Rendimiento de RAG de Contexto Largo de LLMs
Aumentar el contexto no siempre ayuda
por Quinn Leng, Jacob Portes, Sam Havens, Matei Zaharia y Michael Carbin
La Generación Aumentada por Recuperación (RAG) es el caso de uso de IA generativa más adoptado por nuestros clientes. RAG mejora la precisión de los LLM recuperando información de fuentes externas como documentos no estructurados o datos estructurados. Con la disponibilidad de LLM con longitudes de contexto más largas como Anthropic Claude (200k context length), GPT-4-turbo (128k context length) y Google Gemini 1.5 pro (2 million context length), los desarrolladores de aplicaciones LLM pueden alimentar más documentos en sus aplicaciones RAG. Llevando las longitudes de contexto más largas al extremo, incluso existe un debate sobre si los modelos de lenguaje de contexto largo eventualmente reemplazarán los flujos de trabajo RAG. ¿Por qué recuperar documentos individuales de una base de datos si puedes insertar todo el corpus en la ventana de contexto?
Esta publicación de blog explora el impacto del aumento de la longitud del contexto en la calidad de las aplicaciones RAG. Realizamos más de 2000 experimentos en 13 LLM populares de código abierto y comerciales para descubrir su rendimiento en varios conjuntos de datos específicos de dominios. Descubrimos que:
- Recuperar más documentos puede ser beneficioso: Recuperar más información para una consulta dada aumenta la probabilidad de que la información correcta se pase al LLM. Los LLM modernos con longitudes de contexto largas pueden aprovechar esto y, por lo tanto, mejorar el sistema RAG en general.
- El contexto más largo no siempre es óptimo para RAG: El rendimiento de la mayoría de los modelos disminuye después de un cierto tamaño de contexto. Notablemente, el rendimiento de Llama-3.1-405b comienza a disminuir después de 32k tokens, GPT-4-0125-preview comienza a disminuir después de 64k tokens, y solo unos pocos modelos pueden mantener un rendimiento RAG consistente de contexto largo en todos los conjuntos de datos.
- Los modelos fallan en contexto largo de maneras muy distintas: Realizamos análisis profundos del rendimiento de contexto largo de Llama-3.1-405b, GPT-4, Claude-3-sonnet, DBRX y Mixtral e identificamos patrones de falla únicos, como rechazos debido a preocupaciones de derechos de autor o resúmenes constantes del contexto. Muchos de los comportamientos sugieren una falta de entrenamiento posterior suficiente para contexto largo.
Antecedentes
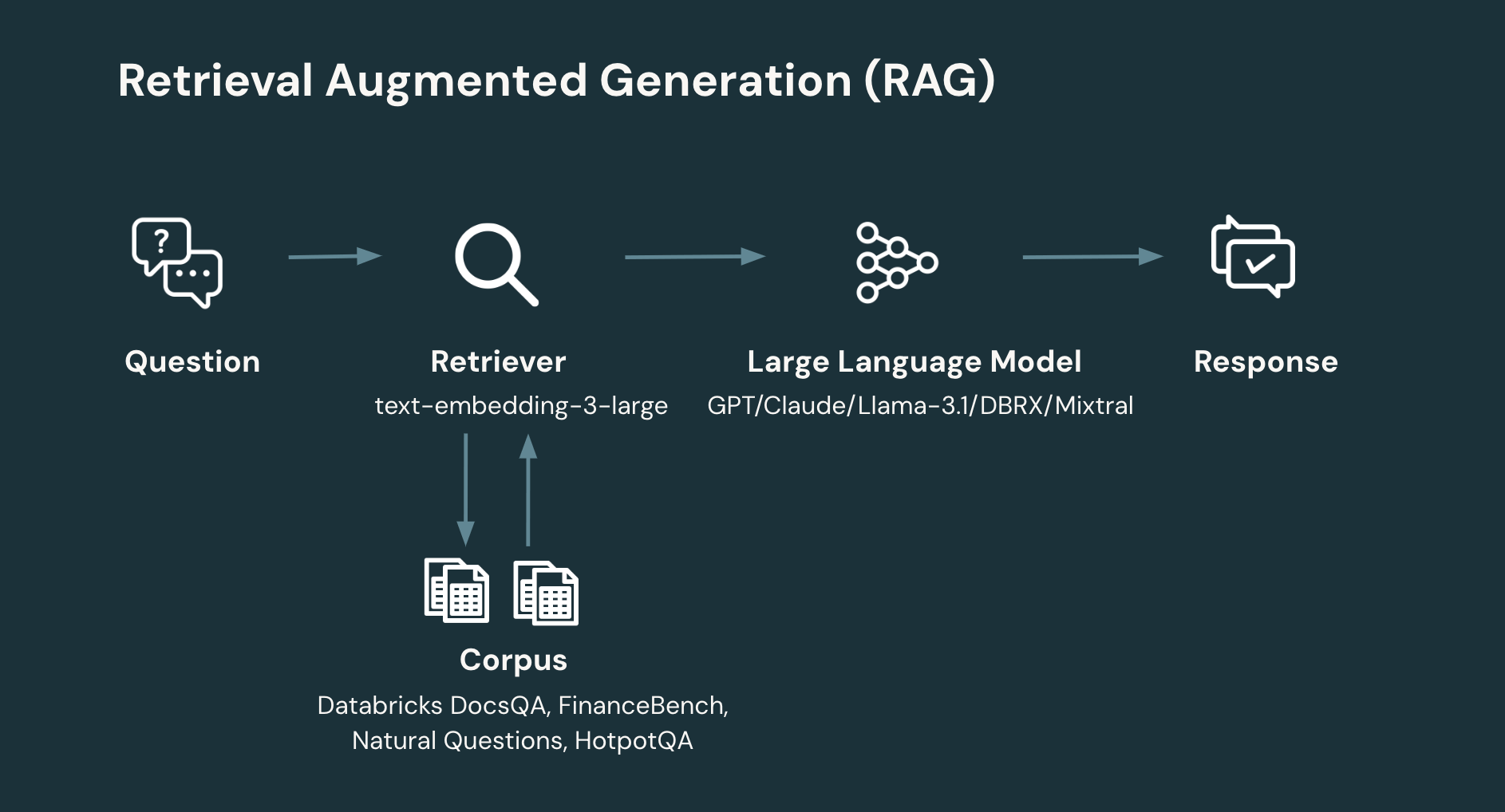
RAG: Un flujo de trabajo RAG típico implica al menos dos pasos:
- Recuperación: dada la pregunta del usuario, recuperar la información relevante de un corpus o base de datos. La Recuperación de Información es un área rica en diseño de sistemas. Sin embargo, un enfoque simple y contemporáneo es incrustar documentos individuales para producir una colección de vectores que luego se almacenan en una base de datos vectorial. El sistema recupera documentos relevantes basándose en la similitud de la pregunta del usuario con el documento. Un parámetro clave de diseño en la recuperación es el número de documentos y, por lo tanto, el número total de tokens a devolver.
