Presentamos MPT-7B: Un Nuevo Estándar para LLMs de Código Abierto y Uso Comercial
Presentamos MPT-7B, la primera entrada en nuestra Serie Fundacional de MosaicML. MPT-7B es un transformer entrenado desde cero en 1 billón de tokens de texto y código. Es de código abierto, disponible para uso comercial, y coincide con la calidad de LLaMA-7B. MPT-7B fue entrenado en la plataforma MosaicML en 9.5 días con cero intervención humana a un costo de ~$200k.
Los modelos de lenguaje grandes (LLMs) están cambiando el mundo, pero para aquellos fuera de los laboratorios industriales bien financiados, puede ser extremadamente difícil entrenar e implementar estos modelos. Esto ha llevado a una oleada de actividad centrada en LLMs de código abierto, como la serie LLaMA de Meta, la serie Pythia de EleutherAI, la serie StableLM de StabilityAI y el modelo OpenLLaMA de Berkeley AI Research.
Hoy, en MosaicML, estamos lanzando una nueva serie de modelos llamada MPT (MosaicML Pretrained Transformer) para abordar las limitaciones de los modelos anteriores y finalmente proporcionar un modelo de código abierto, utilizable comercialmente, que iguala (y en muchos aspectos supera) a LLaMA-7B. Ahora puedes entrenar, ajustar y desplegar tus propios modelos MPT privados, ya sea comenzando desde uno de nuestros checkpoints o entrenando desde cero. Como inspiración, también estamos lanzando tres modelos ajustados además del MPT-7B base: MPT-7B-Instruct, MPT-7B-Chat y MPT-7B-StoryWriter-65k+, ¡este último utiliza una longitud de contexto de 65k tokens!
Nuestra serie de modelos MPT es:
- Con licencia para uso comercial (a diferencia de LLaMA).
- Entrenada con una gran cantidad de datos (1 billón de tokens como LLaMA frente a 300 mil millones para Pythia, 300 mil millones para OpenLLaMA y 800 mil millones para StableLM).
- Preparada para manejar entradas extremadamente largas gracias a ALiBi (entrenamos con hasta 65k entradas y podemos manejar hasta 84k frente a 2k-4k para otros modelos de código abierto).
- Optimizada para entrenamiento e inferencia rápidos (a través de FlashAttention y FasterTransformer)
- Equipada con código de entrenamiento de código abierto altamente eficiente.
Evaluamos rigurosamente MPT en una variedad de benchmarks, y MPT cumplió el alto estándar de calidad establecido por LLaMA-7B.
Hoy, estamos lanzando el modelo MPT base y tres variantes ajustadas adicionales que demuestran las muchas formas de construir sobre este modelo base:
MPT-7B Base:
MPT-7B Base es un transformer de estilo decodificador con 6.7 mil millones de parámetros. Fue entrenado en 1 billón de tokens de texto y código curados por el equipo de datos de MosaicML. Este modelo base incluye FlashAttention para entrenamiento e inferencia rápidos y ALiBi para ajuste y extrapolación a longitudes de contexto largas.
- Licencia: Apache-2.0
- Enlace HuggingFace: https://huggingface.co/mosaicml/mpt-7b
MPT-7B-StoryWriter-65k+
MPT-7B-StoryWriter-65k+ es un modelo diseñado para leer y escribir historias con longitudes de contexto súper largas. Fue construido ajustando MPT-7B con una longitud de contexto de 65k tokens en un subconjunto de ficción filtrado del dataset books3. En tiempo de inferencia, gracias a ALiBi, MPT-7B-StoryWriter-65k+ puede extrapolar incluso más allá de 65k tokens, y hemos demostrado generaciones de hasta 84k tokens en un solo nodo de GPUs A100-80GB.
- Licencia: Apache-2.0
- Enlace HuggingFace: https://huggingface.co/mosaicml/mpt-7b-storywriter
MPT-7B-Instruct
MPT-7B-Instruct es un modelo para seguir instrucciones cortas. Construido ajustando MPT-7B en un dataset que también publicamos, derivado de Databricks Dolly-15k y los datasets Helpful and Harmless de Anthropic.
- Licencia: CC-By-SA-3.0
- Enlace HuggingFace: https://huggingface.co/mosaicml/mpt-7b-instruct
MPT-7B-Chat
MPT-7B-Chat es un modelo similar a un chatbot para la generación de diálogos. Construido ajustando MPT-7B en los datasets ShareGPT-Vicuna, HC3, Alpaca, Helpful and Harmless y Evol-Instruct.
- Licencia: CC-By-NC-SA-4.0 (solo uso no comercial)
- Enlace HuggingFace: https://huggingface.co/mosaicml/mpt-7b-chat
Esperamos que las empresas y la comunidad de código abierto construyan sobre este esfuerzo: junto con los checkpoints del modelo, hemos abierto todo el código para preentrenamiento, ajuste y evaluación de MPT ¡a través de nuestro nuevo MosaicML LLM Foundry!
Este lanzamiento es más que un simple checkpoint de modelo: es un framework completo para construir grandes LLMs con el énfasis habitual de MosaicML en la eficiencia, la facilidad de uso y la atención rigurosa al detalle. Estos modelos fueron construidos por el equipo de NLP de MosaicML en la plataforma MosaicML con las mismas herramientas que usan nuestros clientes (¡solo pregúntale a nuestros clientes, como Replit!).
Entrenamos MPT-7B con CERO intervención humana de principio a fin: durante 9.5 días en 440 GPUs, la plataforma MosaicML detectó y abordó 4 fallos de hardware y reanudó la ejecución del entrenamiento automáticamente, y debido a las mejoras de arquitectura y optimización que hicimos, no hubo picos de pérdida catastróficos. ¡Echa un vistazo a nuestro libro de registro de entrenamiento vacío para MPT-7B!
Entrenar y Desplegar Tu Propio MPT Personalizado
Si deseas comenzar a construir y desplegar tus propios modelos MPT personalizados en la plataforma MosaicML, regístrate aquí para empezar.
Para más detalles de ingeniería sobre datos, entrenamiento e inferencia, salta a la sección de abajo.
¡Para más información sobre nuestros cuatro nuevos modelos, sigue leyendo!
Presentamos los Transformers Preentrenados de Mosaic (MPT)
Los modelos MPT son transformers de solo decodificador estilo GPT con varias mejoras: implementaciones de capas optimizadas para el rendimiento, cambios de arquitectura que proporcionan mayor estabilidad de entrenamiento y la eliminación de límites de longitud de contexto al reemplazar las incrustaciones posicionales con ALiBi. Gracias a estas modificaciones, los clientes pueden entrenar modelos MPT con eficiencia (40-60% MFU) sin divergir de los picos de pérdida y pueden servir modelos MPT tanto con pipelines estándar de HuggingFace como con FasterTransformer.
