Tutorial: Cómo implementar cambios en los dashboards de AI/BI de forma segura y a escala con Databricks Asset Bundles
Despliegue análisis con confianza: una guía completa para crear dashboards de AI/BI confiables y escalables sin procesos manuales
por Eason Gao, Noah Sommerfeld y Jen Lim
- Implemente dashboards impactantes para toda la organización con confianza y estabilidad.
- Mantenga la confianza con cambios e historial visibles, revisables y reversibles.
- Actualice las métricas y la lógica del dashboard a medida que cambian las definiciones de negocio, sin interrumpir los informes de producción.
La idea de que una reunión de la junta directiva comience con un dashboard lleno de errores debería quitarle el sueño a los equipos de análisis. También debería hacerlo el descubrir, después del hecho, que un plan de contratación, el lanzamiento de un producto o un pronóstico de ingresos se basó en una métrica incorrecta. O que un equipo de soporte emitió demasiados reembolsos porque un dashboard representó erróneamente el historial de compras de un cliente.
Estas fallas rara vez son causadas por un mal análisis. Como cualquier sistema de producción, a menudo se deben a que los dashboards se actualizan manualmente a medida que los modelos de datos y los requisitos evolucionan, sin control de versiones, sin un proceso de revisión confiable o sin una forma repetible de promover los cambios entre entornos.
Esta publicación de blog plantea un caso simple: los dashboards de nivel de producción que impulsan el negocio deben gestionarse con la misma disciplina que el código de producción. Debido a que Databricks AI/BI se ejecuta en la misma Plataforma de Inteligencia de Datos que sus canales de datos y capa de gobernanza, los equipos pueden aplicar esas mismas prácticas de producción (control de versiones, configuración específica del entorno e implementación controlada) también a los dashboards.
Para concretar esto, presentaremos cómo los analistas pueden usar las capacidades de Databricks de nivel de producción sin cambiar la forma en que crean dashboards en el día a día.
Específicamente, mostraremos cómo este flujo le permite:
- Revisar y aprobar cada cambio en un dashboard
- Realice un seguimiento del historial de un panel y vincule los cambios de código con los requisitos del negocio
- Revertir un dashboard a una versión anterior
Requisitos previos
Este flujo de trabajo requiere una configuración de infraestructura única que la mayoría de las organizaciones ya tienen. Si aún no los tiene, pídale a su grupo interno de DevOps o TI que lo ayude a configurar:
- Al menos dos workspaces de Databricks (por ejemplo, un workspace de desarrollo y uno de producción) para crear, probar e implementar dashboards.
- Carpetas respaldadas por Git en Databricks (AWS | Azure | GCP), usadas para versionar las definiciones del dashboard
- Databricks Asset Bundles (DABs) (AWS | Azure | GCP) configurados para el proyecto
Introducción: un flujo de trabajo estructurado para implementar cambios en los dashboards de forma segura
Analizaremos un escenario realista: usted es el propietario de un dashboard de rendimiento de ventas que utilizan semanalmente los directivos de finanzas y ventas. Comenzó como un proyecto de pasantes, creado directamente en un espacio de trabajo, pero ha evolucionado con el tiempo y ahora se utiliza en varias revisiones ejecutivas.
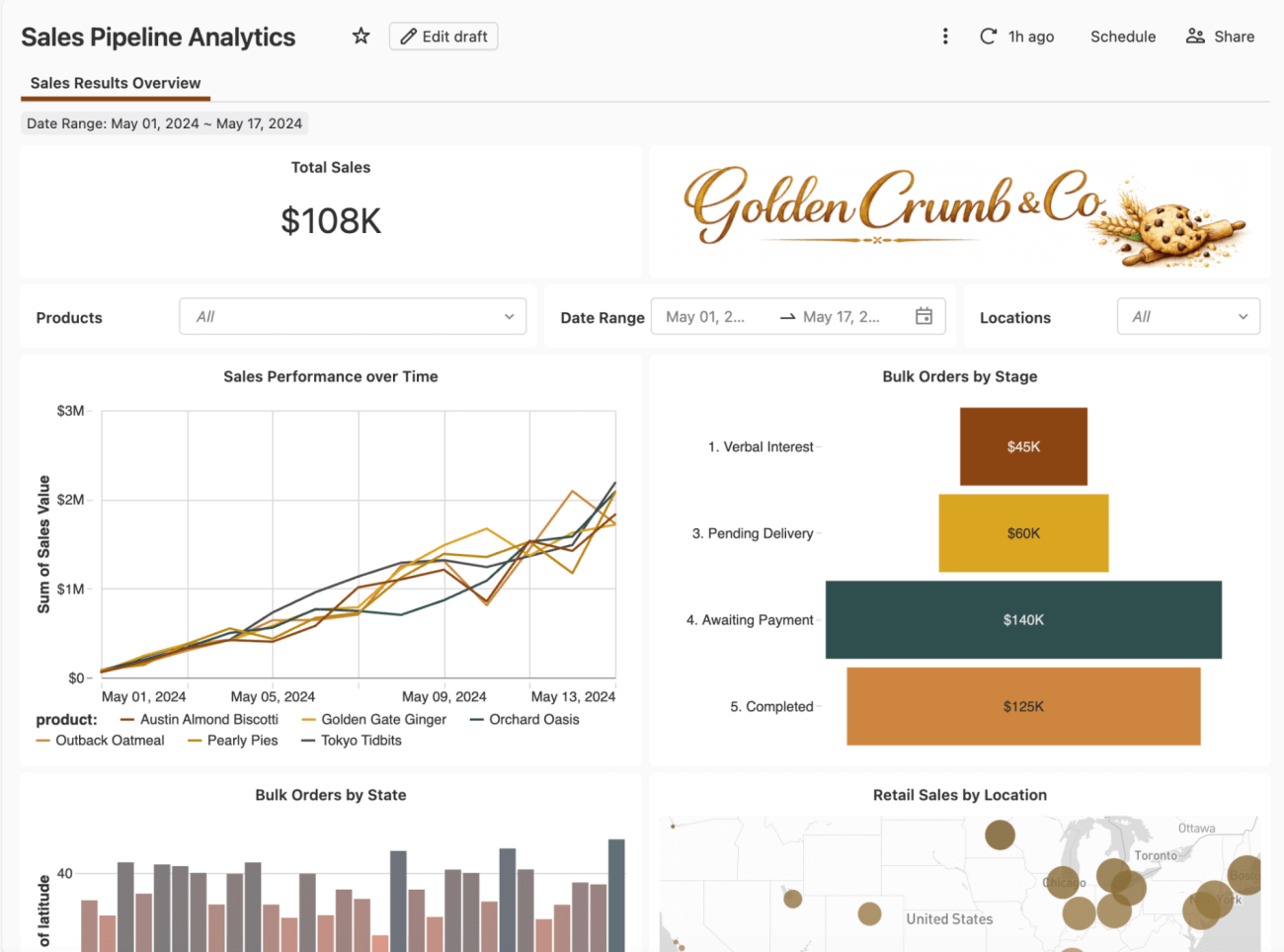
Un cambio en las prioridades de una reunión de la junta directiva trae un nuevo requisito: Finanzas ahora necesita hacer un seguimiento de los montos de ventas comprometidos y no comprometidos, en sustitución de una única métrica de ventas agregada, y el dashboard tiene que reflejar la nueva definición antes de la próxima revisión de previsiones.
Estos valores influyen directamente en las decisiones empresariales reales, incluidos los cálculos de compensación y bonificaciones, así que tomemos este dashboard y pongámoslo por primera vez en una ruta de despliegue disciplinada.
Paso 1: Agregue el dashboard a un Databricks Asset Bundle
Antes de comenzar el proceso, trabaje con su grupo de TI para configurar algunas herramientas de código básicas: un repositorio de Git con un ‘Databricks Asset Bundle’ vacío y algunos scripts de CI/CD para implementar automáticamente el paquete.
Un repositorio de Git es una herramienta para hacer un seguimiento de los cambios en los archivos. Para empezar, necesitamos conectarlo a Databricks para poder hacer un seguimiento de los cambios en la configuración del dashboard. Desde el espacio de trabajo de Databricks, cree una carpeta de Git y pegue la URL del repositorio en el cuadro de diálogo de configuración. Esto hace que Databricks sea consciente del repositorio y nos permite agregarle el dashboard en el siguiente paso.

