La IA de TabPFN acelera la transformación empresarial en Databricks
Descubra cómo TabPFN en Databricks acelera las predicciones de ML estructurado, elimina los ciclos de reentrenamiento y escala la IA en las operaciones empresariales principales con una gobernanza completa
por Dominik Safari, Philipp Singer, Diana Kriuchkova, Sauraj Gambhir, Ryuta Yoshimatsu , Bryan Smith y Dael Williamson
- Por qué los flujos de trabajo de ML clásico siguen siendo complejos y requieren muchos recursos, y cómo TabPFN cambia eso fundamentalmente
- Cómo Databricks permite a los equipos crear, implementar y gobernar las predicciones de TabPFN directamente junto a los datos de Lakehouse
- El valor empresarial que se obtiene: tiempo de predicción más rápido, reducción de la sobrecarga de la ciencia de datos y una adopción más amplia del ML en las operaciones principales
Hoy en día, es difícil encontrar una revista de negocios, una llamada sobre resultados trimestrales, un informe técnico del sector o una presentación de estrategia sobre la transformación empresarial que no se centre en la inteligencia artificial (IA). La IA moderna representa un cambio fundamental en la forma en que las organizaciones abordan el consumo, la interpretación y la generación de contenido, lo que permite a las empresas aumentar y automatizar una amplia gama de tareas que antes requerían una gran pericia y años de conocimientos especializados.
Pero a pesar de toda la atención que ha recibido la capacidad de la IA para comprender y producir contenido no estructurado, es decir, textos, imágenes, audio, etc., muchísimos procesos empresariales básicos han dependido durante mucho tiempo del Machine Learning (ML) clásico, una tecnología diferente aunque relacionada, que produce etiquetas predictivas a partir de entradas de datos estructurados (Figura 1). Hasta ahora, el poder transformador de la IA ha dejado el ML clásico prácticamente sin cambios.
La persistencia de los flujos de trabajo de ML tradicionales se debe a su complejidad inherente y su intensidad de trabajo. Los científicos de datos suelen dedicar más del 80 % de su tiempo a actividades que ocurren incluso antes de que comience el entrenamiento del modelo: preparar y validar entradas de datos estructurados, crear características y seleccionar la clase de modelo correcta. Además, a medida que cambian las distribuciones de datos subyacentes y el rendimiento del modelo se degrada con el tiempo, este trabajo no es una inversión única, sino un ciclo continuo de monitoreo, depuración y reentrenamiento.
A gran escala, este desafío se intensifica. Las organizaciones que implementan cientos, si no miles, de modelos de ML dependen de marcos de experimentación automatizados para evaluar miles de combinaciones de parámetros. Pero ni siquiera la automatización puede superar las limitaciones fundamentales de los recursos.
La realidad es clara: las empresas deben elegir qué modelos reciben atención para su optimización y cuáles funcionan "lo suficientemente bien", dados los recursos limitados y la necesidad de obtener resultados empresariales rápidamente. Pero la aparición de nuevos modelos de IA centrados en entradas de datos estructurados y salidas predictivas podría ofrecer por fin un camino a seguir.