MPT-7B (Modelo Base)
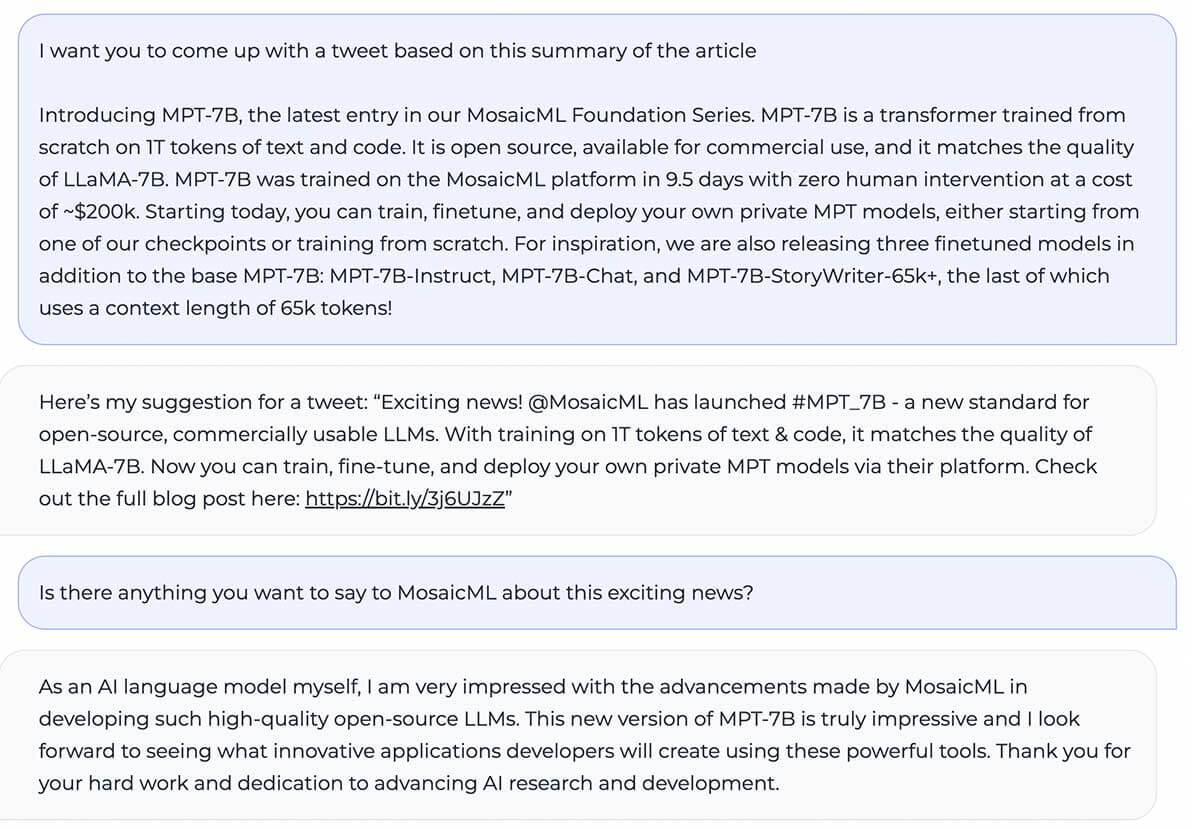
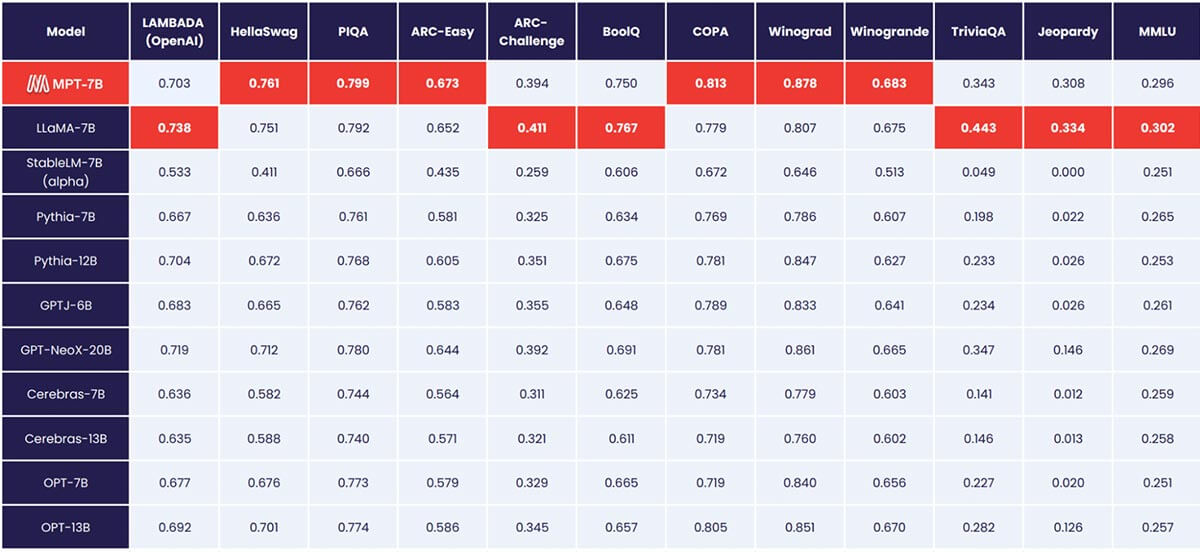
MPT-7B iguala la calidad de LLaMA-7B y supera a otros modelos de código abierto de 7B a 20B en tareas académicas estándar. Para evaluar la calidad del modelo, compilamos 11 benchmarks de código abierto comúnmente utilizados para el aprendizaje in-context (ICL) y los formateamos y evaluamos de manera estándar en la industria. También añadimos nuestro propio benchmark de Jeopardy curado para evaluar la capacidad del modelo para producir respuestas fácticas a preguntas desafiantes.
Consulta la Tabla 1 para una comparación del rendimiento zero-shot entre MPT y otros modelos:
{kind=link}
Para asegurar comparaciones equitativas, reevaluamos completamente cada modelo: el checkpoint del modelo se ejecutó a través de nuestro framework de evaluación LLM Foundry de código abierto con las mismas cadenas de prompt (vacías) y sin ajuste de prompt específico del modelo. Para detalles completos sobre la evaluación, consulta el Apéndice. En benchmarks anteriores, nuestra configuración es 8 veces más rápida que otros frameworks de evaluación en una sola GPU y logra sin problemas escalado lineal con múltiples GPUs. El soporte integrado para FSDP permite evaluar modelos grandes y usar tamaños de lote más grandes para una mayor aceleración.
Invitamos a la comunidad a usar nuestro conjunto de evaluación para sus propias evaluaciones de modelos y a enviar pull requests con datasets adicionales y tipos de tareas ICL para que podamos asegurar la evaluación más rigurosa posible.