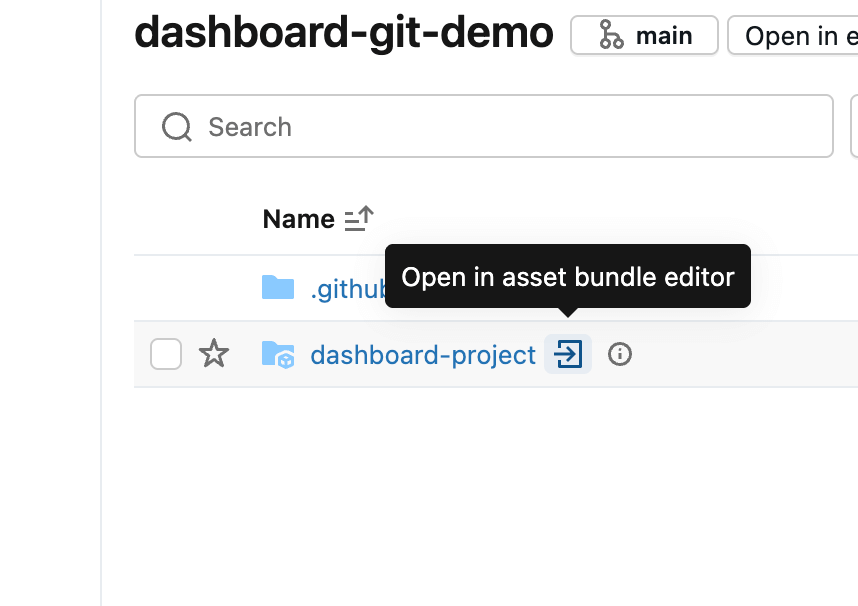
Un Databricks Asset Bundle es una forma de agrupar archivos de código (en este caso, un panel). Si el repositorio ya contiene un bundle, este se detecta automáticamente y se puede abrir con el ícono de flecha. De lo contrario, se puede crear un nuevo bundle desde el menú Crear en la carpeta de Git.
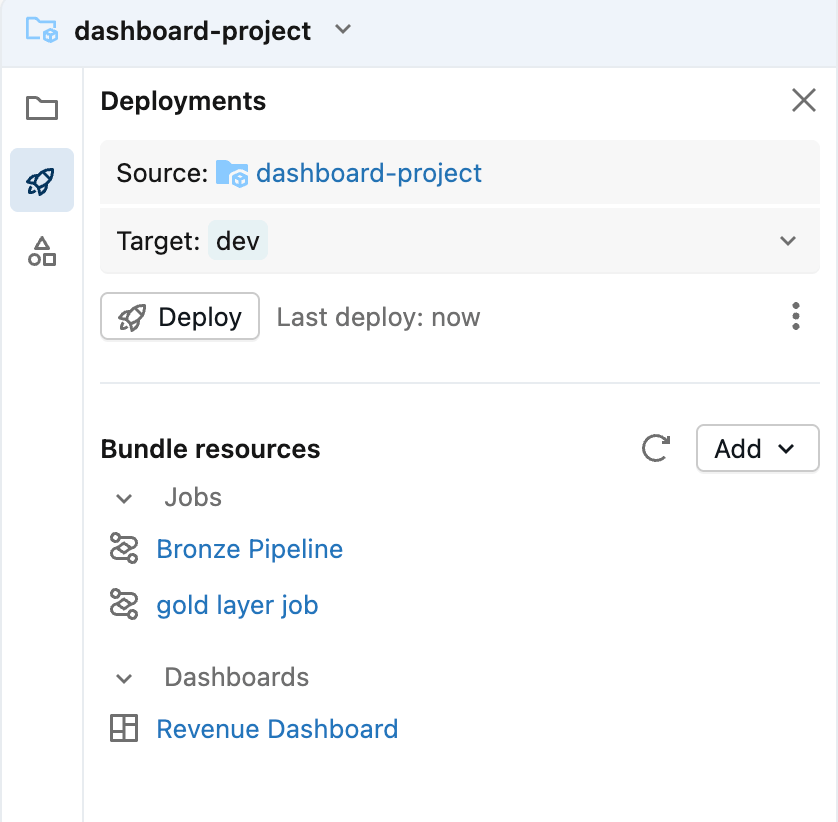
Dentro del editor de Asset Bundle, puede agregar componentes nuevos y existentes al bundle que actualmente está vacío. Para incluir el dashboard, abra el menú Agregar y seleccione Agregar dashboard existente. Después de agregarlo, verá que el dashboard aparece dentro de la carpeta src como parte del bundle.
A partir de este momento, el dashboard se gestiona como un activo implementable, lo que facilita la promoción del mismo dashboard entre los espacios de trabajo de desarrollo, prueba y producción.
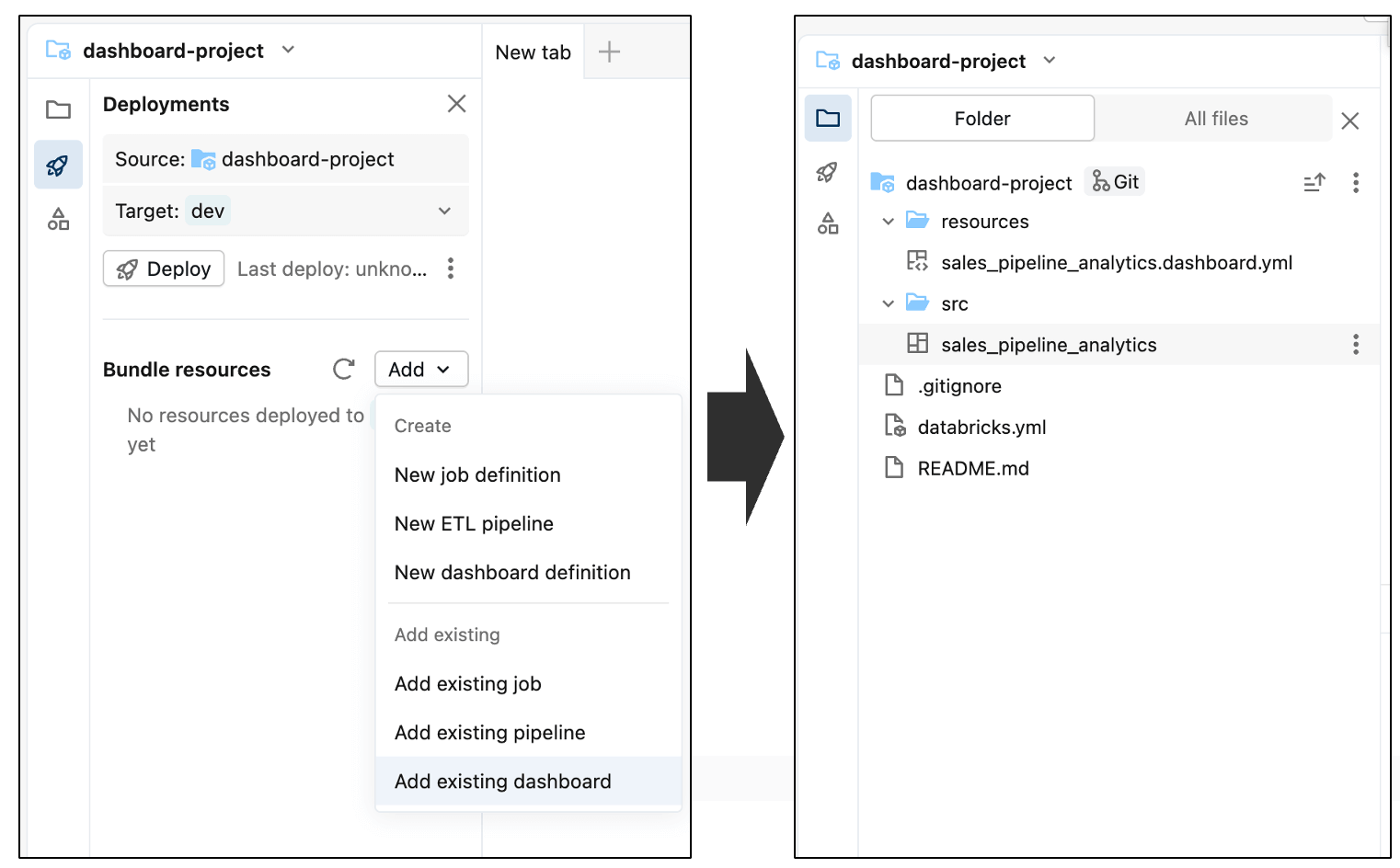
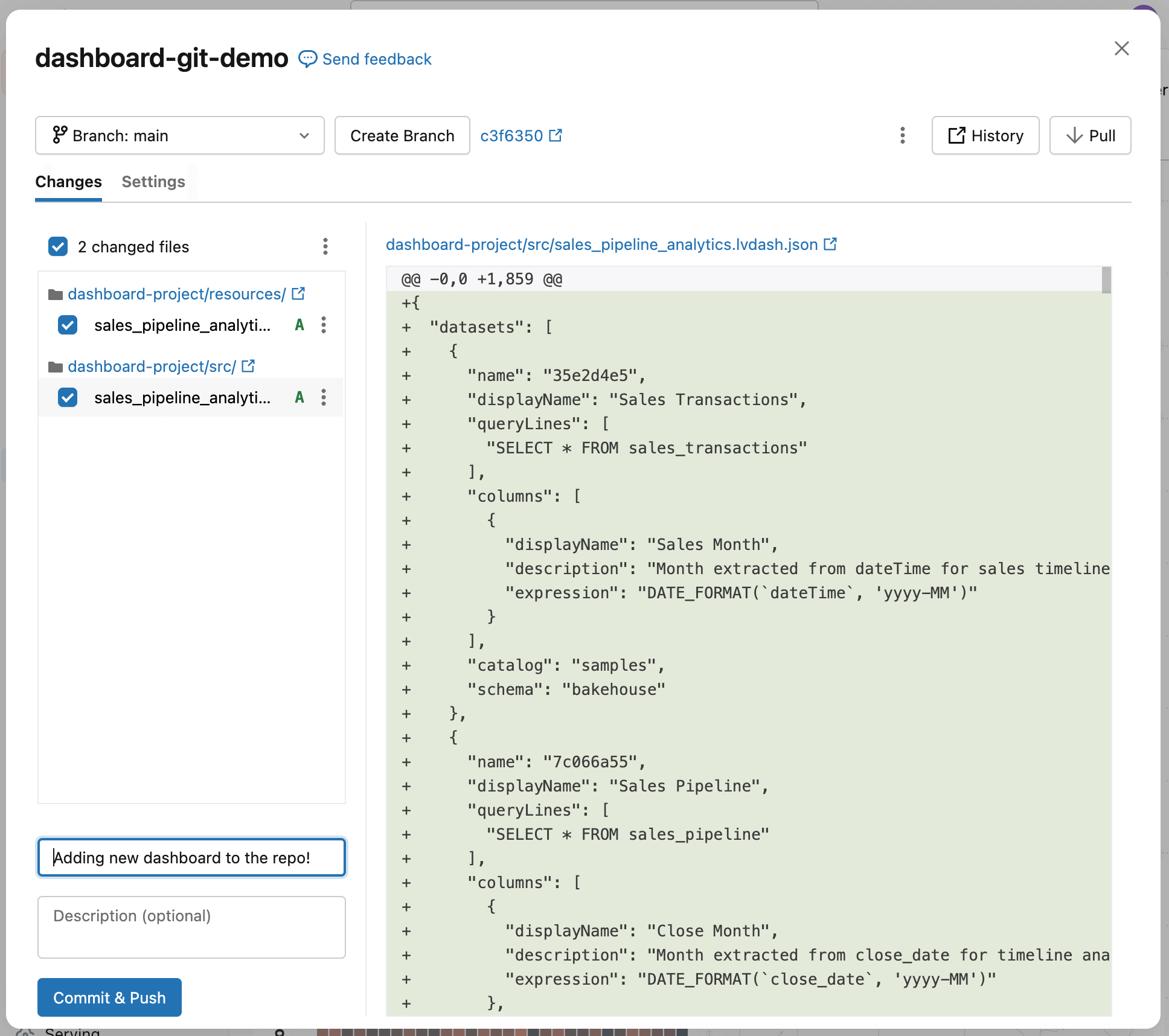
Finalmente, haga commit del dashboard en el repositorio. Esto captura el estado actual del dashboard como un punto de referencia y establece un punto de partida claro para el seguimiento y la revisión de cambios futuros.