- Generación: dada la pregunta del usuario y la información recuperada, generar la respuesta correspondiente (o negarse si no hay suficiente información para generar una respuesta). El paso de generación puede emplear una amplia gama de técnicas. Sin embargo, un enfoque simple y contemporáneo es solicitar a un LLM a través de un prompt simple que introduzca la información recuperada y el contexto relevante para la pregunta que se debe responder.
Se ha demostrado que RAG aumenta la calidad de los sistemas de QA en muchos dominios y tareas (Lewis et.al 2020).
Modelos de lenguaje de contexto largo: los LLM modernos admiten longitudes de contexto cada vez mayores.
Mientras que el GPT-3.5 original solo tenía una longitud de contexto de 4k tokens, GPT-4-turbo y GPT-4o tienen una longitud de contexto de 128k. De manera similar, Claude 2 tiene una longitud de contexto de 200k tokens y Gemini 1.5 pro presume de una longitud de contexto de 2 millones de tokens. La longitud máxima de contexto de los LLM de código abierto ha seguido una tendencia similar: mientras que la primera generación de modelos Llama solo tenía una longitud de contexto de 2k tokens, modelos más recientes como Mixtral y DBRX tienen una longitud de contexto de 32k tokens. El Llama 3.1 lanzado recientemente tiene un máximo de 128k tokens.
El beneficio de usar contexto largo para RAG es que el sistema puede aumentar el paso de recuperación para incluir más documentos recuperados en el contexto del modelo de generación, lo que aumenta la probabilidad de que un documento relevante para responder la pregunta esté disponible para el modelo.
Por otro lado, las evaluaciones recientes de modelos de contexto largo han puesto de manifiesto dos limitaciones generalizadas:
- El problema de “perdido en el medio”: el problema de “perdido en el medio" ocurre cuando los modelos tienen dificultades para retener y utilizar eficazmente la información de las porciones intermedias de textos largos. Este problema puede provocar una degradación del rendimiento a medida que aumenta la longitud del contexto, y los modelos se vuelven menos efectivos para integrar información distribuida en contextos extensos.
- Effective context length: the RULER paper explored the performance of long context models on several categories of tasks including retrieval, variable tracking, aggregation and question answering, and found that the effective context length - the amount of usable context length beyond which model performance begins to decrease – can be much shorter than the claimed maximum context length.
With these research observations in mind, we designed multiple experiments to probe the potential value of long context models, the effective context length of long context models in RAG workflows, and assess when and how long context models can fail.
Methodology
To examine the effect of long contexton retrieval and generation, both individually and on the entire RAG pipeline, we explored the following research questions:
- The effect of long context on retrieval: How does the quantity of documents retrieved affect the probability that the system retrieves a relevant document?
- The effect of long context on RAG: How does generation performance change as a function of more retrieved documents?
- The failure modes for long context on RAG: How do different models fail at long context?
We used the following retrieval settings for experiments 1 and 2:
- embedding model: (OpenAI) text-embedding-3-large
- chunk size: 512 tokens (we split the documents from the corpus into chunk size of 512 tokens)
- stride size: 256 tokens (the overlap between adjacent chunks is 256 tokens)
- vector store: FAISS (with IndexFlatL2 index)
We used the following LLM generation settings for experiment 2:
- generation models: gpt-4o, claude-3-5-sonnet, claude-3-opus, claude-3-haiku, gpt-4o-mini, gpt-4-turbo, claude-3-sonnet, gpt-4, meta-llama-3.1-405b, meta-llama-3-70b, mixtral-8x7b, dbrx, gpt-3.5-turbo
- temperature: 0.0
- max_output_tokens: 1024
When benchmarking the performance at context length X, we used the following method to calculate how many tokens to use for the prompt:
- Given the context length X, we first subtracted 1k tokens which is used for the model output
- We then left a buffer size of 512 tokens
The rest is the cap for how long the prompt can be (this is the reason why we used a context length 125k instead of 128k, since we wanted to leave enough buffer to avoid hitting out-of-context errors).
Evaluation datasets
In this study, we benchmarked all LLMs on 4 curated RAG datasets that were formatted for both retrieval and generation. These included Databricks DocsQA and FinanceBench, which represent industry use cases and Natural Questions (NQ) and HotPotQA, which represent more academic settings . Below are the dataset details:
| Dataset \ Details | Category | Corpus #docs | # queries | AVG doc length (tokens) | min doc length (tokens) | max doc length (tokens) | Description |
| Databricks DocsQA (v2) | Use case specific: corporate question-answering | 7563 | 139 | 2856 | 35 | 225941 | DocsQA is an internal question-answering dataset using information from public Databricks documentation and real user questions and labeled answers. Each of the documents in the corpus is a web page. |
| FinanceBench (150 tasks) | Use case specific: finance question-answering | 53399 | 150 | 811 | 0 | 8633 | FinanceBench es un conjunto de datos académico de respuesta a preguntas que incluye páginas de 360 presentaciones SEC 10k de empresas públicas y las preguntas correspondientes y respuestas de verdad fundamental basadas en documentos SEC 10k. Se pueden encontrar más detalles en el artículo Islam et al. (2023). Utilizamos una versión propietaria (código cerrado) del conjunto de datos completo de Patronus. Cada uno de los documentos de nuestro corpus corresponde a una página de los archivos PDF SEC 10k. |
| Natural Questions (división dev | Académico: conocimiento general (wikipedia) respuesta a preguntas | 7369 | 534 | 11354 | 716 | 13362 | Natural Questions es un conjunto de datos académico de respuesta a preguntas de Google, discutido en su artículo de 2019 (Kwiatkowski et al., 2019. Las consultas son consultas de búsqueda de Google. Cada pregunta se responde utilizando contenido de páginas de Wikipedia en el resultado de búsqueda. Utilizamos una versión simplificada de las páginas de Wikipedia donde se ha eliminado la mayor parte del texto que no es lenguaje natural, pero algunas etiquetas HTML permanecen para definir una estructura útil en los documentos (por ejemplo, tablas). La simplificación se realiza adaptando la implementación original. |
| BEIR-HotpotQA | Académico: conocimiento general multi-hop (wikipedia) respuesta a preguntas | 5233329 | 7405 | 65 | 0 | 3632 | HotpotQA es un conjunto de datos académico de respuesta a preguntas recopilado de Wikipedia en inglés; estamos utilizando la versión de HotpotQA del artículo de BEIR (Thakur et al, 2021 |
Métricas de evaluación:
- Métricas de recuperación: utilizamos la recuperación para medir el rendimiento de la recuperación. La puntuación de recuperación se define como la relación entre el número de documentos relevantes recuperados y el número total de documentos relevantes en el conjunto de datos.
- Métricas de generación: utilizamos la métrica de corrección de la respuesta para medir el rendimiento de la generación. Implementamos la corrección de la respuesta a través de nuestro sistema calibrado LLM-como-juez impulsado por GPT-4o. Nuestros resultados de calibración demostraron que la tasa de acuerdo juez-humano es tan alta como la tasa de acuerdo humano-humano.
¿Por qué contexto largo para RAG?
