Modelo de Incrustación SOTA para Flujos de Trabajo Agentes Ahora en Vista Previa Pública
Qwen3-Embedding-0.6B es el primer modelo de incrustación multilingüe en Foundation Model Serving con el mejor rendimiento en todas las tareas de incrustación
por Felix Zhu, Cade Daniel y Wai Wu
- Qwen3-Embedding-0.6B ya está disponible en Model Serving, ofreciendo un rendimiento de recuperación de última generación en un modelo compacto de 0.6B optimizado para búsqueda vectorial y cargas de trabajo de agentes de IA.
- El primer modelo de incrustación multilingüe en Databricks, compatible con recuperación translingüe en más de 100 idiomas para datos empresariales globales.
- Las incrustaciones Matryoshka permiten compensaciones flexibles entre costo y rendimiento, permitiendo truncar las incrustaciones de 1024 a 32 dimensiones para una búsqueda más rápida y menores costos de almacenamiento.
La recuperación es la base de los sistemas modernos de IA, y la calidad del modelo de incrustación determina la eficacia con la que las aplicaciones pueden encontrar y razonar sobre los datos empresariales. Hoy lanzamos Qwen3-Embedding-0.6B en Databricks, un modelo de incrustación de última generación que ofrece un sólido rendimiento de recuperación, cobertura multilingüe y despliegue seguro sin servidor.
Junto con Agent Bricks y AI Search, este modelo permite a los equipos crear agentes de IA directamente sobre datos empresariales en Databricks, recuperando contexto relevante y razonando sobre datos gobernados sin mover datos fuera de la plataforma.
Cree Agentes Potenciados por Recuperación con Agent Bricks
Los modelos de incrustación de última generación son una base fundamental para los sistemas modernos de IA, lo que permite a las aplicaciones recuperar el contexto adecuado de grandes colecciones de datos empresariales. Qwen3-Embedding-0.6B, ahora disponible en Databricks, ofrece un sólido rendimiento de recuperación para estas cargas de trabajo.
Qwen3-Embedding-0.6B se basa en el potente fundamento de Qwen3 y proviene del mismo equipo de investigación detrás de la serie GTE ampliamente adoptada. Con una longitud de contexto máxima de 32k tokens, este modelo proporciona una flexibilidad increíble para dividir documentos en varios tamaños diferentes. Además, su diseño consciente de las instrucciones permite a los desarrolladores adaptar el modelo a tareas e idiomas específicos con una simple indicación, lo que generalmente aumenta el rendimiento de la recuperación entre un 1 y un 5 %.
En Databricks, esto se puede combinar con Agent Bricks y AI Search para crear agentes de IA impulsados por recuperación directamente sobre datos empresariales. Los equipos pueden indexar documentos con AI Search y recuperar contexto relevante durante la ejecución del agente, basando los agentes en datos gobernados almacenados en Databricks.
Cómo Este Modelo de Incrustación Mejora los Agentes de IA en Databricks
Qwen3-Embedding-0.6B ofrece una calidad de última generación para su tamaño. En las tablas de clasificación MTEB multilingüe e inglés v2, supera a la mayoría de los otros modelos de clase 0.6B y sobrepasa a los modelos de incrustación insignia de OpenAI y Cohere, al tiempo que compite con modelos mucho más grandes de más de 7B. Esto significa que puede lograr un rendimiento de recuperación de primer nivel sin la latencia y el costo de los modelos muy grandes.
El modelo también ofrece un control detallado sobre el costo y la recuperación a través de Matryoshka Representation Learning (MRL), que concentra la información más importante en las primeras dimensiones del vector. Esto permite truncar de forma segura las incrustaciones para un almacenamiento más económico y una búsqueda más rápida, conservando la mayor parte de la señal. Con Qwen3-Embedding-0.6B, puede elegir cualquier tamaño de incrustación de 32 a 1024 dimensiones en el momento de la solicitud, utilizando vectores más pequeños para índices de recuperación a gran escala y vectores de tamaño completo para una reclasificación de mayor precisión.