Verá que el dashboard se agregó al repositorio, junto con algunos archivos de configuración generados automáticamente (que terminan en .yml). Estos archivos describen cómo se debe desplegar el dashboard en diferentes entornos; no es necesario que los edite.
Agregue una nota breve que describa lo que hizo en el campo mensaje de confirmación y, luego, seleccione Confirmar y enviar. Esto crea un punto de control para el dashboard (un estado bueno conocido al que puede volver más tarde) para que los cambios futuros se puedan comparar, revisar y desplegar de forma segura.
Paso 2: Actualizar el panel
Ahora que el dashboard existente ha sido confirmado, puede empezar a hacerle cambios sin afectar a lo que ya está en producción, y Git hará un seguimiento de los cambios específicos que haya realizado.
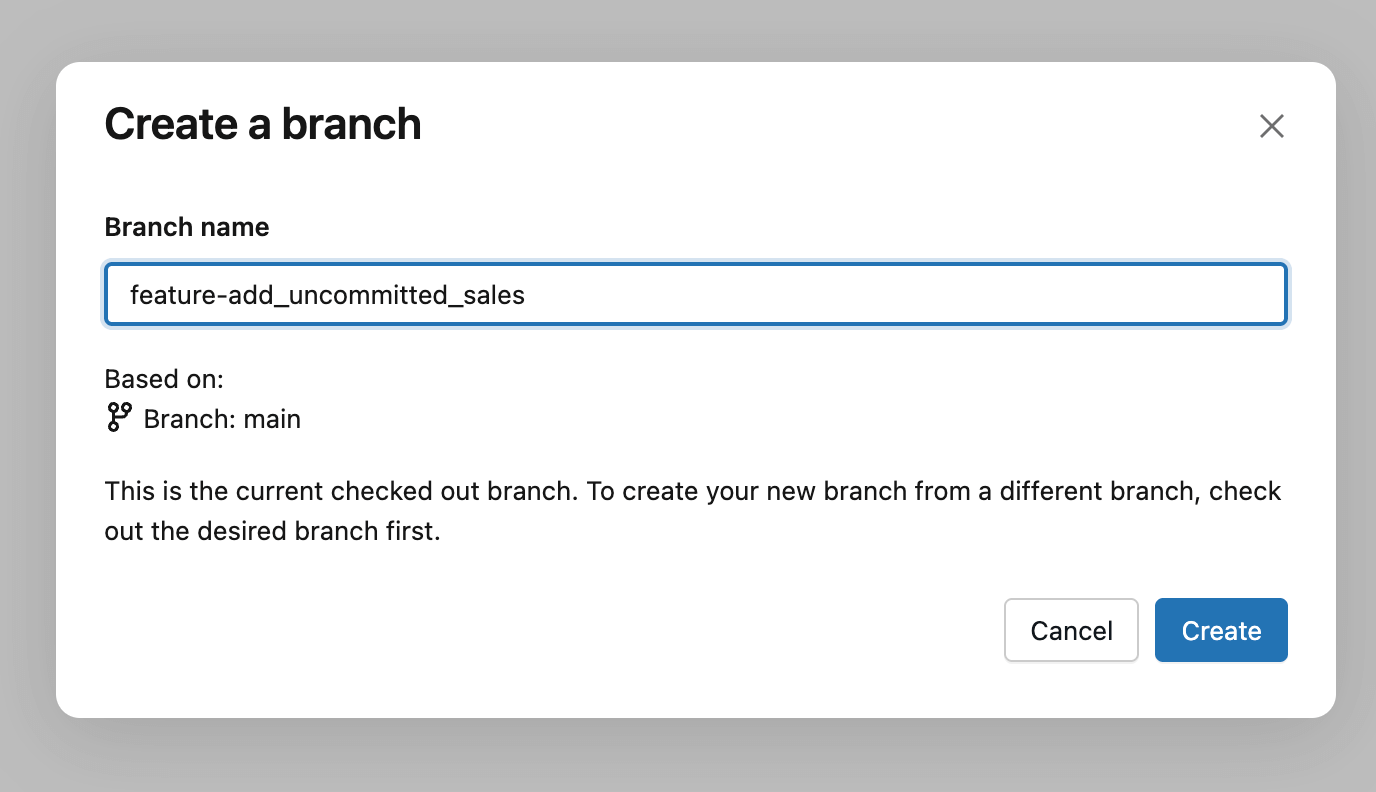
La práctica general es crear una rama de Git, una versión del dashboard en la que se puede trabajar sin afectar a los demás. Puede hacerlo a través del botón Create Branch y, luego, darle un nombre descriptivo, como su nombre, una característica o un número de ticket asociado con el cambio. Considere esto como una versión privada para su actualización: puede editar, probar y refinar el dashboard libremente, y luego decidir por separado cuándo sus cambios están listos para ser revisados e implementados.