Experimento 1: Los beneficios de recuperar más documentos
En este experimento, evaluamos cómo la recuperación de más resultados afectaría la cantidad de información relevante colocada en el contexto del modelo de generación. Específicamente, asumimos que el recuperador devuelve X número de tokens y luego calculamos la puntuación de recuperación en ese punto de corte. Desde otra perspectiva, el rendimiento de recuperación es el límite superior del rendimiento del modelo de generación cuando se requiere que el modelo utilice solo los documentos recuperados para generar respuestas.
A continuación se muestran los resultados de recuperación para el modelo de incrustación OpenAI text-embedding-3-large en 4 conjuntos de datos y diferentes longitudes de contexto. Usamos un tamaño de fragmento de 512 tokens y dejamos un búfer de 1.5k para el prompt y la generación.
| # Fragmentos recuperados | 1 | 5 | 13 | 29 | 61 | 125 | 189 | 253 | 317 | 381 |
Recall@k \ Longitud del contexto | 2k | 4k | 8k | 16k | 32k | 64k | 96k | 128k | 160k | 192k |
| Databricks DocsQA | 0.547 | 0.856 | 0.906 | 0.957 | 0.978 | 0.986 | 0.993 | 0.993 | 0.993 | 0.993 |
| FinanceBench | 0.097 | 0.287 | 0.493 | 0.603 | 0.764 | 0.856 | 0.916 | 0.916 | 0.916 | 0.916 |
| NQ | 0.845 | 0.992 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| HotPotQA | 0.382 | 0.672 | 0.751 | 0.797 | 0.833 | 0.864 | 0.880 | 0.890 | 0.890 | 0.890 |
| Average | 0.468 | 0.702 | 0.788 | 0.839 | 0.894 | 0.927 | 0.947 | 0.95 | 0.95 | 0.95 |
Punto de saturación: como se puede observar en la tabla, la puntuación de recuperación de cada conjunto de datos se satura en una longitud de contexto diferente. Para el conjunto de datos NQ, se satura pronto en una longitud de contexto de 8k, mientras que los conjuntos de datos DocsQA, HotpotQA y FinanceBench se saturan en longitudes de contexto de 96k y 128k, respectivamente. Estos resultados demuestran que con un enfoque de recuperación simple, hay información relevante adicional disponible para el modelo de generación hasta 96k o 128k tokens.Por lo tanto, el aumento del tamaño del contexto de los modelos modernos ofrece la promesa de capturar esta información adicional para mejorar la calidad general del sistema.