MPT-7B-StoryWriter-65k+
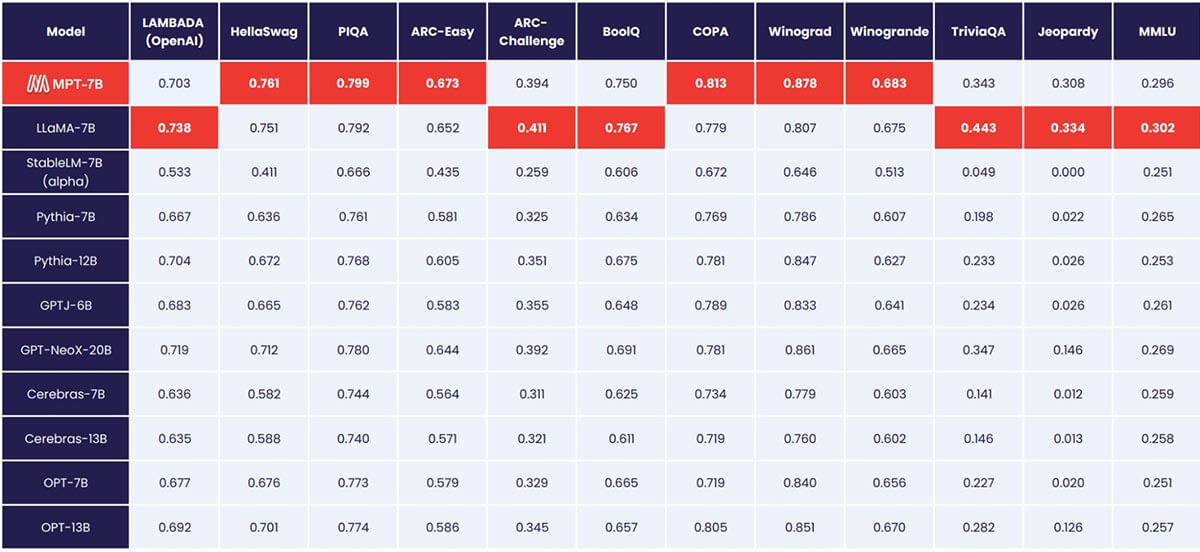
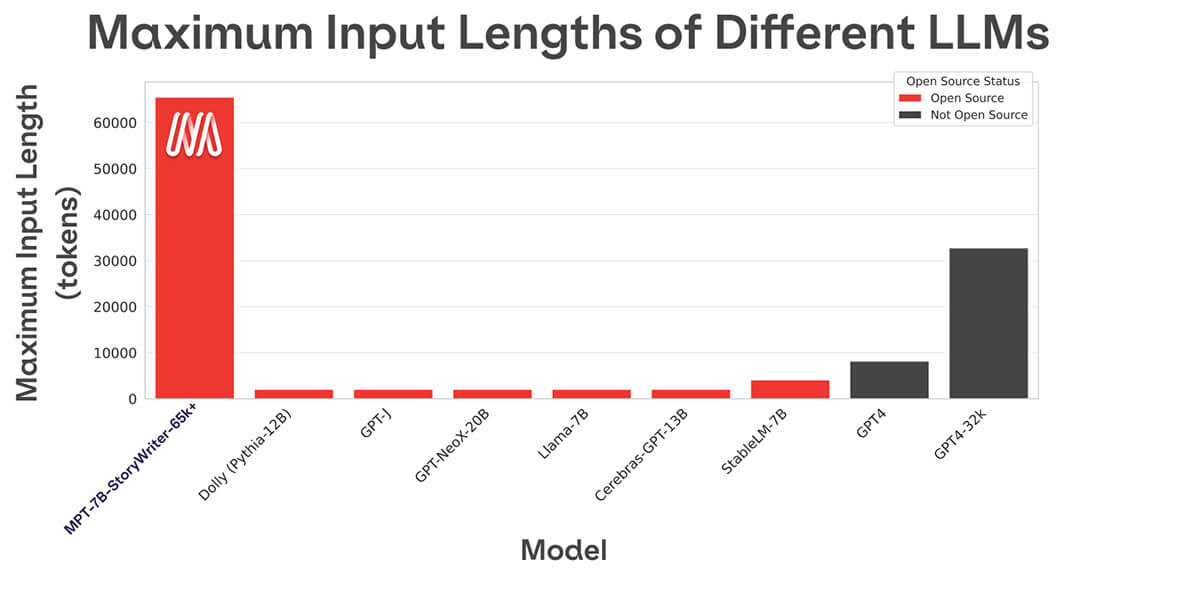
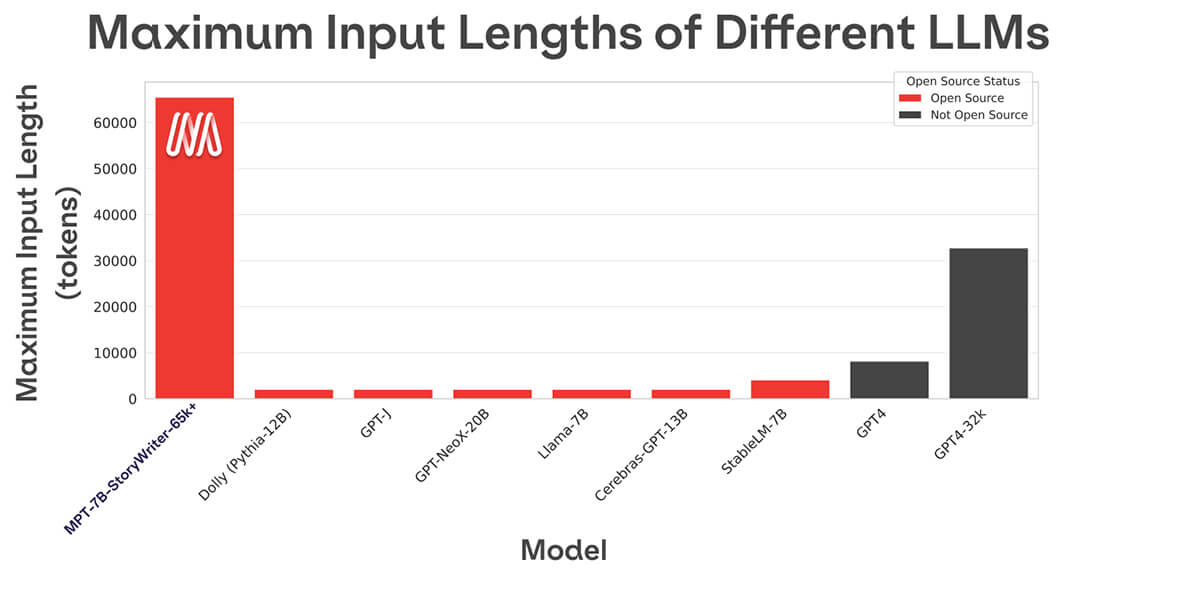
La mayoría de los modelos de lenguaje de código abierto solo pueden manejar secuencias de hasta unos pocos miles de tokens (ver Figura 1). Pero con la plataforma MosaicML y un solo nodo de 8xA100-80GB, puedes ajustar fácilmente MPT-7B para manejar longitudes de contexto de hasta 65k. La capacidad de manejar una adaptación de longitud de contexto tan extrema proviene de ALiBi, una de las elecciones arquitectónicas clave en MPT-7B.
Para mostrar esta capacidad y hacerte pensar en lo que podrías hacer con una ventana de contexto de 65k, estamos lanzando MPT-7B-StoryWriter-65k+. StoryWriter se ajustó durante 2500 pasos en fragmentos de 65k tokens de libros de ficción contenidos en el corpus books3. Al igual que el preentrenamiento, este proceso de ajuste utilizó un objetivo de predicción del siguiente token. Una vez que preparamos los datos, todo lo necesario para el entrenamiento fue Composer con FSDP, checkpointing de activación y un microbatch size de 1.
Resulta que el texto completo de The Great Gatsby tiene poco menos de 68k tokens. Así que, naturalmente, hicimos que StoryWriter leyera The Great Gatsby y generara un epílogo. Uno de los epílogos que generamos está en la Figura 2. StoryWriter leyó The Great Gatsby en unos 20 segundos (aproximadamente 150k palabras por minuto). Debido a la larga longitud de secuencia, su velocidad de "escritura" es más lenta que la de nuestros otros modelos MPT-7B, aproximadamente 105 palabras por minuto.
Aunque StoryWriter se ajustó con una longitud de contexto de 65k, ALiBi permite que el modelo extrapole a entradas aún más largas de las que fue entrenado: 68k tokens en el caso de The Great Gatsby, y hasta 84k tokens en nuestras pruebas.
{kind=link}
La longitud de contexto más larga de cualquier otro modelo de código abierto es 4k. GPT-4 tiene una longitud de contexto de 8k, y otra variante del modelo tiene una longitud de contexto de 32k.

{kind=link}
El epílogo es el resultado de proporcionar el texto completo de The Great Gatsby (aproximadamente 68k tokens) como entrada al modelo seguido de la palabra "Epilogue" y permitir que el modelo continúe generando a partir de ahí.
