La guía definitiva del profesional para el registro escalable
Estandarice y estructure el registro de producción para trabajos de Spark en Databricks, y obtenga más de sus registros centralizando los registros de clúster para su ingesta y análisis.
por Zach King
- Mejores prácticas de nivel de producción para un registro estructurado y práctico en trabajos de Databricks.
- Centralización del almacenamiento de registros que escala y simplifica el procesamiento.
- Creación de un panel de IA/BI para analizar registros.
Introducción: El registro de eventos es importante, y aquí te explicamos por qué
Escalar de unas pocas docenas de trabajos a cientos es un desafío por varias razones, una de las cuales es la observabilidad. La observabilidad es la capacidad de comprender el sistema analizando componentes como registros, métricas y rastreos. Esto es igual de relevante para equipos de datos más pequeños con solo unos pocos pipelines que monitorear, y los motores de computación distribuida como Spark pueden ser difíciles de monitorear, depurar y crear procedimientos de escalamiento maduros de manera confiable.
El registro de eventos es, sin duda, el componente más simple e impactante de estos componentes de observabilidad. Hacer clic y desplazarse por los registros, un trabajo a la vez, no es escalable. Puede consumir mucho tiempo, ser difícil de analizar y, a menudo, requiere experiencia en el flujo de trabajo. Sin establecer estándares de registro maduros en sus pipelines de datos, la solución de problemas de errores o fallas de trabajos lleva significativamente más tiempo, lo que resulta en interrupciones costosas, niveles de escalamiento ineficaces y fatiga de alertas.
En este blog, te guiaremos a través de:
- Pasos para dejar de lado las declaraciones de impresión básicas y configurar un marco de registro adecuado.
- Cuándo configurar los registros de Spark log4j para usar el formato JSON.
- Por qué centralizar el almacenamiento de registros de clúster para facilitar el análisis y la consulta.
- Cómo crear un panel central de IA/BI en Databricks que puedes configurar en tu propio espacio de trabajo para un análisis de registros más personalizado.
Consideraciones Arquitectónicas Clave
Las siguientes consideraciones son importantes a tener en cuenta para adaptar estas recomendaciones de registro a tu organización:
Bibliotecas de registro
- Existen varias bibliotecas de registro tanto para Python como para Scala. Nuestros ejemplos utilizan Log4j y el módulo estándar de Python logging.
- La configuración para bibliotecas o marcos de registro será diferente, y debes consultar su documentación respectiva si utilizas una herramienta no estándar.
Tipos de clúster
- Los ejemplos en este blog se centrarán principalmente en la siguiente computación:
- En el momento de escribir esto, los siguientes tipos de computación tienen menos soporte para la entrega de registros, aunque las recomendaciones para los marcos de registro aún se aplican:
- Lakeflow Declarative Pipelines (anteriormente DLT): Solo admite registros de eventos
- Serverless Jobs: No admite la entrega de registros
- Serverless Notebooks: No admite la entrega de registros
Gobernanza de datos
- La gobernanza de datos debe extenderse a los registros del clúster, ya que los registros pueden exponer accidentalmente datos confidenciales. Por ejemplo, cuando escribes registros en una tabla, debes considerar qué usuarios tienen acceso a la tabla y utilizar un diseño de acceso de mínimo privilegio.
- Demostraremos cómo entregar registros de clúster a volúmenes de Unity Catalog para un control de acceso y linaje más sencillos. La entrega de registros a Volúmenes está en Vista Previa Pública y solo se admite en computación habilitada para Unity Catalog con modo de acceso Estándar o modo de acceso Dedicado asignado a un usuario.
- Esta función no se admite en computación con modo de acceso Dedicado asignado a un grupo.
Desglose de la Solución Técnica
La estandarización es clave para la observabilidad de registros de nivel de producción. Idealmente, la solución debería acomodar cientos o incluso miles de trabajos/pipelines/clústeres.
Para la implementación completa de esta solución, visita este repositorio aquí: https://github.com/databricks-industry-solutions/watchtower
Creación de un volumen para la entrega central de registros
Primero, podemos crear un Volumen de Unity Catalog para que sea nuestro almacenamiento de archivos central para los registros. No recomendamos DBFS ya que no proporciona el mismo nivel de gobernanza de datos. Recomendamos separar los registros de cada entorno (por ejemplo, desarrollo, etapa, producción) en diferentes directorios o volúmenes para que el acceso se pueda controlar de manera más granular.
Puedes crearlo en la interfaz de usuario, dentro de un Databricks Asset Bundle (AWS | Azure | GCP), o en nuestro caso, con Terraform:
Asegúrate de tener los permisos READ VOLUME y WRITE VOLUME en el volumen (AWS | Azure | GCP).
Configurar la entrega de registros del clúster
Ahora que tenemos un lugar central para poner nuestros registros, necesitamos configurar los clústeres para que entreguen sus registros a este destino. Para hacer esto, configura la entrega de registros de computación (AWS | Azure | GCP) en el clúster.