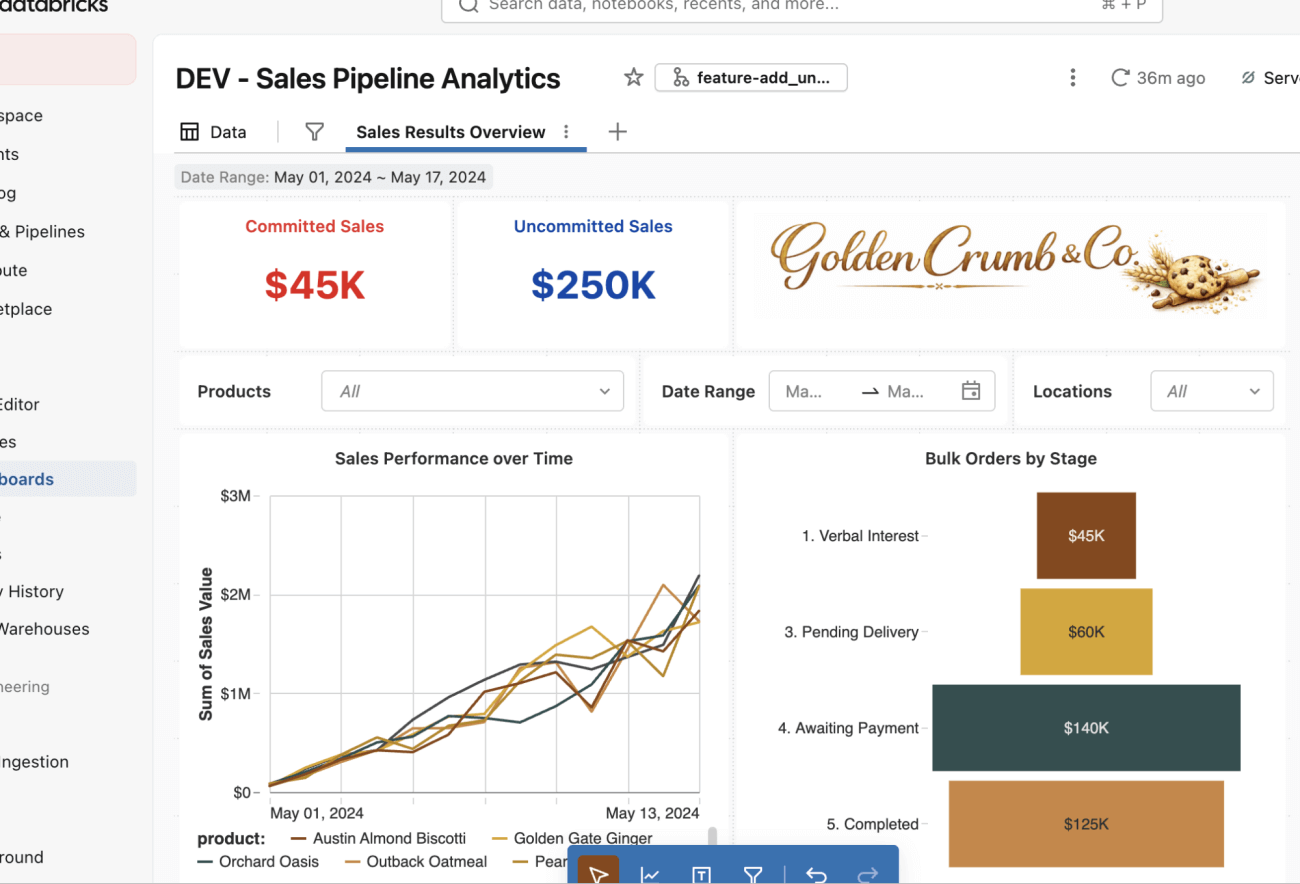
¡Ahora puede hacer los cambios en el dashboard! En este caso, modificará la cifra de ventas en la parte superior izquierda para añadir contadores de ventas no comprometidas y comprometidas (se eligieron el azul y el rojo en negrita para mayor visibilidad).
Notará que nada cambia en la experiencia de creación: realice estos cambios como lo haría normalmente con el editor de la interfaz de usuario del dashboard.
Una vez que el dashboard se vea correcto en el entorno de desarrollo, estará listo para llevar los cambios a producción. Use el mismo botón Git en la parte superior, como antes, para registrar estos cambios con un mensaje de confirmación breve.
Paso 3: Revise el cambio
A continuación, obtiene otro beneficio clave de este flujo de trabajo: un lugar para que otros revisen los cambios y ofrezcan comentarios antes de que el cambio llegue a producción. Requerir la revisión de una segunda persona es una buena práctica general, pero, lo que es igual de importante, crea un espacio de bajo riesgo para discutir ideas, validar suposiciones y refinar el cambio antes de que afecte a los informes.
Para iniciar la revisión, cree una solicitud de extracción (PR) en su proveedor de Git, que es básicamente una página de revisión para la actualización del panel. El revisor puede ver exactamente qué cambió, dejar comentarios para que usted los aborde y aprobar la actualización una vez que todo parezca correcto.
Durante la revisión, el dashboard de producción permanece sin cambios. Solo después de que se abordan los comentarios y se aprueba el cambio, este avanza.
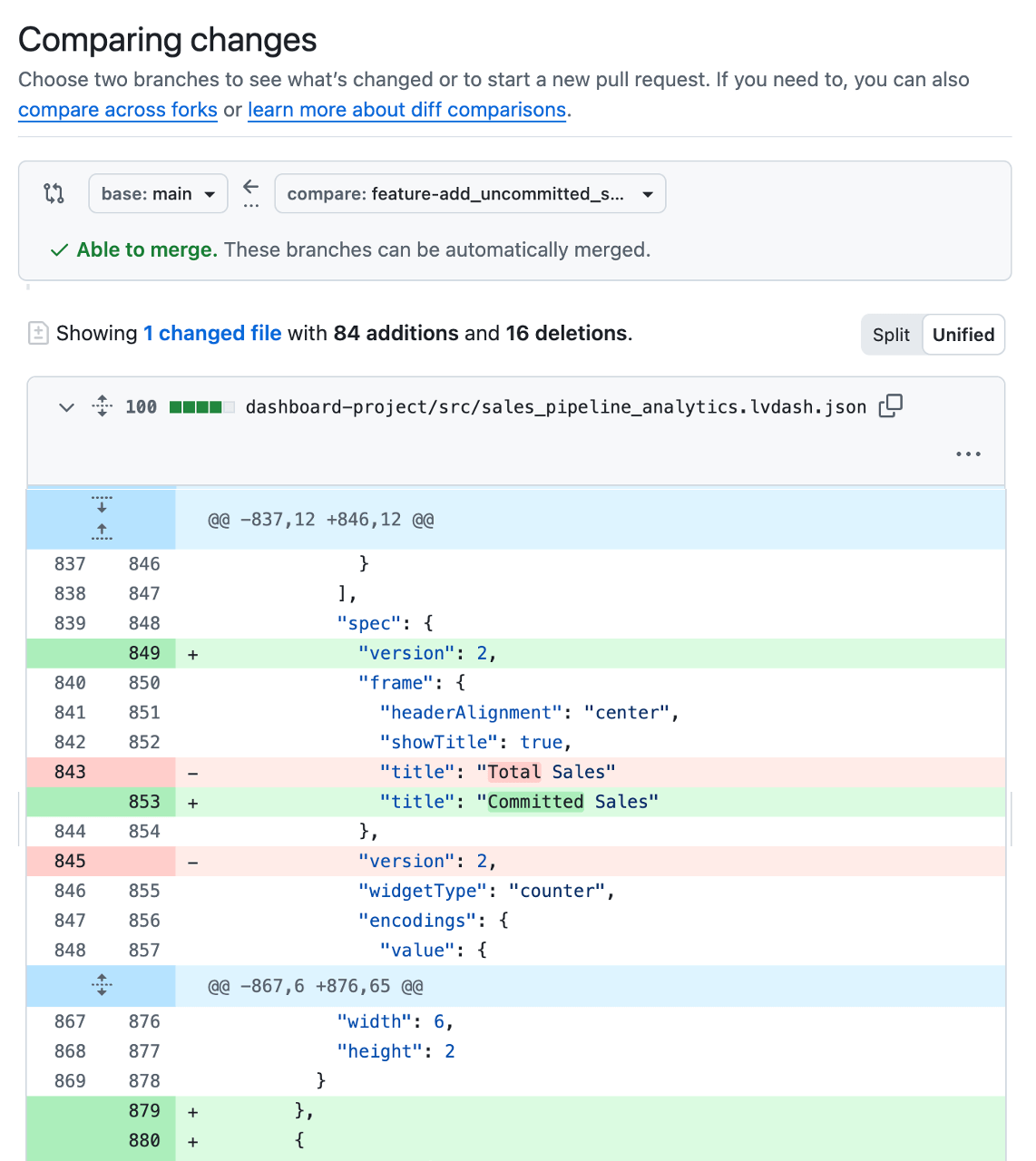
Aunque los cambios en el dashboard se almacenan y se rastrean como archivos de configuración en segundo plano, a menudo es difícil entender qué ha cambiado realmente. Por este motivo, la mayoría de los equipos utilizan una pequeña automatización para desplegar automáticamente una versión de prueba temporal del dashboard para su revisión cada vez que se abre una PR. De esa manera, los revisores pueden ver las métricas, los cálculos y los diseños propuestos en contexto antes de que algo llegue a producción, y detectar problemas de lógica de datos o de la interfaz de usuario. Que el desarrollador o el revisor incluyan capturas de pantalla o enlaces al dashboard de prueba directamente en la PR también hace que los comentarios sean más rápidos y confiables.