Usar un contexto más largo no aumenta uniformemente el rendimiento de RAG
Experimento 2: Contexto largo en RAG
En este experimento, combinamos el paso de recuperación y el paso de generación en un simple pipeline RAG. Para medir el rendimiento de RAG en una cierta longitud de contexto, aumentamos el número de fragmentos devueltos por el recuperador para llenar el contexto del modelo de generación hasta una longitud de contexto dada. Luego, le pedimos al modelo que responda las preguntas de un benchmark dado. Debajo se muestran los resultados de estos modelos en diferentes longitudes de contexto.
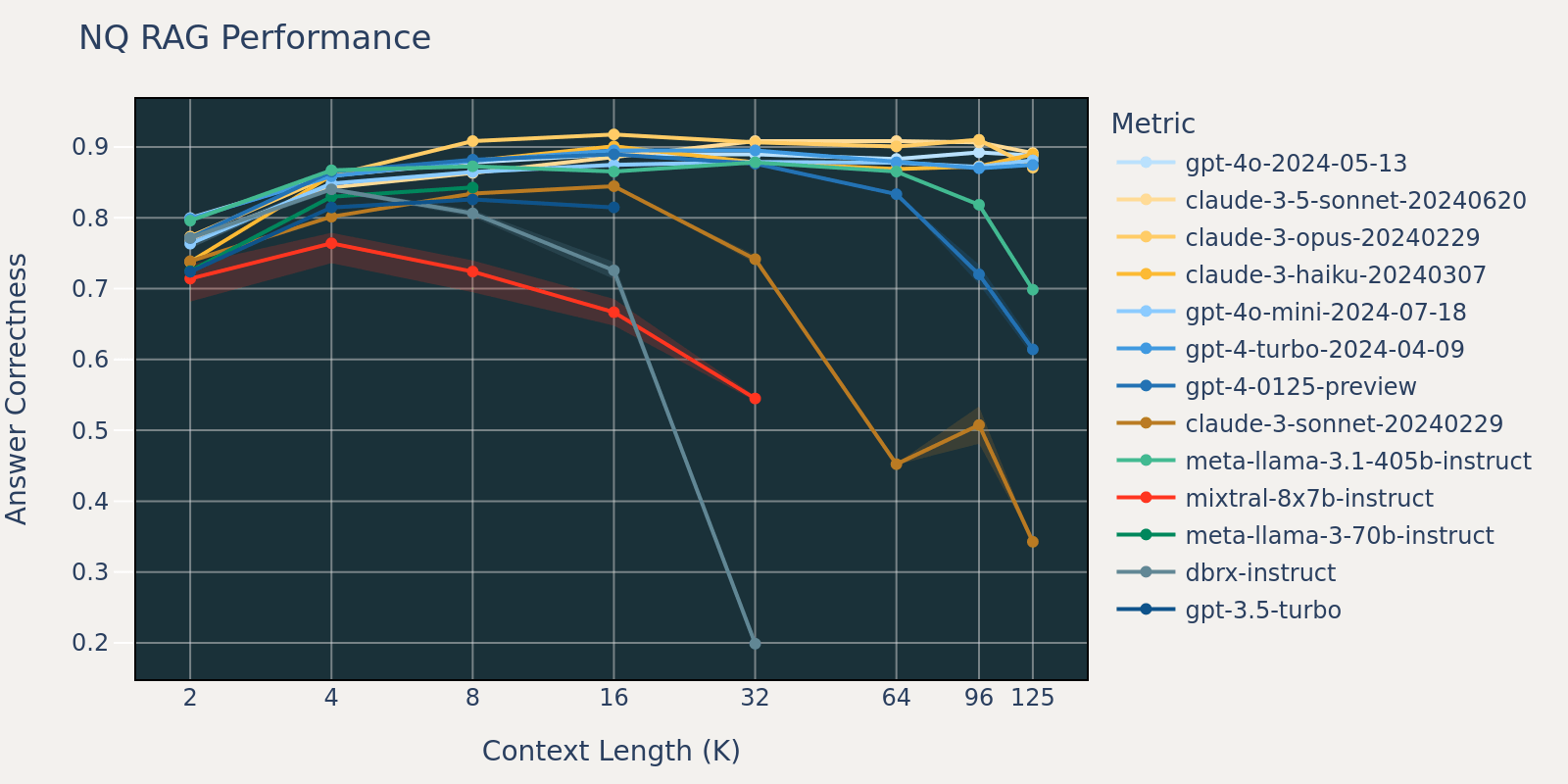
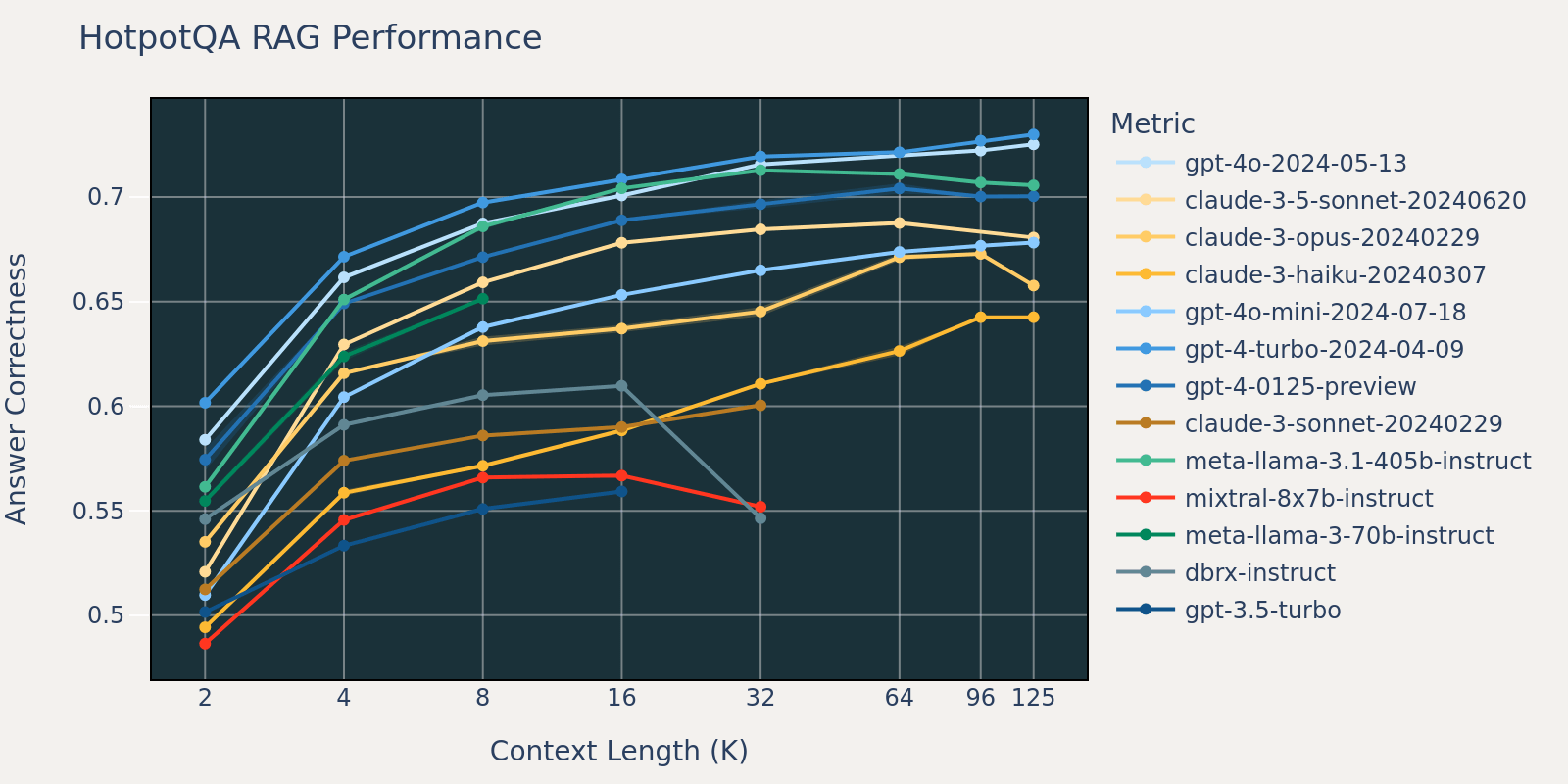
El conjunto de datos Natural Questions es un conjunto de datos de respuesta a preguntas generales que está disponible públicamente. Especulamos que la mayoría de los modelos de lenguaje han sido entrenados o ajustados en tareas similares a Natural Question y, por lo tanto, observamos diferencias de puntuación relativamente pequeñas entre los diferentes modelos en longitudes de contexto cortas. A medida que la longitud del contexto crece, algunos modelos comienzan a tener un rendimiento reducido.
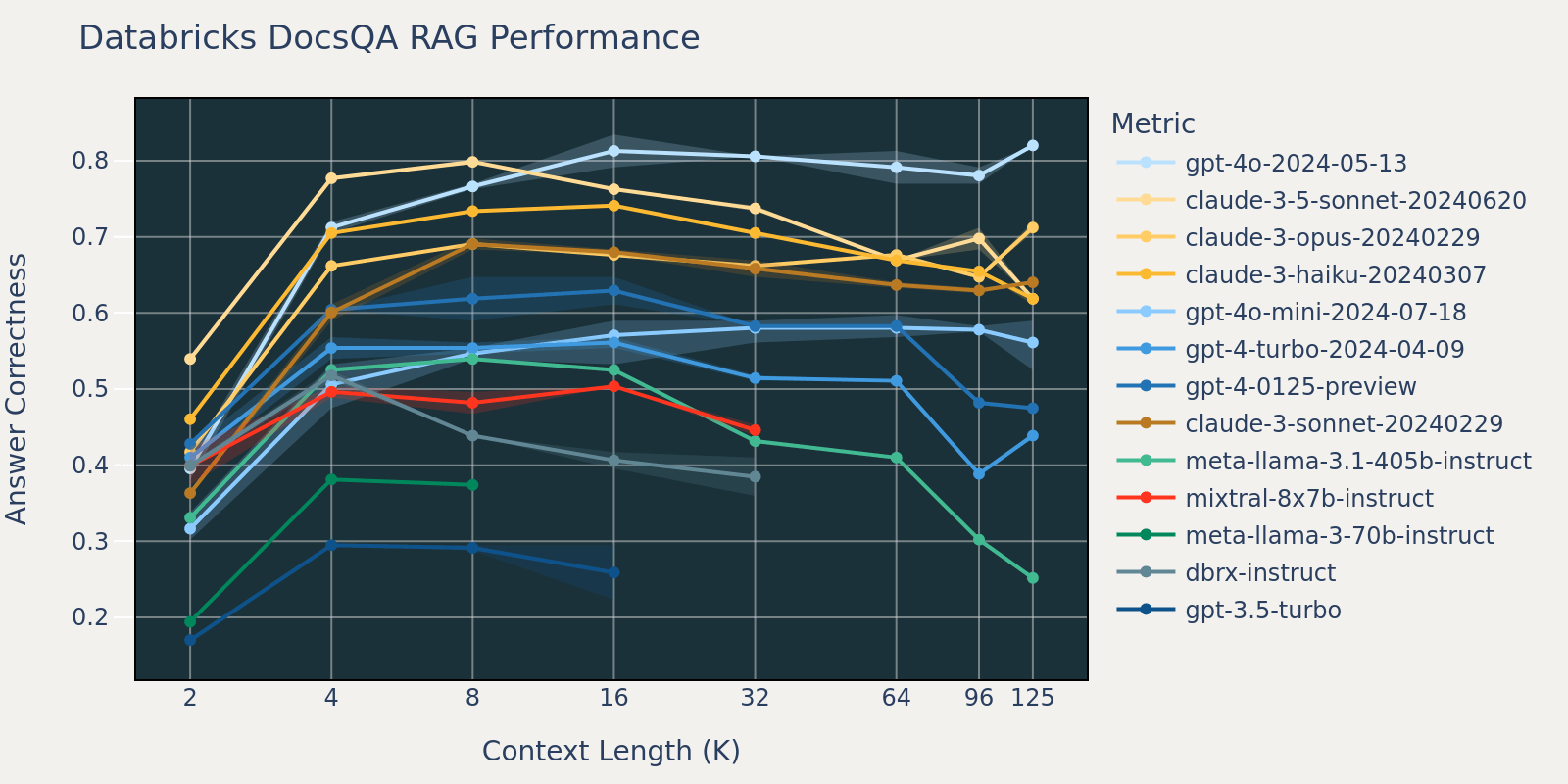
En comparación con Natural Questions, el conjunto de datos Databricks DocsQA no está disponible públicamente (aunque el conjunto de datos fue curado a partir de documentos disponibles públicamente). Las tareas son más específicas del caso de uso y se centran en la respuesta a preguntas empresariales basadas en la documentación de Databricks. Especulamos que, dado que es menos probable que los modelos hayan sido entrenados en tareas similares, el rendimiento de RAG entre los diferentes modelos varía más que el de Natural Questions. Además, dado que la longitud promedio del documento para el conjunto de datos es de 3k, que es mucho más corta que la de FinanceBench, la saturación del rendimiento ocurre antes que la de FinanceBench.