Nuevamente, usa la interfaz de usuario, Terraform u otro método preferido; usaremos Databricks Asset Bundles (YAML):
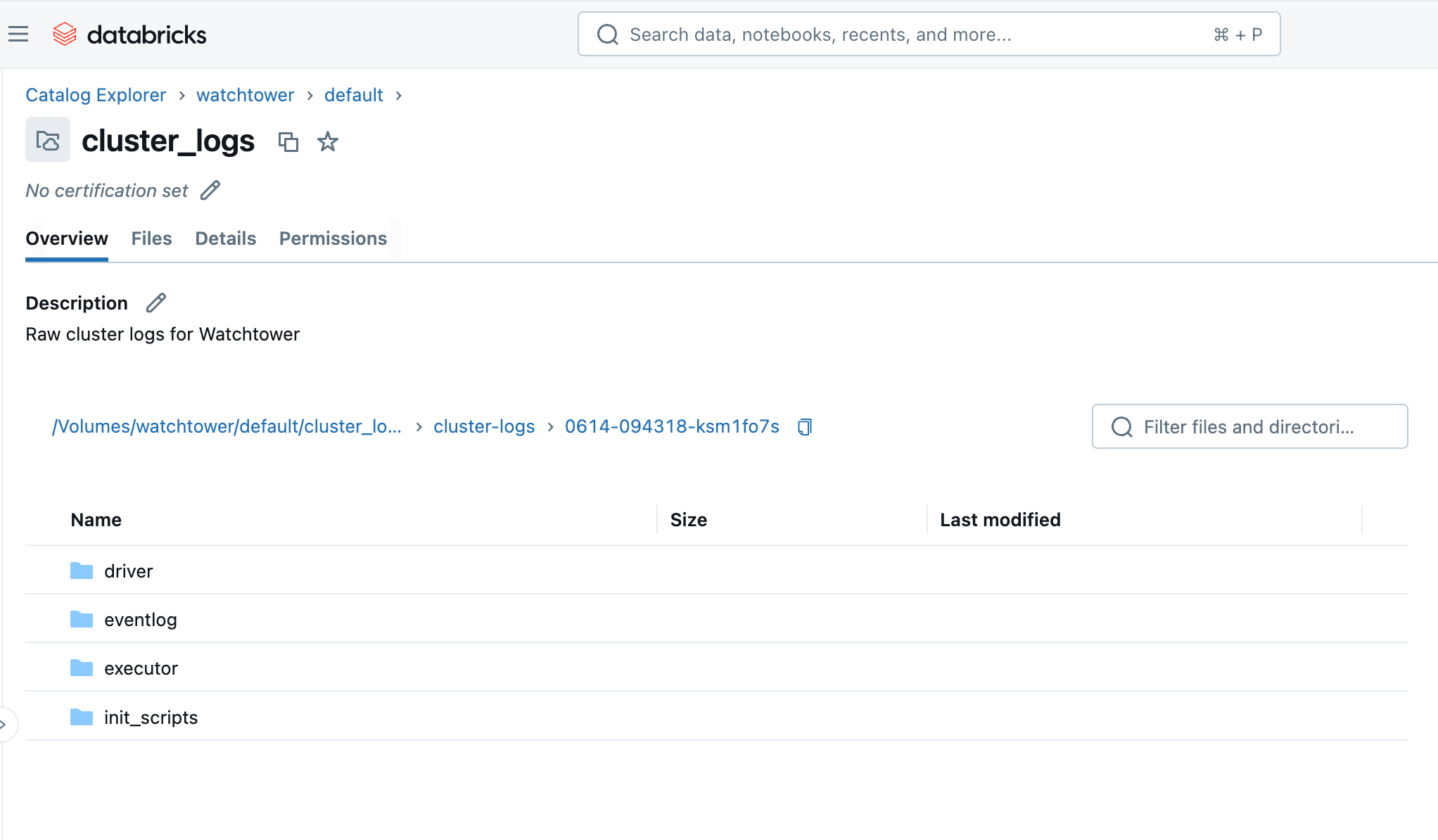
Al ejecutar el clúster o trabajo, en unos minutos, podemos navegar al Volumen en el Catalog Explorer y ver los archivos llegando. Verás una carpeta con el ID del clúster (por ejemplo, 0614-174319-rbzrs7rq), luego carpetas para cada grupo de registros:
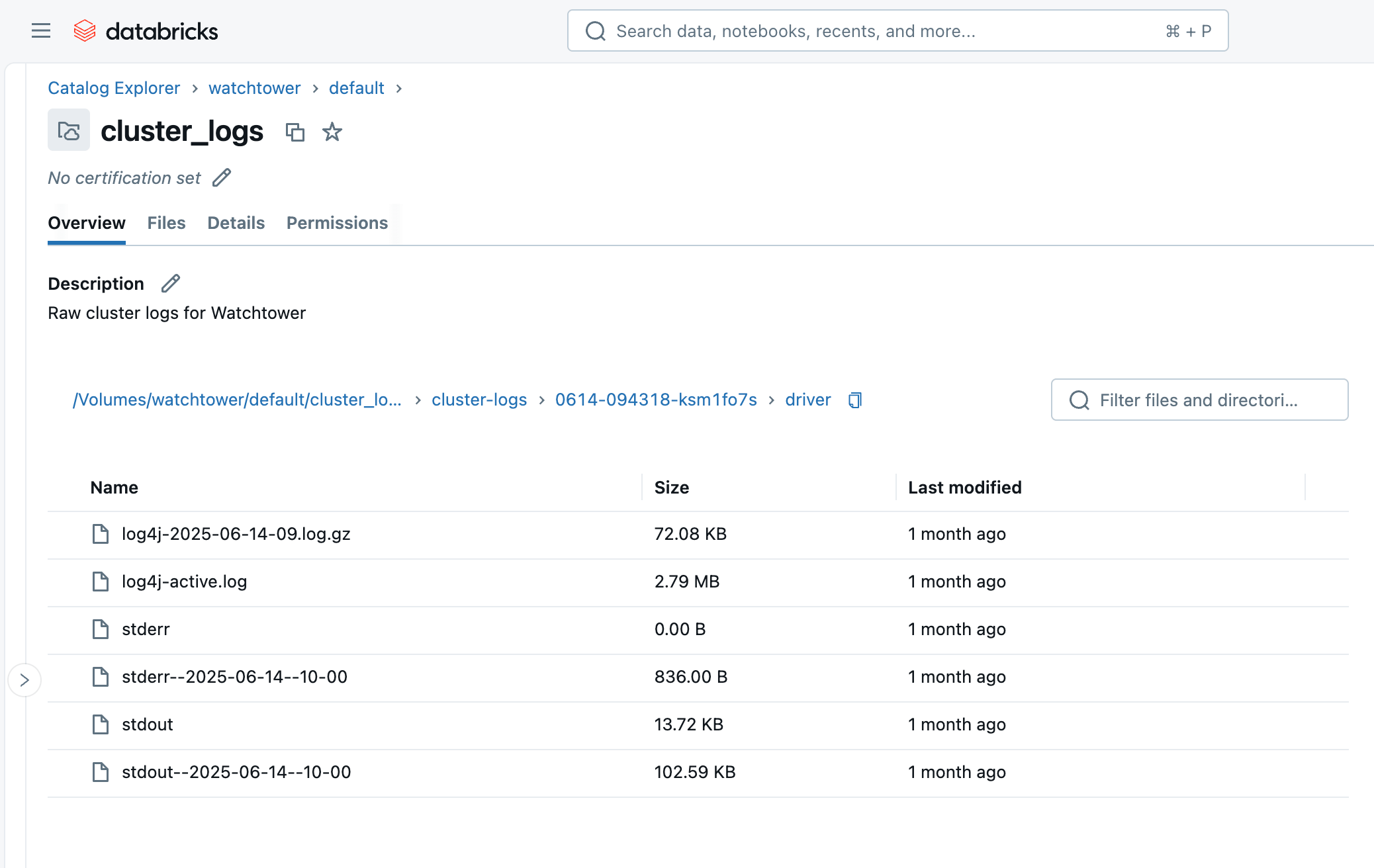
- driver: Registros del nodo Driver, que son los que más nos interesan.
- executor: Registros de cada ejecutor de Spark en el clúster.
- eventlog: registros de eventos que puedes encontrar en la pestaña "Event Log" del clúster, como inicio de clúster, terminación de clúster, redimensionamiento, etc.
- init_scripts: Esta carpeta se genera si el clúster tiene scripts de inicialización, como el nuestro. Se crean subcarpetas para cada nodo del clúster, y luego se pueden encontrar los registros stdout y stderr para cada script de inicialización que se ejecutó en el nodo.
Aplicación de Estándares: Política de Clúster
Los administradores del espacio de trabajo deben aplicar configuraciones estándar siempre que sea posible. Esto significa restringir el acceso a la creación de clústeres y proporcionar a los usuarios una Política de Clúster (AWS | Azure | GCP) con la configuración de registro del clúster establecida en valores fijos como se muestra a continuación:
Al configurar estos atributos con un valor “fijo”, se configura automáticamente el destino de Volumen correcto y se evita que los usuarios olviden o cambien la propiedad.
Ahora, en lugar de configurar explícitamente el cluster_log_conf en el archivo YAML de su paquete de activos, simplemente podemos especificar el ID de la política de clúster a usar:
Más que una simple instrucción print()
Si bien las instrucciones `print()` pueden ser útiles para depurar rápidamente durante el desarrollo, son insuficientes en entornos de producción por varias razones:
- Falta de estructura: Las instrucciones `print()` producen texto no estructurado, lo que dificulta el análisis, la consulta y el procesamiento de registros a gran escala.
- Contexto limitado: A menudo carecen de información contextual esencial como marcas de tiempo, niveles de registro (por ejemplo, INFO, WARNING, ERROR), módulo de origen o ID de trabajo, que son cruciales para una solución de problemas eficaz.
- Sobrecarga de rendimiento: Las instrucciones `print()` excesivas pueden introducir una sobrecarga de rendimiento, ya que desencadenan una evaluación en Spark. Las instrucciones `print()` también escriben directamente en la salida estándar (stdout) sin almacenamiento en búfer ni manejo optimizado.
- Sin control sobre la verbosidad: No existe un mecanismo integrado para controlar la verbosidad de las instrucciones `print()`, lo que resulta en registros demasiado ruidosos o insuficientes en detalle.
Los marcos de registro adecuados, como Log4j para Scala/Java (JVM) o el módulo logging integrado para Python, resuelven todos estos problemas y son preferibles en producción. Estos marcos nos permiten definir niveles de registro o verbosidad, generar formatos legibles por máquinas como JSON y establecer destinos flexibles.
Tenga en cuenta también la diferencia entre stdout, stderr y log4j en los registros del controlador de Spark:
- stdout: Búfer de Salida Estándar de la JVM del nodo controlador. Aquí es donde se escriben las instrucciones `print()` y la salida general por defecto.
- stderr: Búfer de Error Estándar de la JVM del nodo controlador. Aquí es donde se suelen escribir las excepciones/trazas de pila, y muchas bibliotecas de registro también utilizan stderr por defecto.
- log4j: Filtrado específicamente para mensajes de registro escritos con un registrador log4j. Es posible que también vea estos mensajes en stderr.
Python
En Python, esto implica importar el módulo de registro estándar, definir un formato JSON y establecer su nivel de registro.
