PDFs to Production: Announcing state-of-the-art document intelligence on Databricks
With ai_parse_document, parse and understand PDFs directly in SQL with leading quality at 3-5x lower cost
- Today, we’re introducing the newest addition to Agent Bricks: ai_parse_document (Public Preview): Powered by our research team’s agentic system for large-scale multimodal understanding.
- Unlock 80% of your enterprise data with state-of-the-art intelligent document processing: Process millions of complex documents—tables, figures, diagrams—with the power of groundbreaking AI research in one single SQL function.
- Leading quality and cost: We developed a document intelligence system that is competitive in quality with the best competitor offerings at 3-5x lower cost.
- Full platform integration: Automatic incremental processing with Spark Declarative Pipelines, governance with Unity Catalog, and seamless use across Agent Bricks, AI Search, and AIBI.
During the Week of Agents we’re expanding Agent Bricks, the Databricks platform for building governed, production-ready AI agents that accurately reason on your data. One of the biggest challenges enterprises face when scaling agents is access to unstructured data. Nearly 80% of enterprise knowledge is trapped in PDFs, reports, and diagrams that agents can’t read, understand or reason over. These documents hold critical context, yet most AI agents couldn’t read them—until now.
Existing parsing tools stop at text extraction. They miss the layouts, visual elements, and relationships that carry meaning in real documents. Teams spend months writing brittle custom code that still fails on real-world data. ai_parse_document eliminates that complexity. It brings complete document understanding directly into the Databricks Data Intelligence Platform, giving every agent access to the full fidelity of your business context—accurately, securely, and at scale.
With a single SQL command, organizations can transform documents into structured, governed, and queryable data:
The result is not just the PDF’s text, but also layout information, parsed tables, bounding boxes, figures and images with captions – a comprehensive description of the document, as structured information.
