PDFs a Producción: Anuncio de inteligencia documental de última generación en Databricks
Con ai_parse_document, analice y comprenda PDFs directamente en SQL con calidad líder a un costo 3-5 veces menor
- Hoy, presentamos la última incorporación a Agent Bricks: ai_parse_document (versión preliminar pública): Potenciado por nuestro sistema agéntico de investigación para la comprensión multimodal a gran escala.
- Desbloquee el 80% de los datos de su empresa con procesamiento inteligente de documentos de última generación: Procese millones de documentos complejos —tablas, figuras, diagramas— con el poder de la investigación pionera en IA en una única función SQL.
- Calidad y costo líderes: Desarrollamos un sistema de inteligencia documental que compite en calidad con las mejores ofertas de la competencia a un costo 3-5 veces menor.
- Integración completa de la plataforma: Procesamiento incremental automático con Spark Declarative Pipelines, gobernanza con Unity Catalog y uso sin interrupciones en Agent Bricks, AI Search y AIBI.
Durante la Semana de los Agentes estamos expandiendo Agent Bricks, la plataforma de Databricks para construir agentes de IA gobernados y listos para producción que razonan con precisión sobre tus datos. Uno de los mayores desafíos que enfrentan las empresas al escalar agentes es el acceso a datos no estructurados. Casi el 80% del conocimiento empresarial está atrapado en PDFs, informes y diagramas que los agentes no pueden leer, comprender o sobre los cuales no pueden razonar. Estos documentos contienen contexto crítico, pero la mayoría de los agentes de IA no podían leerlos, hasta ahora.
Las herramientas de análisis existentes se detienen en la extracción de texto. Se pierden los diseños, los elementos visuales y las relaciones que transmiten significado en documentos reales. Los equipos pasan meses escribiendo código personalizado frágil que aún falla con datos del mundo real. ai_parse_document elimina esa complejidad. Aporta una comprensión completa del documento directamente a la Plataforma de Inteligencia de Datos de Databricks, dando a cada agente acceso a la fidelidad completa del contexto de tu negocio, de forma precisa, segura y escalable.
Con un solo comando SQL, las organizaciones pueden transformar documentos en datos estructurados, gobernados y consultables:
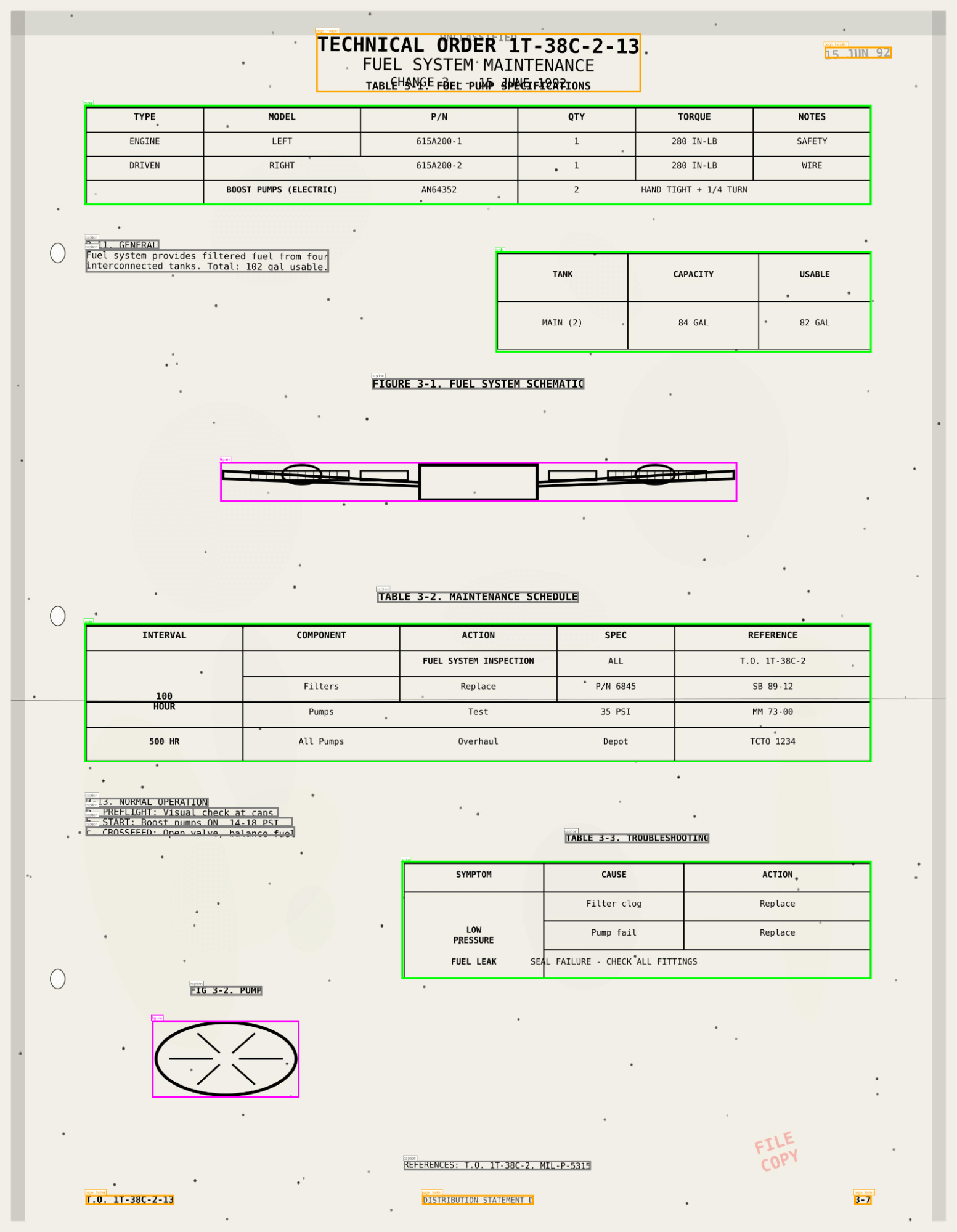
El resultado no es solo el texto del PDF, sino también información de diseño, tablas analizadas, cuadros delimitadores, figuras e imágenes con leyendas: una descripción completa del documento, como información estructurada.