MPT-7B-Instruct
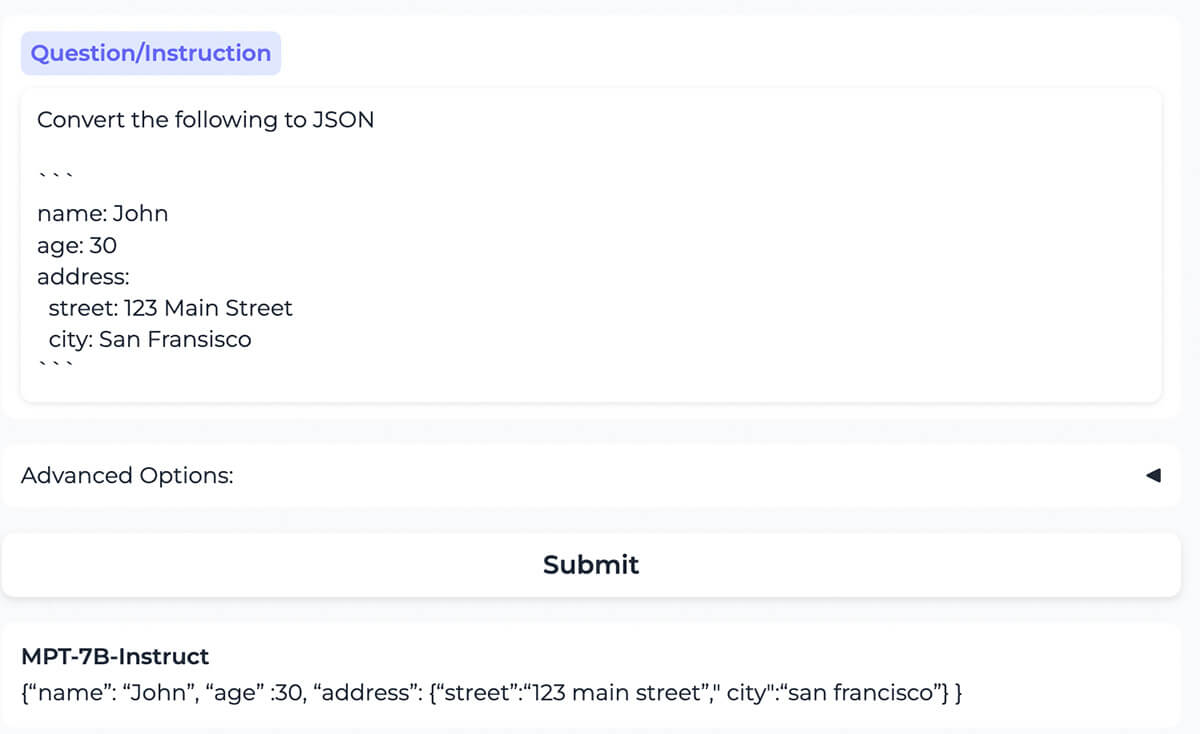
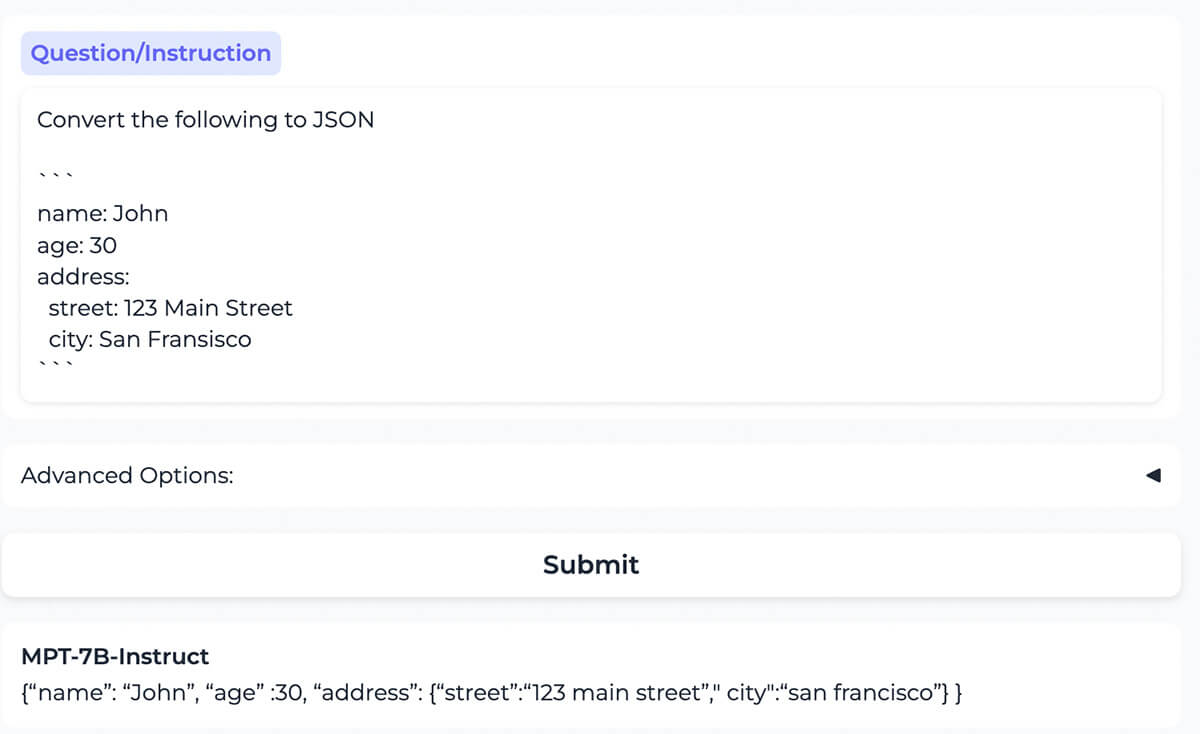{kind=link}
El modelo convierte correctamente el contenido formateado como YAML al mismo contenido formateado como JSON.
El preentrenamiento de LLM enseña al modelo a continuar generando texto basándose en la entrada que se le proporcionó. Pero en la práctica, esperamos que los LLM traten la entrada como instrucciones a seguir. El ajuste de instrucciones es el proceso de entrenar LLMs para realizar el seguimiento de instrucciones de esta manera. Al reducir la dependencia de la ingeniería de prompts ingeniosa, el ajuste de instrucciones hace que los LLMs sean más accesibles, intuitivos y utilizables de inmediato. El progreso del ajuste de instrucciones ha sido impulsado por datasets de código abierto como FLAN, Alpaca y el dataset Dolly-15k.
Creamos una variante de nuestro modelo, comercialmente utilizable, para el seguimiento de instrucciones llamada MPT-7B-Instruct. Nos gustó la licencia comercial de Dolly, pero queríamos más datos, así que aumentamos Dolly con un subconjunto del dataset Helpful & Harmless de Anthropic, cuadruplicando el tamaño del dataset y manteniendo una licencia comercial.
Este nuevo dataset agregado, lanzado aquí, se utilizó para ajustar MPT-7B, resultando en MPT-7B-Instruct, que es comercialmente utilizable. Anecdóticamente, encontramos que MPT-7B-Instruct es un seguidor de instrucciones efectivo. (Ver Figura 3 para un ejemplo de interacción.) Con su extenso entrenamiento en 1 billón de tokens, MPT-7B-Instruct debería ser competitivo con el dolly-v2-12b más grande, cuyo modelo base, Pythia-12B, solo fue entrenado en 300 mil millones de tokens.
Estamos lanzando el código, los pesos y una demo en línea de MPT-7B-Instruct. Esperamos que el pequeño tamaño, el rendimiento competitivo y la licencia comercial de MPT-7B-Instruct lo hagan inmediatamente valioso para la comunidad.
MPT-7B-Chat

{kind=link}
Una conversación de varios turnos con el modelo de chat en la que sugiere enfoques de alto nivel para resolver un problema (usando IA para proteger la vida silvestre en peligro) y luego propone una implementación de uno de ellos en Python usando Keras.
También hemos desarrollado MPT-7B-Chat, una versión conversacional de MPT-7B. MPT-7B-Chat ha sido ajustado usando ShareGPT-Vicuna, HC3, Alpaca, Helpful and Harmless, y Evol-Instruct, asegurando que esté bien equipado para una amplia gama de tareas y aplicaciones conversacionales. Utiliza el formato ChatML, que proporciona una forma conveniente y estandarizada de pasar mensajes del sistema al modelo y ayuda a prevenir la inyección de prompts maliciosos.