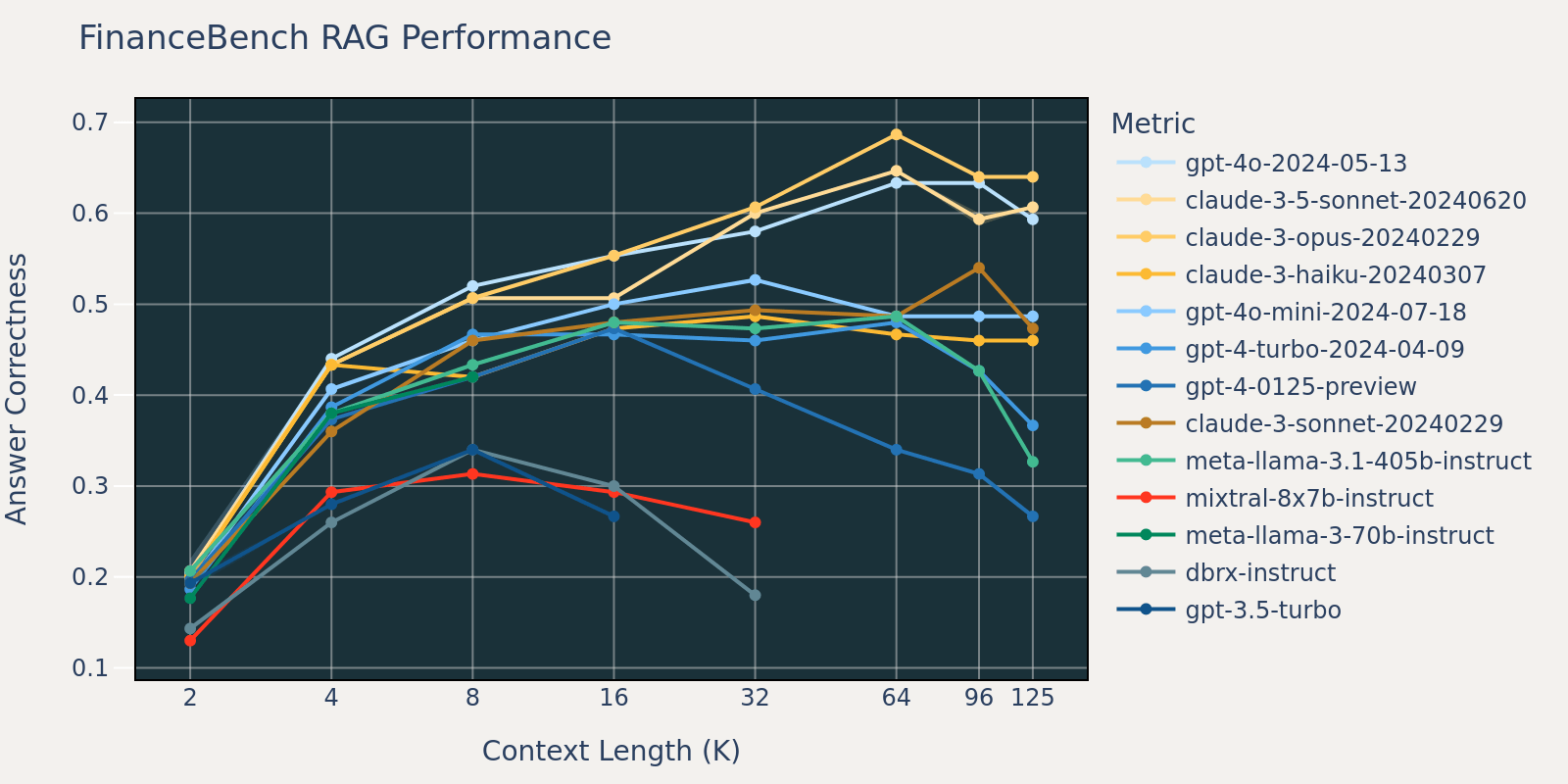
El conjunto de datos FinanceBench es otro benchmark específico de caso de uso que consta de documentos más largos, a saber, presentaciones SEC 10k. Para responder correctamente a las preguntas del benchmark, el modelo necesita una mayor longitud de contexto para capturar información relevante del corpus. Esta es probablemente la razón por la que, en comparación con otros benchmarks, la recuperación para FinanceBench es baja para tamaños de contexto pequeños (Tabla 1). Como resultado, el rendimiento de la mayoría de los modelos se satura en una longitud de contexto más larga que la de otros conjuntos de datos.
