Clusters compartidos en Unity Catalog para ganar: Presentamos bibliotecas de clústeres, UDF de Python, Scala, Machine Learning y más
por Jakob Mund, Stefania Leone, Martin Grund, Herman van Hövell, Andrew Li y Sven Wagner-Boysen
Nos complace anunciar que puede ejecutar aún más cargas de trabajo en los clústeres multiusuario de alta eficiencia de Databricks gracias a las nuevas funciones de seguridad y gobernanza en Unity Catalog. Los equipos de datos ahora pueden desarrollar y ejecutar cargas de trabajo de SQL, Python y Scala de forma segura en recursos de cómputo compartidos. Con esto, Databricks es la única plataforma en la industria que ofrece control de acceso detallado en cómputo compartido para cargas de trabajo de Scala, Python y SQL Spark.
A partir de Databricks Runtime 13.3 LTS, puede mover sus cargas de trabajo a clústeres compartidos sin problemas, gracias a las siguientes funciones que están disponibles en clústeres compartidos:
- Bibliotecas de clúster y scripts de inicialización: Optimice la configuración del clúster instalando bibliotecas de clúster y ejecutando scripts de inicialización al arrancar, con seguridad y gobernanza mejoradas para definir quién puede instalar qué.
- Scala: Ejecute de forma segura cargas de trabajo de Scala multiusuario junto con Python y SQL, con aislamiento completo del código del usuario entre usuarios concurrentes y aplicando los permisos de Unity Catalog.
- Funciones definidas por el usuario (UDF) de Python y Pandas. Ejecute de forma segura UDF de Python y (escalares) de Pandas, con aislamiento completo del código del usuario entre usuarios concurrentes.