"ai_parse_document de Databricks reduce la sobrecarga de configuración, lo que permite a los científicos de datos dedicar menos tiempo a la configuración y más tiempo a avanzar en soluciones complejas centradas en el cliente."—Meiling He, Gerente Principal de Ciencia de Datos, Rockwell Automation
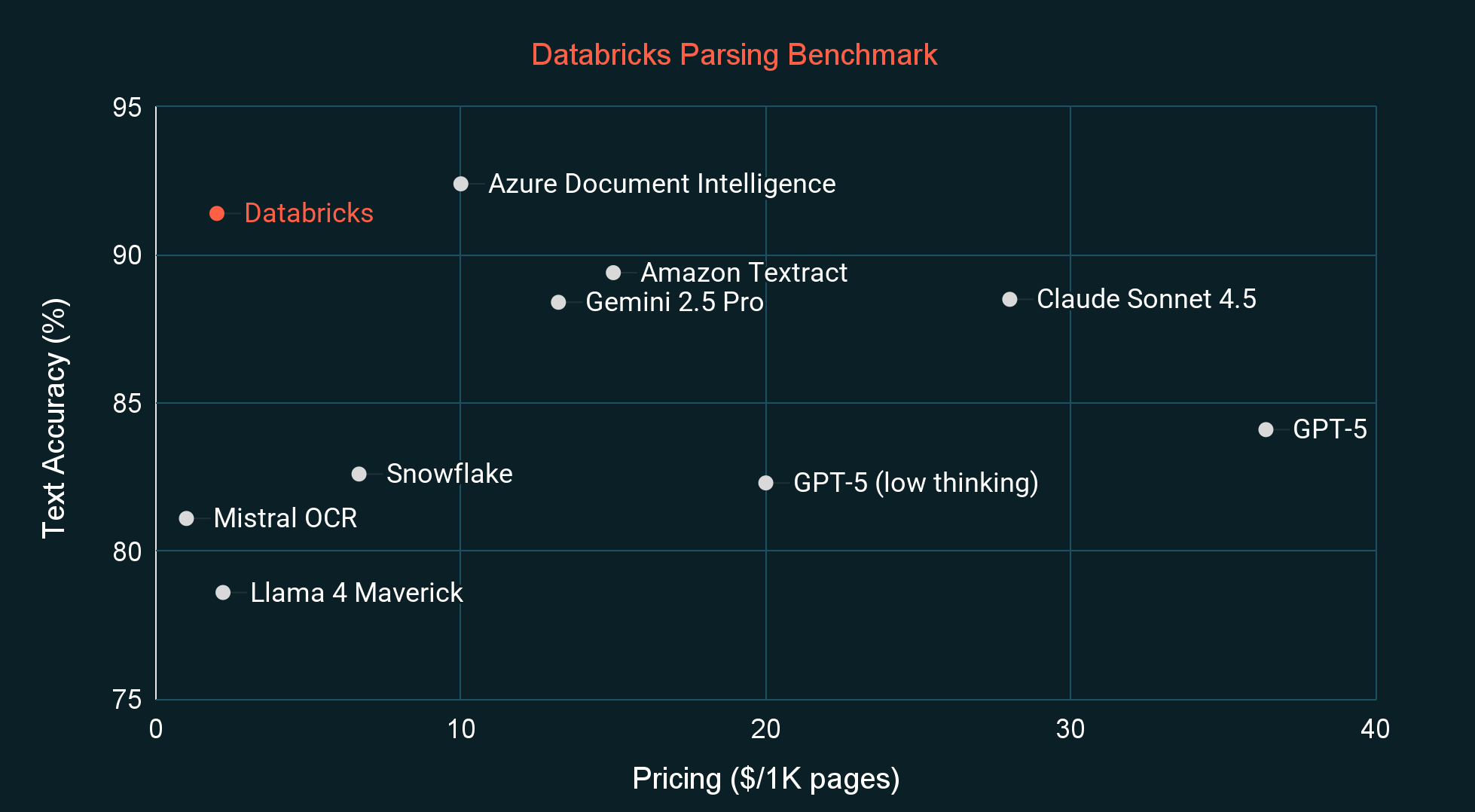
Rendimiento de Precio de Vanguardia
Al compararlo con otros sistemas de análisis de vanguardia y modelos de lenguaje visual (VLMs), ai_parse_document tiene la mayor calidad para su categoría de precio, medida tanto por un punto de referencia externo común (OmniOCR) como por nuestro punto de referencia interno privado (ver Figuras a continuación). El punto de referencia interno está más alineado con la distribución de documentos que hemos visto de los clientes y también es poco probable que forme parte de los datos de entrenamiento de ningún modelo. En las próximas semanas, también publicaremos nuestras nuevas etiquetas OmniOCR, que corrigen algunos errores de etiquetado e introducen cuadros delimitadores e información jerárquica.

Cómo Funciona
ai_parse_document captura tablas, figuras y diagramas con descripciones generadas por IA y metadatos espaciales, almacenando los resultados en Unity Catalog. Tus documentos ahora se comportan como tablas, se pueden buscar mediante AI Search y son accionables en flujos de trabajo de Agent Bricks.
