo que los equipos pueden seguir y resolver de la misma manera que siguen otros incidentes de producción.
Impacto y evaluación
El sistema se evaluó con 2258 muestras etiquetadas, de las cuales 1010 contenían PII y 1248 no eran PII. En este conjunto de datos, alcanzó hasta un 92 % de precisión y un 95 % de recall para la detección de PII.
Lo que es más importante para las partes interesadas es que la implementación produjo los resultados operativos que se necesitaban:
- El esfuerzo de revisión manual se redujo de semanas a horas para cada ciclo de auditoría a gran escala porque los revisores parten de etiquetas sugeridas de alta calidad en lugar de esquemas sin procesar.
- La variación del etiquetado ahora se detecta continuamente a medida que los esquemas evolucionan, en lugar de descubrirse durante una revisión anual.
- Las alertas sobre datos confidenciales mal etiquetados como seguros son más específicas, para que los equipos de seguridad puedan actuar con rapidez en lugar de clasificar los resultados de escáneres ruidosos basados en reglas.
- Las políticas de enmascaramiento y residencia se aplican a escala utilizando la misma taxonomía de etiquetas que impulsa la analítica y la generación de informes.
La precisión y la exhaustividad actúan como barreras de protección, pero el sistema se ajusta en torno a resultados como el tiempo de revisión, la latencia de detección de variaciones y el volumen de tickets procesables producidos por semana.
Conclusión
Al combinar el etiquetado basado en taxonomía y un marco de evaluación de estilo MoE, hemos habilitado los flujos de trabajo de ingeniería y gobernanza existentes en Databricks, con experimentos e implementaciones gestionados mediante MLflow. Mantiene las etiquetas actualizadas a medida que cambian los esquemas, hace que las revisiones de cumplimiento normativo sean más rápidas y centradas, y proporciona los ganchos de aplicación necesarios para aplicar las reglas de enmascaramiento y residencia de forma coherente en toda la plataforma.
La parte más emocionante de este trabajo es la integración de nuestros aprendizajes internos directamente en el producto Data Classification. A medida que operacionalizamos y validamos estas técnicas dentro de LogSentinel, incorporamos nuestras técnicas directamente en Databricks Data Classification.
El mismo patrón —ingerir metadatos y muestras, aumentar el contexto, orquestar múltiples LLM y enviar las predicciones a los sistemas de políticas y de tickets— puede reutilizarse siempre que se requiera una comprensión fiable y evolutiva de los datos. Al incorporar estos conocimientos en nuestra oferta de productos principal, permitimos que todas las organizaciones aprovechen su inteligencia de datos para el cumplimiento y la gobernanza con la misma precisión y escala que nosotros en Databricks.
Agradecimientos
Este proyecto fue posible gracias a la colaboración de varios equipos de ingeniería. Gracias a Anirudh Kondaveeti, Sittichai Jiampojamarn, Zefan Xu, Li Yang, Xiaohui Sun, Dibyendu Karmakar, Chenen Liang, Viswesh Periyasamy, Chengzu Ou, Evion Kim, Matthew Hayes, Benjamin Ebanks, Sudeep Srivastava por su apoyo y sus contribuciones.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.