A partir de Spark 4, o Databricks Runtime 17.0+, se incluye un registrador estructurado simplificado en PySpark: https://spark.apache.org/docs/latest/api/python/development/logger.html. El siguiente ejemplo se puede adaptar a PySpark 4 intercambiando la instancia del registrador por una instancia de `pyspark.logger.PySparkLogger`.
Gran parte de este código es solo para formatear nuestros mensajes de registro de Python como JSON. JSON es semiestructurado y fácil de leer tanto para humanos como para máquinas, lo que apreciaremos cuando ingiramos y consultemos estos registros más adelante en este blog. Si omitiéramos este paso, podríamos terminar confiando en expresiones regulares complejas e ineficientes para adivinar qué parte del mensaje es el nivel de registro frente a una marca de tiempo frente al mensaje, etc.
Por supuesto, esto es bastante verboso para incluirlo en cada notebook o paquete de Python. Para evitar duplicaciones, este código repetitivo puede empaquetarse como código de utilidad y cargarse en sus trabajos de varias maneras:
- Coloque el código repetitivo en un módulo de Python en el espacio de trabajo y utilice las importaciones de archivos del espacio de trabajo (AWS | Azure | GCP) para ejecutar el código al inicio de sus notebooks principales.
- Compile el código repetitivo en un archivo wheel de Python y cárguelo en los clústeres como una Biblioteca (AWS | Azure | GCP).
Scala
Los mismos principios se aplican a Scala, pero usaremos Log4j en su lugar, o más específicamente, la abstracción SLF4j:
Cuando veamos los Registros del Controlador en la UI, encontraremos nuestros mensajes de registro INFO y WARN en Log4j. Esto se debe a que el nivel de registro predeterminado es INFO, por lo que los mensajes DEBUG y TRACE no se escriben.

¡Sin embargo, los registros de Log4j no están en formato JSON! Veremos cómo solucionar eso a continuación.
Registro para Spark Structured Streaming
Para capturar información útil para trabajos de streaming, como métricas de origen y destino de streaming y progreso de la consulta, también podemos implementar `StreamingQueryListener` de Spark.
Luego, registre el oyente de registro con su sesión de Spark:
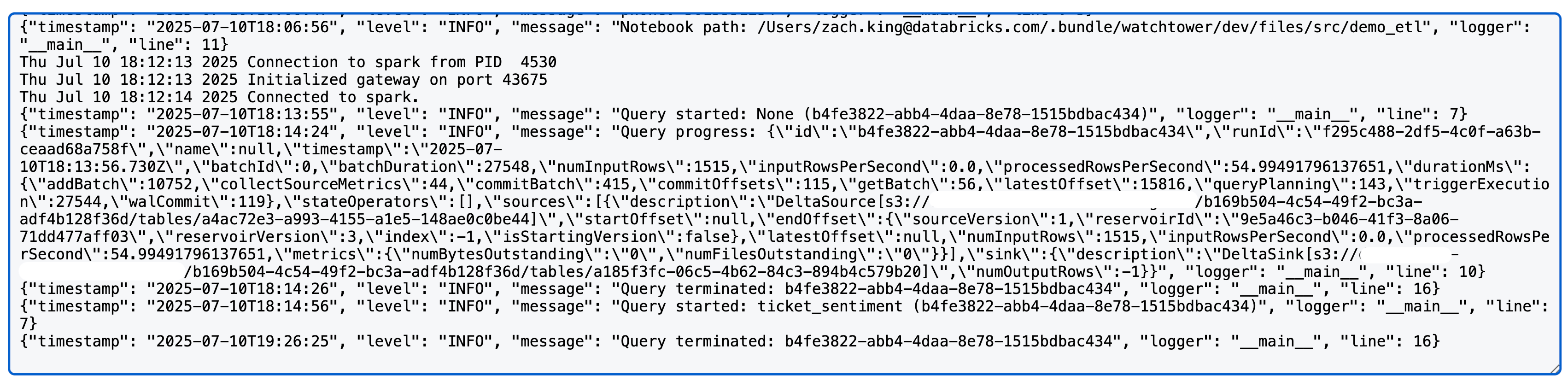
Al ejecutar una consulta de streaming estructurada de Spark, ahora verá algo como lo siguiente en los registros de log4j (nota: usamos una fuente y un destino Delta en este caso; las métricas detalladas pueden variar según la fuente/destino):
Configuración de los registros Spark Log4j
Hasta ahora, solo hemos afectado el registro de nuestro propio código. Sin embargo, al observar los Registros del Controlador del clúster, podemos ver muchos más registros, la mayoría, de hecho, provienen de las internas de Spark. Cuando creamos registradores de Python o Scala en nuestro código, esto no influye en los registros internos de Spark.
Ahora revisaremos cómo configurar los registros de Spark para el nodo Controlador para que utilicen un formato JSON estándar que podamos analizar fácilmente.
Log4j utiliza un archivo de configuración local para controlar el formato y los niveles de registro, y podemos modificar esta configuración utilizando un Script de Inicialización de Clúster (AWS | Azure | GCP). Tenga en cuenta que antes de DBR 11.0, se utilizaba Log4j v1.x, que utiliza un archivo Java Properties (log4j.properties). DBR 11.0+ utiliza Log4j v2.x, que utiliza un archivo XML (log4j2.xml) en su lugar.
El archivo `log4j2.xml` predeterminado en los nodos controladores de Databricks utiliza un `PatternLayout` para un formato de registro básico:
Cambiaremos esto a JsonTemplateLayout usando el siguiente script de inicialización:
Este script de inicialización simplemente reemplaza PatternLayout por JsonTemplateLayout. Ten en cuenta que los scripts de inicialización se ejecutan en todos los nodos del clúster, incluidos los nodos trabajadores; en este ejemplo, solo estamos configurando los registros del controlador por motivos de verbosidad y porque solo ingeriremos los registros del controlador más adelante. Sin embargo, el archivo de configuración también se puede encontrar en los nodos trabajadores en /home/ubuntu/databricks/spark/dbconf/log4j/executor/log4j.properties.