“Extraer tablas, texto y metadatos de PDFs o imágenes solía ser un proceso complejo y que requería mucho código. Databricks lo condensó en una única función SQL, ai_parse_document, simplificando radicalmente el procesamiento de datos no estructurados a escala y poniéndolo en manos de cada equipo de datos, no solo de los científicos de datos.”—Rajesh Balakrishnan, Científico de Datos Principal, TE Connectivity
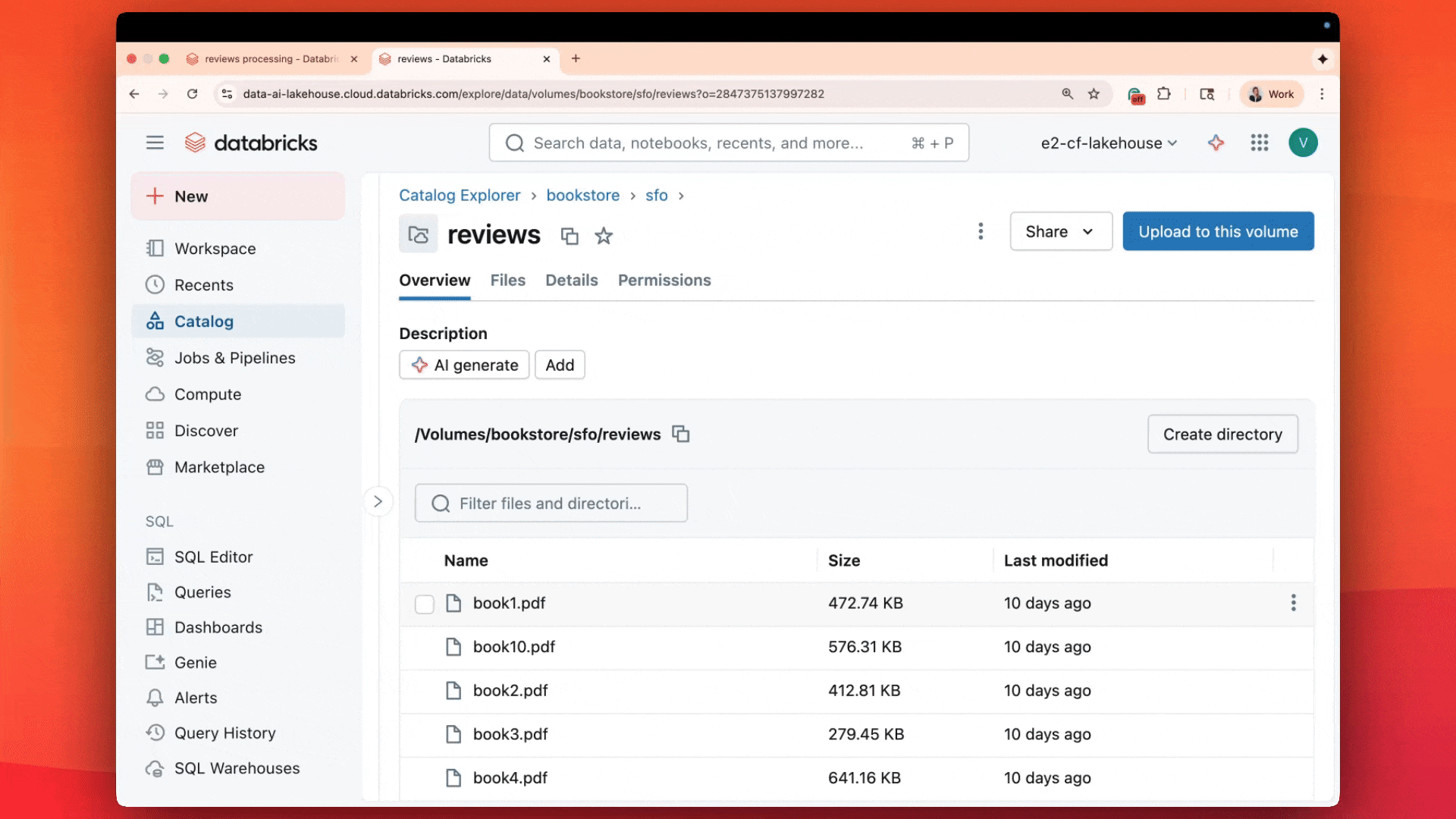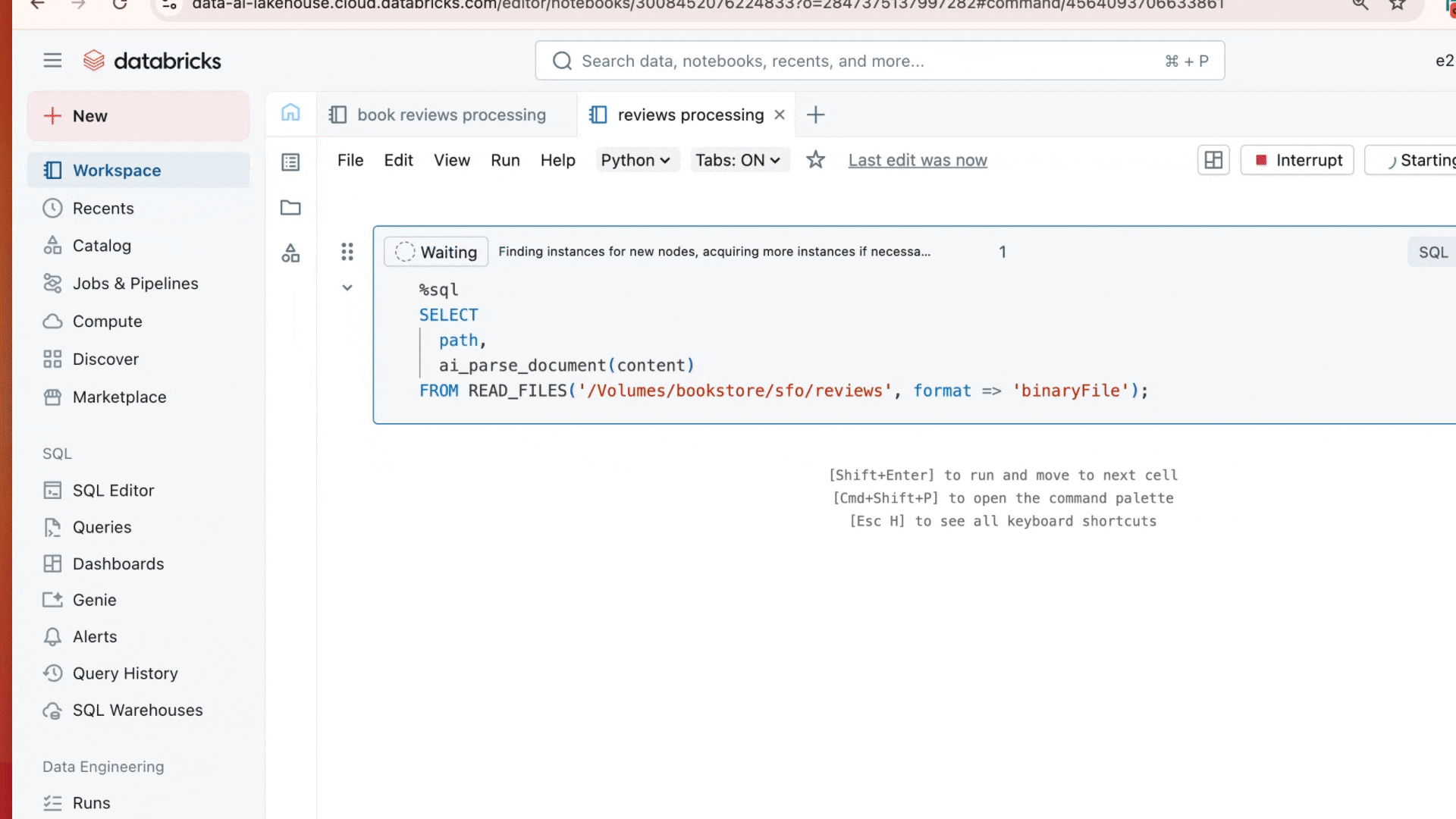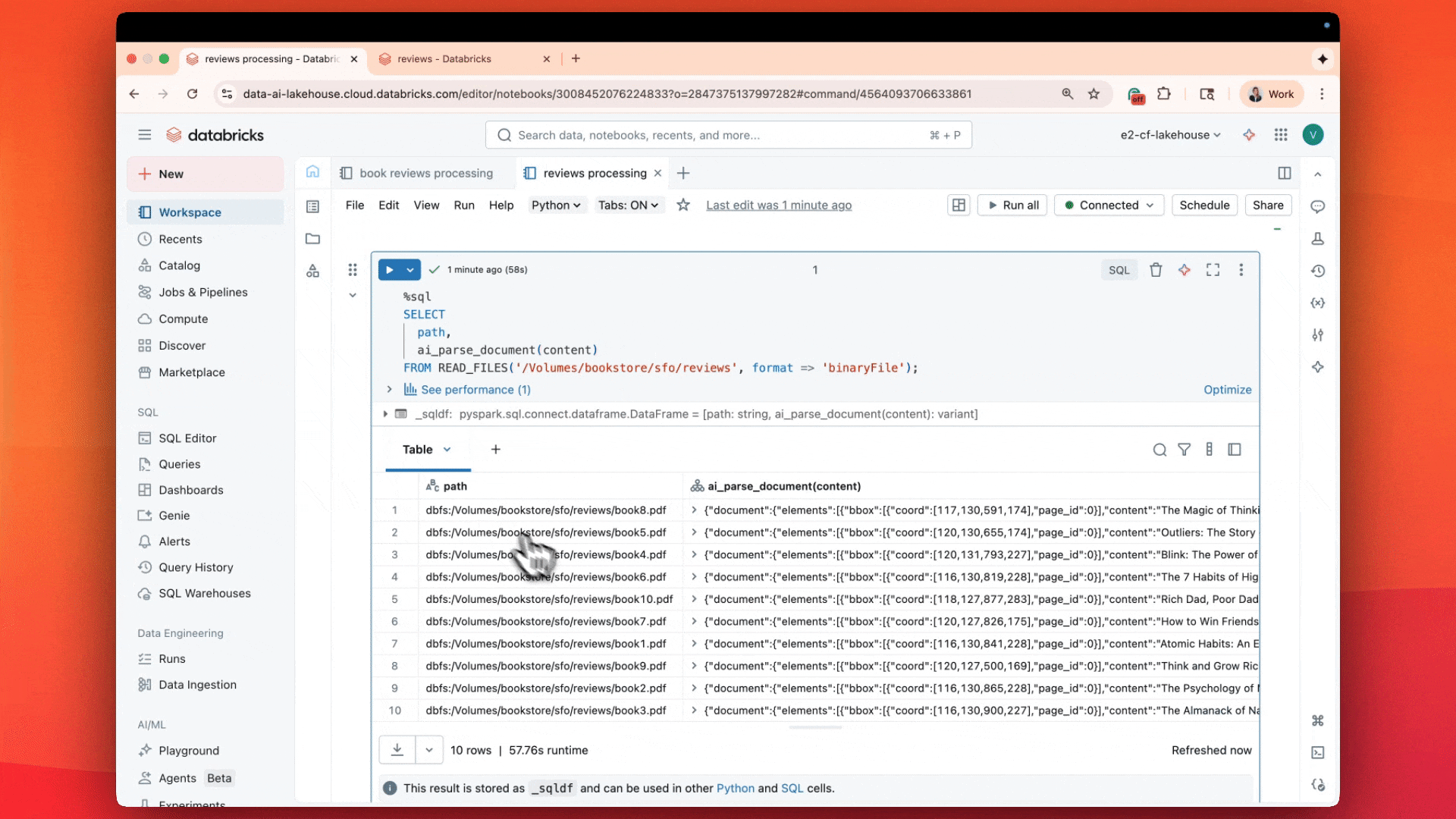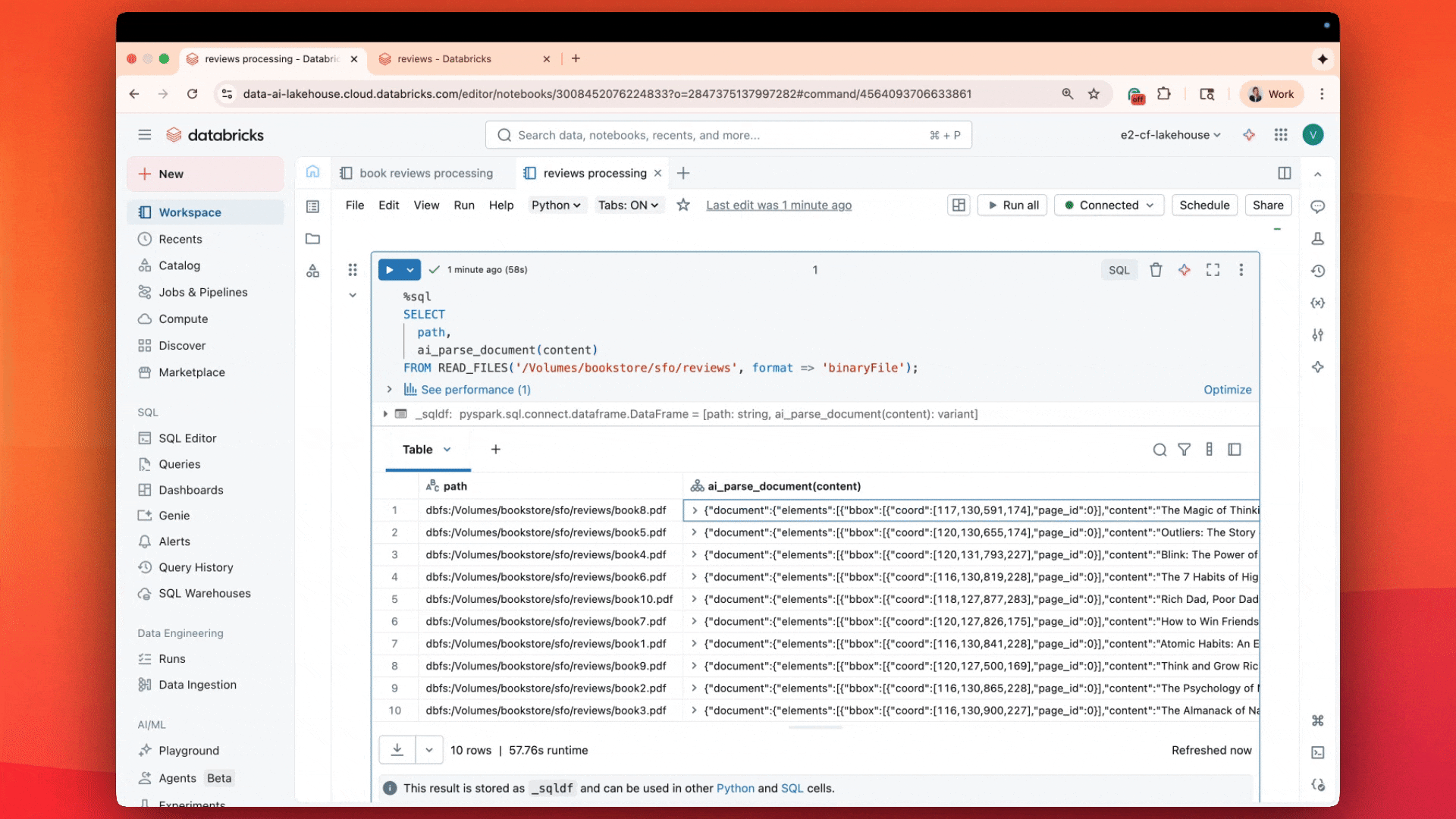
Con una sola instrucción SQL, los clientes ya están procesando millones de documentos en paralelo:
Cada resultado incluye:
- Tablas conservadas exactamente como aparecen, incluidas celdas combinadas y estructuras anidadas.