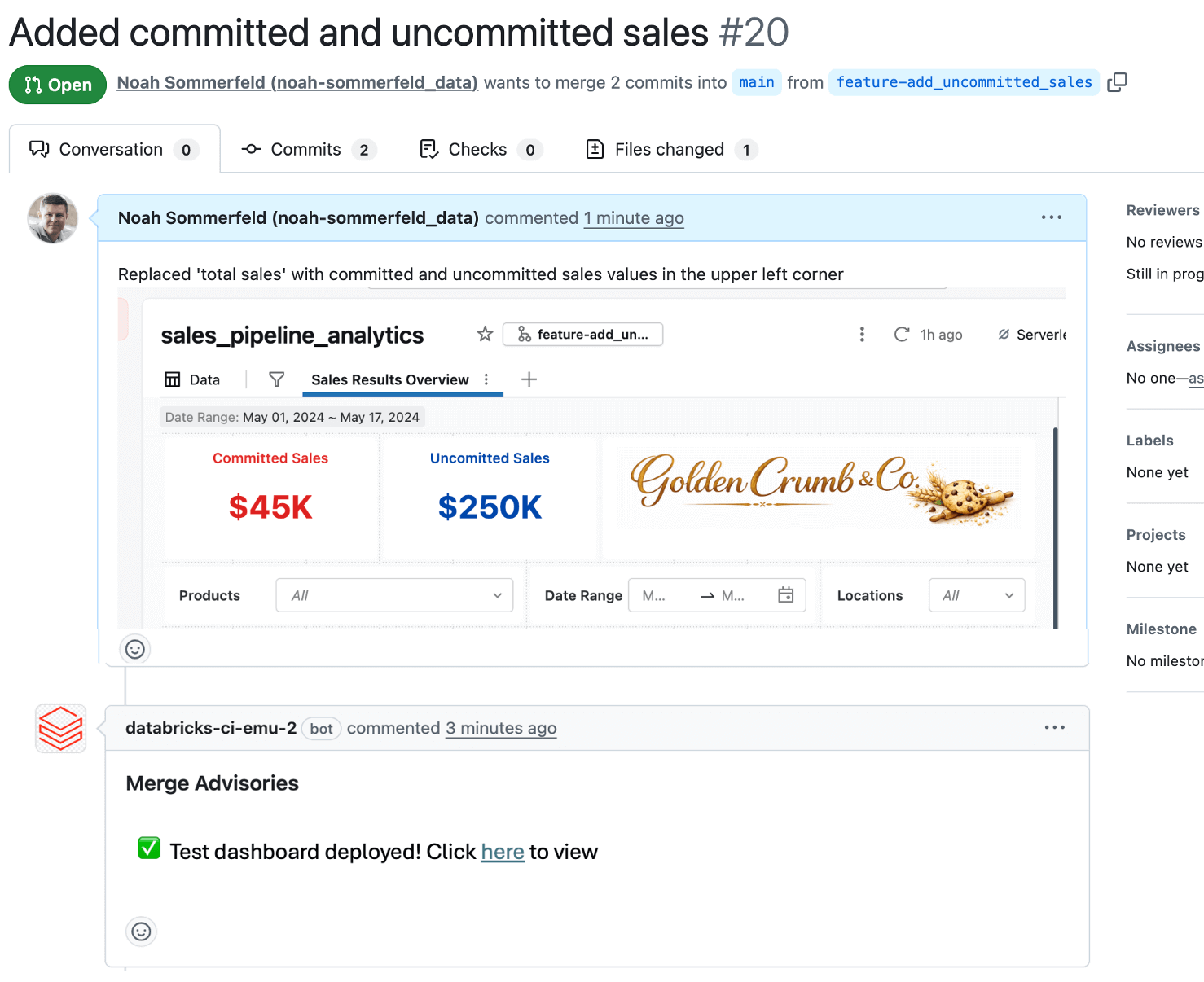
Los revisores pueden agregar comentarios y aprobar, los cuales se registran para que el cambio sea más fácil de entender más adelante.
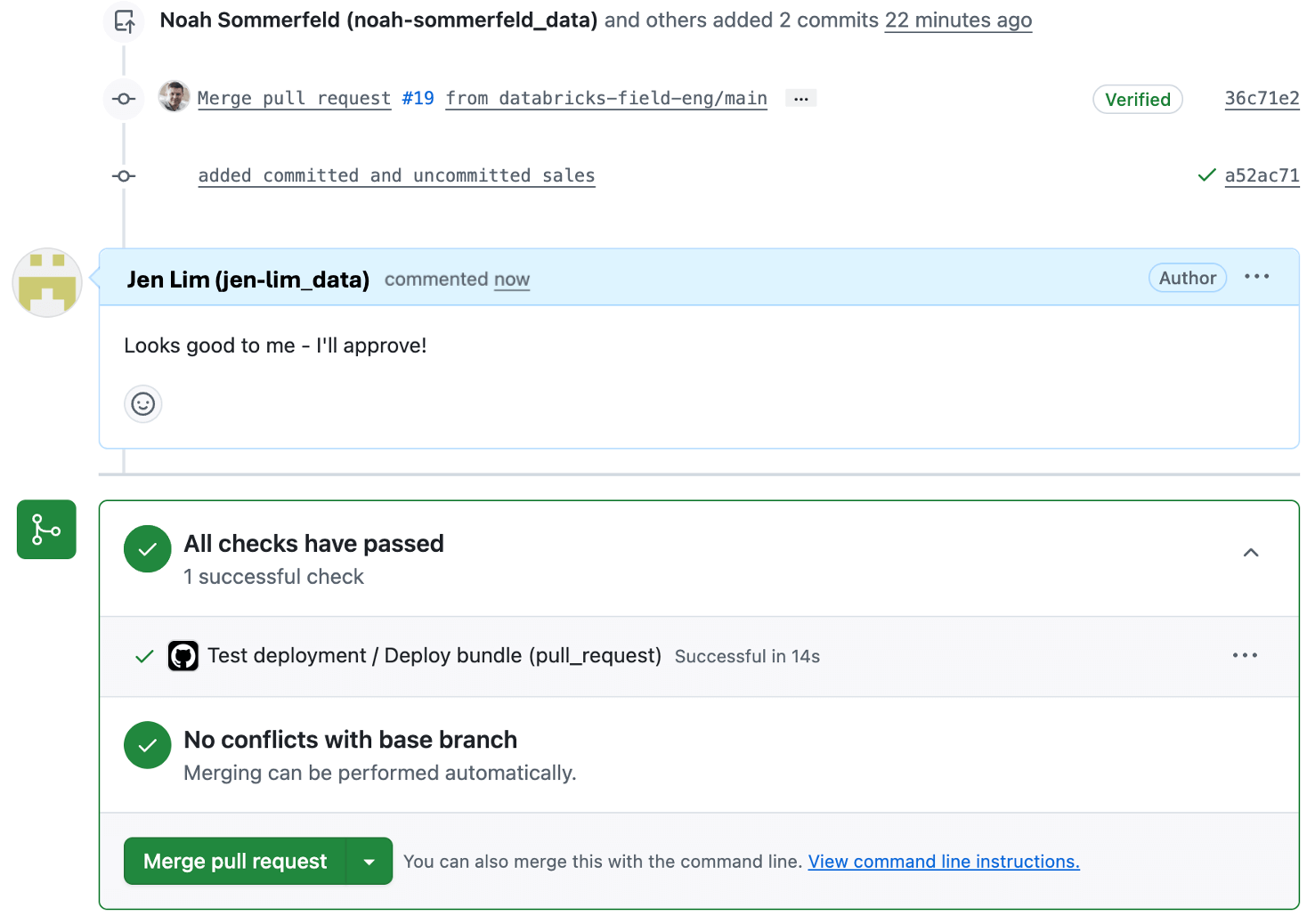
Paso 4: implementar el dashboard en producción usando el bundle
Con el cambio aprobado, ya está listo para implementar el dashboard en producción.
Los dashboards a menudo necesitan configuraciones diferentes en producción que en desarrollo; por ejemplo, apuntar a un catálogo o esquema de producción en lugar de a un conjunto de datos de desarrollo, o usar un SQL Warehouse diferente.
La buena noticia es que se esperan y gestionan estas diferencias como parte del proceso de implementación.
Cuando agregó el dashboard al Asset Bundle, Databricks generó un pequeño archivo .yml de configuración que captura estas configuraciones específicas del entorno. Este archivo le permite anular valores por entorno sin cambiar la lógica del dashboard en sí. En nuestro caso, hemos especificado que el catálogo que utiliza el dashboard en producción debe ser diferente al de prueba, utilizando un valor ${variable} para el nombre del catálogo.
