Trazado Nativo de PySpark
Cree visualizaciones directamente desde DataFrames de PySpark con facilidad
por Xinrong Meng y Ruifeng Zheng
- Introducción al trazado nativo de PySpark: Este blog explica la necesidad de capacidades de visualización integradas en PySpark, alineándose con la funcionalidad que los usuarios esperan de la API de Pandas en Spark y los DataFrames nativos de pandas.
- Características y capacidades clave: Explicamos varios tipos de gráficos admitidos, cómo el trazado de PySpark aprovecha estrategias eficientes de procesamiento de datos (por ejemplo, muestreo, métricas globales) y la integración con Plotly para visualizaciones.
- Ejemplo práctico: Demostramos el trazado de PySpark con un ejemplo práctico, guiando a los lectores a través de la creación y personalización de visualizaciones, y destacando los conocimientos prácticos derivados de los gráficos.
Introducción
Nos complace presentar el trazado nativo en PySpark con Databricks Runtime 17.0 (notas de la versión), un emocionante salto adelante para la visualización de datos. Ya no tendrá que saltar entre herramientas solo para visualizar sus datos; ahora, puede crear gráficos atractivos e intuitivos directamente desde sus DataFrames de PySpark. Es rápido, fluido y está integrado. Esta función esperada durante mucho tiempo hace que la exploración de sus datos sea más fácil y potente que nunca.
Trabajar con big data en PySpark siempre ha sido potente, especialmente en lo que respecta a la transformación y el análisis de conjuntos de datos a gran escala. Si bien los DataFrames de PySpark están diseñados para la escala y el rendimiento, los usuarios anteriormente necesitaban convertirlos a DataFrames de la API de Pandas en Apache Spark™ para generar gráficos. Pero este paso adicional hizo que los flujos de trabajo de visualización fueran más complicados de lo necesario. La diferencia en la estructura entre los DataFrames de PySpark y los de estilo pandas a menudo generaba fricción, lo que ralentizaba el proceso de exploración de datos visualmente.
Ejemplo
Aquí hay un ejemplo de uso del trazado de PySpark para analizar las ventas, las ganancias y los márgenes de beneficio en varias categorías de productos.
Comenzamos con un DataFrame que contiene datos de ventas y ganancias para diferentes categorías de productos, como se muestra a continuación:
Nuestro objetivo es visualizar la relación entre las ventas y las ganancias, al mismo tiempo que incorporamos el margen de beneficio como una dimensión visual adicional para que el análisis sea más significativo. Aquí está el código para crear el gráfico:
Tenga en cuenta que “fig” es de tipo “plotly.graph_objs._figure.Figure”. Podemos mejorar su apariencia actualizando el diseño utilizando las funcionalidades existentes de Plotly. La figura ajustada se ve así:
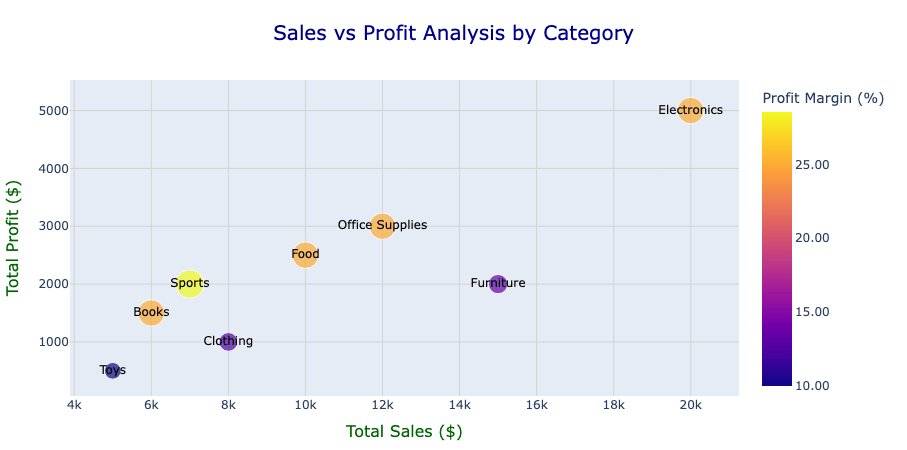
De la figura, podemos observar relaciones claras entre las ventas y las ganancias en diferentes categorías. Por ejemplo, Electronics muestra altas ventas y ganancias con un margen de beneficio relativamente moderado, lo que indica una fuerte generación de ingresos pero con margen para mejorar la eficiencia.
