Conozca a KARL: un agente más rápido para el conocimiento empresarial, impulsado por RL personalizado
Aprendizaje por refuerzo para agentes empresariales
Para ver el informe técnico completo, haga clic aquí. ¿Le interesa probar el RL personalizado de Databricks en su agente empresarial? Haga clic aquí.
La mejora en las capacidades de razonamiento de los modelos actuales ha provocado una explosión de agentes implementados para el trabajo de conocimiento, como escribir código, hacer preguntas sobre datos empresariales y automatizar flujos de trabajo comunes. Si bien los modelos utilizados en tareas empresariales son muy potentes, también son extremadamente costosos, y los costos de inferencia han comenzado a crecer de forma insostenible para muchos casos de uso. En esta publicación y en el informe técnico correspondiente, describimos nuestra experiencia utilizando el aprendizaje por refuerzo (RL) para crear modelos personalizados que impulsen casos de uso que son una parte clave de nuestro producto Agent Bricks. Este ejemplo demuestra que, por costos relativamente bajos, es posible crear modelos personalizados que superan ampliamente a los modelos de vanguardia en las tres dimensiones críticas: costo de inferencia, latencia y calidad. Nuestros hallazgos son consistentes con otras observaciones de la industria, como el modelo Composer de Cursor, donde la personalización basada en RL logró mejorar drásticamente tanto la velocidad como la calidad en comparación con otras alternativas.
KARL: un agente de conocimiento más rápido, potente y económico para los usuarios de Databricks
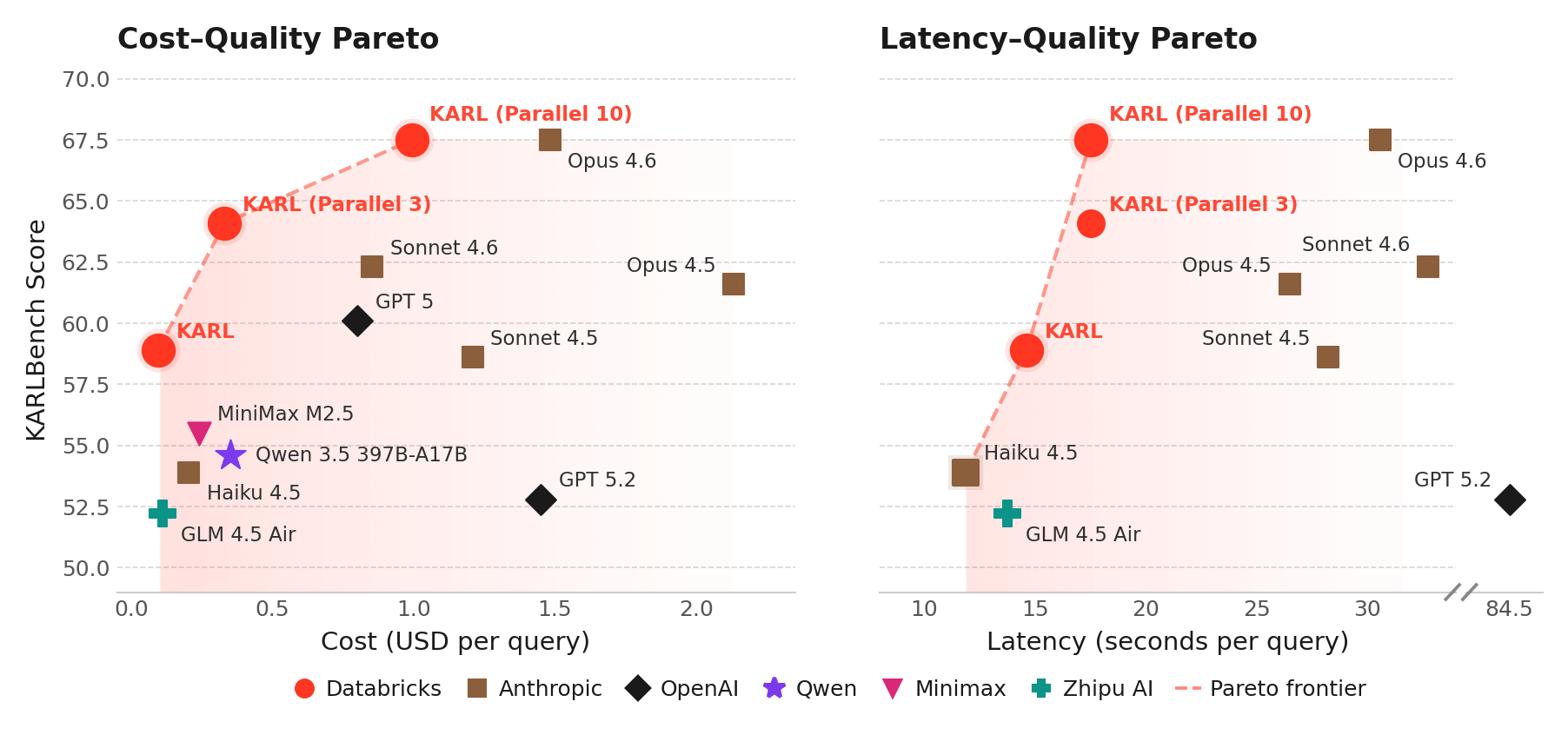
El modelo que entrenamos, al que llamamos KARL, aborda una capacidad empresarial fundamental: el razonamiento fundamentado, que consiste en responder preguntas buscando documentos, encontrando hechos, haciendo referencias cruzadas de información y razonando a lo largo de docenas o cientos de pasos. El razonamiento fundamentado es necesario para varios productos de Databricks, como Agent Bricks Knowledge Assistant. A diferencia de las matemáticas y la codificación, las tareas de razonamiento fundamentado son difíciles de verificar; a menudo no hay una única respuesta correcta. En situaciones como esta, guiar el aprendizaje por refuerzo hacia una buena solución es especialmente difícil.
Utilizando RL, técnicas e infraestructura desarrolladas en Databricks, KARL iguala el rendimiento de los modelos propietarios más potentes del mundo a una fracción del costo de servicio y la latencia, incluso en nuevas tareas de razonamiento fundamentado que nunca había visto. (Consulte el informe técnico para obtener todos los detalles). Logramos esto con solo unos pocos miles de horas de GPU de entrenamiento y datos totalmente sintéticos.
En pruebas internas con usuarios humanos, KARL proporcionó respuestas mejores y más completas que nuestros productos existentes y los modelos de frontera más recientes. Esta investigación se está incorporando a los agentes de Databricks que utiliza hoy en día, como Agent Bricks, para fundamentar las respuestas en sus datos no estructurados y estructurados en Databricks Lakehouse.
Un pipeline de RL reutilizable para los clientes de Databricks
Nos complace anunciar que los mismos pipelines e infraestructura de RL que utilizamos para crear KARL (y otros agentes de los que hablaremos pronto) ya están disponibles para los clientes de Databricks que buscan mejorar el rendimiento de los modelos y reducir los costos para sus cargas de trabajo agénticas de alto volumen. Casi todas las tareas empresariales del mundo real son difíciles de verificar, por lo que KARL allana el camino, no solo para una mejor experiencia para los usuarios de Databricks, sino también para que nuestros clientes creen sus propios modelos de RL personalizados para sus agentes más populares. Nuestra vista previa privada de Custom RL, respaldada por AI Runtime, le permite utilizar la infraestructura de KARL para crear una versión más eficiente y específica del dominio de su agente. Si tiene un agente de IA que está escalando rápidamente y está interesado en optimizarlo con RL, regístrese aquí para expresar su interés en esta vista previa.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.