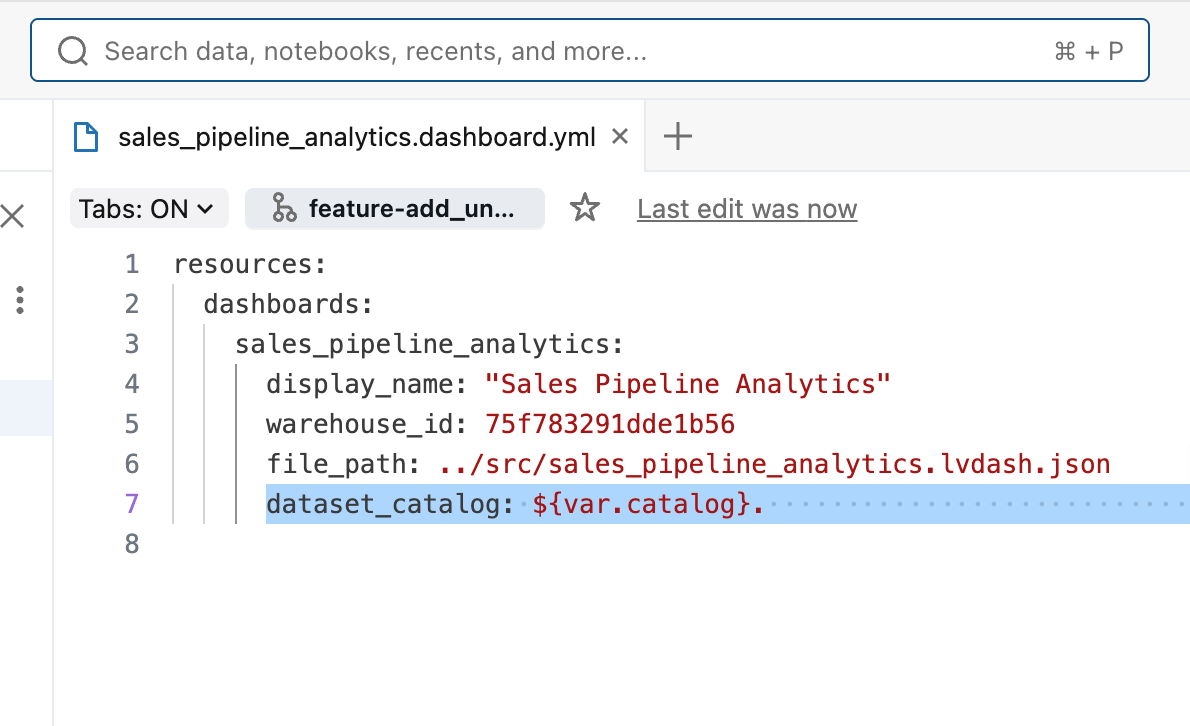
Por último, el archivo databricks.yml vincula todos los recursos del paquete y define qué catálogo se usa en cada entorno, lo que facilita la administración de implementaciones coherentes en los espacios de trabajo de desarrollo, prueba y producción.
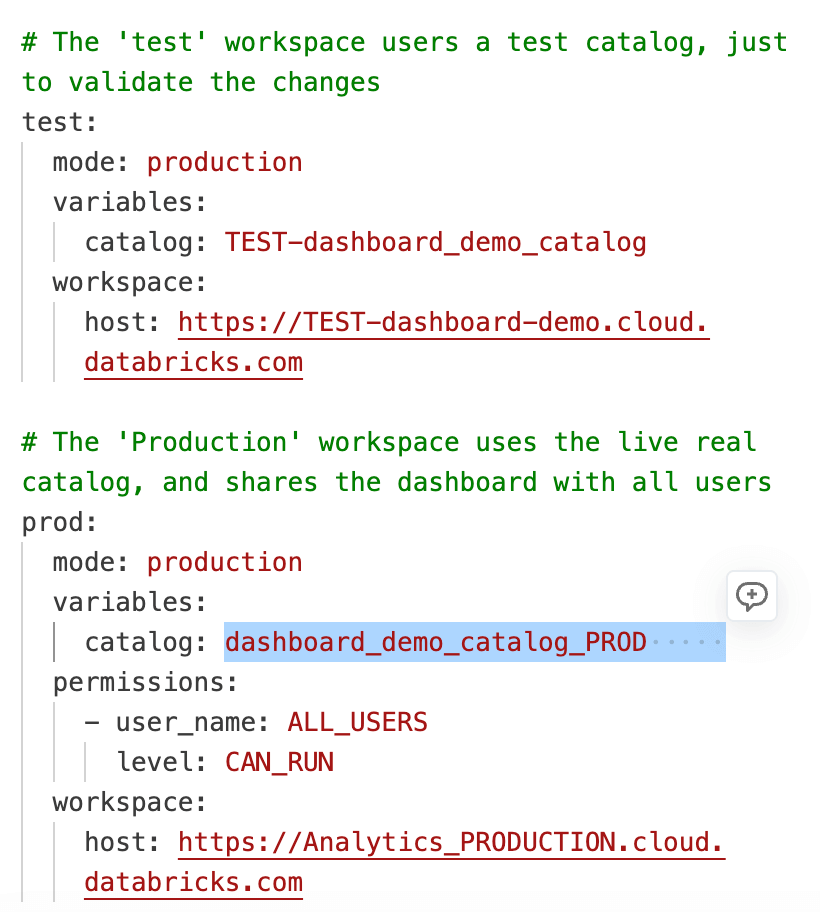
Una vez que la Pull Request se aprueba y se fusiona en la rama principal, la automatización del despliegue se ejecuta y utiliza los valores específicos del entorno definidos en databricks.yml. El mismo código del dashboard se reutiliza en todos los espacios de trabajo, mientras que las configuraciones como el catálogo, el esquema y el warehouse se aplican en función del entorno de destino. Esto elimina la necesidad de mantener copias separadas del dashboard para cada espacio de trabajo y garantiza que los cambios se comporten de forma predecible en todas partes.
Para la mayoría de los proveedores de Git, podrá ver la automatización del despliegue en la pull request para que pueda supervisar el despliegue y confirmar cuándo se completa (o si se produce un problema). Si se produce un problema, el despliegue se detiene sin afectar al dashboard de producción existente para permitirle solucionar el problema. Una vez que el despliegue finaliza correctamente, el dashboard actualizado está activo en producción y listo para las partes interesadas.
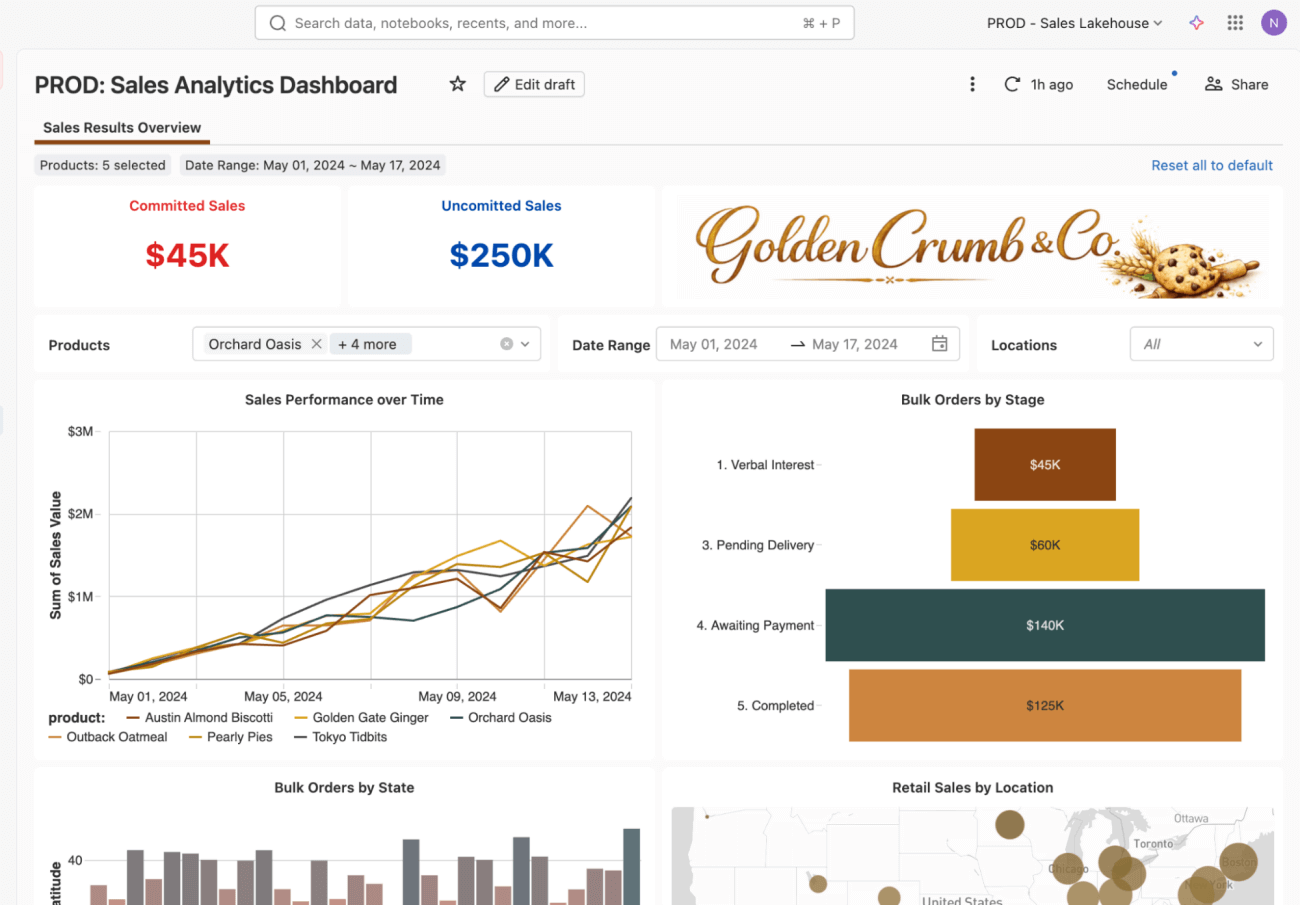
Bono 1: ¿Qué pasa si quiere inspeccionar el historial?
