Presentamos Apache Spark 3.0
Ya disponible en Databricks Runtime 7.0
por Matei Zaharia, Reynold Xin, Xiao Li, Wenchen Fan y Yin Huai
Nos complace anunciar que Apache SparkTM 3.0.0 Esta versión está disponible en Databricks como parte de nuestro nuevo Databricks Runtime 7.0. La versión 3.0.0 Esta versión incluye más de 3400 parches y es la culminación de enormes contribuciones de la comunidad de código abierto, lo que aporta importantes avances en las capacidades de Python y SQL y se centra en la facilidad de uso tanto para la exploración como para la producción. Estas iniciativas reflejan cómo ha evolucionado el proyecto para satisfacer más casos de uso y audiencias más amplias, y este año se conmemora su décimo aniversario como proyecto de código abierto.
Estas son las principales características nuevas de Spark 3.0:
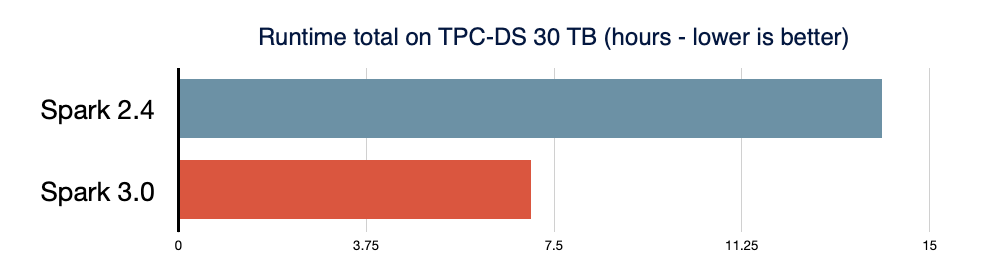
- Mejora del rendimiento 2x en TPC-DS sobre Spark 2.4, gracias a la ejecución adaptativa de consultas, la poda dinámica de particiones y otras optimizaciones
- Compatibilidad con ANSI SQL
- Mejoras significativas en las API de pandas, que incluyen sugerencias de tipo de Python y UDF de pandas adicionales
- Mejor manejo de errores de Python, que simplifica las excepciones de PySpark
- Nueva UI para la transmisión estructurada
- Aceleraciones de hasta 40x para llamar a las funciones definidas por el usuario de R
- Más de 3400 tickets de Jira resueltos
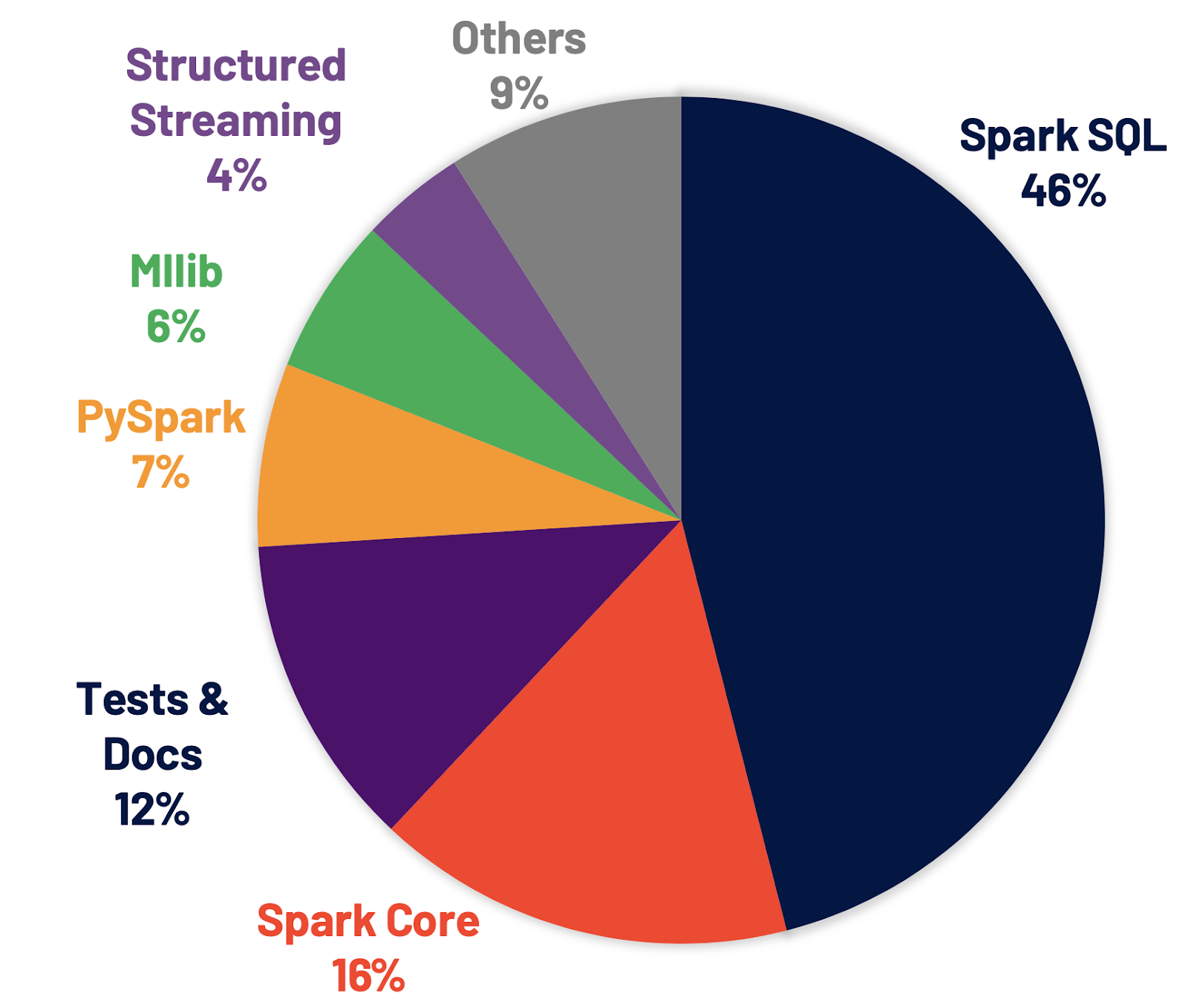
No se requieren cambios importantes en el código para adoptar esta versión de Apache Spark. Para obtener más información, consulta la guía de migración.
Celebramos los 10 años del desarrollo y la evolución de Spark