Puedes añadir a este script según sea necesario, o usar cat $LOG4J2_PATH para ver el contenido completo del archivo original para facilitar las modificaciones.
A continuación, cargaremos este script de inicialización en el volumen de Unity Catalog. Para organización, crearemos un volumen separado en lugar de reutilizar nuestro volumen de registros sin procesar de antes, y esto se puede lograr en Terraform de la siguiente manera:
Esto creará el volumen y cargará automáticamente el script de inicialización en él.
Pero todavía necesitamos configurar nuestro clúster para usar este script de inicialización. Anteriormente, usamos una política de clúster para aplicar el destino de entrega de registros, y podemos hacer el mismo tipo de aplicación para este script de inicialización para garantizar que nuestros registros de Spark siempre tengan el formato JSON estructurado. Modificaremos el JSON de la política anterior agregando lo siguiente:
Nuevamente, usar un valor fijo aquí garantiza que el script de inicialización siempre se establecerá en el clúster.
Ahora, si volvemos a ejecutar nuestro código de Spark de antes, ¡podemos ver todos los registros del controlador en la sección Log4j formateados como JSON!
Ingesta de los registros
En este punto, hemos abandonado las declaraciones `print` básicas por el registro estructurado, lo hemos unificado con los registros de Spark y hemos dirigido nuestros registros a un volumen central. Esto ya es útil para explorar y descargar los archivos de registro utilizando el Explorador de Catálogos o Databricks CLI: databricks fs cp dbfs:/Volumes/watchtower/default/cluster_logs/cluster-logs/$CLUSTER_ID . --recursive.
Sin embargo, el verdadero valor de este centro de registro se ve cuando ingerimos los registros en una tabla de Unity Catalog. Esto cierra el ciclo y nos da una tabla contra la cual podemos escribir consultas expresivas, realizar agregaciones e incluso detectar problemas comunes de rendimiento. ¡Todo esto lo veremos en breve!
La ingesta de los registros es fácil gracias a Lakeflow Declarative Pipelines, y emplearemos una arquitectura medallion con Auto Loader para cargar los datos de forma incremental.
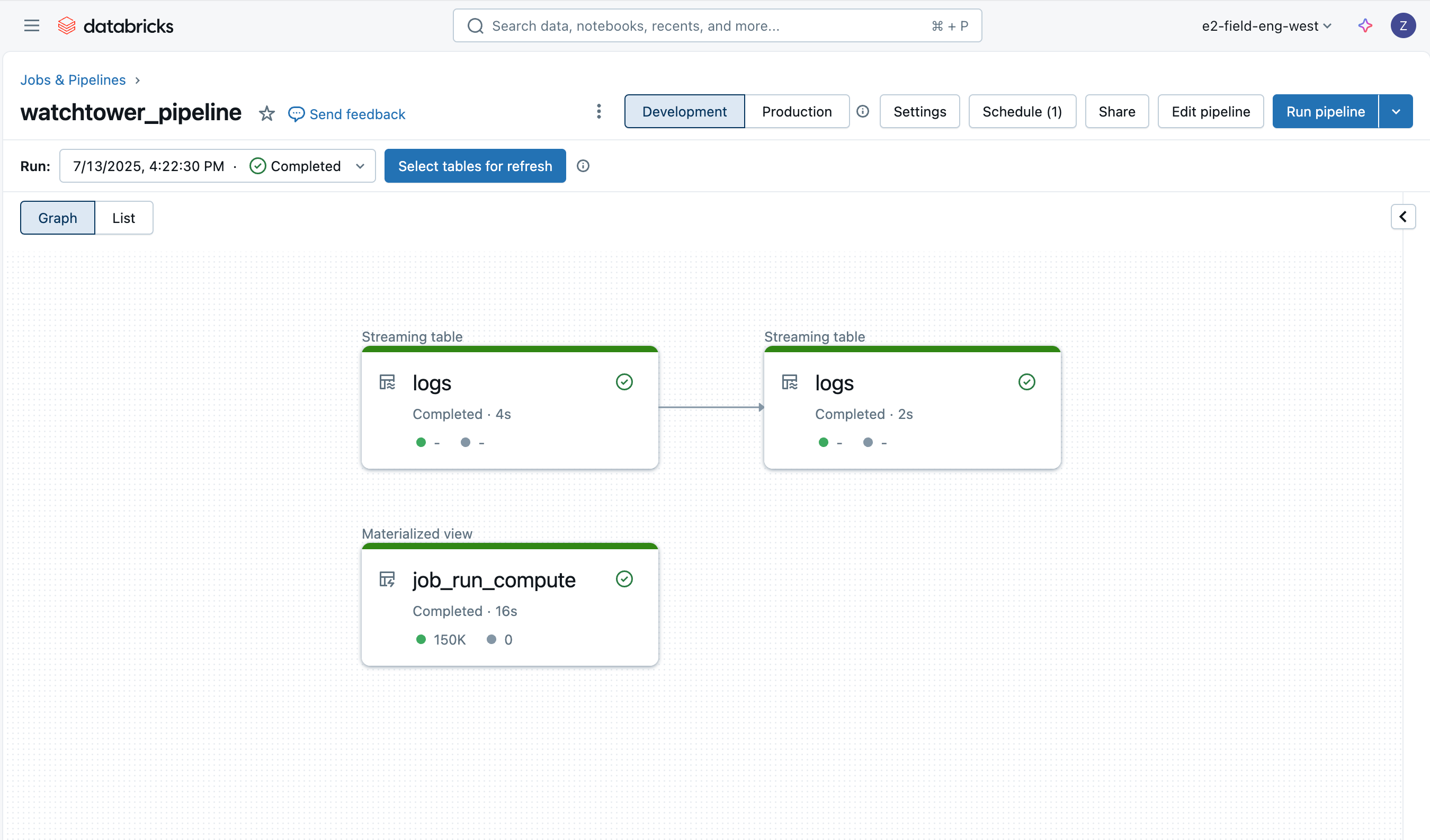
Registros de Bronce
La primera tabla es simplemente una tabla de bronce para cargar los datos brutos de los registros del controlador, agregando algunas columnas adicionales como el nombre del archivo, tamaño, ruta y hora de la última modificación.