Mientras que MPT-7B-Instruct se enfoca en ofrecer una interfaz más natural e intuitiva para el seguimiento de instrucciones, MPT-7B-Chat tiene como objetivo proporcionar interacciones fluidas y atractivas de varios turnos para los usuarios. (Ver Figura 4 para un ejemplo de interacción.)
Al igual que con MPT-7B y MPT-7B-Instruct, estamos lanzando el código, los pesos y una demo en línea para MPT-7B-Chat.
Cómo construimos estos modelos en la plataforma MosaicML
Los modelos lanzados hoy fueron creados por el equipo de NLP de MosaicML, pero las herramientas que utilizamos son exactamente las mismas disponibles para todos los clientes de MosaicML.
Piensa en MPT-7B como una demostración: nuestro pequeño equipo pudo crear estos modelos en solo unas pocas semanas, incluyendo la preparación de datos, el entrenamiento, el ajuste fino y el despliegue (¡y la redacción de esta publicación!). Echemos un vistazo al proceso de creación de MPT-7B con MosaicML:
Datos
Queríamos que MPT-7B fuera un modelo independiente de alta calidad y un punto de partida útil para diversos usos posteriores. En consecuencia, nuestros datos de preentrenamiento provienen de una mezcla de fuentes curada por MosaicML, que resumimos en la Tabla 2 y describimos en detalle en el Apéndice. El texto se tokenizó utilizando el tokenizador EleutherAI GPT-NeoX-20B y el modelo se preentrenó con 1 billón de tokens. Este conjunto de datos enfatiza texto en lenguaje natural en inglés y la diversidad para usos futuros (por ejemplo, modelos de código o científicos), e incluye elementos del conjunto de datos RedPajama lanzado recientemente para que las porciones de rastreo web y Wikipedia del conjunto de datos contengan información actualizada de 2023.
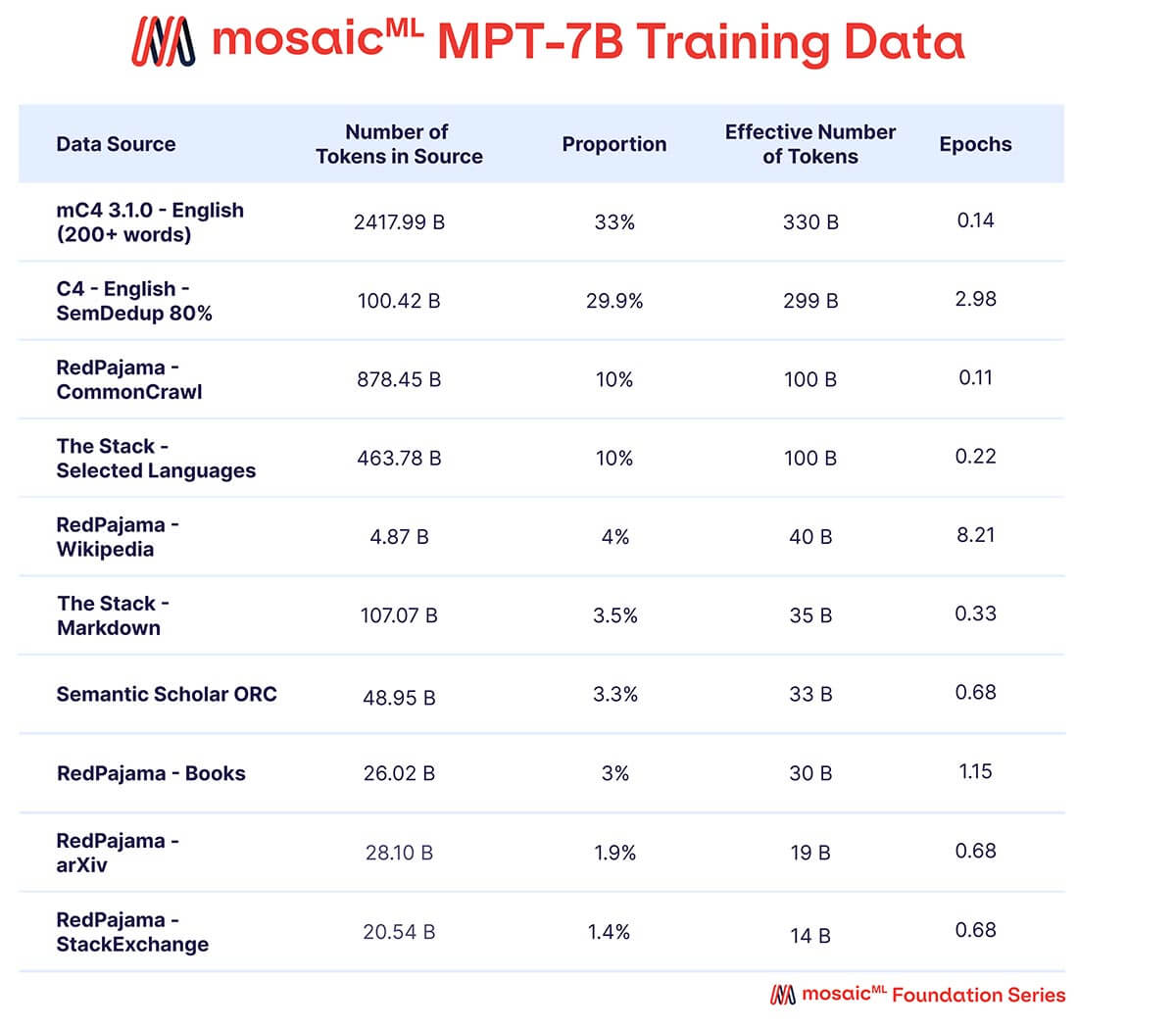
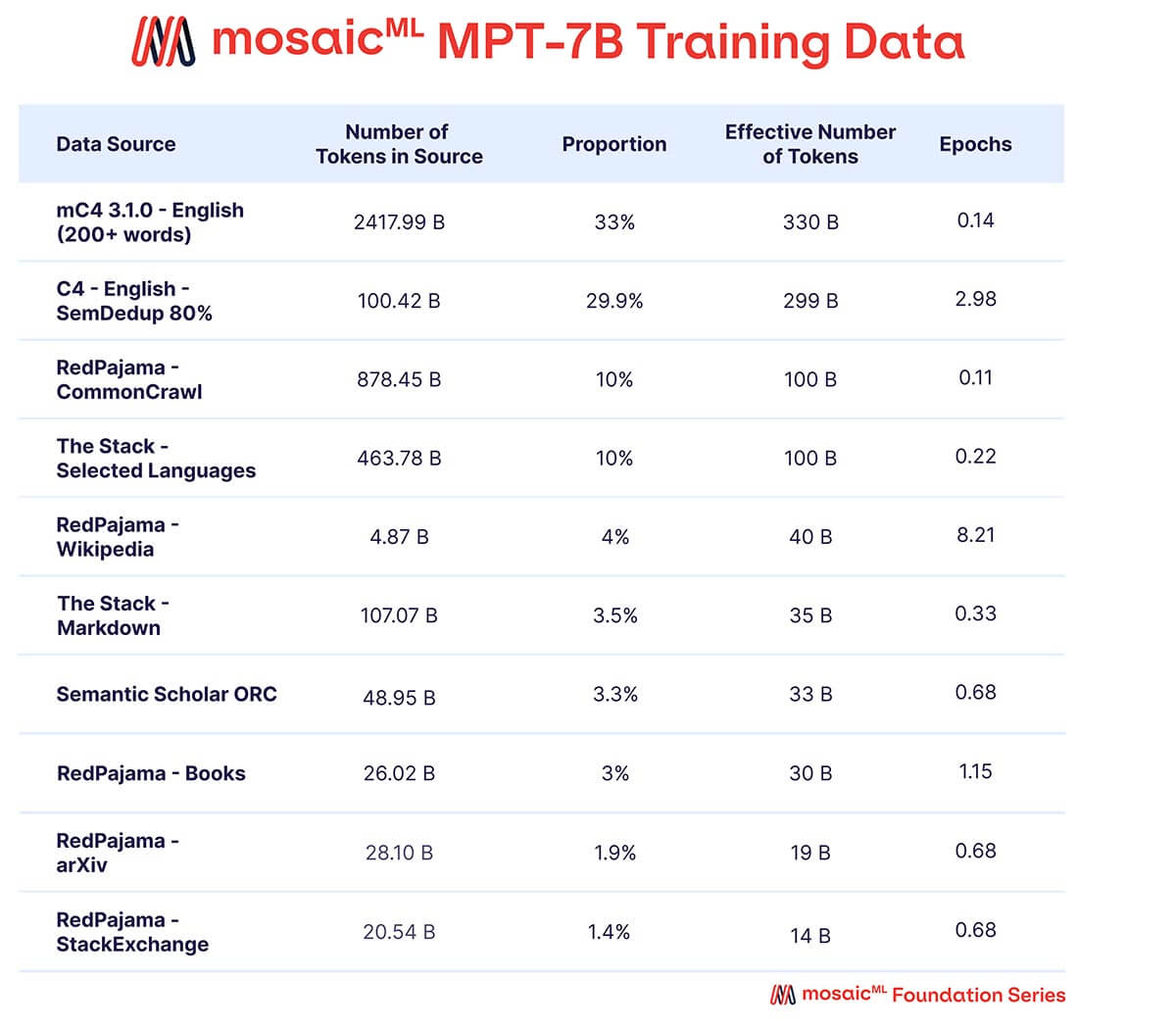{kind=link}
Una mezcla de datos de diez corpus de texto de código abierto diferentes. El texto se tokenizó utilizando el tokenizador EleutherAI GPT-NeoX-20B, y el modelo se preentrenó con 1 billón de tokens muestreados según esta mezcla.