Video 1. Interacción con el modelo TabPFN como parte del acelerador de soluciones de Databricks
Presentamos TabPFN, un modelo de IA para el machine learning
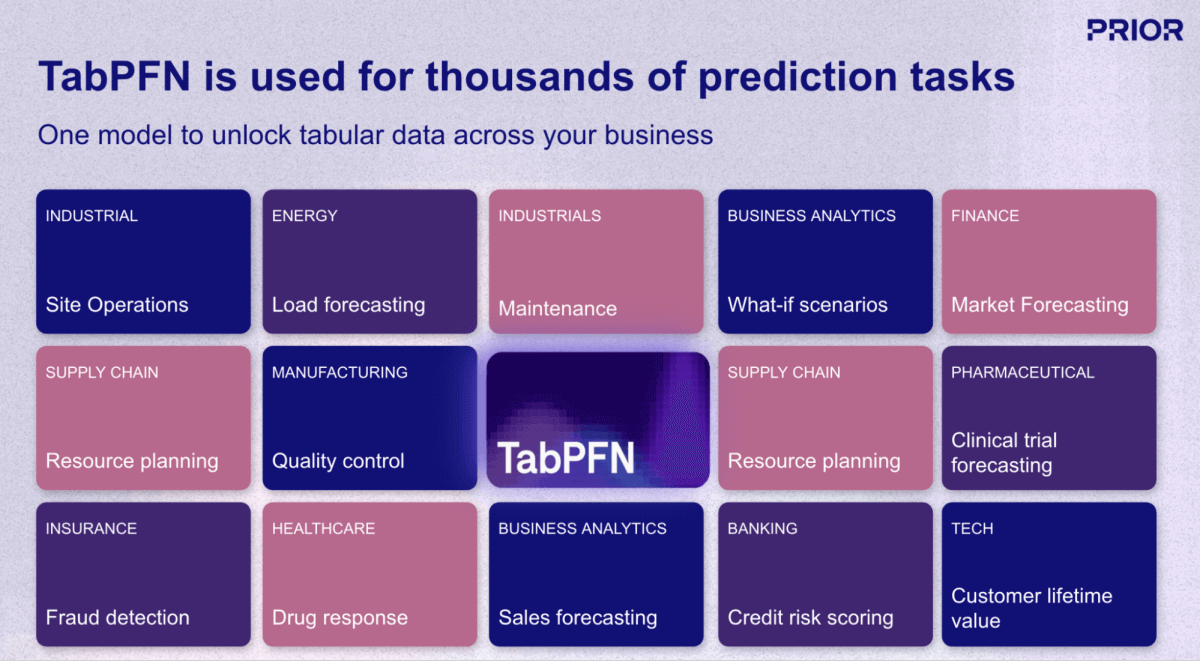
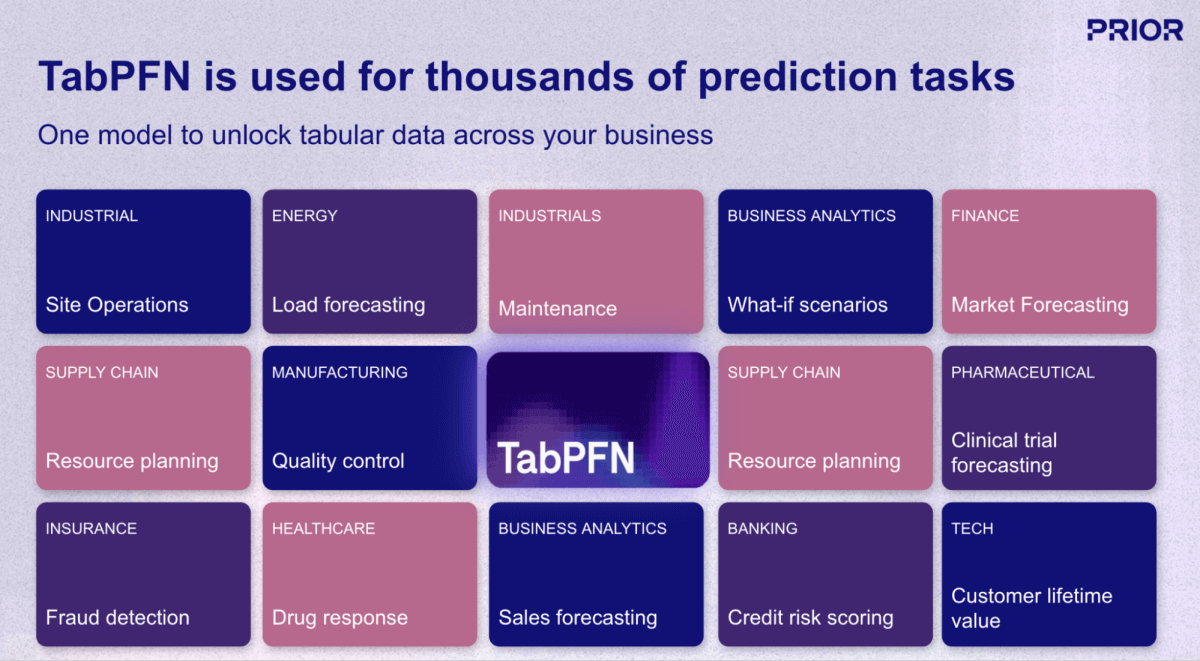
Uno de los desarrollos más prometedores en este espacio es TabPFN, un modelo de base (IA) de Prior Labs que reinventa fundamentalmente el flujo de trabajo del machine learning (ML) para datos estructurados. A diferencia de los enfoques de ML tradicionales que requieren construir y entrenar un modelo único para cada tarea de predicción, TabPFN aplica el mismo paradigma de "preentrenado y listo para usar" de los LLM a los datos empresariales tabulares. El modelo fue preentrenado con más de 130 millones de conjuntos de datos sintéticos, aprendiendo eficazmente a "aprender a aprender" a partir de datos estructurados en prácticamente cualquier dominio o caso de uso (Figura 1).