Usando las expectativas de Lakeflow Declarative Pipeline (AWS | Azure | GCP), también obtenemos monitoreo nativo de la calidad de los datos. Veremos más de estas verificaciones de calidad de datos en las otras tablas.
Registros de Plata (Silver)
La siguiente tabla (de plata) es más crítica; nos gustaría analizar cada línea de texto de los registros, extrayendo información como el nivel de registro, la marca de tiempo del registro, el ID del clúster y la fuente del registro (stdout/stderr/log4j).
Nota: aunque hemos configurado el registro JSON tanto como ha sido posible, siempre tendremos cierto grado de texto sin procesar en forma no estructurada de otras herramientas iniciadas al arrancar. La mayoría de estas estarán en stdout, y nuestra transformación de plata demuestra una forma de mantener el análisis flexible, intentando analizar el mensaje como JSON y recurriendo a regex solo cuando sea necesario.
IDs de Cómputo
La última tabla de nuestro pipeline es una vista materializada construida sobre las Tablas del Sistema de Databricks. Almacenará los IDs de cómputo utilizados por cada ejecución de trabajo y simplificará las uniones futuras cuando deseemos recuperar el ID del trabajo que produjo ciertos registros. Ten en cuenta que un solo trabajo puede tener múltiples clústeres, así como tareas SQL que se ejecutan en un almacén en lugar de un clúster de trabajo, por lo tanto, la utilidad de precalcular esta referencia.