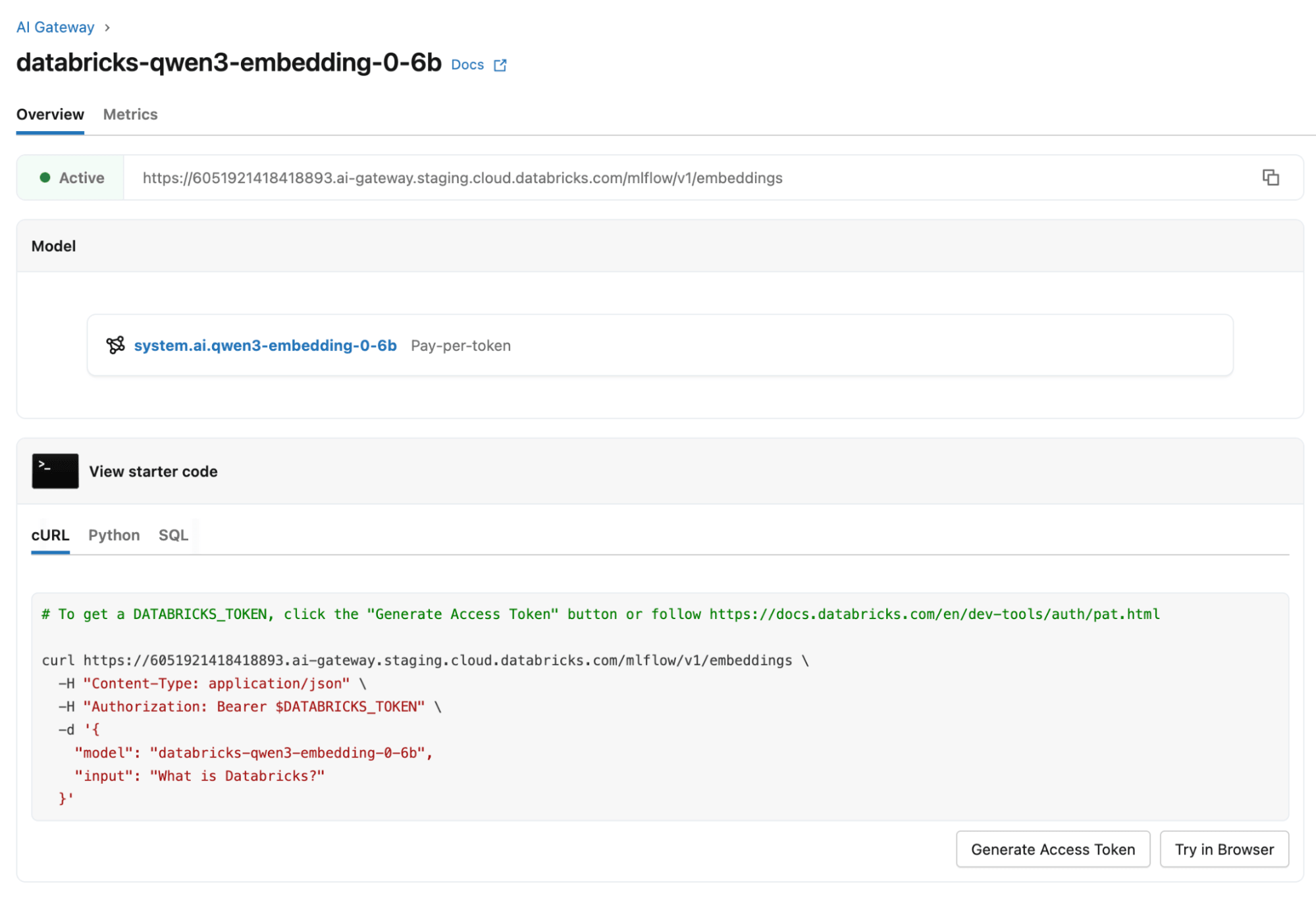
Para usar esta función con databricks-qwen3-embedding-0-6b, establezca el campo opcional dimensions en su solicitud de API REST de Incrustaciones al tamaño de salida deseado (una potencia de dos entre 32 y 1024). Consulte la documentación de la API REST de Modelos Fundacionales para obtener detalles.
Multilingüe por Diseño
Qwen3-Embedding-0.6B es el primer modelo de incrustación multilingüe alojado por Databricks, diseñado desde el principio para cargas de trabajo globales. Si bien muchos modelos de incrustación están orientados al inglés con soporte multilingüe limitado, Qwen3-Embedding-0.6B hereda una amplia cobertura de idiomas del modelo base Qwen3, que fue preentrenado en texto que abarca más de 100 idiomas.
Esto permite un rendimiento sólido no solo para la recuperación en inglés, sino también para tareas multilingües y translingües. Las aplicaciones pueden buscar en un idioma y recuperar resultados en otro, o admitir conjuntos de datos multilingües y recuperación de código en varios lenguajes de programación.
Despliegue Seguro Sin Servidor
Al igual que otros modelos fundacionales alojados por Databricks, Qwen3-Embedding-0.6B se ejecuta en GPU seguras y totalmente administradas sin servidor dentro de la plataforma Databricks.
Simplemente llame a las API de Modelos Fundacionales, y Databricks se encarga del aprovisionamiento, la escalabilidad automática y la fiabilidad. Dado que el modelo se ejecuta en una infraestructura compatible y consciente de la geografía, puede mantener las incrustaciones cerca de sus datos, cumplir con los requisitos de residencia de datos e integrar la recuperación directamente con las cargas de trabajo existentes de Databricks.
¡Pruebe Qwen3-Embedding-0.6B hoy mismo!
Ya sea que esté creando búsqueda semántica, canalizaciones RAG, recuperación multilingüe o sistemas de clasificación de texto, Qwen3-Embedding-0.6B ofrece una combinación excepcional de velocidad, eficiencia y precisión de última generación. Este modelo está disponible como databricks-qwen3-embedding-0-6b en todas las nubes y regiones que admiten Foundation Model Serving, y puede probar este modelo en la página de Databricks Serving. Está disponible en todas las superficies de Model Serving: Pago por Token, Funciones de IA (inferencia por lotes) y Throughput Provisioned. También puede seleccionar este modelo para casos de uso de AI Search.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.