{kind=link}
Acortar los plazos del ML
Las implicaciones para la productividad del ML son drásticas. Mientras que los enfoques tradicionales requieren que los científicos de datos inviertan horas o días en la preparación de datos, la creación de características, la selección de modelos y el ajuste de hiperparámetros, TabPFN ofrece predicciones de nivel de producción en una única pasada hacia adelante, que generalmente se mide en segundos.
El modelo maneja las entradas sin procesar directamente, gestionando automáticamente los valores faltantes, los tipos de datos mixtos, las características categóricas y de texto, y los valores atípicos sin requerir el preprocesamiento exhaustivo que normalmente consume la mayor parte del esfuerzo de la ciencia de datos. Quizás lo más importante es que TabPFN elimina la carga de mantenimiento continuo del reentrenamiento de modelos: a medida que se dispone de nuevos datos, las organizaciones simplemente actualizan el contexto del modelo en lugar de iniciar un nuevo ciclo de entrenamiento.
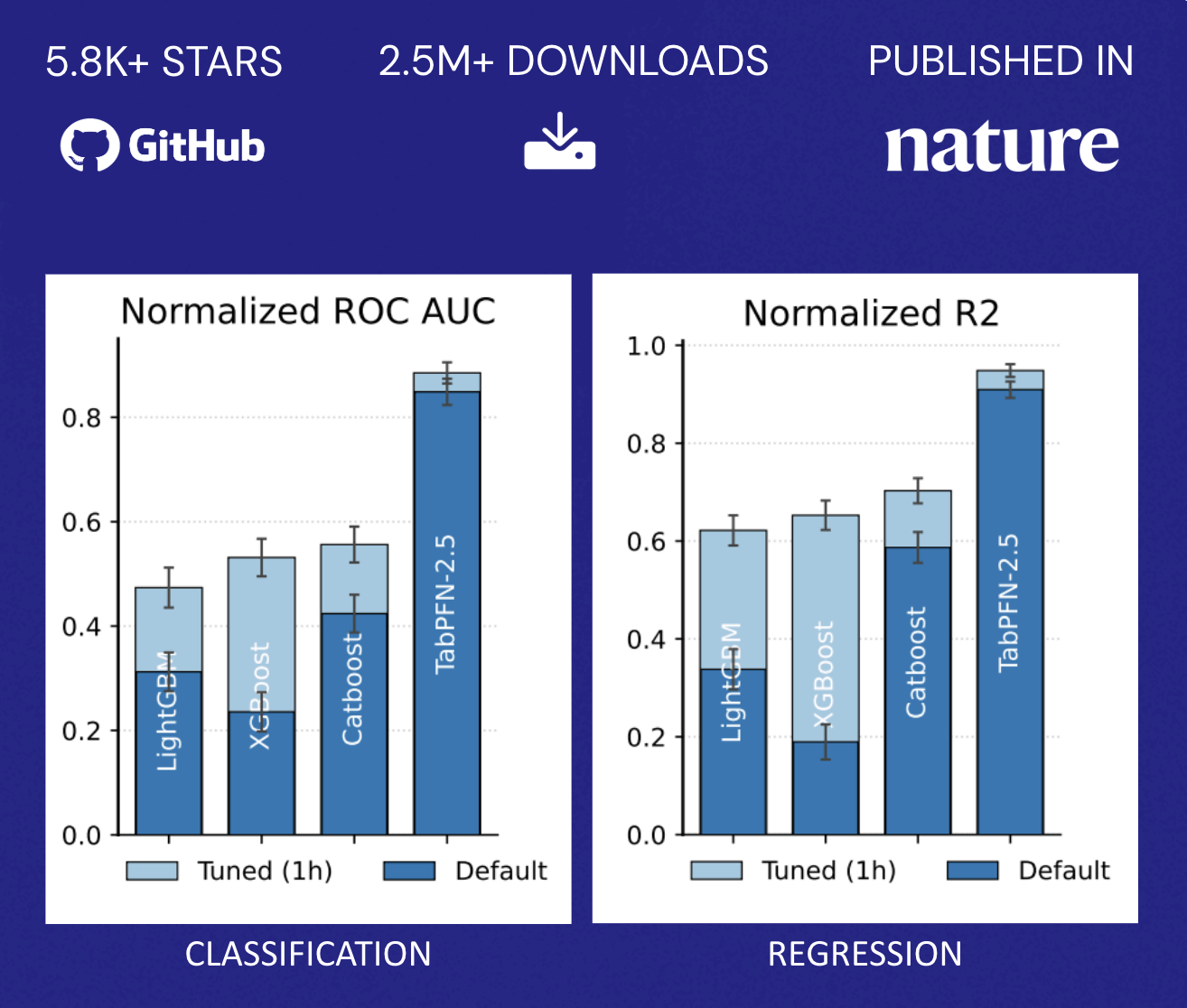
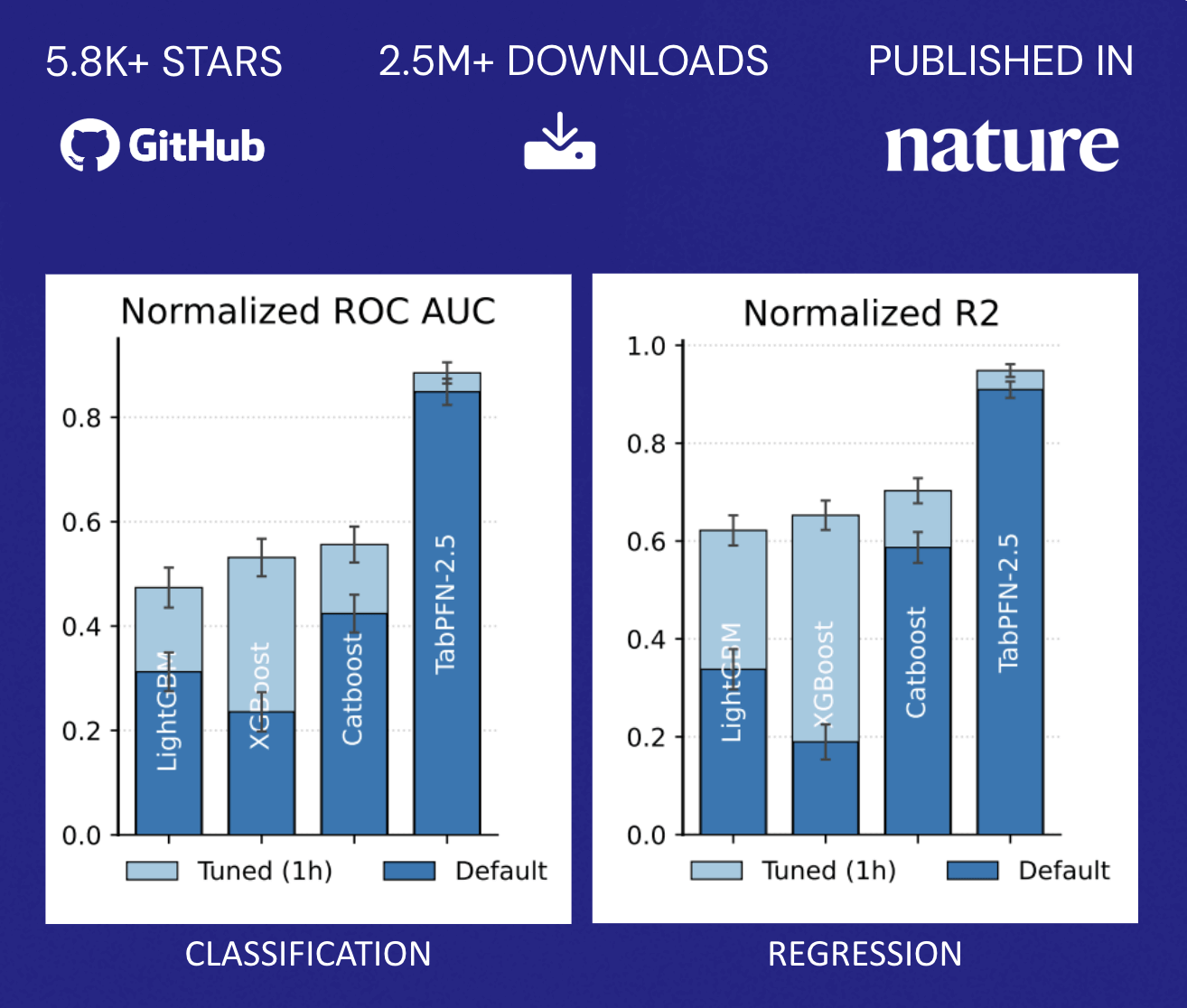
Rendimiento sin concesiones
TabPFN supera la precisión de los métodos tradicionales que requieren horas de ajuste automatizado. Este perfil de rendimiento altera fundamentalmente la economía descrita anteriormente: las organizaciones ya no se enfrentan a una elección binaria entre la precisión del modelo y la asignación de recursos. En su lugar, pueden implementar rápidamente capacidades predictivas en una gama más amplia de casos de uso sin escalar proporcionalmente sus equipos de ciencia de datos, democratizando el ML más allá del puñado de aplicaciones de mayor valor que normalmente justifican los esfuerzos de optimización dedicados (Figura 2).
