¿Qué son los modelos de aprendizaje automático?
Algoritmos que aprenden patrones a partir de datos de entrenamiento para realizar predicciones, desde regresión lineal y árboles de decisión hasta redes neuronales profundas.
- El proceso de entrenamiento implica la introducción de datos etiquetados mediante algoritmos que ajustan parámetros internos (pesos, coeficientes) para minimizar el error de predicción en los conjuntos de validación, utilizando técnicas como el descenso de gradiente, la retropropagación y la regularización.
- Los tipos de modelos abarcan el aprendizaje supervisado (clasificación, regresión), el aprendizaje no supervisado (agrupamiento, reducción de dimensionalidad), el aprendizaje por refuerzo y los enfoques semisupervisados, cada uno adecuado para diferentes estructuras de problemas y disponibilidad de datos.
- Las métricas de evaluación incluyen exactitud, precisión, recuperación, puntuación F1 y AUC-ROC para la clasificación; MSE, MAE y R² para la regresión; y puntuación de silueta e índice de Davies-Bouldin para el agrupamiento, lo que guía la selección del modelo y el ajuste de hiperparámetros.
¿Qué es un modelo de aprendizaje automático?
Un modelo de aprendizaje automático es un programa que puede encontrar patrones o tomar decisiones a partir de un conjunto de datos nunca antes visto. Por ejemplo, en el procesamiento del lenguaje natural, los modelos de aprendizaje automático pueden analizar y reconocer correctamente la intención detrás de oraciones o combinaciones de palabras nunca antes escuchadas. En el reconocimiento de imágenes, se puede enseñar a un modelo de aprendizaje automático a reconocer objetos, como coches o perros. Un modelo de aprendizaje automático puede realizar estas tareas si lo "entrenas" con un gran conjunto de datos. Durante el entrenamiento, el algoritmo de aprendizaje automático se optimiza para encontrar ciertos patrones o resultados a partir del conjunto de datos, dependiendo de la tarea. El resultado de este proceso, frecuentemente un programa informático con reglas y estructuras de datos específicas, se denomina modelo de aprendizaje automático.
¿Qué es un algoritmo de aprendizaje automático?
Un algoritmo de aprendizaje automático es un método matemático para encontrar patrones en un conjunto de datos. Los algoritmos de aprendizaje automático suelen basarse en estadísticas, cálculo y álgebra lineal. Algunos ejemplos populares de algoritmos de aprendizaje automático incluyen regresión lineal, árboles de decisión, bosque aleatorio y XGBoost.
¿Qué es el entrenamiento de modelos en el aprendizaje automático?
El proceso de ejecutar un algoritmo de aprendizaje automático en un conjunto de datos (llamado datos de entrenamiento) y optimizar el algoritmo para encontrar ciertos patrones o salidas se denomina entrenamiento de modelos. La función resultante con reglas y estructuras de datos se denomina modelo de aprendizaje automático entrenado.
¿Cuáles son los diferentes tipos de aprendizaje automático?
En general, la mayoría de las técnicas de aprendizaje automático se pueden clasificar en aprendizaje supervisado, aprendizaje no supervisado y aprendizaje por refuerzo.
¿Qué es el aprendizaje automático supervisado?
En el aprendizaje automático supervisado, se le proporciona al algoritmo un conjunto de datos de entrada y se le recompensa o se optimiza para cumplir con un conjunto de resultados específicos. Por ejemplo, el aprendizaje automático supervisado se utiliza ampliamente en el reconocimiento de imágenes, en el que se usa una técnica llamada clasificación. El aprendizaje automático supervisado también se usa para predecir datos demográficos, como el crecimiento de la población o los indicadores de salud, mediante una técnica llamada regresión.
¿Qué es el aprendizaje automático no supervisado?
En el aprendizaje automático no supervisado, se proporciona al algoritmo un conjunto de datos de entrada, pero no se recompensa ni se optimiza para obtener resultados específicos, sino que se entrena para agrupar objetos por características comunes. Por ejemplo, los motores de recomendación de las tiendas en línea se basan en el aprendizaje automático no supervisado, concretamente en una técnica denominada agrupamiento.
¿Qué es el aprendizaje por refuerzo?
En el aprendizaje por refuerzo, el algoritmo se entrena a sí mismo mediante numerosos experimentos de prueba y error. El aprendizaje por refuerzo se produce cuando el algoritmo interactúa continuamente con el entorno, en lugar de basarse en datos de entrenamiento. Uno de los ejemplos más populares de aprendizaje por refuerzo es la conducción autónoma.
¿Cuáles son los diferentes modelos de aprendizaje automático?
Existen muchos modelos de aprendizaje automático, y casi todos se basan en ciertos algoritmos de aprendizaje automático. Los algoritmos populares de clasificación y regresión caen bajo el aprendizaje automático supervisado, y los algoritmos de agrupamiento generalmente se implementan en escenarios de aprendizaje automático no supervisado.