- Machine Learning de un solo nodo: Ejecute scikit-learn, XGBoost, prophet y otras bibliotecas populares de ML utilizando el nodo controlador de Spark, y utilice MLflow para administrar el ciclo de vida completo de machine learning.
- Structured Streaming: Desarrolle soluciones de procesamiento y análisis de datos en tiempo real utilizando structured streaming.
Acceso a datos más fácil en Unity Catalog
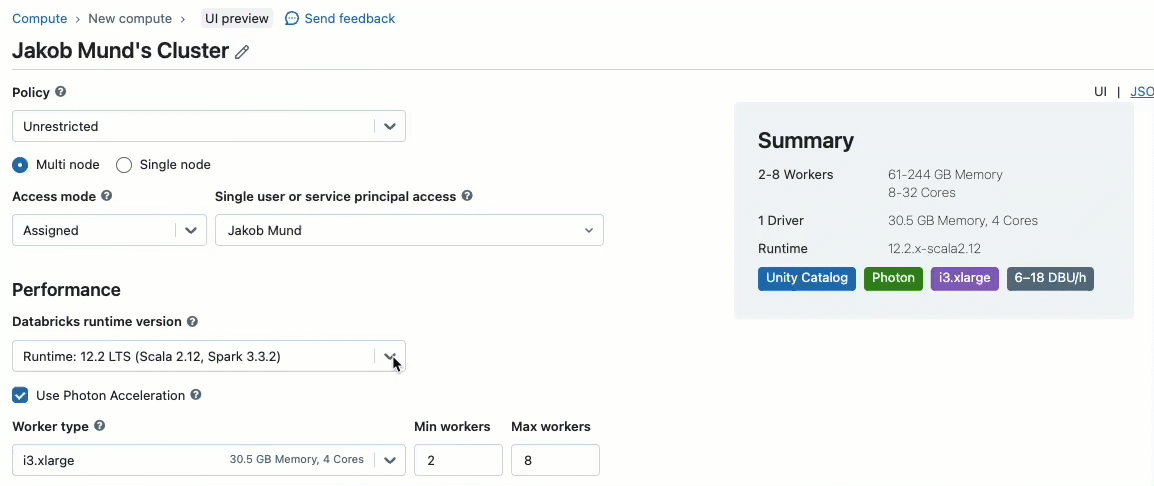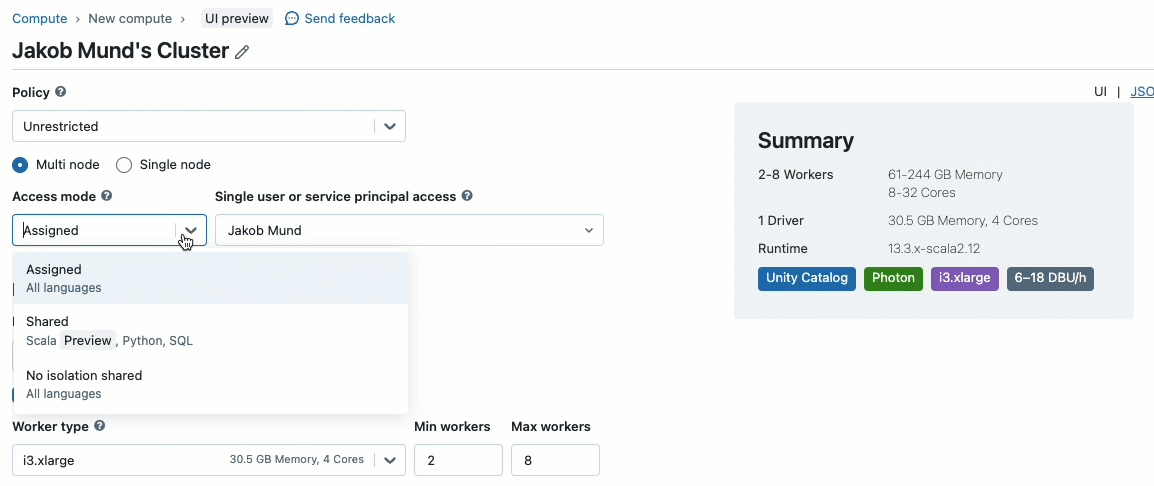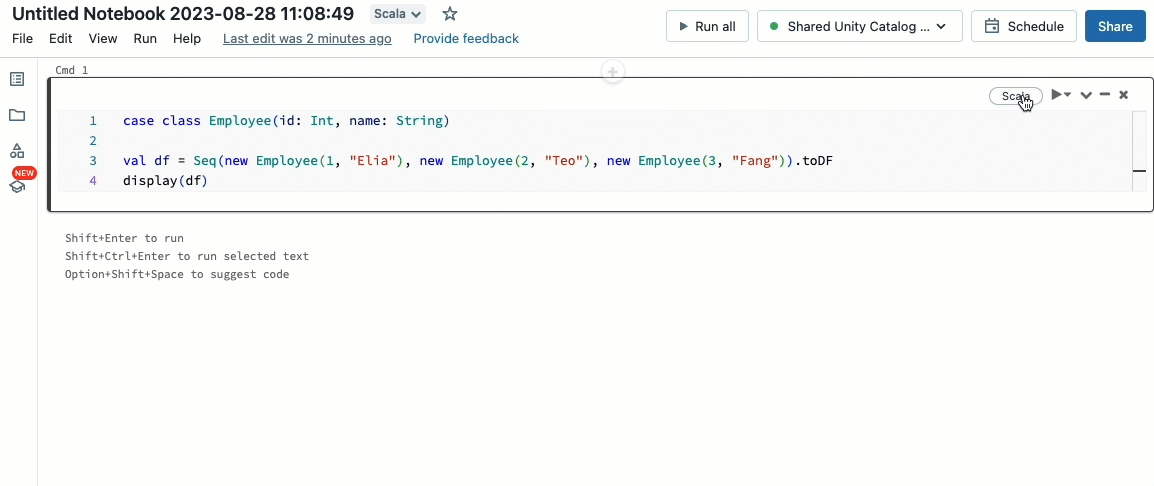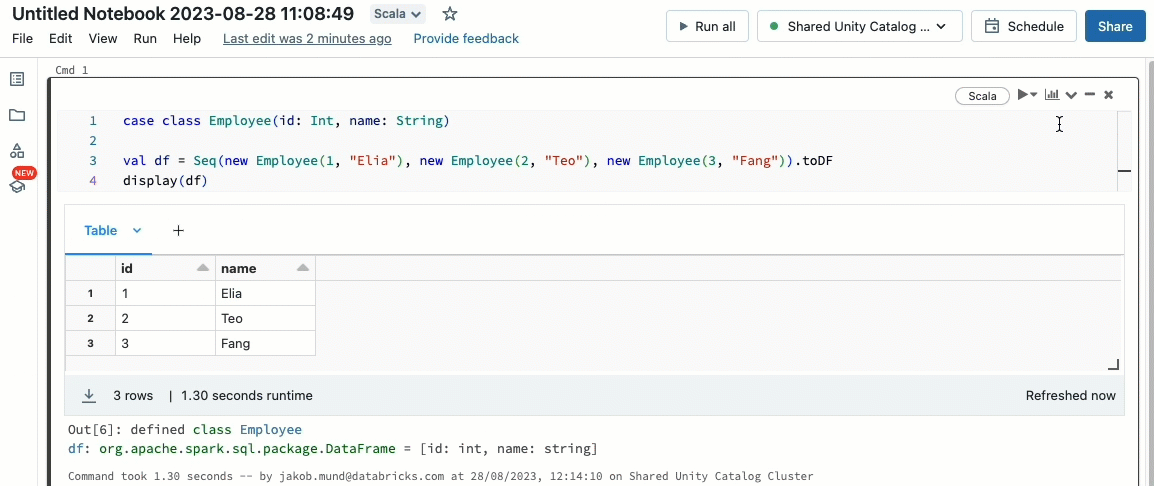
Al crear un clúster para trabajar con datos gobernados por Unity Catalog, puede elegir entre dos modos de acceso:
- Clústeres en modo de acceso compartido – o simplemente clústeres compartidos – son las opciones de cómputo recomendadas para la mayoría de las cargas de trabajo. Los clústeres compartidos permiten que cualquier número de usuarios se conecte y ejecute cargas de trabajo de forma concurrente en el mismo recurso de cómputo, lo que permite importantes ahorros de costos, una gestión simplificada de clústeres y una gobernanza de datos integral que incluye control de acceso detallado. Esto se logra mediante el aislamiento de cargas de trabajo de usuario de Unity Catalog, que ejecuta cualquier código de usuario SQL, Python y Scala en aislamiento completo sin acceso a recursos de nivel inferior.
- Los clústeres en modo de acceso de un solo usuario se recomiendan para cargas de trabajo que requieren acceso privilegiado a la máquina o que utilizan API de RDD, ML distribuido, GPU, Databricks Container Service o R.