- Figuras y diagramas descritos automáticamente con subtítulos generados por IA.
- Metadatos espaciales y cuadros delimitadores para citas y validación.
- Salidas de imagen opcionales almacenadas en volúmenes de Unity Catalog para búsqueda multimodal o visualización.
Dado que todo permanece dentro de Databricks, mantienes una gobernanza, linaje y observabilidad consistentes.
Reemplaza tu conjunto de analizadores externos con una única función SQL que funciona como cualquier otra operación de Databricks. Mientras que los equipos normalmente exportan documentos a servicios de OCR, API de detección de diseño y herramientas de subtitulado de figuras,ai_parse_document los procesa sin salir de tu entorno Databricks:
“ai_parse_document hace que RAG sea rápido y simple en Databricks al permitir el análisis de documentos en paralelo directamente dentro de las tablas Delta que ya estás usando”—Hunter Johnson, Científico de Datos Principal, Emerson Electric Co.
De la interpretación a la acción con Agent Bricks
Una vez interpretados, los datos de los documentos fluyen de forma natural a través del resto del ecosistema de Agent Bricks:
- AI Search indexa cada elemento para aplicaciones RAG multimodales que entienden texto y visuales.
- Declarative Agents optimizan la extracción, clasificación y resumen con lenguaje natural para obtener mejor rendimiento y menores costos.
- AI Functions extraen entidades, clasifican contenido y resumen texto, todo con SQL.
- Supervisor Agent coordina agentes de análisis de documentos con otros agentes especializados, permitiendo flujos de trabajo complejos y de varios pasos.
- AI/BI Dashboards y Spark Declarative Pipelines utilizan los mismos datos interpretados para análisis y procesamiento continuo.
En conjunto, estas capacidades hacen que los datos no estructurados sean una parte totalmente integrada de la plataforma Agent Bricks.
Diseñado para escala y fiabilidad en producción
Muchas empresas tienen millones de documentos no estructurados que procesar, algunas incluso reciben millones al día. Es fundamental contar con una solución que pueda escalar de forma fiable para procesar estos datos sin tardar días. Databricks integra ai_parse_document con Spark Declarative Pipelines, proporcionando procesamiento de documentos automático e incremental a escala. Cuando llegan nuevos documentos, ya sea desde SharePoint, S3 o ADLS, se procesan automáticamente. Lakeflow se encarga de los reintentos, el checkpointing y el escalado, por lo que nunca necesitará reprocesar datos existentes ni escribir código de orquestación personalizado.
Todo se rige a través de Unity Catalog, lo que le permite administrar permisos, auditar el acceso y rastrear el linaje del contenido procesado exactamente como lo hace con los datos estructurados.
Desbloquee datos no estructurados con Agent Bricks
ai_parse_document es la última incorporación a Agent Bricks AI Functions, uniéndose a capacidades como ai_extract, ai_classify, ai_summarize y ai_query. Juntas, estas funciones brindan a cada equipo la capacidad de razonar sobre todos los datos empresariales directamente dentro de la plataforma Databricks. Al combinar la inteligencia de documentos con la gobernanza, la observabilidad y la orquestación integradas, Databricks permite a las empresas crear agentes de IA que comprenden verdaderamente su contexto empresarial y actúan sobre él con confianza.
¿Listo para desbloquear el valor de sus datos no estructurados?
- Lea la documentación para empezar a usar ai_parse_document hoy
Autores de la investigación (contribución igual): Ziyi Yang, Jasmine Collins, Adyasha Maharana, Cory Stephenson, Erich Elsen, Adam Gurary, Ethan Tang
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.