Características del trazado de PySpark
Interfaz de usuario
El usuario interactúa con el trazado de PySpark llamando a la propiedad plot en un DataFrame de PySpark y especificando el tipo de gráfico deseado como submétodo o estableciendo el parámetro “kind”. Por ejemplo:
o de manera equivalente:
Este diseño se alinea con las interfaces de la API de Pandas en Apache Spark y el pandas nativo, proporcionando una experiencia coherente e intuitiva para los usuarios familiarizados con el trazado de pandas.
Tipos de gráficos admitidos
El trazado de PySpark admite una variedad de tipos de gráficos comunes, como gráficos de líneas, barras (incluidas las horizontales), áreas, dispersión, circulares, de caja, histogramas y gráficos de densidad/KDE. Esto permite a los usuarios visualizar tendencias, distribuciones, comparaciones y relaciones directamente desde los DataFrames de PySpark.
Internos
La función está impulsada por Plotly (versión 4.8 o posterior) como el backend de visualización predeterminado, ofreciendo capacidades de trazado ricas e interactivas, mientras que el pandas nativo se utiliza internamente para procesar datos para la mayoría de los gráficos.
Dependiendo del tipo de gráfico, el procesamiento de datos en el trazado de PySpark se maneja a través de una de las tres estrategias:
- Top N Filas: El proceso de trazado utiliza un número limitado de filas del DataFrame (predeterminado: 1000). Esto se puede configurar usando la opción “spark.sql.pyspark.plotting.max_rows”, lo que lo hace eficiente para obtener información rápida. Esto se aplica a los gráficos de barras, gráficos de barras horizontales y gráficos circulares.
- Muestreo: El muestreo aleatorio representa eficazmente la distribución general sin procesar todo el conjunto de datos. Esto garantiza la escalabilidad y al mismo tiempo mantiene la representatividad. Esto se aplica a los gráficos de áreas, gráficos de líneas y gráficos de dispersión.
- Métricas Globales: Para gráficos de caja, histogramas y gráficos de densidad/KDE, los cálculos se realizan en todo el conjunto de datos. Esto permite una representación precisa de las distribuciones de datos, garantizando la corrección estadística.
Este enfoque respeta las estrategias de trazado de la API de Pandas en Apache Spark para cada tipo de gráfico, con mejoras de rendimiento adicionales:
- Muestreo: Anteriormente, se requerían dos pasadas sobre todo el conjunto de datos: una para calcular la relación de muestreo y otra para realizar el muestreo real. Implementamos un nuevo método basado en el muestreo de reservorio, reduciéndolo a una sola pasada.
- Subgráficos: Para los casos en que cada columna corresponde a un subgráfico, ahora calculamos las métricas para todas las columnas juntas, lo que mejora la eficiencia.
- Gráficos basados en ML: Introdujimos expresiones SQL internas dedicadas para estos gráficos, lo que permite optimizaciones del lado de SQL, como la generación de código.
Conclusión
El trazado nativo de PySpark cierra la brecha entre PySpark y la visualización de datos intuitiva. Esta función permite a los usuarios de PySpark crear gráficos de alta calidad directamente desde sus DataFrames de PySpark, lo que hace que el análisis de datos sea más rápido y accesible que nunca. ¡No dude en probar esta función en Databricks Runtime 17.0 para mejorar su experiencia de visualización de datos!
¿Listo para explorar más? Consulte la documentación de la API de PySpark para obtener guías y ejemplos detallados.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.