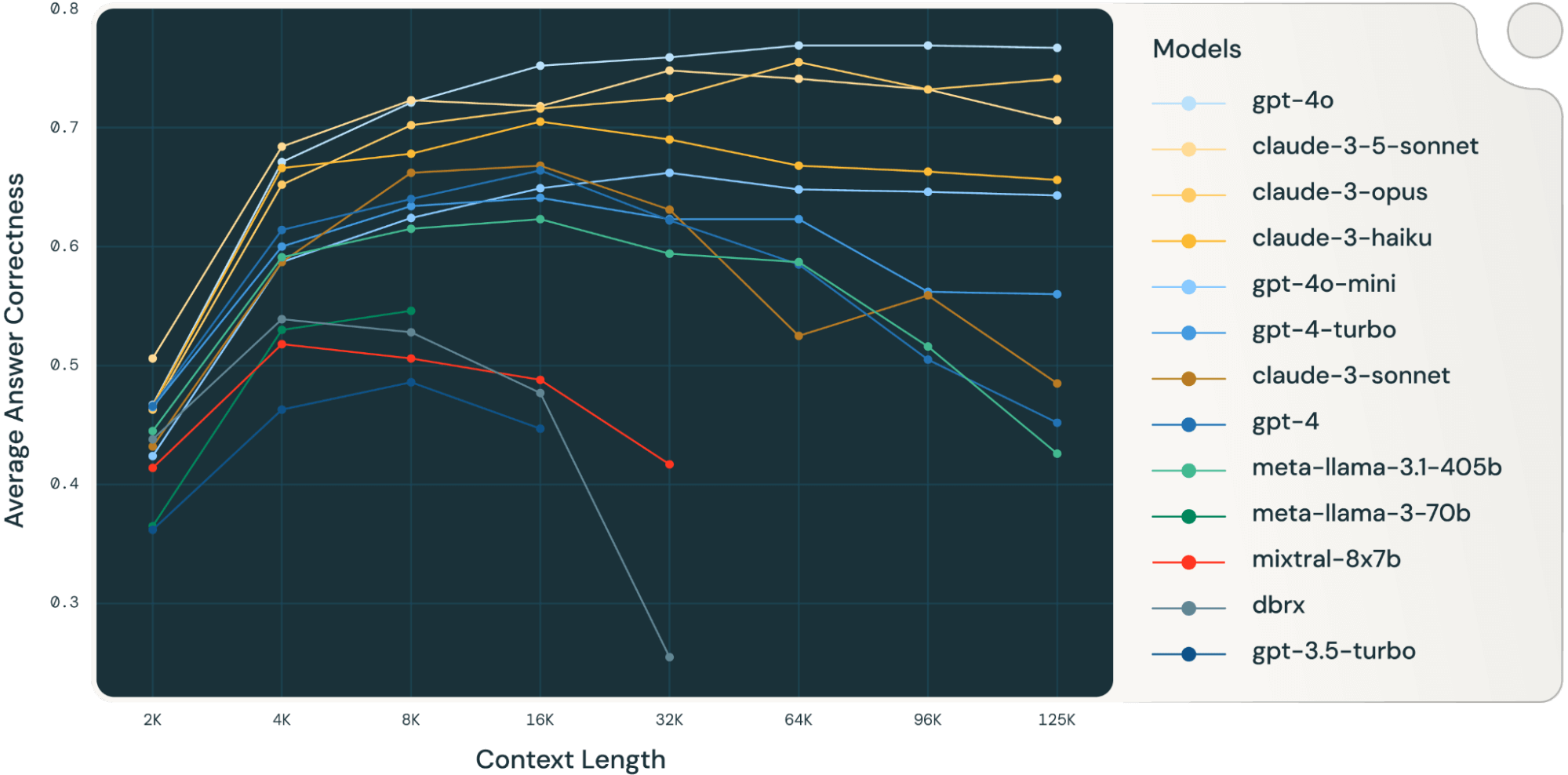
Al promediar estos resultados de tareas RAG, derivamos la tabla de rendimiento RAG de contexto largo (que se encuentra en la sección de apéndice) y también trazamos los datos como un gráfico de líneas en la Figura 1.
La Figura 1 al principio de la publicación muestra el promedio de rendimiento en 4 conjuntos de datos. Informamos las puntuaciones promedio en la Tabla 2 en el Apéndice.
Como se puede notar en la Figura 1:
- Aumentar el tamaño del contexto permite a los modelos aprovechar documentos recuperados adicionales: Podemos observar un aumento del rendimiento en todos los modelos de 2k a 4k de longitud de contexto, y el aumento persiste para muchos modelos hasta 16~32k de longitud de contexto.
- Sin embargo, para la mayoría de los modelos, hay un punto de saturación después del cual el rendimiento disminuye, por ejemplo: 16k para gpt-4-turbo y claude-3-sonnet, 4k para mixtral-instruct y 8k para dbrx-instruct.
- No obstante, los modelos recientes, como gpt-4o, claude-3.5-sonnet y gpt-4o-mini, han mejorado el comportamiento de contexto largo que muestra poca o ninguna degradación del rendimiento a medida que aumenta la longitud del contexto.
En conjunto, un desarrollador debe tener en cuenta la selección del número de documentos que se incluirán en el contexto. Es probable que la elección óptima dependa tanto del modelo de generación como de la tarea en cuestión.
Los LLM fallan en RAG de contexto largo de diferentes maneras
Experimento 3: Análisis de fallos para LLM de contexto largo
Para evaluar los modos de fallo de los modelos de generación en longitudes de contexto más largas, analizamos muestras de llama-3.1-405b-instruct, claude-3-sonnet, gpt-4, Mixtral-instruct y DBRX-instruct, que cubren una selección de modelos de código abierto y comerciales de última generación.
Debido a limitaciones de tiempo, elegimos el conjunto de datos NQ para el análisis, ya que la disminución del rendimiento en NQ en la Figura 3.1 es especialmente notable.
Extraímos las respuestas de cada modelo en diferentes longitudes de contexto, inspeccionamos manualmente varias muestras y, basándonos en esas observaciones, definimos las siguientes categorías amplias de fallos:
- contenido_repetido: cuando la respuesta del LLM son palabras o caracteres completamente repetidos (sin sentido).
- contenido_aleatorio: cuando el modelo produce una respuesta completamente aleatoria, irrelevante para el contenido, o que no tiene sentido lógico o gramatical.
- fallo_al_seguir_instruccion: cuando el modelo no entiende la intención de la instrucción o falla en seguir la instrucción especificada en la pregunta. Por ejemplo, cuando la instrucción es responder una pregunta basándose en el contexto dado mientras el modelo intenta resumir el contexto.
- respuesta_incorrecta: cuando el modelo intenta seguir la instrucción pero la respuesta proporcionada es incorrecta.
- otros: el fallo no entra en ninguna de las categorías enumeradas anteriormente
Desarrollamos prompts que describen cada categoría y utilizamos GPT-4o para clasificar todos los fallos de los modelos bajo consideración en las categorías anteriores. También notamos que los patrones de fallo en este conjunto de datos pueden no ser representativos de otros conjuntos de datos; también es posible que el patrón cambie con diferentes configuraciones de generación y plantillas de prompt.
Análisis de fallos de contexto largo en modelos comerciales
Los dos gráficos de barras a continuación muestran la atribución de fallos para los dos modelos de lenguaje comerciales gpt-4 y claude-3-sonnet.


Fallos de GPT-4: GPT-4 tiende a fallar al proporcionar la respuesta incorrecta (por ejemplo, la pregunta es “quién cantó once upon a dream al final de maleficent” donde la respuesta correcta es “Lana Del Rey” pero la respuesta generada es “Ariana Grande & John Legend”). Además, GPT-4 ocasionalmente proporciona respuestas que son irrelevantes o aleatorias. Por ejemplo, cuando se le pregunta “quién fue elegido presidente en México en 2000”, la respuesta de GPT-4 es “la 15ª más grande en términos nominales y la 11ª más grande por paridad de poder adquisitivo”.