Una vez que la actualización del dashboard esté activa, es posible que necesite entender el historial de qué, cuándo y por qué cambió. Una ventaja de este flujo es que el cambio ahora es rastreable. En lugar de una edición única realizada directamente en un espacio de trabajo, aparece como una secuencia de versiones guardadas.
Cada entrada representa una actualización del dashboard, junto con el autor y la marca de tiempo. Puede abrir cualquier entrada para revisar los cambios y revertirla si es necesario.
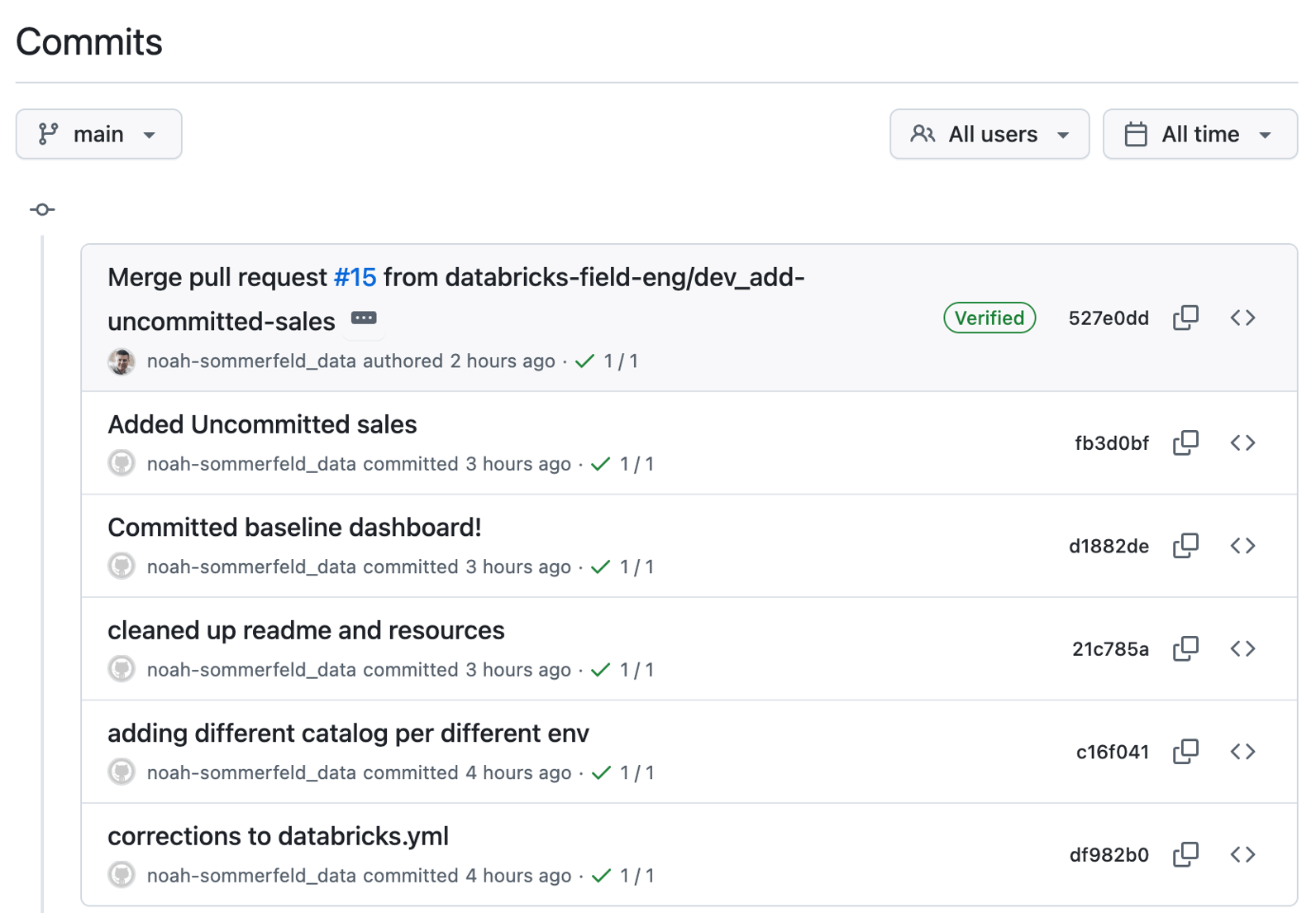
Extra 2: ¿Qué pasa si necesita revertir un cambio?
Incluso con una revisión y pruebas cuidadosas, pueden seguir apareciendo problemas, como un dashboard que no se carga o una definición de métrica que resulta ser incorrecta.
Como el dashboard se gestiona a través de este flujo de trabajo, puede volver a una versión estable conocida mediante el mismo proceso controlado que se utilizó para implementar la actualización.
Comience por abrir el historial de cambios del dashboard en el repositorio y localizar la actualización que desea deshacer. Desde allí, puede revisar lo que se modificó para confirmar que está revirtiendo el cambio correcto antes de continuar.
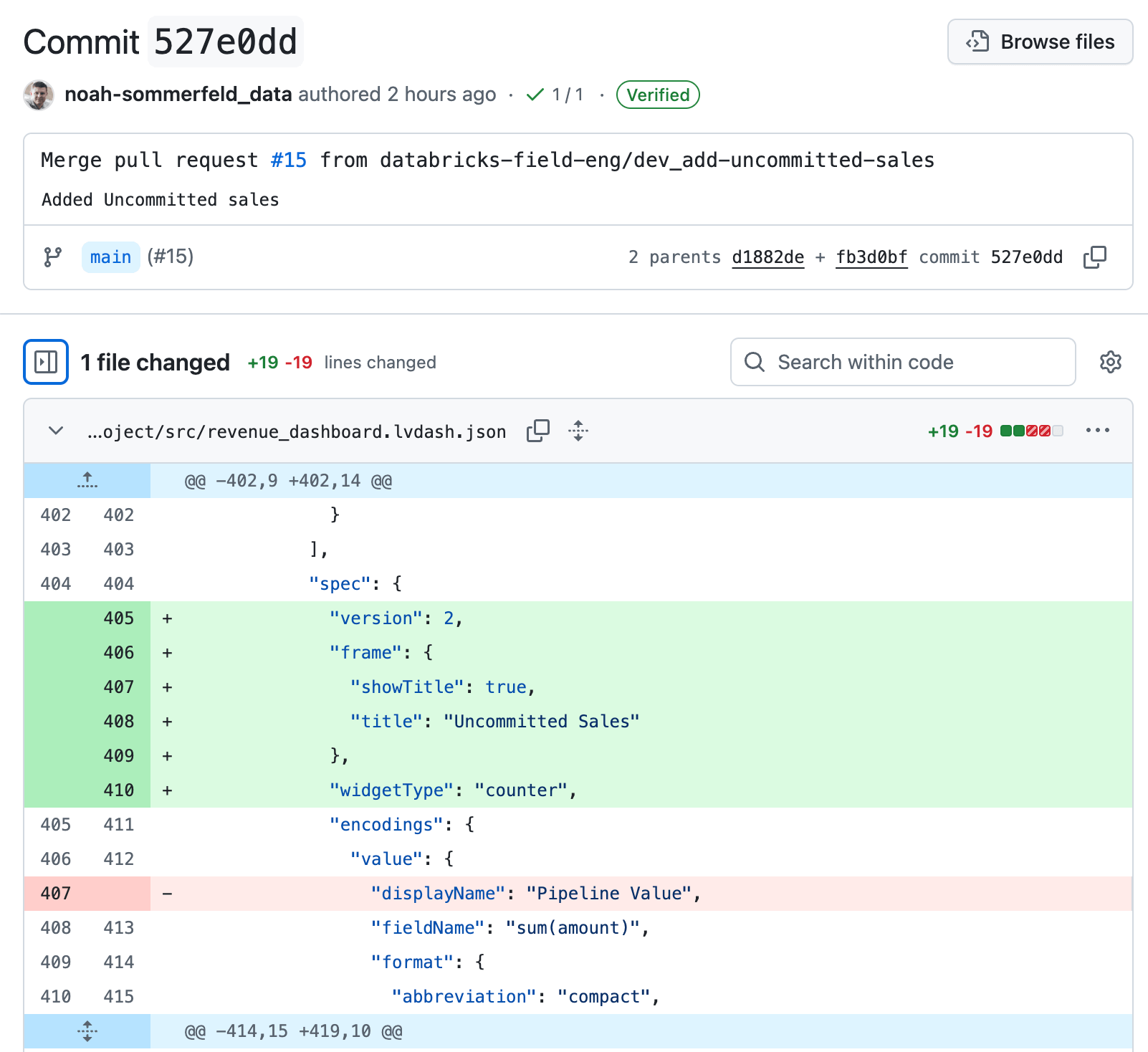
Desde los detalles del cambio, siga el enlace de regreso a la página de revisión. Para revertir la actualización, seleccione Revertir. Esto crea un nuevo cambio para “deshacer” que revierte solo esa actualización específica, restaurando la lógica anterior del dashboard y manteniendo intacto el resto del historial.
