¿Qué es Spark Streaming?
Cómo Spark Streaming procesa microlotes de datos en tiempo real con DStreams y por qué Structured Streaming es ahora el motor preferido
- Comprenda qué es Apache Spark Streaming, cómo amplía la API principal de Spark y por qué ahora se considera un motor de streaming heredado en favor de la transmisión estructurada.
- Vea cómo Spark Streaming ingiere datos de fuentes como Kafka, Flume y Amazon Kinesis, los procesa en microlotes y envía los resultados a archivos, bases de datos o paneles mediante DStreams.
- Explore las principales ventajas que introdujo Spark Streaming, como el procesamiento unificado de lotes y streaming, la tolerancia a fallos y la integración con MLlib y Spark SQL.
Apache Spark Streaming es la generación anterior del motor de streaming de Apache Spark. Ya no hay actualizaciones para Spark Streaming y es un proyecto heredado. Hay un motor de streaming más nuevo y fácil de usar en Apache Spark llamado Structured Streaming. Deberías usar Spark Structured Streaming para tus aplicaciones y canalizaciones de streaming. Consulta Structured Streaming.
¿Qué es Spark Streaming?
Apache Spark Streaming es un sistema de procesamiento de streaming escalable y tolerante a errores que admite de forma nativa cargas de trabajo tanto por lotes como de streaming. Spark Streaming es una extensión de la API principal de Spark que permite a los ingenieros y científicos de datos procesar datos en tiempo real de diversas fuentes, como Kafka, Flume y Amazon Kinesis. Estos datos procesados se pueden enviar a sistemas de archivos, bases de datos y paneles en vivo. Su abstracción principal es un flujo discretizado o, en resumen, un DStream, que representa un flujo de datos dividido en lotes pequeños. Los DStreams se basan en los RDD, la abstracción de datos principal de Spark. Esto permite que Spark Streaming se integre sin problemas con cualquier otro componente de Spark, como MLlib y Spark SQL. Spark Streaming es diferente de otros sistemas que tienen un motor de procesamiento diseñado solo para el streaming o que tienen API similares para lotes y streaming, pero se compilan internamente en motores diferentes. El motor de ejecución único de Spark y el modelo de programación unificado para lotes y streaming ofrecen algunos beneficios únicos en comparación con otros sistemas de streaming tradicionales.
La guía de IA agéntica para la empresa

Cuatro aspectos principales de Spark Streaming
- Recuperación rápida de fallas y nodos rezagados
- Mejor balanceo de carga y uso de recursos
- Combinación de datos en streaming con conjuntos de datos estáticos y consultas interactivas
- Integración nativa con bibliotecas de procesamiento avanzado (SQL, aprendizaje automático, procesamiento de grafos)
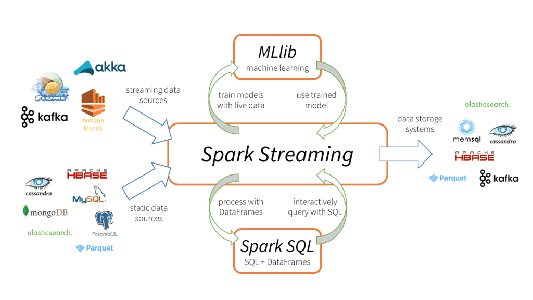
Esta unificación de diversas capacidades de procesamiento de datos es la razón principal de la rápida adopción de Spark Streaming. Les facilita mucho a los desarrolladores usar un solo framework para satisfacer todas sus necesidades de procesamiento.
Recursos adicionales
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.