Despliegue del Pipeline
El pipeline se puede desplegar a través de la UI, Terraform o dentro de nuestro paquete de activos. Usaremos el paquete de activos y proporcionaremos el siguiente YAML de recursos:
Analiza Registros con un Panel de IA/BI
Finalmente, podemos consultar los datos de los registros en todos los trabajos, ejecuciones de trabajos, clústeres y espacios de trabajo. Gracias a las optimizaciones de las tablas administradas de Unity Catalog, estas consultas también serán rápidas y escalables. Veamos un par de ejemplos.
N Errores Principales
Esta consulta encuentra los errores más comunes encontrados, lo que ayuda a priorizar y mejorar el manejo de errores. También puede ser un indicador útil para escribir runbooks que cubran los problemas más comunes.
N Trabajos Principales por Errores
Esta consulta clasifica los trabajos por el número de errores observados, lo que ayuda a encontrar los trabajos más problemáticos.
Panel de IA/BI
Si incorporamos estas consultas en un panel de IA/BI de Databricks, tendremos una interfaz centralizada para buscar y filtrar todos los registros, detectar problemas comunes y solucionar errores.
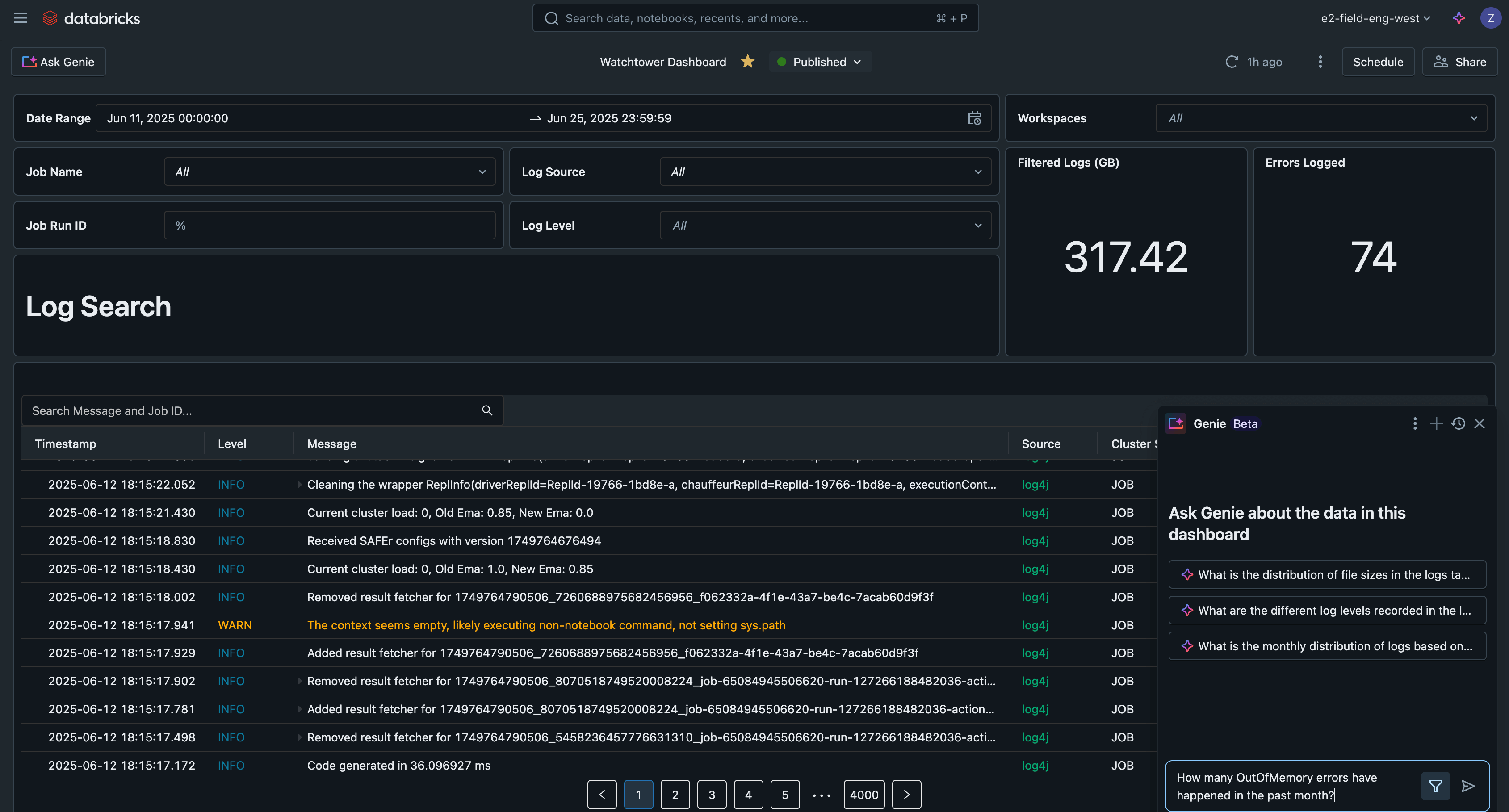
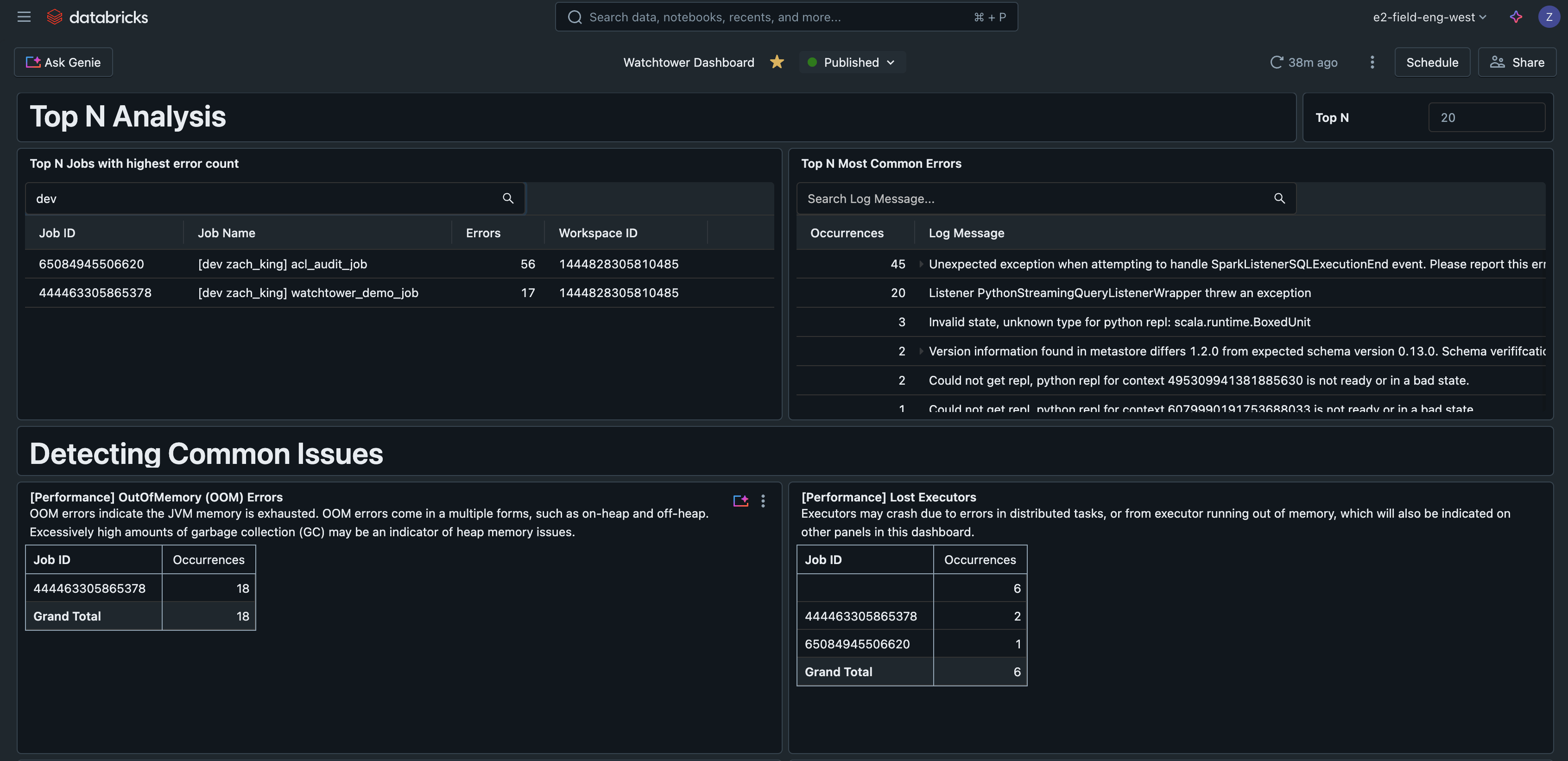
Este panel de IA/BI de ejemplo está disponible junto con todo el código de esta solución en GitHub.