Aprendizaje automático supervisado
- Regresión logística: se utiliza para determinar si una entrada pertenece a un determinado grupo o no.
- SVM: las máquinas de vectores de soporte (SVM) crean coordenadas para cada objeto en un espacio n-dimensional y utilizan un hiperplano para agrupar objetos por características comunes.
- Naive Bayes: es un algoritmo que asume la independencia entre variables y utiliza la probabilidad para clasificar objetos en función de sus características.
- Árboles de decisión: también son clasificadores que se usan para determinar en qué categoría pertenece una entrada al recorrer las hojas y nodos de un árbol.
- Regresión lineal: se utiliza para identificar relaciones entre la variable de interés y las entradas, y predecir sus valores basándose en los valores de las variables de entrada.
- kNN: la técnica de los k vecinos más cercanos implica agrupar los objetos más cercanos en un conjunto de datos y encontrar las características más frecuentes o promedio entre los objetos.
- Bosque aleatorio: es una colección de muchos árboles de decisión de subconjuntos aleatorios de los datos, lo que da lugar a una combinación de árboles que pueden ser más precisos en la predicción que un solo árbol de decisión.
- Algoritmos de potenciación: estos utilizan aprendizaje en conjunto, como Gradient Boosting Machine, XGBoost y LightGBM. Combinan las predicciones de varios algoritmos (como los árboles de decisión) y toman en cuenta el error del algoritmo anterior.
Aprendizaje automático no supervisado
- K-Means: este algoritmo encuentra similitudes entre objetos y los agrupa en K clústeres diferentes.
- Agrupamiento jerárquico: construye un árbol de clústeres anidados sin necesidad de especificar el número de clústeres.
¿Qué es un árbol de decisión en el aprendizaje automático (ML)?
Un árbol de decisiones es un enfoque predictivo en aprendizaje automático para determinar a qué clase pertenece un objeto. Como su nombre lo indica, un árbol de decisión es un diagrama de flujo en forma de árbol donde la clase de un objeto se determina paso a paso mediante ciertas condiciones conocidas. 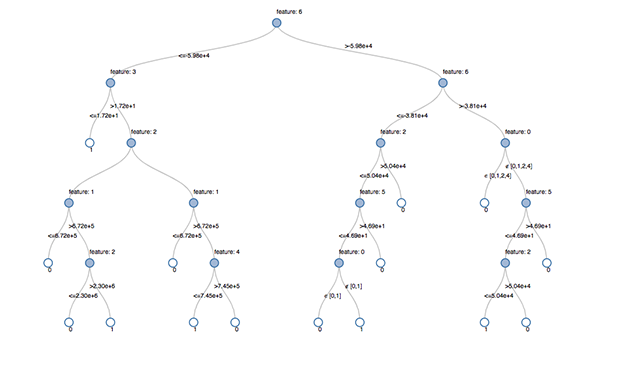 Un árbol de decisión visualizado en Databricks Lakehouse. Fuente: https://www.databricks.com/blog/2019/05/02/detecting-financial-fraud-at-scale-with-decision-trees-and-mlflow-on-databricks.html
Un árbol de decisión visualizado en Databricks Lakehouse. Fuente: https://www.databricks.com/blog/2019/05/02/detecting-financial-fraud-at-scale-with-decision-trees-and-mlflow-on-databricks.html
La guía de IA agéntica para la empresa

¿Qué es la regresión en el aprendizaje automático?
La regresión en la ciencia de datos y el aprendizaje automático es un método estadístico que permite predecir resultados en base a un conjunto de variables de entrada. El resultado suele ser una variable que depende de una combinación de las variables de entrada. 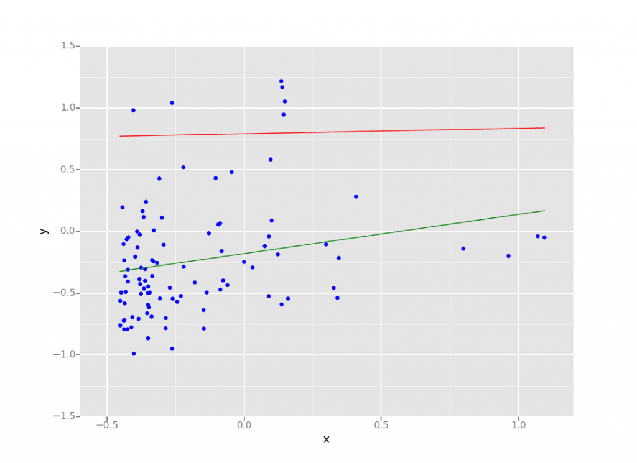 Un modelo de regresión lineal realizado en Databricks Lakehouse. Fuente: https://www.databricks.com/blog/2015/06/04/simplify-machine-learning-on-spark-with-databricks.html
Un modelo de regresión lineal realizado en Databricks Lakehouse. Fuente: https://www.databricks.com/blog/2015/06/04/simplify-machine-learning-on-spark-with-databricks.html
¿Qué es un clasificador en aprendizaje automático?