"Databricks’ ai_parse_document reduces configuration overhead, enabling data scientists to spend less time on setup and more time advancing complex, customer-focused solutions."—Meiling He, Sr. Data Science Manager, Rockwell Automation
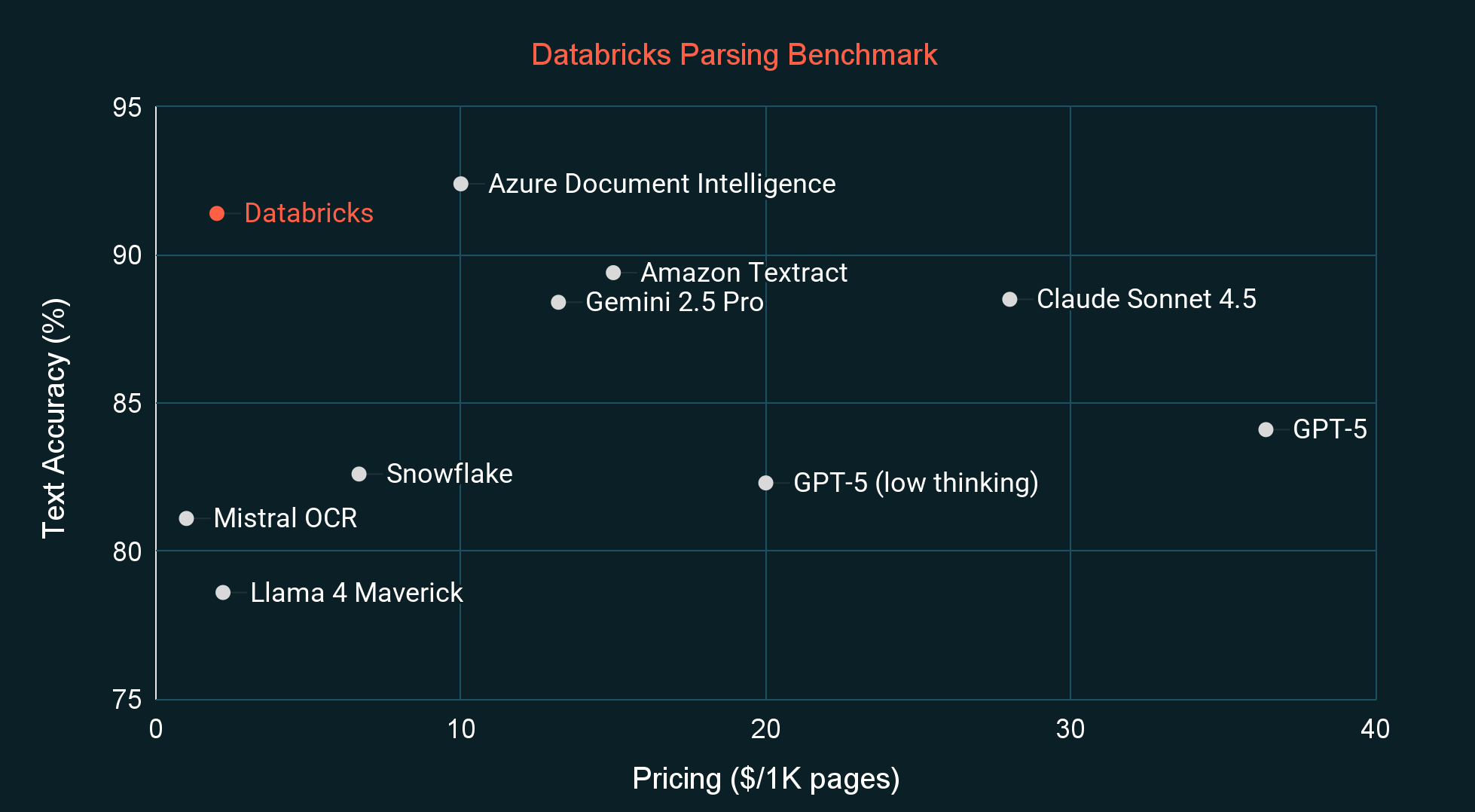
State of the Art Price-Performance
When benchmarked against other state-of-the-art parsing systems and vision language models (VLMs), ai_parse_document has the highest quality for its price category, measured both by a common external benchmark (OmniOCR) and also by our private internal benchmark (see Figures below). The internal benchmark is more aligned with the distribution of documents we’ve seen from customers and also unlikely to be part of any model’s training data. In the coming weeks, we will also release our new OmniOCR labels, which fix some labeling errors and introduce bounding boxes and hierarchy information.

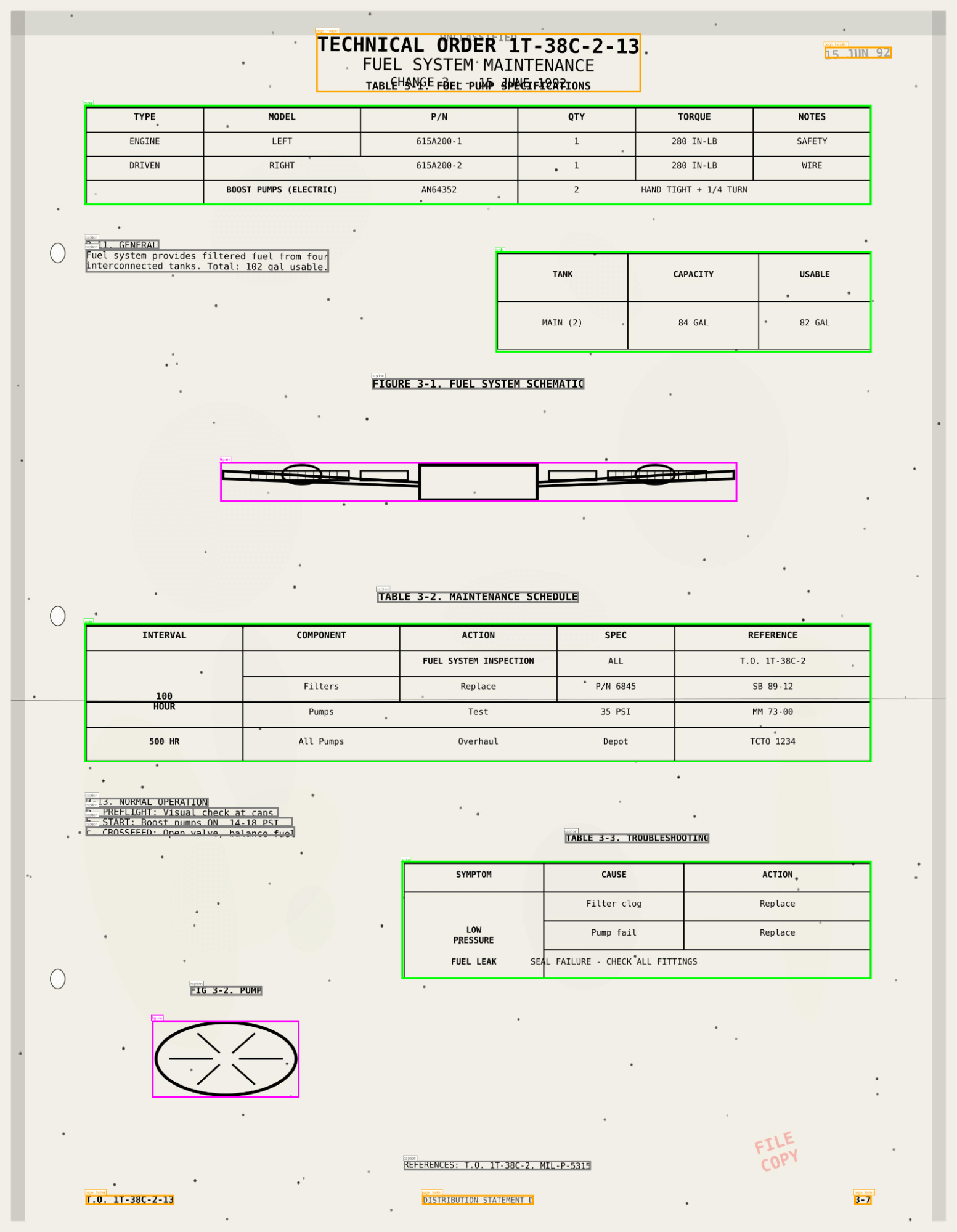
How It Works