Mientras que los clústeres de un solo usuario siguen la arquitectura tradicional de Spark, donde el código del usuario se ejecuta en Spark con acceso privilegiado a la máquina subyacente, los clústeres compartidos garantizan el aislamiento del usuario de ese código. La siguiente figura ilustra la arquitectura y los primitivos de aislamiento únicos para clústeres compartidos: Cualquier código de usuario del lado del cliente (Python, Scala) se ejecuta completamente aislado y las UDF que se ejecutan en los ejecutores de Spark se ejecutan en entornos aislados. Con esta arquitectura, podemos multiplexar de forma segura las cargas de trabajo en los mismos recursos de cómputo y ofrecer una solución colaborativa, rentable y segura al mismo tiempo.
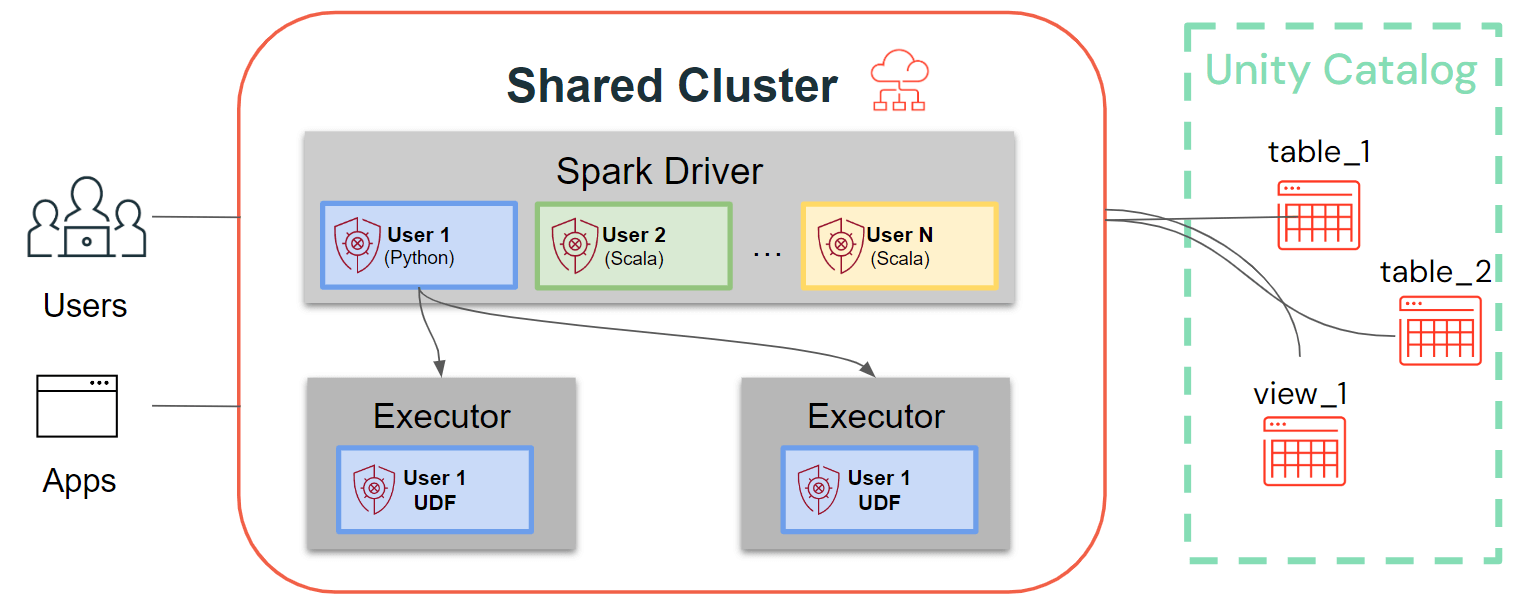
Últimas mejoras para clústeres compartidos: Bibliotecas de clúster, scripts de inicialización, UDF de Python, Scala, ML y compatibilidad con streaming
Configure su clúster compartido utilizando bibliotecas de clúster y scripts de inicialización
Las bibliotecas de clúster le permiten compartir y administrar bibliotecas de forma fluida para un clúster o incluso para varios clústeres, garantizando versiones consistentes y reduciendo la necesidad de instalaciones repetitivas. Ya sea que necesite incorporar marcos de machine learning, conectores de bases de datos u otros componentes esenciales en sus clústeres, las bibliotecas de clúster proporcionan una solución centralizada y sin esfuerzo ahora disponible en clústeres compartidos.
Las bibliotecas se pueden instalar desde volúmenes de Unity Catalog (AWS, Azure, GCP), archivos del espacio de trabajo (AWS, Azure, GCP), PyPI/Maven y ubicaciones de almacenamiento en la nube, utilizando la interfaz de usuario o la API de clúster existente.