Escenarios del Mundo Real
Como hemos demostrado en el panel de referencia, existen muchos casos de uso prácticos que una solución de registro como esta admite, tales como:
- Buscar registros en todas las ejecuciones de un trabajo individual
- Buscar registros en todos los trabajos
- Analizar registros para identificar los errores más comunes
- Encontrar trabajos con el mayor número de errores
- Monitorizar problemas de rendimiento o advertencias:
- Sobrecarga de GC (Recolección de Basura)
- Desbordamiento de Spark (Spark spill)
- Detectar PII (Información Personalmente Identificable) en los registros
En un escenario realista, los profesionales saltan manualmente de una ejecución de trabajo a otra para entender los errores y no saben cómo priorizar las alertas. Al establecer no solo registros robustos sino también una tabla estándar para almacenarlos, los profesionales pueden simplemente consultar los registros para identificar el error más común y priorizarlo. Supongamos que hay 1 ejecución de trabajo fallida debido a un error de OutOfMemory, mientras que hay 10 trabajos fallidos debido a un error de permiso repentino cuando se revocó involuntariamente el SELECT al principal del servicio; su equipo de guardia normalmente está fatigado por la avalancha de alertas, pero ahora puede darse cuenta rápidamente de que el error de permiso es una prioridad mayor y comienza a trabajar para resolver el problema con el fin de restaurar los 10 trabajos.
De manera similar, los profesionales a menudo necesitan verificar los registros de múltiples ejecuciones del mismo trabajo para hacer comparaciones. Un ejemplo del mundo real es correlacionar las marcas de tiempo de un mensaje de registro específico de cada ejecución por lotes del trabajo, con otra métrica o gráfico (es decir, cuándo se registró el "lote completado" frente a un gráfico de rendimiento de solicitudes en una API que llamó). Ingerir los registros simplifica esto, por lo que podemos consultar la tabla y filtrar por el ID del trabajo, y opcionalmente por una lista de IDs de ejecución de trabajos, sin necesidad de hacer clic en cada ejecución una por una.
Consideraciones Operacionales
- Los registros del clúster se entregan cada cinco minutos y se comprimen (gzipped) cada hora en el destino elegido.
- Recuerde usar tablas administradas por Unity Catalog con Optimización Predictiva y Clustering Líquido para obtener el mejor rendimiento en las tablas.
- Los registros sin procesar no necesitan almacenarse indefinidamente, que es el comportamiento predeterminado cuando se utiliza la entrega de registros del clúster. En nuestro pipeline de Declarative Pipelines, use la opción Auto Loader
cloudFiles.cleanSourcepara eliminar archivos después de un período de retención especificado, también definido comocloudFiles.cleanSource.retentionDuration. También puede usar reglas de ciclo de vida del almacenamiento en la nube. - Los registros del ejecutor también se pueden configurar e ingerir, pero generalmente no son necesarios, ya que la mayoría de los errores se propagan al controlador de todos modos.
- Considere agregar Alertas de Databricks SQL (AWS | Azure | GCP) para alertas automatizadas basadas en la tabla de registros ingerida.
- Lakeflow Declarative Pipelines tienen sus propios registros de eventos, que puede usar para monitorizar e inspeccionar la actividad del pipeline. Este registro de eventos también se puede escribir en Unity Catalog.
Integración y Tareas Pendientes
Los clientes también pueden desear integrar sus registros con herramientas de registro populares como Loki, Logstash o AWS CloudWatch. Si bien cada una tiene sus propios requisitos de autenticación, configuración y conectividad, todas seguirían un patrón muy similar utilizando el script de inicialización del clúster para configurar y, a menudo, ejecutar un agente de reenvío de registros.
Conclusiones Clave
Para recapitular, las lecciones clave son:
- Utilice marcos de registro estandarizados, no declaraciones de impresión, en producción.
- Utilice scripts de inicialización a nivel de clúster para personalizar la configuración de Log4j.
- Configure la entrega de registros del clúster para centralizar los registros.
- Utilice tablas administradas por Unity Catalog con Optimización Predictiva y Clustering Líquido para obtener el mejor rendimiento de las tablas.
- Databricks le permite ingerir y enriquecer registros para un análisis más profundo.
Próximos Pasos
Comience a producir sus registros hoy mismo consultando el repositorio de GitHub para esta solución completa aquí: https://github.com/databricks-industry-solutions/watchtower!
Los Arquitectos de Soluciones de Entrega (DSAs) de Databricks aceleran las iniciativas de Datos e IA en las organizaciones. Proporcionan liderazgo arquitectónico, optimizan las plataformas en cuanto a costo y rendimiento, mejoran la experiencia del desarrollador y impulsan la ejecución exitosa de proyectos. Los DSAs cierran la brecha entre la implementación inicial y las soluciones de nivel de producción, trabajando en estrecha colaboración con varios equipos, incluidos ingeniería de datos, líderes técnicos, ejecutivos y otras partes interesadas para garantizar soluciones personalizadas y un tiempo de valorización más rápido. Para beneficiarse de un plan de ejecución personalizado, orientación estratégica y soporte durante su viaje de datos e IA de un DSA, póngase en contacto con su equipo de cuentas de Databricks.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.