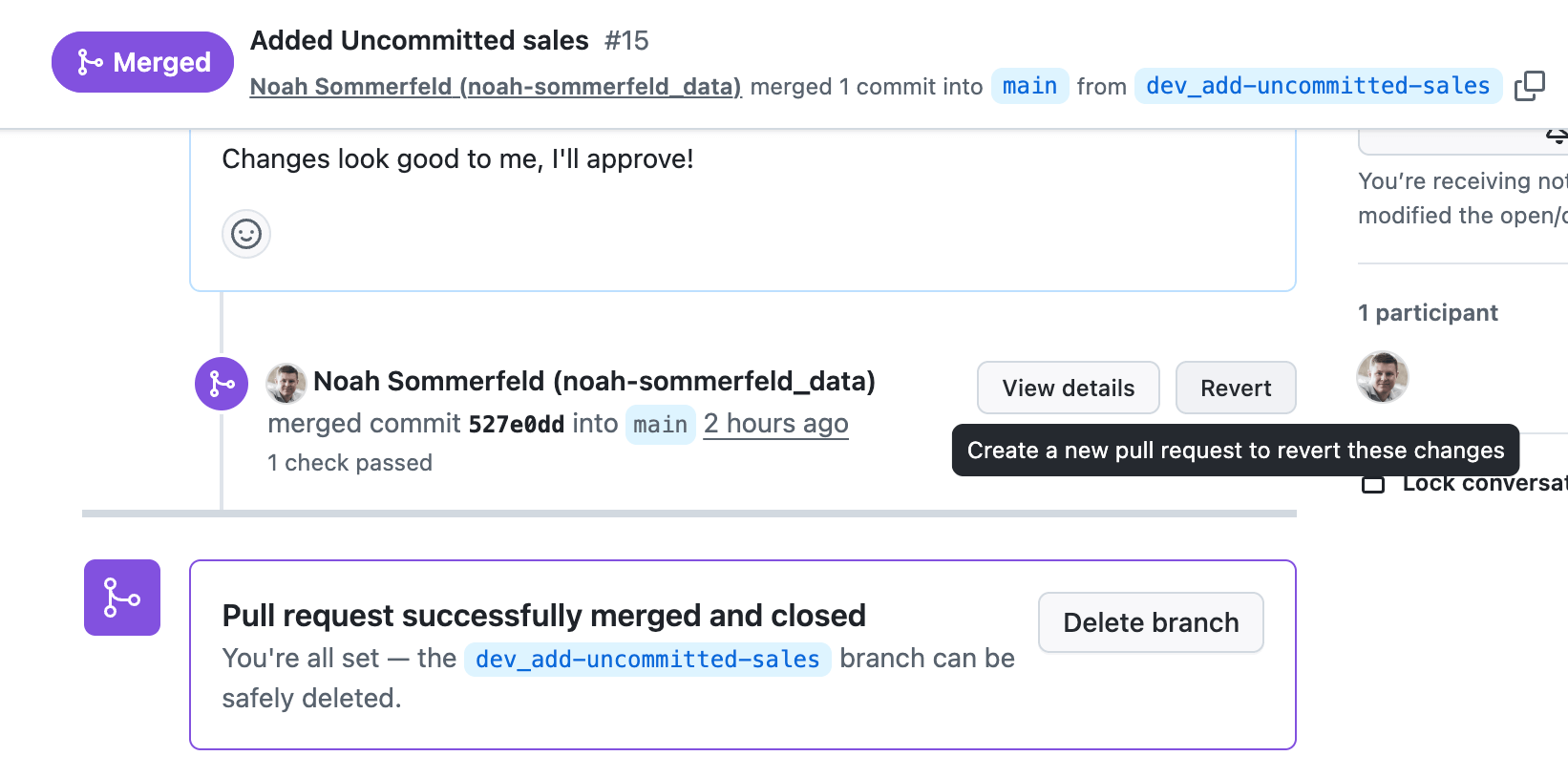
Una vez que el cambio se fusiona en la rama principal, la misma automatización que implementó el dashboard en producción lo revertirá. Esto significa que puede responder a una interrupción o a un problema de cálculo de alto impacto en cuestión de minutos, sin omitir los controles que ya tiene implementados.
Extra 3: ¿Qué sucede si sus fuentes de datos tienen una actualización?
La mayoría de los paneles están estrechamente vinculados a sus orígenes de datos, lo que significa que las actualizaciones de un panel a menudo están estrechamente vinculadas a las actualizaciones en las canalizaciones. La buena noticia es que los Asset Bundles están diseñados para agrupar componentes relacionados en un solo paquete.
Esto garantiza que un cambio en el modelo de datos ascendente nunca lo tome por sorpresa y, cuando los cambios de visualización requieran actualizaciones del modelo de datos, pueda implementar ambos cambios en una sola implementación.
Conclusión
Considerar los dashboards de AI/BI como productos de datos de nivel de producción es fundamental para tomar decisiones empresariales fiables y mitigar riesgos. En este flujo de trabajo, un pequeño conjunto de pasos adicionales hace que los cambios en el dashboard sean visibles, revisables y reversibles, sin cambiar la forma en que crea dashboards en el día a día.
Al gestionar los dashboards con Git y Databricks Asset Bundles, los equipos establecen un flujo de trabajo rutinario y predecible para las actualizaciones: hacer el cambio, revisarlo, probarlo e implementarlo. El mismo proceso se aplica tanto si la actualización es un pequeño ajuste visual como un cambio significativo en la lógica de negocio.
Con la disciplina de despliegue adecuada, los cambios en el dashboard dejan de ser una fuente de riesgo y se convierten en una fuente confiable de información que evoluciona con el negocio, incluso en situaciones de alto riesgo como una reunión de la junta directiva.
Más información y próximos pasos
Si se siente inspirado y quiere profundizar en las piezas utilizadas en este flujo de trabajo, aquí hay algunos recursos que son un buen lugar para continuar:
- ‘Estrategia de ramificación’ (AWS | Azure | GCP)
Aprenda cómo se fusionan y despliegan los cambios utilizando un modelo de ramificación que sigue las mejores prácticas. - Databricks Asset Bundles (AWS | Azure | GCP)
Aprenda cómo se usan los Asset Bundles para empaquetar e implementar recursos de Databricks de forma coherente en todos los entornos. - CI/CD para la implementación automatizada en Databricks (AWS | Azure | GCP)
Aprenda a implementar CI/CD con los scripts de Github Actions de inicio (AWS | Azure | GCP) - Uso de Asset Bundles desde la IU del workspace de Databricks (AWS | Azure | GCP)
Aprenda a crear, editar e implementar bundles directamente desde el workspace. - Carpetas respaldadas por Git en Databricks (AWS | Azure | GCP)
Aprenda cómo funciona la integración de Git en Databricks y cómo el control de versiones se integra en los flujos de trabajo de análisis diarios.
Si está listo para dar el siguiente paso con Databricks AI/BI, puede elegir cualquiera de las siguientes opciones:
- Edición gratuita y prueba: Obtenga experiencia práctica registrándose en nuestra edición gratuita o prueba.
- Documentación: profundice en los detalles con nuestra documentación.
- Página web: Visite nuestra página web para obtener más información.
- Demostraciones: Mire nuestros videos de demostración, realice recorridos por el producto y obtenga tutoriales prácticos para ver estas AI/BI en acción.
- Capacitación: empiece con la capacitación gratuita sobre el producto a través de Databricks Academy.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.