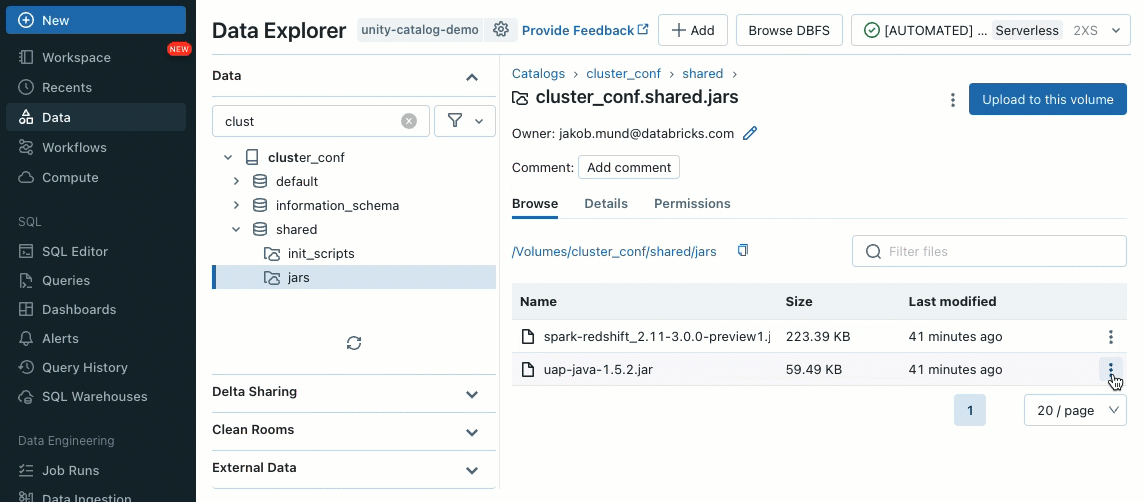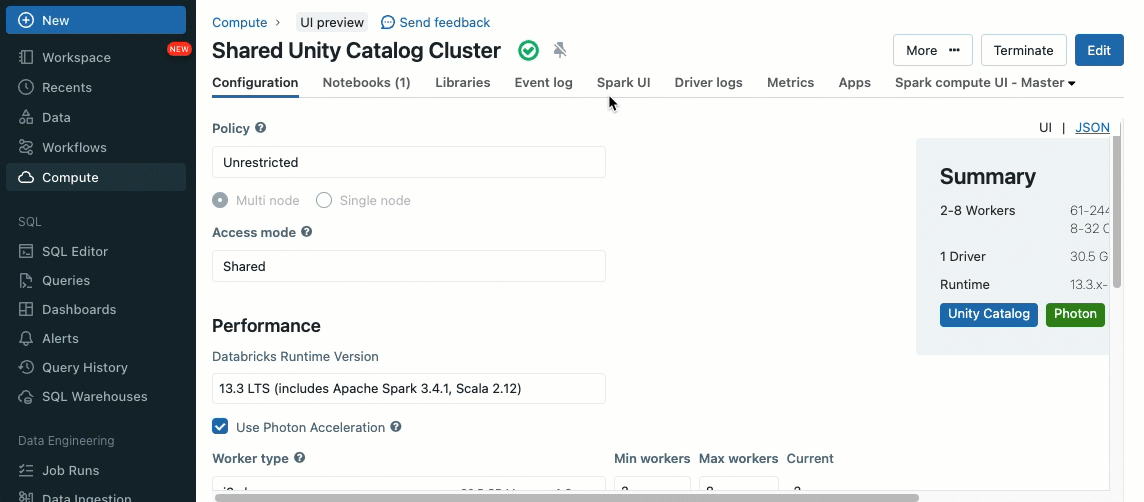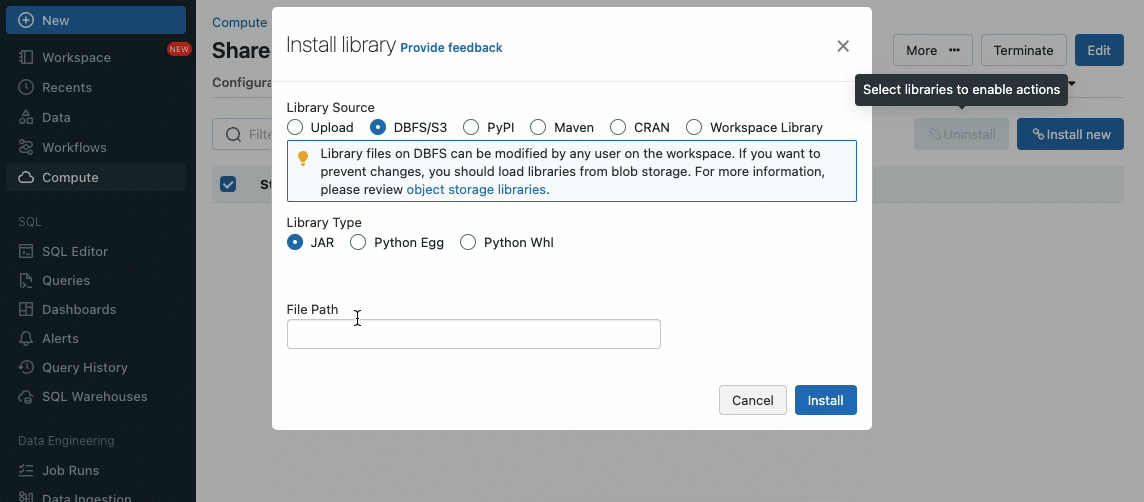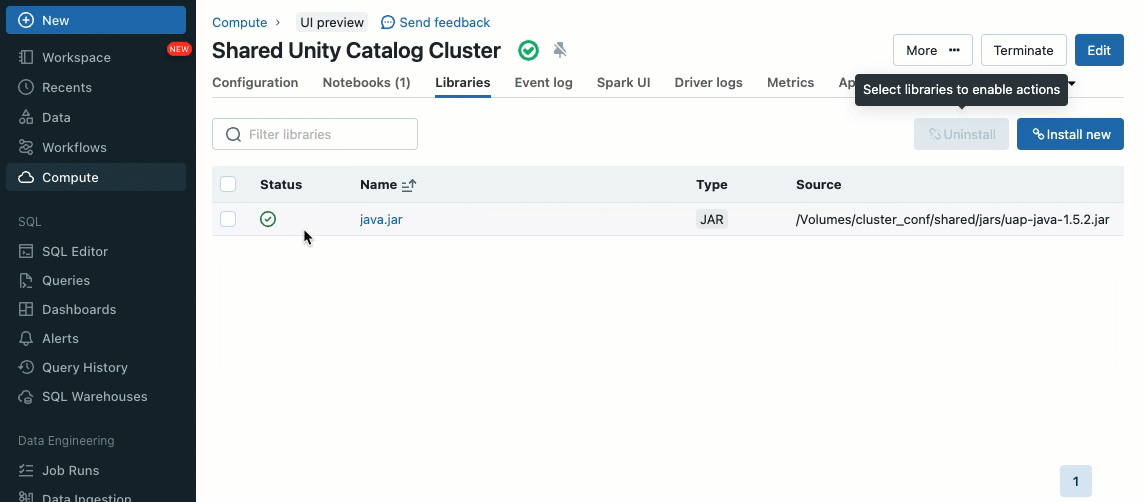
Utilizando scripts de inicialización, como administrador de clúster, puede ejecutar scripts personalizados durante el proceso de creación del clúster para automatizar tareas como la configuración de mecanismos de autenticación, la configuración de ajustes de red o la inicialización de fuentes de datos.