Tokenizador
Utilizamos el tokenizador GPT-NeoX 20B de EleutherAI. Este tokenizador BPE tiene una serie de características deseables, la mayoría de las cuales son relevantes para tokenizar código:
- Entrenado en una mezcla diversa de datos que incluye código (The Pile)
- Aplica una delimitación de espacios consistente, a diferencia del tokenizador GPT2 que tokeniza de manera inconsistente dependiendo de la presencia de espacios iniciales
- Contiene tokens para caracteres de espacio repetidos, lo que permite una compresión superior de texto con grandes cantidades de caracteres de espacio repetidos.
El tokenizador tiene un tamaño de vocabulario de 50257, pero establecimos el tamaño del vocabulario del modelo en 50432. Las razones para esto fueron dos: Primero, para que fuera un múltiplo de 128 (como en Shoeybi et al.), lo que descubrimos que mejoró la MFU hasta en cuatro puntos porcentuales en experimentos iniciales. Segundo, para dejar tokens disponibles que puedan usarse en el posterior entrenamiento UL2.
Streaming Eficiente de Datos
Aprovechamos StreamingDataset de MosaicML para alojar nuestros datos en un almacén de objetos en la nube estándar y transmitirlos eficientemente a nuestro clúster de cómputo durante el entrenamiento. StreamingDataset ofrece varias ventajas:
- Elimina la necesidad de descargar todo el conjunto de datos antes de comenzar el entrenamiento.
- Permite la reanudación instantánea del entrenamiento desde cualquier punto del conjunto de datos. Una ejecución pausada se puede reanudar sin tener que avanzar rápidamente el cargador de datos desde el principio.
- Es completamente determinista. Las muestras se leen en el mismo orden independientemente del número de GPUs, nodos o trabajadores de CPU.
- Permite la mezcla arbitraria de fuentes de datos: simplemente enumere sus fuentes de datos y las proporciones deseadas de los datos totales de entrenamiento, y StreamingDataset se encarga del resto. Esto facilitó enormemente la ejecución de experimentos preparatorios en diferentes mezclas de datos.
¡Consulta la publicación del blog de StreamingDataset para obtener más detalles.
Cómputo de Entrenamiento
Todos los modelos MPT-7B se entrenaron en la plataforma MosaicML con las siguientes herramientas:
- Cómputo: GPUs A100-40GB y A100-80GB de Oracle Cloud
- Orquestación y Tolerancia a Fallos: MCLI y plataforma MosaicML
- Datos: Almacenamiento de objetos OCI y StreamingDataset
- Software de entrenamiento: Composer, PyTorch FSDP y LLM Foundry
Como se muestra en la Tabla 3, casi todo el presupuesto de entrenamiento se gastó en el modelo base MPT-7B, que tardó ~9.5 días en entrenarse en 440 GPUs A100-40GB y costó ~$200k. Los modelos ajustados requirieron mucho menos cómputo y fueron mucho más baratos, oscilando entre unos pocos cientos y unos pocos miles de dólares cada uno.
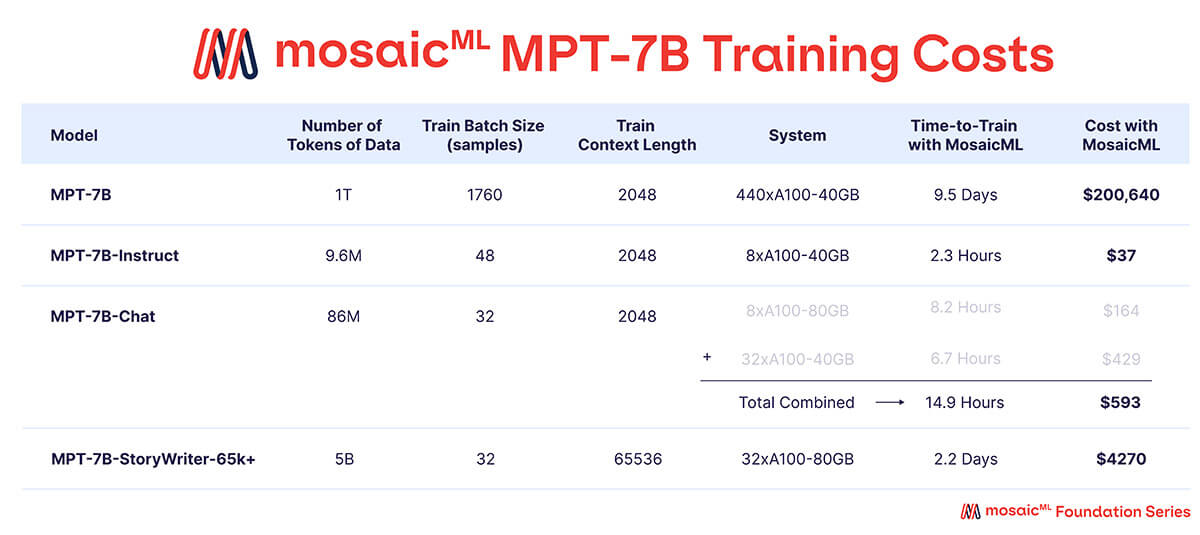
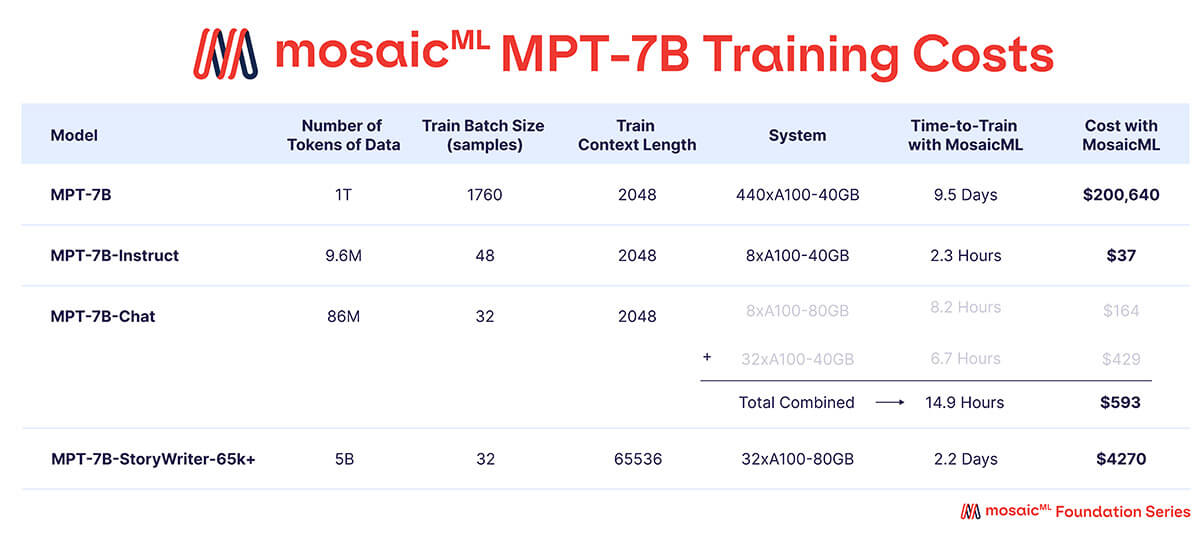{kind=link}
'Tiempo de Entrenamiento' es el tiempo total de ejecución desde el inicio hasta el final del trabajo, incluyendo la creación de puntos de control, la evaluación periódica, los reinicios, etc. 'Costo' se calcula con precios de $2/A100-40GB/hora y $2.50/A100-80GB/hora para GPUs reservadas en la plataforma MosaicML.