{kind=link}
Escalando el impacto de la IA a la predicción estructurada
Actualmente, TabPFN admite conjuntos de datos de hasta 100 000 filas y 2000 características, con versiones empresariales que se extienden a 10 millones de filas, lo que cubre la gran mayoría de los casos de uso de ML operativo en el sector minorista, las finanzas, la atención médica, la fabricación y otras industrias. Para las organizaciones que buscan operacionalizar la IA más allá de la generación de contenido y las tareas de lenguaje natural, los modelos de base como TabPFN representan la pieza que falta, aportando las mismas mejoras de productividad escalonadas a los datos estructurados y al análisis predictivo que durante mucho tiempo han sido la columna vertebral de la toma de decisiones basada en datos (Figura 3).
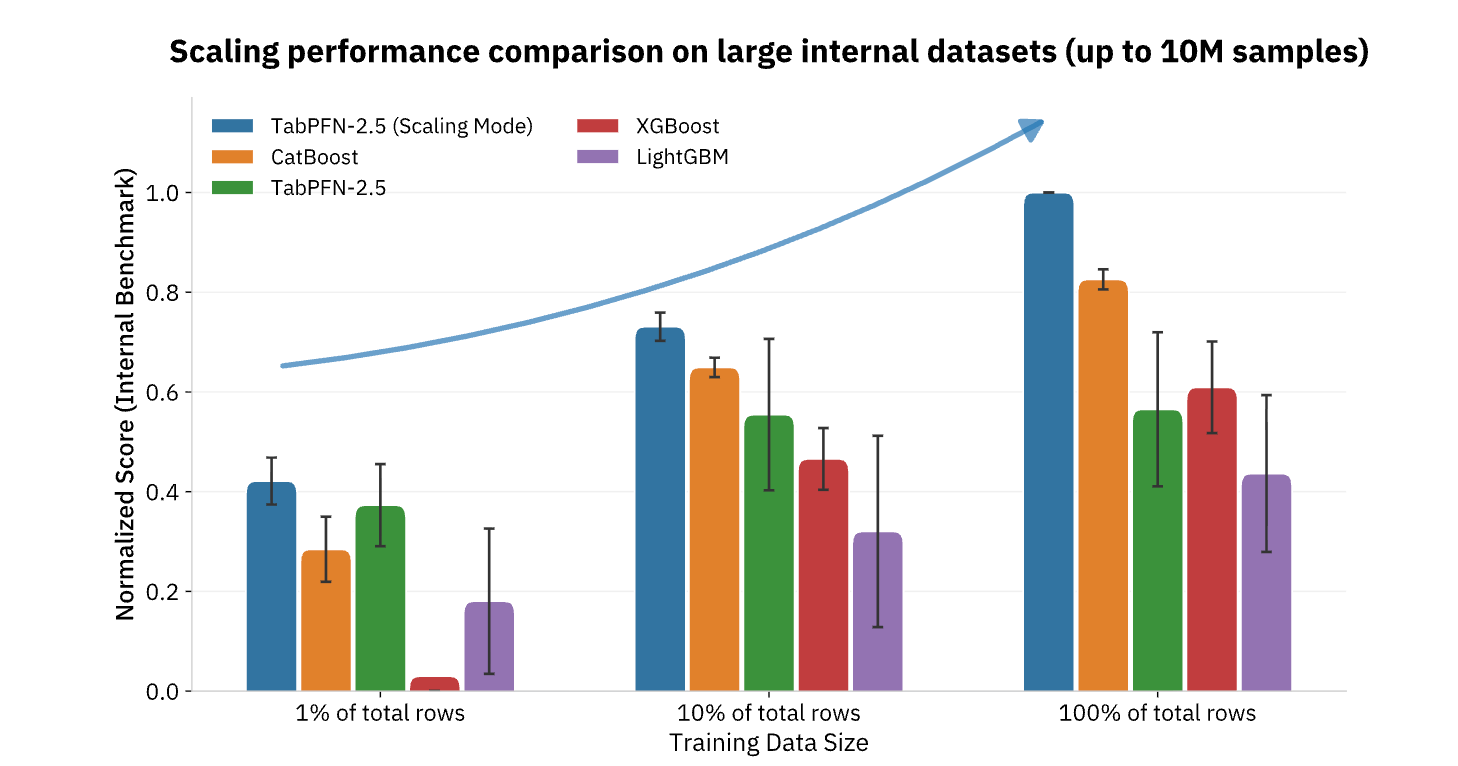
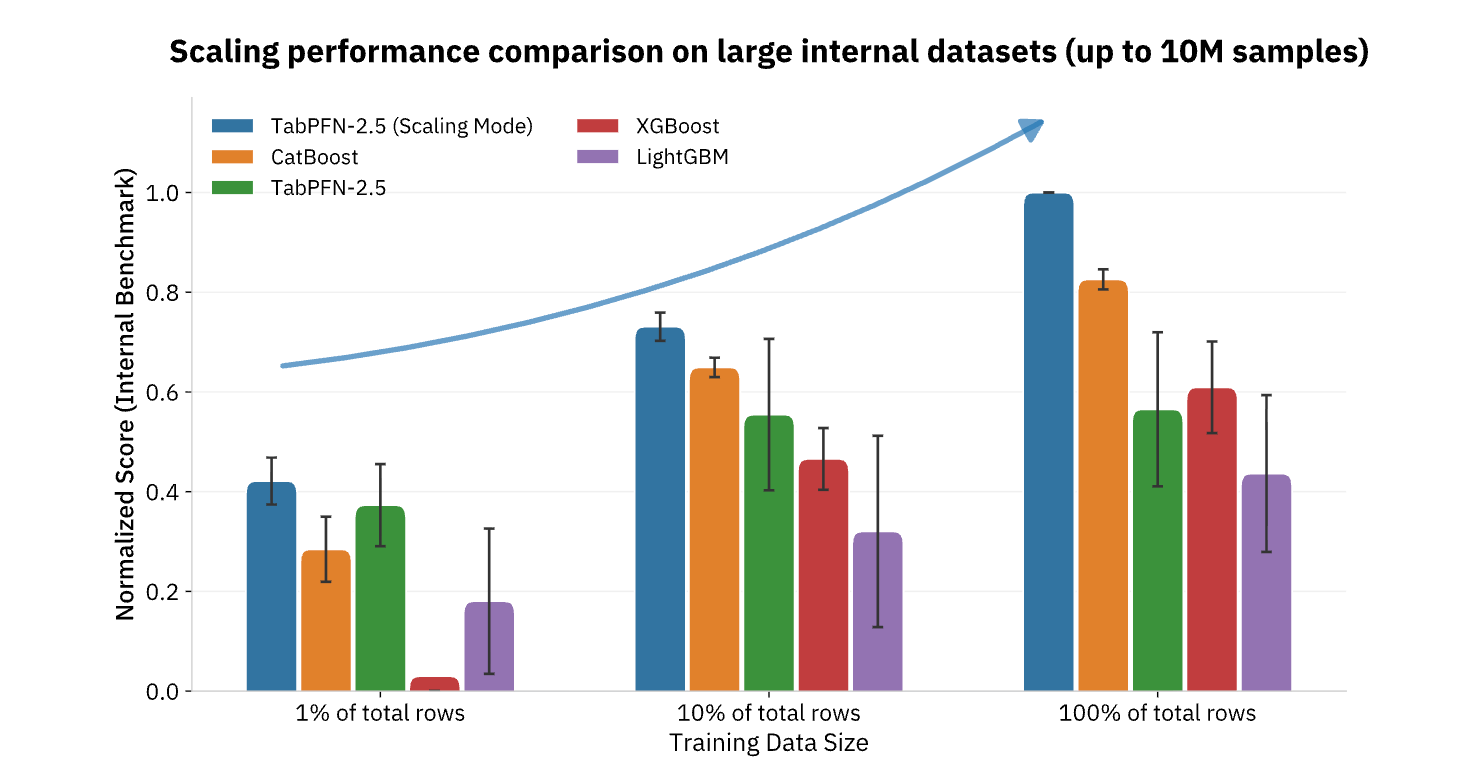{kind=link}
TabPFN ya está impulsando muchas aplicaciones del mundo real para empresas de todo el mundo. Las implementaciones en diversos dominios, desde la gestión de riesgos financieros con Taktile, hasta la evaluación de resultados de salud con NHS y el mantenimiento predictivo con Hitachi, han experimentado un impulso, tanto en la eficiencia como en la calidad de los resultados. TabPFN supera consistentemente a los métodos de ML tradicionales, mejorando la línea de base en un 10%-65% y acelerando los flujos de trabajo de ciencia de datos en un 90%. Las organizaciones están logrando mayores ingresos, mejores resultados de salud, ahorro en costos de mantenimiento, prevención de la pérdida de clientes y mucho más.