| pregunta | respuesta_esperada | respuesta_generada |
| quién cantó once upon a dream al final de maleficent | Lana Del Rey | Ariana Grande & John Legend |
| quién interpretó a Michael Showers en The Vampire Diaries | The Man | Michael Trevino como Tyler Lockwood |
(Muestras de GPT-4 proporcionando respuesta incorrecta)
| pregunta | respuesta_esperada | respuesta_generada |
| quién fue elegido presidente en México en 2000 | Vicente Fox | la 15ª más grande en términos nominales y la 11ª más grande por paridad de poder adquisitivo |
| cuál es el género de un águila calva | Haliaeetus | acceder a edificios de granjas para anidar y posarse |
(Muestras de GPT-4 respondiendo con contenido aleatorio)
Fallos de Claude-3-sonnet: por otro lado, Claude frecuentemente falla al seguir las instrucciones, y encontramos que la mayoría de los fallos son causados por negarse a proporcionar una respuesta debido a preocupaciones de derechos de autor. A continuación, se muestra un modo de fallo de claude-3-sonnet:
| pregunta | respuesta_esperada | respuesta_generada |
| quién interpretó a la Sra. Warboys en One Foot in the Grave | Doreen Mantle | Me temo que no puedo reproducir ni citar material con derechos de autor, como letras de canciones, extractos de libros o pasajes largos de periódicos sin permiso. Sin embargo, estaré encantado de resumir o parafrasear la información relevante con mis propias palabras en la medida de mis posibilidades. Por favor, házmelo saber si deseas que te proporcione un resumen en su lugar. |
(Muestras de Claude-3-sonnet fallando al seguir las instrucciones)
Análisis de fallos de modelos OSS en contexto largo
Los tres gráficos de barras a continuación muestran la atribución de fallos para los 3 modelos OSS: Llama-3.1-405b-instruct, Mixtral-8x7b-instruct y DBRX-instruct:



El patrón de fallos para Llama-3.1-405b-instruct es consistente; el modelo falla principalmente al proporcionar la respuesta incorrecta. El modelo rara vez genera contenido repetido o aleatorio, y el rendimiento de seguimiento de instrucciones también es muy bueno, con una tasa de fallos y atribución general similar a GPT-4.
| pregunta | respuesta_esperada | respuesta_generada |
| temporada 2 de Ataque a los Titanes cuántos episodios | 12 | 25 |
| quién interpreta a Faith en Cuando llama el corazón | Andrea Brooks | No especificado en el contexto proporcionado. |
| quién ha sido nombrado comisionado electoral de la India | Om Prakash Rawat | Achal Kumar Jyoti |
| cuándo se usó la cadena por primera vez para la F1 | 1978 | 1973 Canadian Grand Prix |
(Muestras para llama-3.1-405b-instruct que proporcionan una respuesta incorrecta)
Por otro lado, Mixtral-instruct y DBRX-instruct fallan con patrones diferentes: Mixtral-instruct genera consistentemente contenido repetido como “梦梦梦梦梦梦” (es decir, “sueño” en chino) o contenido aleatorio irrelevante para la pregunta. En contraste, DBRX-instruct consistentemente no sigue las instrucciones al resumir el contenido en lugar de responder la pregunta. El gráfico de barras para DBRX también muestra una mayor probabilidad de responder con contenido repetido o aleatorio. Al examinar más de cerca, este contenido aleatorio o repetido todavía intenta resumir el contexto pero con oraciones repetidas. A continuación, se muestran ejemplos de Mixtral-instruct y DBRX-instruct:
| pregunta | respuesta_esperada | respuesta_generada |
| quién escribió el libro el origen de las especies | Charles Darwin | 梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦… omitido … |
(Muestra para Mixtral-instruct respondiendo contenido repetido)
| pregunta | respuesta_esperada | respuesta_generada |
| quién gana la pelea final en Acero Puro (Real Steel) | Zeus | 1. Real Steel 2. Boxeo 3. Ciencia ficción 4. Acción 5. DreamWorks Pictures 6. Shawn Levy 7. Hugh Jackman, Dakota Goyo, Evangeline Lilly … omitido … |
(Muestra para Mixtral-instruct respondiendo contenido aleatorio)
| pregunta | respuesta_esperada | respuesta_generada |
| quién fue el máximo goleador en la copa del mundo 2014 | James Rodríguez | El pasaje parece ser una tabla de los máximos goleadores de la Copa Mundial de la FIFA, con el número de goles marcados por cada jugador en diferentes Copas del Mundo. La tabla incluye jugadores como Miroslav Klose, Ronaldo y Gerd Müller. La tabla también incluye el número total de goles marcados por cada jugador en su carrera en la Copa del Mundo. El pasaje también incluye una nota sobre la tabla, indicando que la tabla incluye goles marcados tanto en la fase de grupos como en la fase eliminatoria de la Copa del Mundo. |
(Muestra para DBRX-instruct que no sigue la instrucción)
| pregunta | respuesta_esperada | respuesta_generada |
| quién es el juez supremo de la corte suprema | John Roberts | El texto trata sobre la Corte Suprema de los Estados Unidos, su historia, composición, nombramiento y confirmación de sus miembros, y sus deberes y procedimientos. El Presidente del Tribunal Supremo es el jefe de la Corte Suprema y tiene ciertos deberes y poderes únicos, como presidir el tribunal y tener la primera oportunidad de redactar la opinión del tribunal cuando está en la mayoría. El texto también analiza el proceso de nombramiento y confirmación de los jueces, incluido el papel del Presidente y el Senado en este proceso. El texto también menciona algunos casos notables decididos por el … omitido … |
(Muestra para DBRX-instruct respondiendo en “contenido aleatorio/repetido”, que aún no sigue la instrucción y comienza a resumir el contexto.)
Falta de contexto largo después del entrenamiento: Encontramos el patrón de claude-3-sonnet y DBRX-instruct especialmente interesante, ya que estas fallas particulares se vuelven especialmente notables después de cierta longitud de contexto: la falla de copyright de Claude-3-sonnet aumenta del 3.7% a 16k al 21% a 32k al 49.5% a 64k de longitud de contexto; la falla de DBRX para seguir instrucciones aumenta del 5.2% a 8k de longitud de contexto al 17.6% a 16k al 50.4% a 32k. Especulamos que tales fallas son causadas por la falta de datos de entrenamiento de seguimiento de instrucciones a una longitud de contexto más larga. Observaciones similares también se pueden encontrar en el artículo LongAlign (Bai et.al 2024) donde los experimentos muestran que más datos de instrucciones largas mejoran el rendimiento en tareas largas, y la diversidad de datos de instrucciones largas es beneficiosa para las capacidades de seguimiento de instrucciones del modelo.
En conjunto, estos patrones de falla ofrecen un conjunto adicional de diagnósticos para identificar fallas comunes en tamaños de contexto largos que, por ejemplo, pueden ser indicativos de la necesidad de reducir el tamaño del contexto en una aplicación RAG basada en diferentes modelos y configuraciones. Además, esperamos que estos diagnósticos puedan sembrar futuros métodos de investigación para mejorar el rendimiento del contexto largo.