ai_parse_document captures tables, figures, and diagrams with AI-generated descriptions and spatial metadata, storing results in Unity Catalog. Your documents now behave like tables—searchable through AI Search and actionable in Agent Bricks workflows.
“Extracting tables, text, and metadata from PDFs or images used to be a complex, code-heavy process. Databricks condensed it into a single SQL function, ai_parse_document, radically simplifying unstructured data processing at scale and putting it in the hands of every data team, not just data scientists.”—Rajesh Balakrishnan, Principal Data Scientist, TE Connectivity
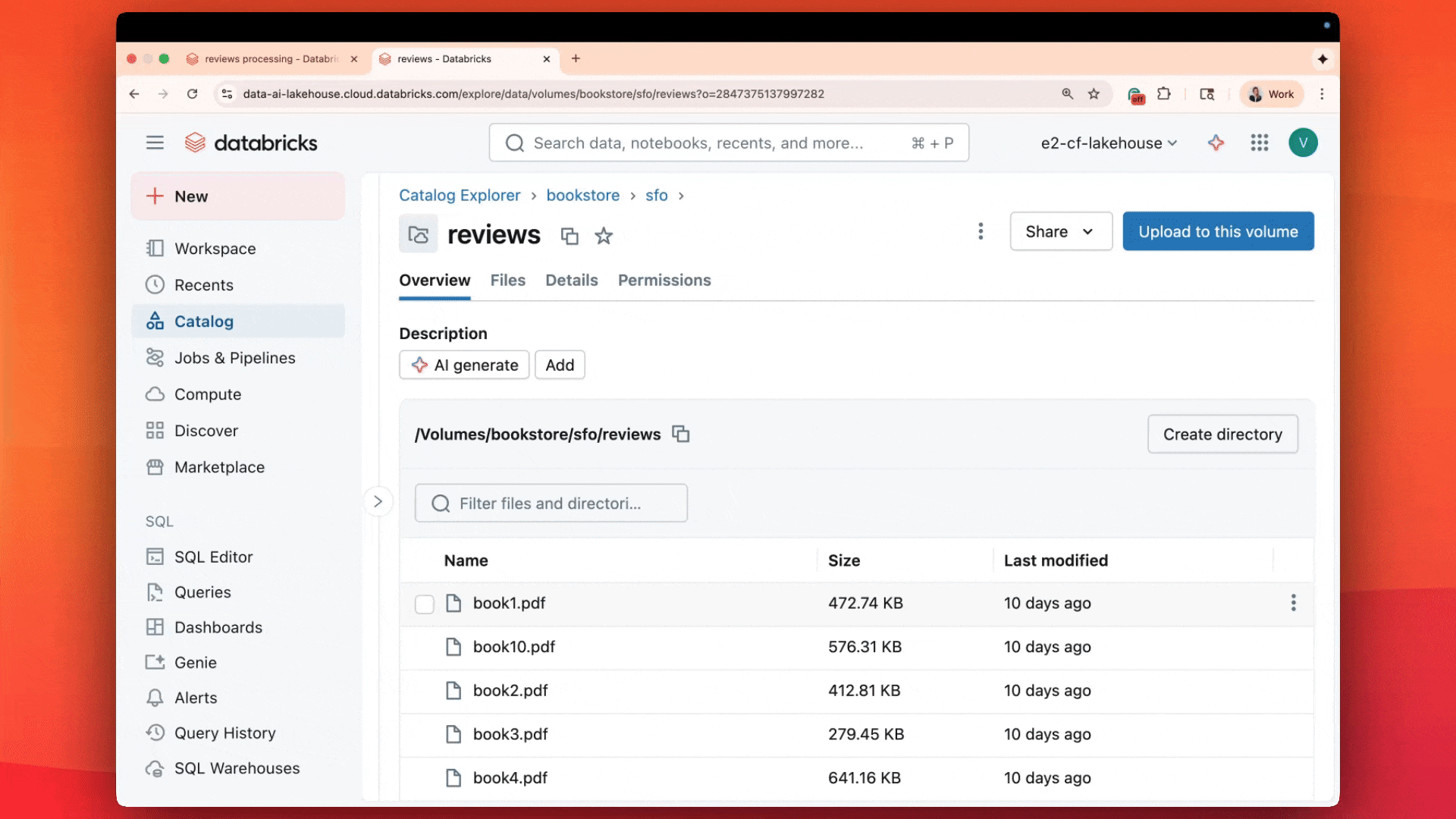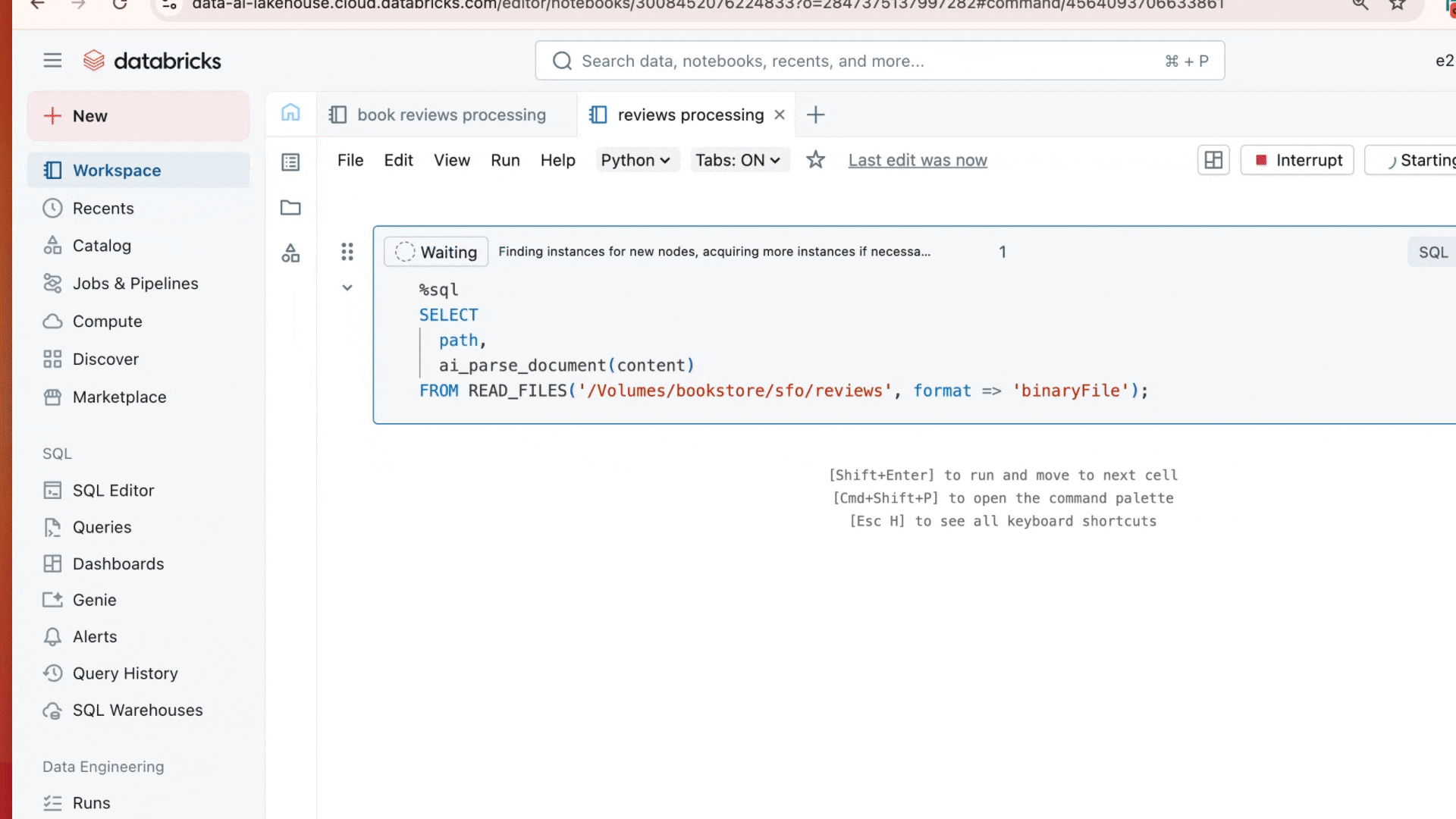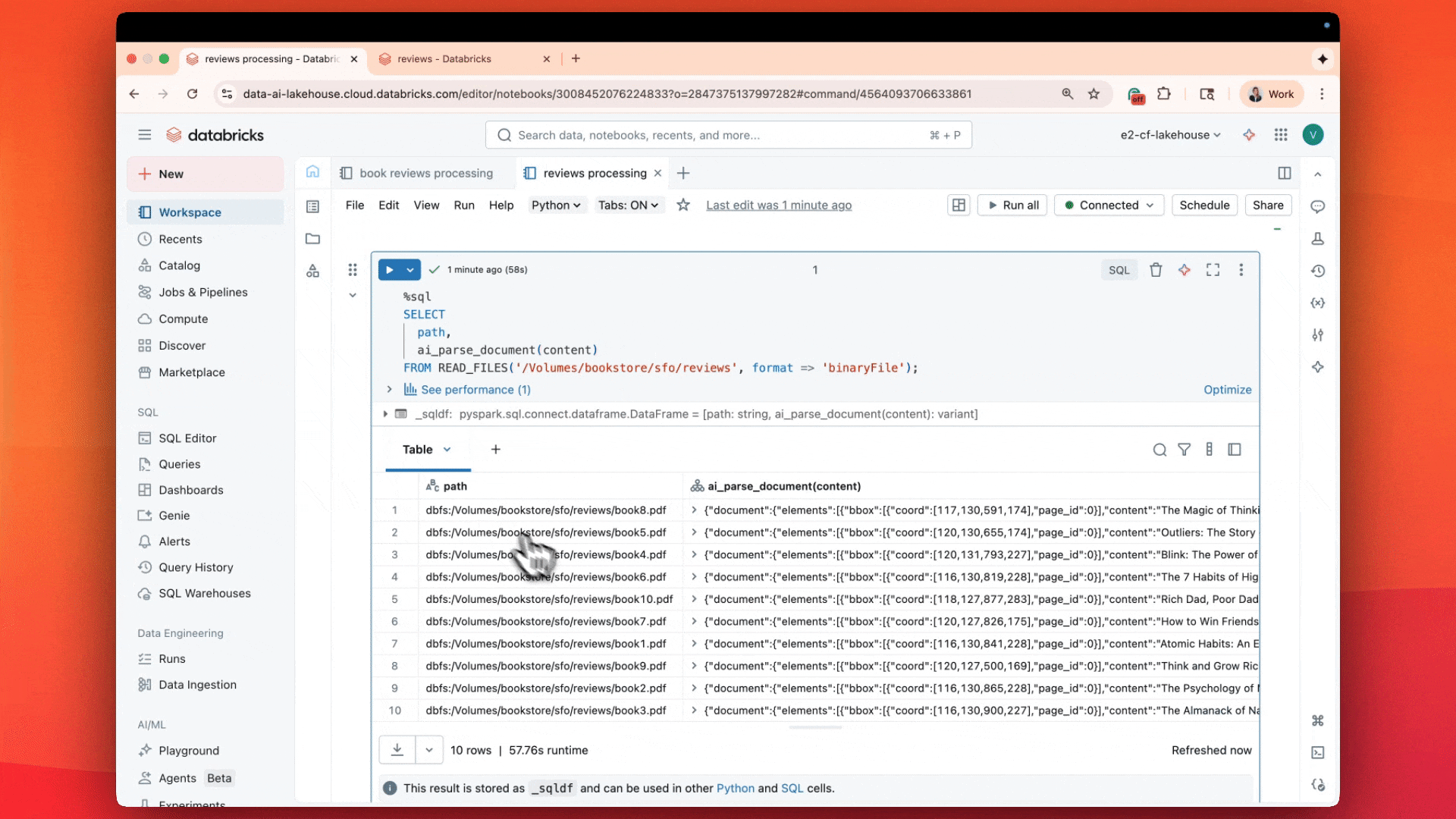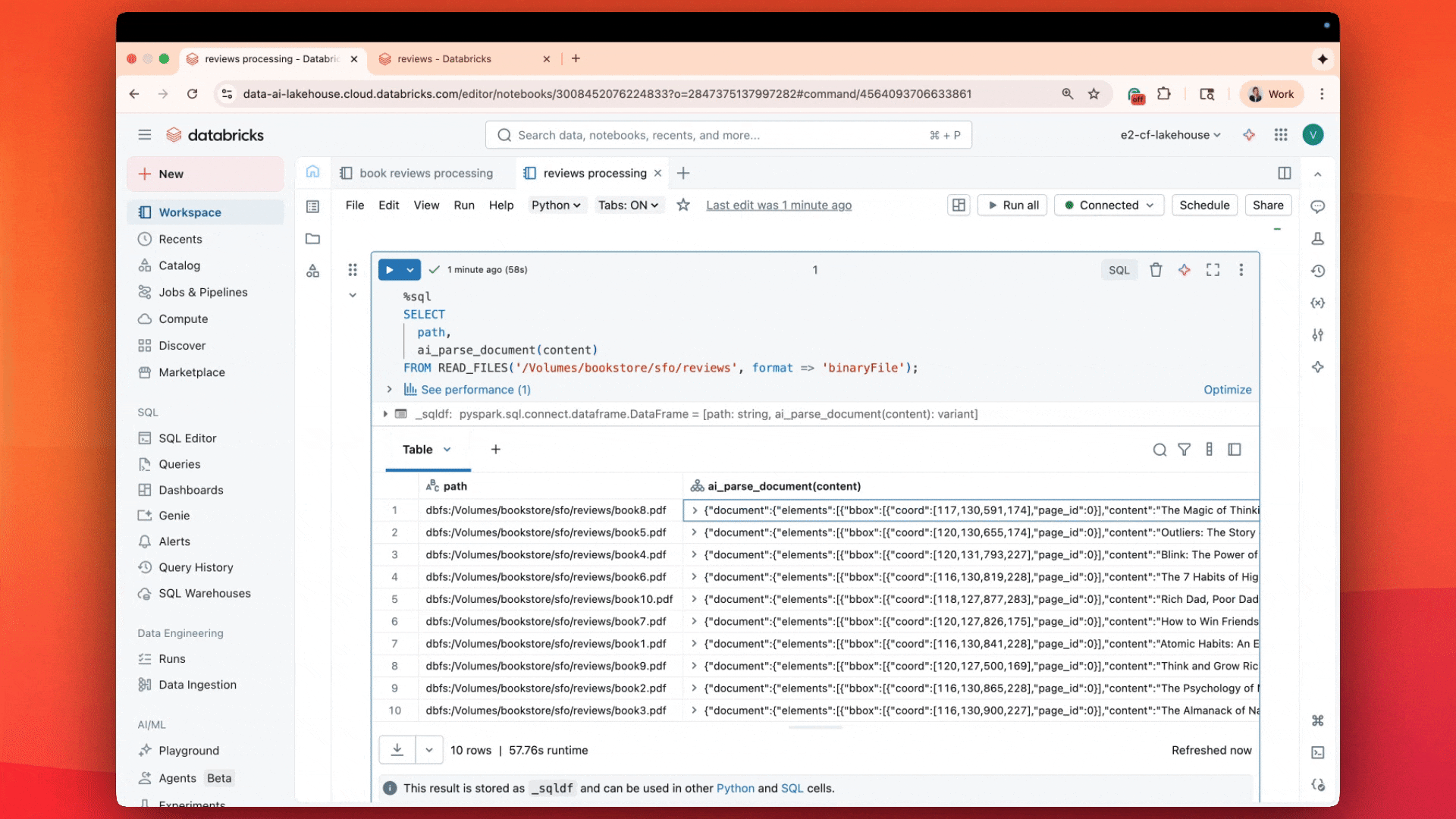
With one SQL statement, customers are already processing millions of documents in parallel:
Each result includes:
- Tables preserved exactly as they appear, including merged cells and nested structures.
- Figures and diagrams described automatically with AI-generated captions.
- Spatial metadata and bounding boxes for citations and validation.