Los scripts de inicialización se pueden instalar en clústeres compartidos, ya sea directamente durante la creación del clúster o para un conjunto de clústeres utilizando políticas de clúster (AWS, Azure, GCP). Para máxima flexibilidad, puede elegir si desea utilizar un script de inicialización de volúmenes de Unity Catalog (AWS, Azure, GCP) o almacenamiento en la nube.
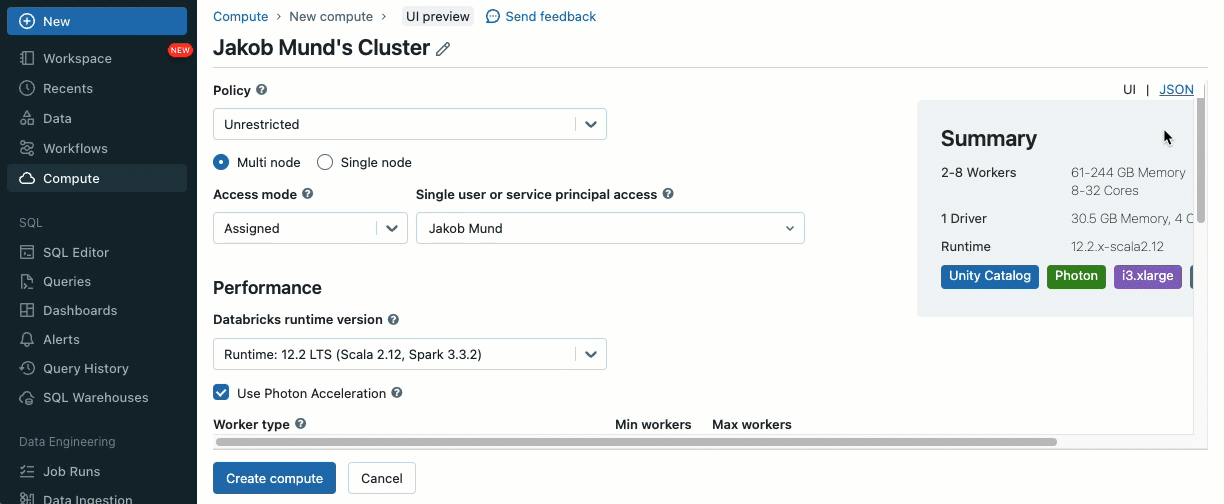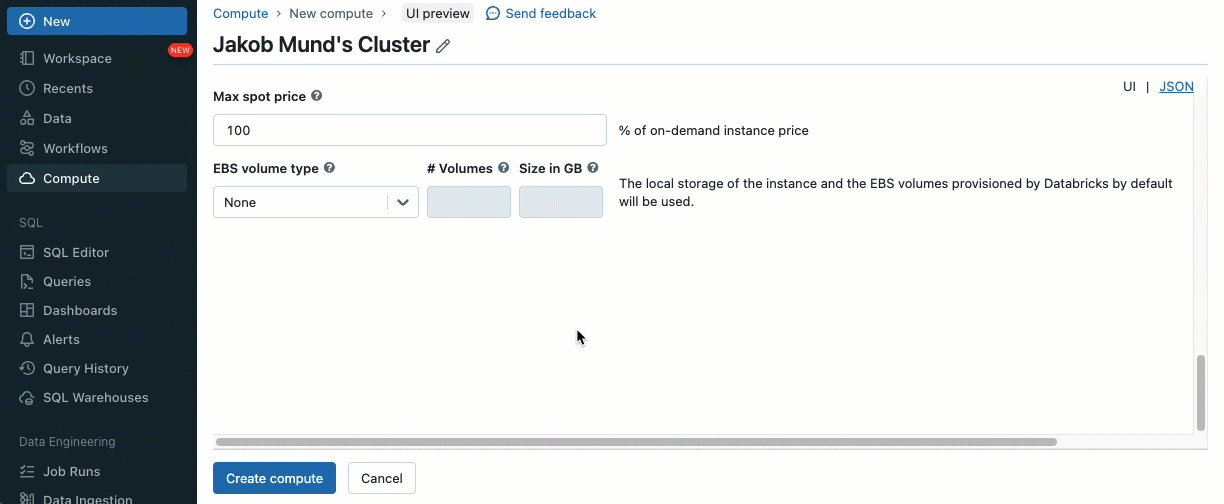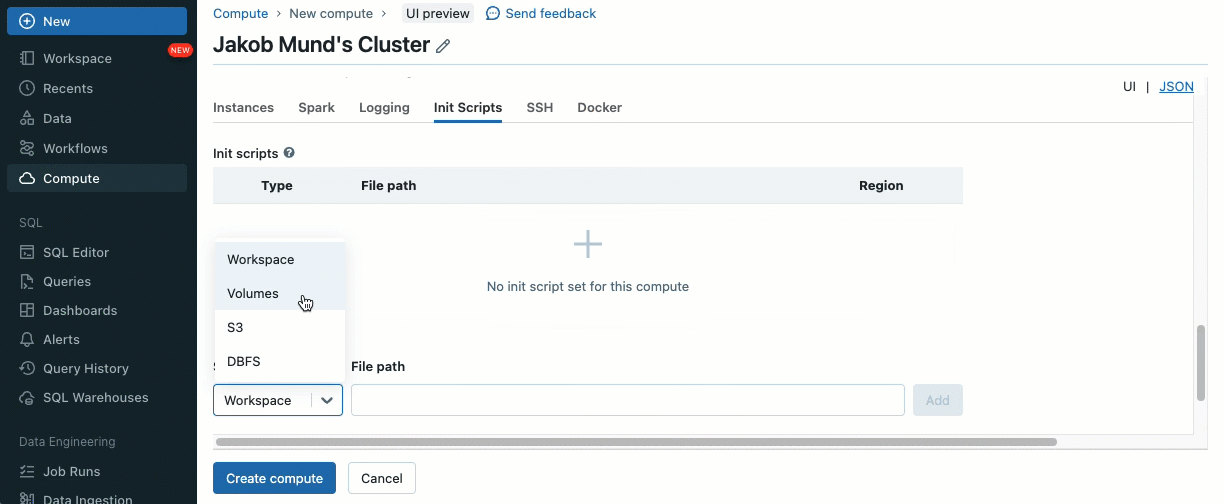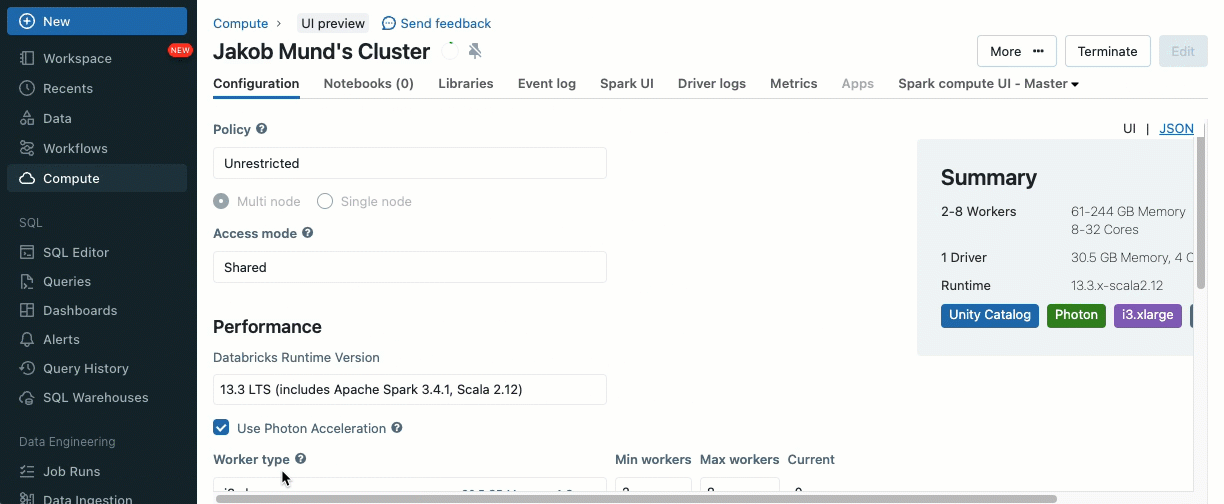
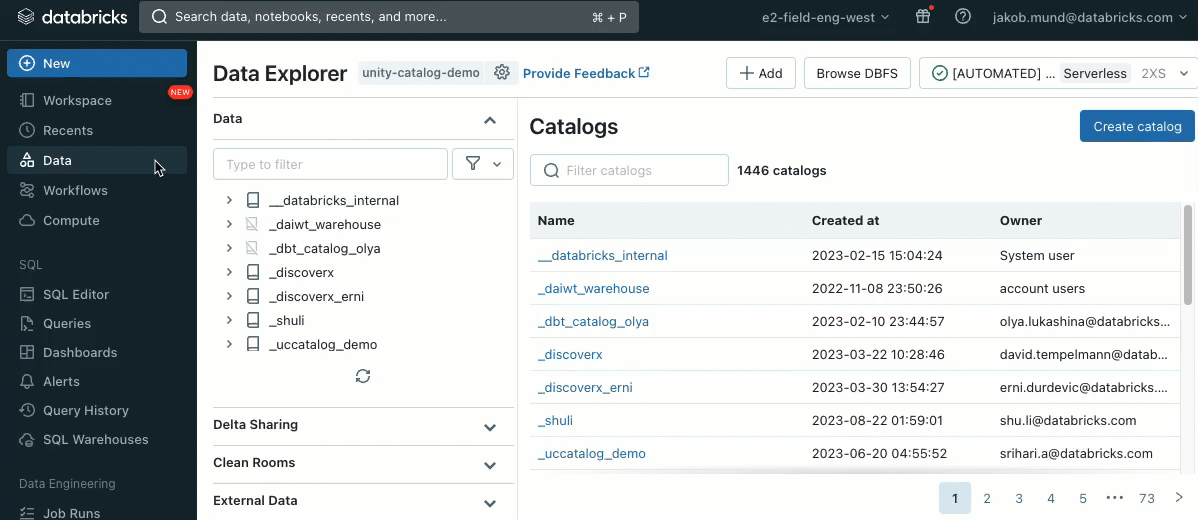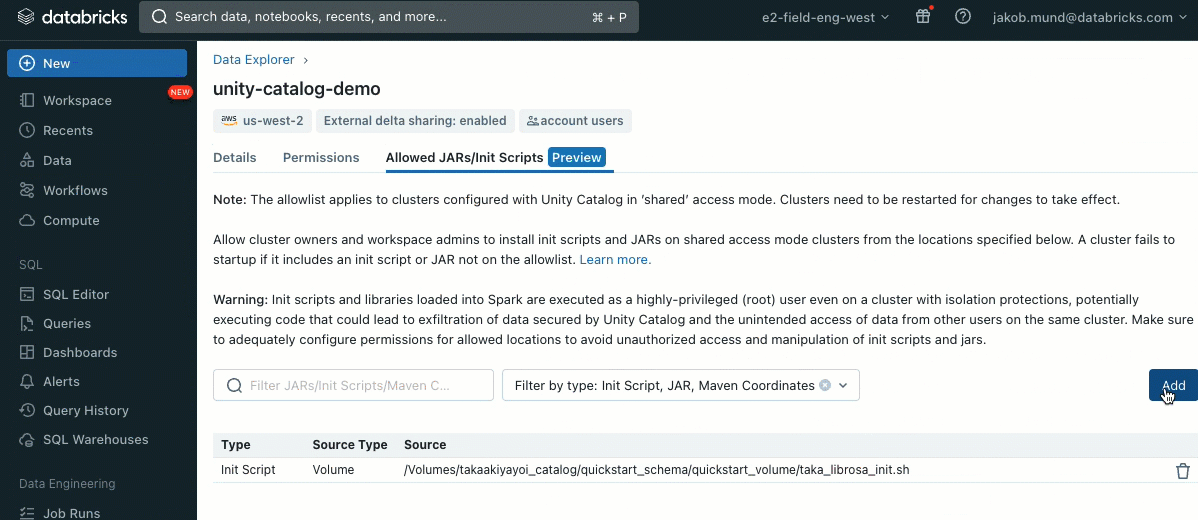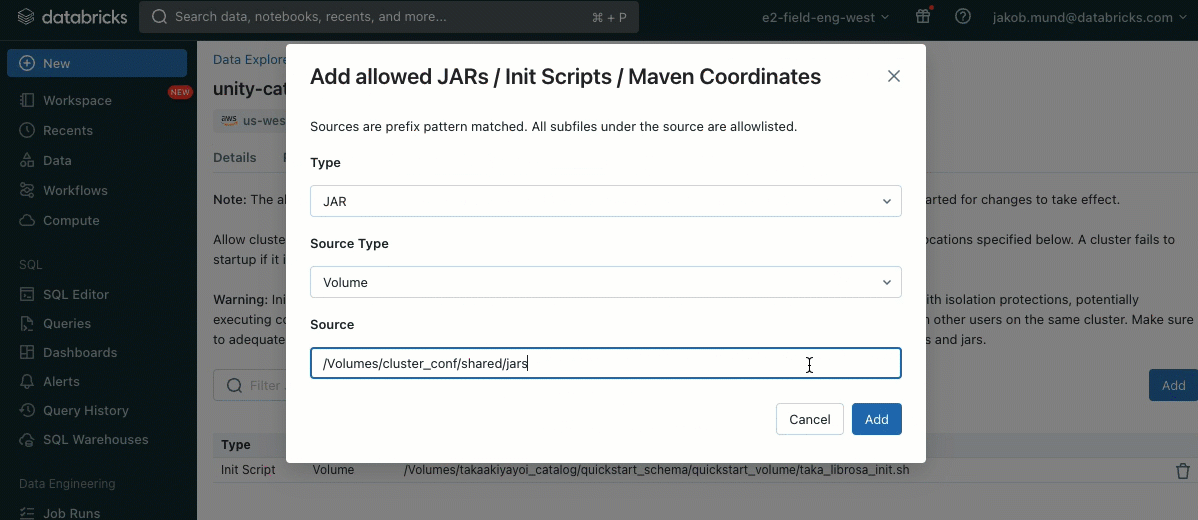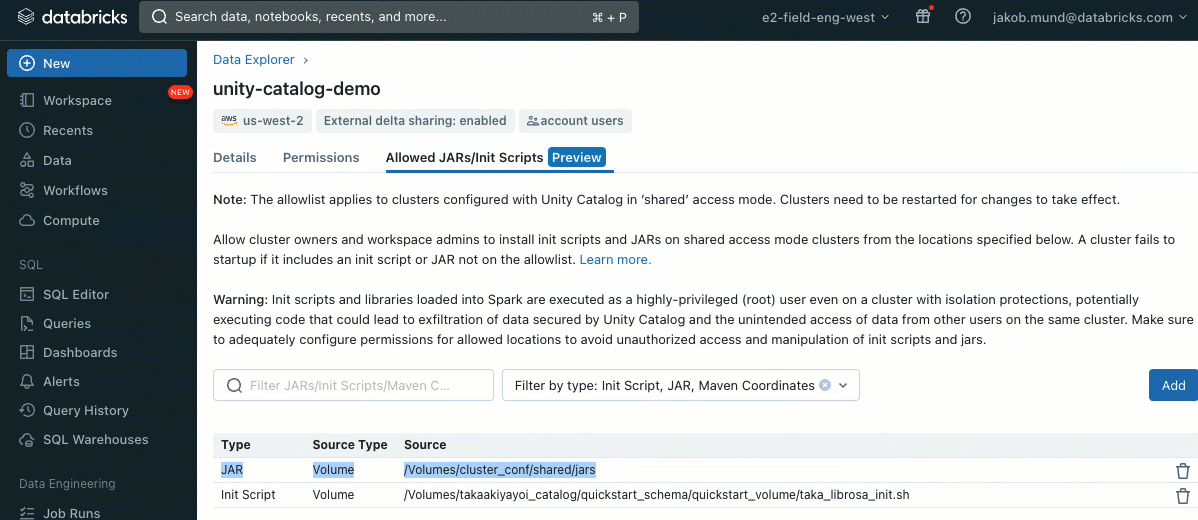
Como capa adicional de seguridad, introducimos una lista de permitidos (AWS, Azure, GCP) que rige la instalación de bibliotecas de clúster (jars) y scripts de inicialización. Esto pone a los administradores en control de gestionarlos en clústeres compartidos. Para cada metastore, el administrador del metastore puede configurar los volúmenes y las ubicaciones de almacenamiento en la