Un clasificador es un algoritmo de aprendizaje automático que asigna un objeto como miembro de una categoría o grupo. Por ejemplo, los clasificadores se utilizan para detectar si un correo electrónico es spam o si una transacción es fraudulenta.
¿Cuántos modelos existen en el aprendizaje automático?
¡Muchos! El aprendizaje automático es un campo en evolución y siempre se están desarrollando más modelos de aprendizaje automático.
¿Cuál es el mejor modelo para el aprendizaje automático?
El modelo de aprendizaje automático más adecuado para una situación específica depende del resultado deseado. Por ejemplo, para predecir el número de compras de vehículos en una ciudad a partir de datos históricos, una técnica de aprendizaje supervisado como la regresión lineal podría ser la más útil. Por otro lado, para identificar si un cliente potencial en esa ciudad compraría un vehículo, dados sus ingresos e historial de desplazamientos, un árbol de decisiones podría ser la mejor opción.
¿Qué es la implementación de modelos en el aprendizaje automático (ML)?
El despliegue de modelos es el proceso de hacer disponible un modelo de aprendizaje automático para su uso en un entorno objetivo, ya sea para pruebas o producción. El modelo suele integrarse con otras aplicaciones del entorno (como bases de datos e interfaces de usuario) a través de APIs. El despliegue es la etapa tras la cual una organización puede realmente obtener un retorno de la gran inversión realizada en el desarrollo de modelos. 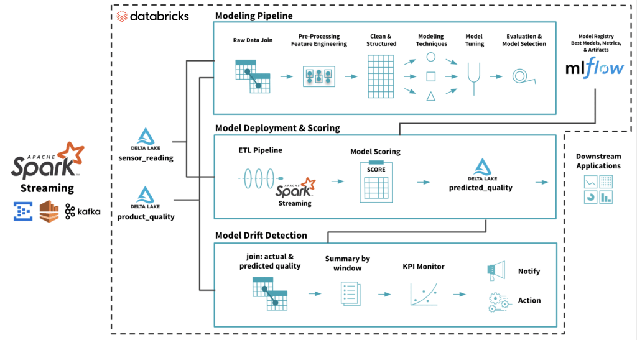 Un ciclo de vida completo de un modelo de aprendizaje automático en el Databricks Lakehouse. Fuente: https://www.databricks.com/blog/2019/09/18/productionizing-machine-learning-from-deployment-to-drift-detection.html
Un ciclo de vida completo de un modelo de aprendizaje automático en el Databricks Lakehouse. Fuente: https://www.databricks.com/blog/2019/09/18/productionizing-machine-learning-from-deployment-to-drift-detection.html
¿Qué son los modelos de aprendizaje profundo?
Los modelos de aprendizaje profundo son una clase de modelos de aprendizaje automático que imitan la forma en que los humanos procesan la información. El modelo consta de varias capas de procesamiento (de ahí el término 'profundo') para extraer características de alto nivel de los datos proporcionados. Cada capa de procesamiento transmite una representación más abstracta de los datos a la siguiente capa, y la capa final proporciona una visión más similar a la humana. A diferencia de los modelos tradicionales de ML que requieren que los datos sean etiquetados, los modelos de aprendizaje profundo pueden ingerir grandes cantidades de datos no estructurados. Se emplean para realizar funciones más humanas, como el reconocimiento facial y el procesamiento del lenguaje natural.  Una representación simplificada del aprendizaje profundo. Fuente: https://www.databricks.com/discover/pages/the-democratization-of-artificial-intelligence-and-deep-learning
Una representación simplificada del aprendizaje profundo. Fuente: https://www.databricks.com/discover/pages/the-democratization-of-artificial-intelligence-and-deep-learning
¿Qué es el aprendizaje automático de series temporales?
Un modelo de aprendizaje automático de series temporales es aquel en el que una de las variables independientes es una longitud sucesiva de tiempo (minutos, días, años, etc.) y tiene una relación con la variable dependiente o predicha. Los modelos de aprendizaje automático de series temporales se utilizan para predecir eventos temporales, como por ejemplo: el tiempo la semana próxima, el número esperado de clientes en un mes futuro, la orientación de ingresos para el año próximo, etc.
¿Dónde puedo obtener más información sobre el aprendizaje automático?
- Consulta este libro electrónico gratuito para descubrir los muchos casos de uso fascinantes de aprendizaje automático que están implementando las empresas a nivel mundial.
- Para obtener una comprensión más profunda del aprendizaje automático por parte de los expertos, consulte el blog de aprendizaje automático de Databricks.
Recursos adicionales
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.