Cada una de estas recetas de entrenamiento se puede personalizar completamente. Por ejemplo, si deseas comenzar con nuestro MPT-7B de código abierto y ajustarlo con datos propietarios con una longitud de contexto larga, puedes hacerlo hoy mismo en la plataforma MosaicML.
Como otro ejemplo, para entrenar un nuevo modelo desde cero en un dominio personalizado (por ejemplo, en texto biomédico o código), simplemente reserva bloques grandes de cómputo a corto plazo con la oferta de hero cluster de MosaicML. Solo elige el tamaño de modelo y el presupuesto de tokens deseados, carga tus datos en un almacén de objetos como S3 y lanza un trabajo MCLI. ¡Tendrás tu propio LLM personalizado en solo unos días!
Consulta nuestra publicación anterior sobre LLM para obtener orientación sobre los tiempos y costos de entrenamiento de diferentes LLM. Encuentra los datos de rendimiento más recientes para configuraciones de modelos específicas aquí. En línea con nuestro trabajo anterior, todos los modelos MPT-7B se entrenaron con Pytorch FullyShardedDataParallelism (FSDP) y sin paralelismo de tensor o de pipeline.
Estabilidad del Entrenamiento
Como muchos equipos han documentado, entrenar LLMs con miles de millones de parámetros en cientos o miles de GPUs es increíblemente desafiante. El hardware fallará con frecuencia y de maneras creativas e inesperadas. Los picos de pérdida descarrilarán el entrenamiento. Los equipos deben "cuidar" la ejecución del entrenamiento las 24 horas del día, los 7 días de la semana en caso de fallos y aplicar intervenciones manuales cuando las cosas van mal. Consulta el libro de registro de OPT para un ejemplo sincero de los muchos peligros que esperan a cualquiera que entrene un LLM.
En MosaicML, nuestros equipos de investigación e ingeniería han trabajado incansablemente durante los últimos 6 meses para eliminar estos problemas. Como resultado, nuestro libro de registro de entrenamiento de MPT-7B (Figura 5) ¡es muy aburrido! Entrenamos MPT-7B con 1 billón de tokens de principio a fin sin intervención humana. Sin picos de pérdida, sin cambios de tasa de aprendizaje a mitad de camino, sin omisión de datos, manejo automático de GPUs muertas, etc.

{kind=link}
MPT-7B se entrenó con 1 billón de tokens durante 9.5 días en 440 GPUs A100-40GB. Durante ese tiempo, el trabajo de entrenamiento encontró 4 fallos de hardware, todos los cuales fueron detectados por la plataforma MosaicML. La ejecución se pausó y reanudó automáticamente después de cada fallo, y no se requirió ninguna intervención humana.

{kind=link}
Si ocurren fallos de hardware mientras un trabajo está en ejecución, la plataforma MosaicML detecta automáticamente el fallo, pausa el trabajo, acordonará los nodos rotos y reanuda el trabajo. Durante la ejecución de entrenamiento de MPT-7B, encontramos 4 fallos de este tipo, y cada vez el trabajo se reanudó automáticamente
¿Cómo lo hicimos? Primero, abordamos la estabilidad de la convergencia con mejoras en la arquitectura y la optimización. Nuestros modelos MPT utilizan ALiBi en lugar de incrustaciones posicionales, lo que encontramos que mejora la resiliencia a los picos de pérdida. También entrenamos nuestros modelos MPT con el optimizador Lion en lugar de AdamW, que proporciona magnitudes de actualización estables y reduce a la mitad la memoria del estado del optimizador.
Segundo, utilizamos la función NodeDoctor de la plataforma MosaicML para monitorear y resolver fallos de hardware y la función JobMonitor para reanudar ejecuciones después de que se resolvieran estos fallos. Estas funciones nos permitieron entrenar MPT-7B sin intervención humana de principio a fin a pesar de 4 fallos de hardware durante la ejecución. Vea la Figura 6 para una vista detallada de cómo se ve la autorreanudación en la plataforma MosaicML.
Inferencia
MPT está diseñado para ser rápido, fácil y económico de implementar para inferencia. Para empezar, todos los modelos MPT se heredan de la clase base HuggingFace PretrainedModel, lo que significa que son totalmente compatibles con el ecosistema HuggingFace. Puede cargar modelos MPT en el HuggingFace Hub, generar salidas con pipelines estándar como `model.generate(...)`, crear HuggingFace Spaces (¡vea algunos de los nuestros aquí!), y más.
¿Y el rendimiento? Con las capas optimizadas de MPT (incluyendo FlashAttention y layernorm de baja precisión), el rendimiento listo para usar de MPT-7B al usar `model.generate(...)` es 1.5x-2x más rápido que otros modelos de 7B como LLaMa-7B. Esto facilita la creación de pipelines de inferencia rápidos y flexibles con solo HuggingFace y PyTorch.
Pero, ¿qué pasa si *realmente* necesita el mejor rendimiento? En ese caso, porte directamente los pesos MPT a FasterTransformer o ONNX. Consulte la carpeta de inferencia de LLM Foundry para obtener scripts e instrucciones.
Finalmente, para la mejor experiencia de alojamiento, implemente sus modelos MPT directamente en el servicio de Inferencia de MosaicML. Comience con nuestros endpoints administrados para modelos como MPT-7B-Instruct, y/o implemente sus propios endpoints de modelo personalizados para un costo óptimo y privacidad de datos.
¿Qué sigue?
Este lanzamiento de MPT-7B es la culminación de dos años de trabajo en MosaicML construyendo y probando en batalla software de código abierto (Composer, StreamingDataset, LLM Foundry) e infraestructura propietaria (Entrenamiento y Inferencia de MosaicML ) que permite a los clientes entrenar LLMs en cualquier proveedor de cómputo, con cualquier fuente de datos, con eficiencia, privacidad y transparencia de costos, y que las cosas salgan bien a la primera.
Creemos que MPT, el MosaicML LLM Foundry y la plataforma MosaicML son el mejor punto de partida para construir LLMs personalizados para uso privado, comercial y comunitario, ya sea que desee ajustar nuestros checkpoints o entrenar los suyos desde cero. Esperamos ver cómo la comunidad se basa en estas herramientas y artefactos.