Uso de TabPFN con Databricks
Databricks ha sido durante mucho tiempo la plataforma preferida para los científicos de datos que buscan desarrollar capacidades predictivas con machine learning (ML). Como plataforma abierta, TabPFN es ideal para su uso dentro de la plataforma de Databricks.
Cree donde residen los datos
La mayoría del ML clásico empresarial comienza con los datos de Lakehouse: transacciones, telemetría operativa, eventos de clientes, señales de inventario e indicadores de riesgo. Mover esos datos a entornos externos ralentiza a los equipos al crear duplicación, aumentar el riesgo de seguridad y debilitar la reproducibilidad y la auditabilidad. Databricks habilita los flujos de trabajo de TabPFN directamente junto a los datos gobernados, para que los equipos puedan minimizar el movimiento de datos mientras mantienen los controles. Con Unity Catalog, las organizaciones centralizan el control de acceso y la auditoría y preservan el linaje en los activos de datos e IA, lo que es importante cuando se necesita demostrar qué datos se utilizaron, cómo se derivaron las características y quién tuvo acceso en el momento de la decisión.
Operacionalizar los resultados de manera eficiente
TabPFN es un enfoque de modelado. Para crear un impacto en la producción, debe integrarse con patrones empresariales repetibles, como la puntuación por lotes y en tiempo real, la evaluación, la gobernanza y el monitoreo. Databricks es una plataforma sólida para estos flujos de trabajo, con computación escalable e infraestructura de inferencia en tiempo real que puede convertir a TabPFN en un proceso operativo fiable. Para la evaluación y el monitoreo, MLflow proporciona seguimiento de experimentos y un registro de modelos para gestionar versiones, linaje y flujos de trabajo de promoción de forma auditable.
