¿Qué es Adagrad?
Un optimizador de tasa de aprendizaje adaptativo que ajusta el tamaño del paso por parámetro en función de gradientes pasados acumulados, especialmente útil para datos dispersos y PNL.
- Divide la tasa de aprendizaje entre la raíz cuadrada de los gradientes cuadrados acumulados para cada parámetro, lo que genera tamaños de paso adaptativos por parámetro con un decaimiento drástico con el tiempo.
- Especialmente eficaz para características dispersas e incrustaciones de palabras en PLN, donde las características poco frecuentes requieren actualizaciones más grandes para aprender representaciones significativas a partir de ejemplos de entrenamiento limitados.
- Puede sufrir tasas de aprendizaje decrecientes que detienen el entrenamiento prematuramente; se ha mejorado con variantes como Adadelta y RMSprop que utilizan medias móviles exponenciales en lugar de acumulación completa.
El descenso del gradiente es el método de optimización más comúnmente utilizado en los algoritmos de aprendizaje automático y aprendizaje profundo. Se usa para entrenar un modelo de aprendizaje automático.
Tipos de descenso de gradiente
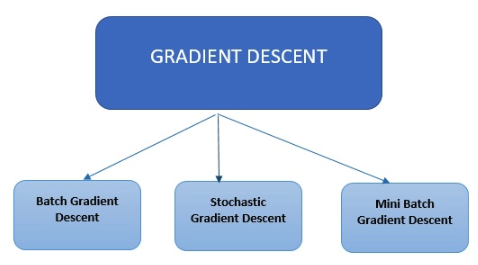 En los algoritmos modernos de aprendizaje automático y aprendizaje profundo se emplean tres tipos principales de descenso del gradiente.
En los algoritmos modernos de aprendizaje automático y aprendizaje profundo se emplean tres tipos principales de descenso del gradiente.
Descenso de gradiente por lotes
El descenso del gradiente por lotes es el tipo más sencillo. Calcula el error para cada ejemplo en el conjunto de datos de entrenamiento; sin embargo, solo actualiza el modelo después de que se han evaluado todos los ejemplos de entrenamiento.
Descenso de gradiente estocástico
El descenso del gradiente estocástico calcula el error y actualiza el modelo para cada ejemplo en el conjunto de datos de entrenamiento.
Descenso del gradiente por minilotes
El descenso del gradiente por minilotes, en lugar de revisar todos los ejemplos, resume un número menor de ejemplos en función del tamaño del lote y realiza una actualización para cada uno de estos lotes. El descenso del gradiente estocástico es un método común para la optimización. Es conceptualmente simple y, a menudo, se puede implementar de manera eficiente. Sin embargo, tiene un parámetro (el tamaño del paso) que debe ajustarse manualmente. Se han propuesto diferentes opciones para automatizar este ajuste. Uno de los esquemas exitosos es AdaGrad. Mientras que los métodos estándar de subgradiente estocástico siguen principalmente un esquema de procedimiento predeterminado que ignora las características de los datos que se observan. Por el contrario, los algoritmos de AdaGrad incorporan dinámicamente el conocimiento de la geometría de los datos observados en iteraciones anteriores para realizar un aprendizaje basado en gradientes más informativo. AdaGrad se lanzó en dos versiones. AdaGrad Diagonal (esta es la versión que usamos en la práctica), su principal característica es que mantiene y adapta una tasa de aprendizaje por dimensión; la segunda versión conocida como Full AdaGrad mantiene una tasa de aprendizaje por dirección (por ejemplo, una matriz PSD completa). El algoritmo de gradiente adaptativo (Adagrad) es un algoritmo para la optimización basada en gradientes. La tasa de aprendizaje se adapta por componentes a los parámetros incorporando el conocimiento de observaciones pasadas. Realiza actualizaciones más grandes (por ejemplo, altas tasas de aprendizaje) para aquellos parámetros que están relacionados con características poco frecuentes y actualizaciones más pequeñas (es decir, bajas tasas de aprendizaje) para los frecuentes. Realiza actualizaciones más pequeñas. Como resultado, es muy adecuada cuando se trata de datos dispersos (PLN o reconocimiento de imágenes). Cada parámetro tiene su propia tasa de aprendizaje que mejora el rendimiento en problemas con gradientes dispersos.
Ventajas de utilizar AdaGrad
- Elimina la necesidad de ajustar manualmente la tasa de aprendizaje
- La convergencia es más rápida y confiable que el simple SGD cuando la escala de los pesos es desigual.
- No es muy sensible al tamaño del paso maestro.
La guía de IA agéntica para la empresa

Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.