¿Qué es la arquitectura Lambda?
Arquitectura que combina procesamiento por lotes y en flujo con una capa de lote para precisión, una capa de velocidad para resultados en tiempo real y una capa de servicio que fusiona ambas.
- La capa de lotes almacena el conjunto de datos maestro en un formato inmutable de solo anexión y precalcula las vistas de lotes mediante procesamiento estilo MapReduce, lo que proporciona resultados completos y precisos, pero con horas de latencia.
- La capa de velocidad procesa únicamente flujos de datos recientes mediante sistemas de baja latencia como Storm o Flink, creando vistas en tiempo real que compensan el retraso de la capa de lotes con consistencia final al actualizar las vistas de lotes.
- La capa de servicio indexa las vistas de lotes y de velocidad, lo que permite consultas ad-hoc rápidas que fusionan ambas perspectivas. Sin embargo, la complejidad de la arquitectura ha disminuido a medida que los sistemas de transmisión como Apache Spark ofrecen capacidades tanto de lotes como en tiempo real.
¿Qué es la Arquitectura Lambda?
La arquitectura Lambda es una forma de procesar grandes cantidades de datos (es decir, “Big Data”) que ofrece acceso a métodos de procesamiento por lotes y procesamiento de transmisión con un enfoque híbrido. La arquitectura Lambda se usa para resolver el problema del cálculo de funciones arbitrarias. La arquitectura Lambda en sí está compuesta por 3 capas:
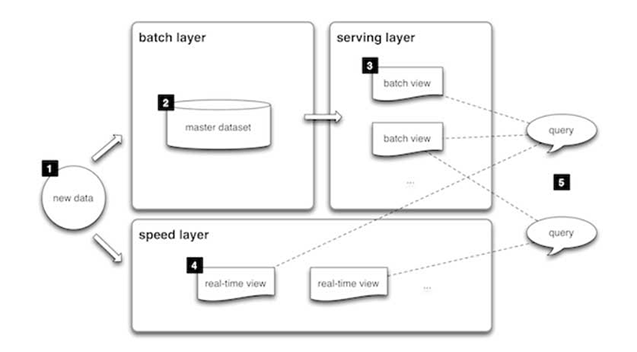
Capa por lotes
Los nuevos datos llegan de forma continua al sistema de datos. Se envían simultáneamente a la capa por lotes y a la capa de velocidad. El sistema analiza todos los datos a la vez y, finalmente, los corrige en la capa de transmisión. Aquí podemos encontrar mucho ETL y un almacén de datos tradicional. Esta capa se crea con un cronograma predefinido, normalmente una o dos veces al día. La capa por lotes tiene dos funciones muy importantes:
- Gestionar el conjunto de datos maestro
- Calcular previamente las vistas por lotes
Capa de servicio
Las salidas de la capa por lotes, en forma de vistas por lotes, y las que provienen de la capa de velocidad, en forma de vistas casi en tiempo real, se envían al servicio. Esta capa indexa las vistas por lotes para que se puedan consultar con baja latencia de forma ad hoc.
Capa de velocidad (capa de transmisión)
Esta capa gestiona los datos que aún no se entregan en la vista por lotes debido a la latencia de la capa por lotes. Además, solo maneja datos recientes para proporcionar una visión completa de los datos al usuario mediante la creación de vistas en tiempo real.
La guía de IA agéntica para la empresa

Beneficios de las arquitecturas lambda
Estos son los principales beneficios de las arquitecturas lambda:
- No tiene administración de servidores: no tienes que instalar, mantener ni administrar ningún software.
- Escalado flexible: tu aplicación puede escalarse automáticamente o escalarse mediante el ajuste de su capacidad.
- Alta disponibilidad automatizada: se refiere al hecho de que las aplicaciones sin servidor ya tienen disponibilidad incorporada y tolerancia a fallas. Representa una garantía de que todas las solicitudes obtendrán una respuesta sobre si tuvieron éxito o no.
- Agilidad empresarial: reacciona en tiempo real a los cambiantes escenarios del negocio/mercado
Desafíos con las arquitecturas lambda
- Complejidad: las arquitecturas Lambda pueden ser muy complejas. Los administradores normalmente deben mantener bases de código separadas para las capas por lotes y de transmisión, lo que puede dificultar la depuración.
Relacionado
Delta Lake: fuente y destino unificados para procesamiento por lotes y de transmisión
Recursos adicionales
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.