¿Qué es Catalyst Optimizer?
Cómo el optimizador Catalyst utiliza técnicas basadas en reglas y costos en planes de consulta estructurados en árbol para hacer que las consultas Spark SQL sean más rápidas, más eficientes y más fáciles de ampliar
- Descubra cómo Catalyst se encuentra en el corazón de Spark SQL como un optimizador extensible basado en funciones de Scala como la coincidencia de patrones y las cuasi-citas para admitir nuevas reglas y tipos de datos.
- Comprenda cómo Catalyst representa las consultas como árboles y aplica reglas en las fases de análisis, optimización lógica, planificación física y generación de código para crear planes de ejecución eficientes.
- Descubra cómo Catalyst admite la optimización basada en reglas y costos, y expone puntos de extensión para fuentes de datos externas y tipos definidos por el usuario.
En el núcleo de Spark SQL se encuentra el optimizador Catalyst, que aprovecha las características avanzadas del lenguaje de programación (p. ej.: el patrón de coincidencia y las cuasi-citas o "quasiquotes" de Scala) de una forma novedosa para crear un optimizador de consultas extensible. Catalyst se basa en construcciones de programación funcional en Scala y está diseñado con dos objetivos clave:
- Agregar fácilmente nuevas técnicas y características de optimización a Spark SQL.
- Permitir a desarrolladores externos ampliar el optimizador (p. ej.: agregar reglas específicas de fuentes de datos, soporte para nuevos tipos de datos, etc.)
La guía de IA agéntica para la empresa

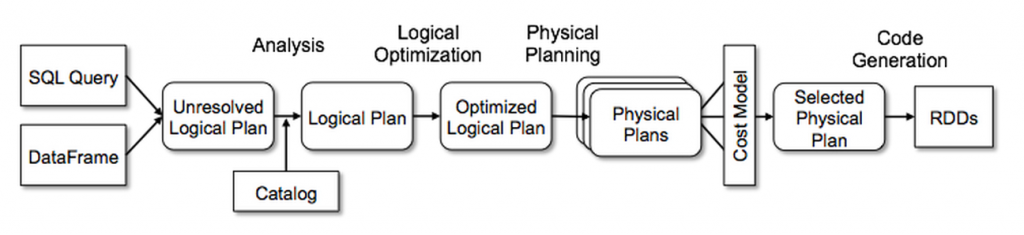
Catalyst contiene una biblioteca general para representar árboles y aplica reglas para manipularlos. Además de este marco, cuenta con bibliotecas específicas para el procesamiento de consultas relacionales (p. ej.: expresiones, planes de consulta lógica) y varios conjuntos de reglas que gestionan las diferentes fases de la ejecución de consultas: análisis, optimización lógica, planificación física y generación de códigos para compilar las partes de las consultas en código de byte de Java. Para esto, utiliza otra característica de Scala, quasiquotes, que facilita la generación de código en tiempo de ejecución a partir de expresiones componibles. Catalyst también ofrece varios puntos de extensión públicos, como las fuentes de datos externas y los tipos definidos por el usuario. Además, Catalyst admite tanto la optimización basada en reglas como la basada en costos.
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.