¿Qué es Apache Spark?
Un motor de análisis unificado para el procesamiento de datos distribuidos a gran escala con API en Java, Scala, Python y R para procesamiento por lotes, transmisión, aprendizaje automático y gráficos.
- Construido sobre conjuntos de datos distribuidos resilientes (RDD), permite operaciones paralelas en memoria con tolerancia a fallos y evaluación diferida, lo que ofrece mejoras de velocidad de 10 a 100 veces con respecto a Hadoop MapReduce para cargas de trabajo iterativas.
- Proporciona la API DataFrame con el optimizador Catalyst para la planificación de consultas y el motor de ejecución Tungsten para la gestión de memoria, compatible con consultas SQL y procesamiento de datos estructurados.
- Incluye MLlib para aprendizaje automático distribuido, Structured Streaming para procesamiento en tiempo real y GraphX para análisis de grafos; todos comparten el mismo marco de ejecución.
¿Qué es Apache Spark?
Apache Spark es un motor de análisis de código abierto que se usa para cargas de trabajo de big data. Puede manejar cargas de trabajo tanto por lotes como de análisis en tiempo real y de procesamiento de datos. Apache Spark comenzó en 2009 como un proyecto de investigación en la Universidad de California, Berkeley. Los investigadores buscaban una manera de acelerar los trabajos de procesamiento en los sistemas de Hadoop. Se basa en Hadoop MapReduce y extiende el modelo MapReduce para usarlo de forma eficiente en más tipos de cómputos, lo que incluye consultas interactivas y procesamiento de streaming. Spark proporciona vinculaciones nativas para los lenguajes de programación Java, Scala, Python y R. Además, incluye varias bibliotecas para admitir la creación de aplicaciones para el aprendizaje automático [MLlib], el procesamiento de transmisiones [Spark Streaming] y el procesamiento de grafos [GraphX]. Apache Spark consta de Spark Core y un conjunto de bibliotecas. Spark Core es el corazón de Apache Spark y es responsable de proporcionar la transmisión de tareas distribuidas, la programación y la funcionalidad de I/O. El motor de Spark Core usa el concepto de conjunto de datos distribuido y resiliente (RDD) como su tipo de datos básico. El RDD está diseñado para ocultar la mayor parte de la complejidad computacional a sus usuarios. Spark opera sobre los datos de forma inteligente; los datos y las particiones se agregan en un clúster de servidores, donde pueden procesarse y, luego, moverse a otro almacén de datos o ejecutarse a través de un modelo analítico. No se te pedirá que especifiques el destino de los archivos o los recursos computacionales que deben usarse para almacenar o recuperar archivos. 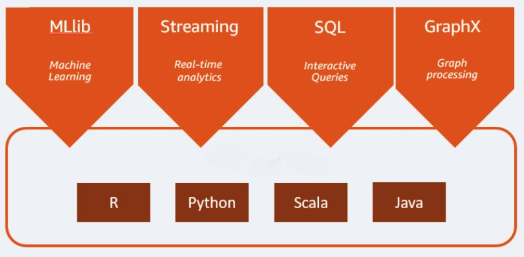
La guía de IA agéntica para la empresa

¿Cuáles son los beneficios de Apache Spark?
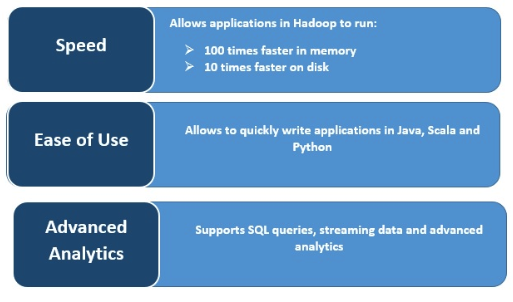
Velocidad
Spark se ejecuta muy rápido al almacenar datos en la memoria caché en múltiples operaciones en paralelo. La característica principal de Spark es su motor en memoria que aumenta la velocidad de procesamiento; haciéndolo hasta 100 veces más rápido que MapReduce cuando se procesa en memoria y 10 veces más rápido en disco, cuando se trata de procesamiento de datos a gran escala. Spark hace esto posible al reducir el número de operaciones de lectura/escritura en el disco.
Procesamiento de flujos en tiempo real
Apache Spark puede procesar streaming en tiempo real y también se integra con otros frameworks. Spark ingiere datos en minilotes y realiza transformaciones de RDD en esos minilotes de datos.
Admite múltiples cargas de trabajo
Apache Spark puede ejecutar múltiples cargas de trabajo, como consultas interactivas, análisis en tiempo real, aprendizaje automático y procesamiento de grafos. Una sola aplicación puede combinar múltiples cargas de trabajo sin problemas.
Mayor usabilidad
La capacidad de admitir varios lenguajes de programación lo hace dinámico. Te permite escribir aplicaciones rápidamente en Java, Scala, Python y R, lo que te da una variedad de lenguajes para crear tus aplicaciones.
Analítica avanzada
Spark admite consultas SQL, aprendizaje automático, procesamiento de streaming y procesamiento de grafos.
Recursos adicionales
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.