Gobernanza continua del modelo
Databricks proporciona un monitoreo continuo del rendimiento del modelo TabPFN, detectando cuándo las predicciones comienzan a desviarse de los resultados empresariales reales. Cuando se necesitan ajustes, la arquitectura de TabPFN elimina el ciclo de reentrenamiento tradicional que dura semanas: los equipos simplemente actualizan el contexto del modelo con datos recientes y lo vuelven a implementar en minutos en lugar de días. Esta combinación de monitoreo automatizado y capacidad de actualización rápida garantiza que la calidad de la predicción se mantenga alineada con las condiciones cambiantes del mercado, al tiempo que reduce drásticamente los recursos de ciencia de datos que suelen ser necesarios para el mantenimiento continuo del modelo.
Para ayudar a los equipos a probar TabPFN con una configuración mínima, publicamos un acelerador de soluciones de acceso público que muestra cómo ejecutar TabPFN de principio a fin en Databricks con datos gobernados de Lakehouse. El acelerador incluye una serie de notebooks que simulan datos de forma realista a partir de una variedad de escenarios del sector y crean predicciones con TabPFN (Video 1).
Empiece hoy mismo, llevando el poder transformador de la IA a sus cargas de trabajo de ML e impulsando la transformación de los procesos empresariales en todos los ámbitos.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.