nube desde las cuales se pueden instalar bibliotecas (jars) y scripts de inicialización, proporcionando así un repositorio centralizado de recursos confiables y evitando instalaciones no autorizadas. Esto permite un control más granular sobre las configuraciones del clúster y ayuda a mantener la coherencia en los flujos de trabajo de datos de su organización.
Traiga sus cargas de trabajo de Scala
Scala ahora es compatible con clústeres compartidos gobernados por Unity Catalog. Los ingenieros de datos pueden aprovechar la flexibilidad y el rendimiento de Scala para manejar todo tipo de desafíos de big data, de forma colaborativa en el mismo clúster y aprovechando el modelo de gobernanza de Unity Catalog.
Integrar Scala en su flujo de trabajo Databricks existente es muy fácil. Simplemente seleccione Databricks runtime 13.3 LTS o posterior al crear un clúster compartido, y estará listo para escribir y ejecutar código Scala junto con otros lenguajes compatibles.
Aproveche las funciones definidas por el usuario (UDF), Machine Learning y Structured Streaming
¡Eso no es todo! Estamos encantados de presentar más avances que cambian las reglas del juego para los clústeres compartidos.
Compatibilidad con funciones definidas por el usuario (UDF) de Python y Pandas: Ahora puede aprovechar el poder de las UDF de Python y (escalares) de Pandas también en clústeres compartidos. Simplemente traiga sus cargas de trabajo a clústeres compartidos sin problemas, sin necesidad de adaptaciones de código. Al aislar la ejecución del código de usuario de las UDF en los ejecutores de Spark en un entorno aislado, los clústeres compartidos proporcionan una capa adicional de protección para sus datos, evitando el acceso no autorizado y posibles brechas.
Compatibilidad con todas las bibliotecas populares de ML utilizando el nodo controlador de Spark y MLflow: Ya sea que esté trabajando con Scikit-learn, XGBoost, prophet y otras bibliotecas populares de ML, ahora puede crear, entrenar y desplegar modelos de machine learning directamente en clústeres compartidos. Para instalar bibliotecas de ML para todos los usuarios, puede utilizar las nuevas bibliotecas de clúster. Con la compatibilidad integrada con MLflow (2.2.0 o posterior), la gestión del ciclo de vida completo de machine learning nunca ha sido tan fácil.
Structured Streaming ahora también está disponible en clústeres compartidos gobernados por Unity Catalog. Esta adición transformadora permite el procesamiento y análisis de datos en tiempo real, revolucionando la forma en que sus equipos de datos manejan las cargas de trabajo de streaming de forma colaborativa.
Empiece hoy, vendrán más cosas buenas
Descubre el poder de Scala, las bibliotecas de clústeres, las UDF de Python, el ML de un solo nodo y el streaming en clústeres compartidos hoy mismo, simplemente usando Databricks Runtime 13.3 LTS o superior. Consulta las guías de inicio rápido (AWS, Azure, GCP) para obtener más información y comenzar tu viaje hacia la excelencia en datos.
En las próximas semanas y meses, continuaremos unificando la arquitectura de cómputo de Unity Catalog y haremos que sea aún más sencillo trabajar con Unity Catalog.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.