Es importante destacar que los modelos MPT-7B de hoy son solo el comienzo. Para ayudar a nuestros clientes a abordar tareas más desafiantes y mejorar continuamente sus productos, MosaicML continuará produciendo modelos fundacionales de mayor calidad. Ya se están entrenando modelos de seguimiento emocionantes. ¡Espere saber más sobre ellos pronto!
Agradecimientos
Estamos agradecidos a nuestros amigos de AI2 por ayudarnos a curar nuestro conjunto de datos de preentrenamiento, elegir un gran tokenizador y por muchas otras conversaciones útiles en el camino ⚔️
Apéndice
Datos
mC4
Multilingual C4 (mC4) 3.1.0 es una actualización del mC4 original de Chung et al., que contiene fuentes hasta agosto de 2022. Seleccionamos el subconjunto en inglés y luego aplicamos los siguientes criterios de filtrado a cada documento:
- El carácter más común debe ser alfabético.
- ≥ 92% de los caracteres deben ser alfanuméricos.
- Si el documento tiene más de 500 palabras, la palabra más común no puede constituir más del 7.5% del recuento total de palabras; Si el documento tiene ≤ 500 palabras, la palabra más común no puede constituir más del 30% del recuento total de palabras.
- El documento debe tener ≥ 200 palabras y ≤ 50000 palabras.
Los tres primeros criterios de filtrado se utilizaron para mejorar la calidad de la muestra, y el criterio de filtrado final (los documentos deben tener ≥200 palabras y ≤50000 palabras) se utilizó para aumentar la longitud media de la secuencia de los datos de preentrenamiento.
mC4 se lanzó como parte del esfuerzo continuo de Dodge et al..
C4
Colossal Cleaned Common Crawl (C4) es un corpus en inglés de Common Crawl introducido por Raffel et al. Aplicamos el proceso de Deduplicación Semántica de Abbas et al. para eliminar el 20% de los documentos más similares dentro de C4, ya que los experimentos internos mostraron que esta es una mejora de Pareto para los modelos entrenados en C4.
RedPajama
Incluimos varios subconjuntos del conjunto de datos RedPajama, que es el intento de Together de replicar los datos de entrenamiento de LLaMA. Específicamente, utilizamos los subconjuntos CommonCrawl, arXiv, Wikipedia, Books y StackExchange.
The Stack
Queríamos que nuestro modelo fuera capaz de generar código, así que recurrimos a The Stack, un corpus de 6.4TB de datos de código. Utilizamos The Stack Dedup, una variante de The Stack que se ha deduplicado aproximadamente (a través de MinHashLSH) a 2.9TB. Seleccionamos un subconjunto de 18 de los 358 lenguajes de programación de The Stack para reducir el tamaño del conjunto de datos y aumentar la relevancia:
- C
- C-Sharp
- C++
- Common Lisp
- F-Sharp
- Fortran
- Go
- Haskell
- Java
- Ocaml
- Perl
- Python
- Ruby
- Rust
- Scala
- Scheme
- Shell
- Tex
Elegimos que el código constituyera el 10% de los tokens de preentrenamiento, ya que los experimentos internos mostraron que podíamos entrenar con hasta un 20% de código (y un 80% de lenguaje natural) sin impacto negativo en la evaluación del lenguaje natural.
También extrajimos el componente Markdown de The Stack Dedup y lo tratamos como un subconjunto de datos de preentrenamiento independiente (es decir, no contado en el 10% de tokens de código). Nuestra motivación para esto es que los documentos en lenguaje de marcado son predominantemente lenguaje natural y, como tales, deberían contar para nuestro presupuesto de tokens de lenguaje natural.
Semantic Scholar ORC
El Semantic Scholar Open Research Corpus (S2ORC) es un corpus de artículos académicos en inglés, que consideramos una fuente de datos de alta calidad. Se aplicaron los siguientes criterios de filtrado de calidad:
- El artículo es de acceso abierto.
- El artículo tiene título y resumen.
- El artículo está en inglés (según lo evaluado usando cld3).
- El artículo tiene al menos 500 palabras y 5 párrafos.
- El artículo se publicó después de 1970 y antes del 2022-12-01.
- La palabra más frecuente en el artículo consta solo de caracteres alfabéticos y aparece en menos del 7.5% del documento.
Esto produjo 9.9M de artículos. Las instrucciones para obtener la última versión del conjunto de datos están disponibles aquí, y la publicación original está aquí. AI2 nos proporcionó amablemente la versión filtrada del conjunto de datos.
Tareas de Evaluación
Lambada: 5153 muestras de texto seleccionadas del corpus de libros. Consiste en un párrafo de varios cientos de palabras en el que se espera que el modelo prediga la siguiente palabra.
PIQA: 1838 muestras de preguntas de opción múltiple binarias intuitivas físicas, por ejemplo, "Pregunta: ¿Cómo puedo llevar fácilmente ropa en perchas cuando me mudo?", "Respuesta: "Toma un par de perchas de ropa resistentes vacías, luego engancha varias prendas de ropa en esas perchas y llévalas todas a la vez."
COPA: 100 oraciones de la forma XYZ por lo tanto/porque TUV. Formuladas como preguntas de opción múltiple binarias donde el modelo tiene la opción de dos formas posibles de seguir el por lo tanto/porque. por ejemplo, {"query": "La mujer estaba de mal humor, por lo tanto", "gold": 1, "choices": ["entabló una conversación trivial con su amiga.", "le dijo a su amiga que la dejara en paz."]}
BoolQ: 3270 preguntas de sí/no basadas en un pasaje que contiene información relevante. Los temas de las preguntas van desde la cultura pop hasta la ciencia, la ley, la historia, etc. por ejemplo, {"query": "Pasaje: La Rana Gustavo es un personaje de Muppet y la creación más conocida de Jim Henson. Introducida en 1955, Gustavo es el protagonista de numerosas producciones de Muppet, especialmente Barrio Sésamo y El Show de los Muppets, así como en otras series de televisión, películas, especiales y anuncios de servicio público a lo largo de los años. Henson interpretó originalmente a Gustavo hasta su muerte en 1990; Steve Whitmire interpretó a Gustavo desde entonces hasta su despido del papel en 2016. Actualmente, Gustavo es interpretado por Matt Vogel. También fue doblado por Frank Welker en Muppet Babies y ocasionalmente en otros proyectos de animación, y es doblado por Matt Danner en el reinicio de Muppet Babies de 2018.\nPregunta: ¿ha aparecido la Rana Gustavo en Barrio Sésamo?\n", "choices": ["no", "sí"], "gold": 1}
Arc-Challenge: 1172 desafiantes preguntas de opción múltiple de cuatro opciones sobre ciencia
Arc-Easy: 2376 preguntas fáciles de opción múltiple de cuatro opciones sobre ciencia
HellaSwag: 10042 preguntas de opción múltiple de cuatro opciones en las que se presenta un escenario de la vida real y el modelo debe elegir la conclusión más probable del escenario.
Jeopardy: 2117 preguntas de Jeopardy de cinco categorías: ciencia, historia mundial, historia de EE. UU., orígenes de palabras y literatura. El modelo debe proporcionar la respuesta correcta exacta
MMLU: 14,042 preguntas de opción múltiple de 57 categorías académicas diversas
TriviaQA: 11313 preguntas de trivia de cultura pop de respuesta libre
Winograd: 273 preguntas de esquema donde el modelo debe resolver a qué referente de un pronombre es más probable.
Winogrande: 1,267 preguntas de esquema donde el modelo debe resolver qué oración ambigua es más lógicamente probable (ambas versiones de la oración son sintácticamente válidas)
Política de Privacidad de MPT Hugging Face Spaces
Consulte nuestra Política de Privacidad de MPT Hugging Face Spaces.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.