- Optional image outputs stored in Unity Catalog volumes for multimodal search or visualization.
Because everything stays inside Databricks, you maintain consistent governance, lineage, and observability.
Replace your stack of external parsers with a single SQL function that works like any other Databricks operation. While teams typically export documents to OCR services, layout detection APIs, and figure captioning tools, ai_parse_document processes them without leaving your Databricks environment:
“ai_parse_document makes RAG fast and simple on Databricks by enabling parallel document parsing directly within the Delta tables you’re already using”—Hunter Johnson, Lead Data Scientist, Emerson Electric Co.
From Parsing to Action with Agent Bricks
Once parsed, document data flows naturally through the rest of the Agent Bricks ecosystem:
- AI Search indexes every element for multimodal RAG applications that understand both text and visuals.
- Declarative Agents optimize extraction, classification, and summarization with natural language to get better throughput and lower costs
- AI Functions extract entities, classify content, and summarize text—all with SQL.
- Supervisor Agent coordinates document-analysis agents with other specialized agents, enabling complex, multi-step workflows.
- AI/BI Dashboards and Spark Declarative Pipelines use the same parsed data for analytics and continuous processing.
Together, these capabilities make unstructured data a fully integrated part of the Agent Bricks platform.
Built for Production Scale and Reliability
Many companies have millions of unstructured documents to parse, some even have millions that come in per day. It’s critical to have a solution that can reliably scale to process this data without taking days. Databricks integrates ai_parse_document with Spark Declarative Pipelines, providing automatic, incremental document processing at scale. When new documents arrive—whether from SharePoint, S3, or ADLS—they’re parsed automatically. Lakeflow handles retries, checkpointing, and scaling, so you never need to reprocess existing data or write custom orchestration code.
Everything is governed through Unity Catalog, letting you manage permissions, audit access, and track lineage for parsed content exactly as you do for structured data.
Unlock Unstructured Data with Agent Bricks
ai_parse_document is the latest addition to Agent Bricks AI Functions, joining capabilities like ai_extract, ai_classify, ai_summarize, and ai_query. Together, these functions give every team the ability to reason over all enterprise data directly within the Databricks platform. By combining document intelligence with built-in governance, observability, and orchestration, Databricks enables enterprises to build AI agents that truly understand their business context and act on it with confidence.
Ready to unlock the value in your unstructured data?
- Read the documentation to start using ai_parse_document today
- Build incremental document pipelines with our reference solution
Research Authors (equal contribution): Ziyi Yang, Jasmine Collins, Adyasha Maharana, Cory Stephenson, Erich Elsen, Adam Gurary, Ethan Tang
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.