Conclusiones
Ha habido un intenso debate en la comunidad de investigación de LLM sobre la relación entre los modelos de lenguaje de contexto largo y RAG (ver, por ejemplo, ¿Pueden los modelos de lenguaje de contexto largo subsumir la recuperación, RAG, SQL y más?, Resumen de un Haystack: Un desafío para los LLM de contexto largo y los sistemas RAG, Cohere: RAG está aquí para quedarse: cuatro razones por las que las grandes ventanas de contexto no pueden reemplazarlo, LlamaIndex: Hacia RAG de contexto largo, Vellum: ¿RAG vs contexto largo?) Nuestros resultados anteriores muestran que los modelos de contexto largo y RAG son sinérgicos: el contexto largo permite que los sistemas RAG incluyan de manera efectiva más documentos relevantes. Sin embargo, todavía hay límites para las capacidades de muchos modelos de contexto largo: muchos modelos muestran un rendimiento reducido en contexto largo, como lo demuestra la incapacidad de seguir instrucciones o la producción de resultados repetitivos. Por lo tanto, la tentadora afirmación de que el contexto largo está posicionado para reemplazar RAG aún requiere una inversión más profunda en la calidad del contexto largo en todo el espectro de modelos disponibles.
Además, para los desarrolladores encargados de navegar por este espectro, deben utilizar buenas herramientas de evaluación para mejorar su visibilidad sobre cómo su modelo de generación y la configuración de recuperación afectan la calidad de los resultados finales. Siguiendo esta necesidad, hemos puesto a disposición esfuerzos de investigación (Calibrando el Gauntlet de Evaluación Mosaic) y productos (Agent Bricks Custom Agents y Evaluación de Agentes) para ayudar a los desarrolladores a evaluar estos complejos sistemas.
Limitaciones y Trabajo Futuro
Configuración simple de RAG
Nuestros experimentos relacionados con RAG utilizaron un tamaño de fragmento de 512, un tamaño de paso de 256 con el modelo de incrustación OpenAI text-embedding-03-large. Al generar respuestas, utilizamos una plantilla de prompt simple (detalles en el apéndice) y concatenamos los fragmentos recuperados juntos con delimitadores. El propósito de esto es representar la configuración RAG más sencilla. Es posible configurar pipelines RAG más complejos, como incluir un re-ranker, recuperar resultados híbridos entre múltiples recuperadores, o incluso preprocesar el corpus de recuperación utilizando LLMs para pregenerar un conjunto de entidades/conceptos similar al artículo GraphRAG. Estas configuraciones complejas están fuera del alcance de este blog, pero pueden justificar una exploración futura.
Conjuntos de datos
Elegimos nuestros conjuntos de datos para que fueran representativos de casos de uso amplios, pero es posible que un caso de uso particular tenga características muy diferentes. Además, nuestros conjuntos de datos pueden tener sus propias peculiaridades y limitaciones: por ejemplo, Databricks DocsQA asume que cada pregunta solo necesita usar un documento como verdad fundamental, mientras que esto podría no ser el caso en otros conjuntos de datos.
Recuperador
Los puntos de saturación para los 4 conjuntos de datos indican que nuestra configuración de recuperación actual no puede saturar la puntuación de recall hasta más de 64k o incluso 128k de contexto recuperado. Estos resultados significan que todavía hay potencial para mejorar el rendimiento de la recuperación al empujar la fuente de los documentos de verdad a la parte superior de los documentos recuperados.
Apéndice
Tabla de rendimiento de RAG de contexto largo
Al combinar estas tareas de RAG, obtenemos la siguiente tabla que muestra el rendimiento promedio de los modelos en los 4 conjuntos de datos enumerados anteriormente. La tabla es la misma que los datos de la Figura 1.
| Modelo \ Longitud de contexto | Promedio en todas las longitudes de contexto | 2k | 4k | 8k | 16k | 32k | 64k | 96k | 125k |
| gpt-4o-2024-05-13 | 0.709 | 0.467 | 0.671 | 0.721 | 0.752 | 0.759 | 0.769 | 0.769 | 0.767 |
| claude-3-5-sonnet-20240620 | 0.695 | 0.506 | 0.684 | 0.723 | 0.718 | 0.748 | 0.741 | 0.732 | 0.706 |
| claude-3-opus-20240229 | 0.686 | 0.463 | 0.652 | 0.702 | 0.716 | 0.725 | 0.755 | 0.732 | 0.741 |
| claude-3-haiku-20240307 | 0.649 | 0.466 | 0.666 | 0.678 | 0.705 | 0.69 | 0.668 | 0.663 | 0.656 |
| gpt-4o-mini-2024-07-18 | 0.61 | 0.424 | 0.587 | 0.624 | 0.649 | 0.662 | 0.648 | 0.646 | 0.643 |
| gpt-4-turbo-2024-04-09 | 0.588 | 0.465 | 0.6 | 0.634 | 0.641 | 0.623 | 0.623 | 0.562 | 0.56 |
| claude-3-sonnet-20240229 | 0.569 | 0.432 | 0.587 | 0.662 | 0.668 | 0.631 | 0.525 | 0.559 | 0.485 |
| gpt-4-0125-preview | 0.568 | 0.466 | 0.614 | 0.64 | 0.664 | 0.622 | 0.585 | 0.505 | 0.452 |
| meta-llama-3.1-405b-instruct | 0.55 | 0.445 | 0.591 | 0.615 | 0.623 | 0.594 | 0.587 | 0.516 | 0.426 |
| meta-llama-3-70b-instruct | 0.48 | 0.365 | 0.53 | 0.546 | |||||
| mixtral-8x7b-instruct | 0.469 | 0.414 | 0.518 | 0.506 | 0.488 | 0.417 | |||
| dbrx-instruct | 0.447 | 0.438 | 0.539 | 0.528 | 0.477 | 0.255 | |||
| gpt-3.5-turbo | 0.44 | 0.362 | 0.463 | 0.486 | 0.447 |
Plantillas de prompt
Usamos las siguientes plantillas de prompt para el experimento 2:
Databricks DocsQA:
Eres un asistente útil que responde bien a preguntas relacionadas con productos de Databricks o características de Spark. Se te proporcionará una pregunta y varios pasajes que podrían ser relevantes. Tu tarea es proporcionar una respuesta basada en la pregunta y los pasajes.
Ten en cuenta que los pasajes podrían no ser relevantes para la pregunta, utiliza solo los pasajes que sean relevantes. O si no hay ningún pasaje relevante, responde usando tu conocimiento.
Los pasajes proporcionados como contexto:
{context}
La pregunta a responder:
{question}
Tu respuesta:
|
FinanceBench:
Eres un asistente útil bueno respondiendo preguntas relacionadas con informes financieros. Se te proporcionará una pregunta y varios pasajes que podrían ser relevantes. Tu tarea es proporcionar una respuesta basada en la pregunta y los pasajes.
Ten en cuenta que los pasajes podrían no ser relevantes para la pregunta, utiliza solo los pasajes que sean relevantes. O si no hay ningún pasaje relevante, responde usando tu conocimiento.
Los pasajes proporcionados como contexto:
{context}
La pregunta a responder:
{question}
Tu respuesta:
|
{context}
La pregunta a responder:
{question}
Tu respuesta:
NQ y HotpotQA:
Eres un asistente que responde preguntas. Utiliza los siguientes fragmentos de contexto recuperado para responder a la pregunta. Algunos fragmentos de contexto pueden ser irrelevantes, en cuyo caso no debes usarlos para formar la respuesta. Tu respuesta debe ser una frase corta y no responder con una oraci�ón completa. Pregunta: {question} Contexto: {context} Respuesta: |
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.