Spark surgió del AMPlab de la UC Berkeley, un laboratorio de investigación enfocado en la computación de datos intensiva. Los investigadores del AMPlab trabajaban con grandes empresas a escala de internet en sus problemas de datos e IA, pero vieron que estos mismos problemas también los enfrentarían todas las empresas con volúmenes de datos grandes y crecientes. El equipo desarrolló un nuevo motor para abordar estas cargas de trabajo emergentes y, al mismo tiempo, hacer que las API para trabajar con big data sean significativamente más accesibles para los desarrolladores.
Las contribuciones de la comunidad no tardaron en llegar para expandir Spark a diferentes áreas, con nuevas capacidades en torno al streaming, Python y SQL, y estos patrones ahora constituyen algunos de los casos de uso dominantes de Spark. Esa inversión continua ha llevado a Spark a donde está hoy, como el motor de facto para las cargas de trabajo de procesamiento de datos, ciencia de datos, machine learning y análisis de datos. Apache Spark 3.0 continúa esta tendencia al mejorar significativamente el soporte para SQL y Python —los dos lenguajes más utilizados con Spark en la actualidad—, así como las optimizaciones de rendimiento y operabilidad en el resto de Spark.
Mejoras en el motor Spark SQL
Spark SQL es el motor que respalda la mayoría de las aplicaciones de Spark. Por ejemplo, en Databricks, descubrimos que más del 90 % de las llamadas a la API de Spark usan las API de DataFrame, Dataset y SQL junto con otras bibliotecas optimizadas por el optimizador de SQL. Esto significa que incluso los desarrolladores de Python y Scala pasan gran parte de su trabajo a través del motor de Spark SQL. En la versión de Spark 3.0, el 46 % de todos los parches aportados fueron para SQL, lo que mejora tanto el rendimiento como la compatibilidad con ANSI. Como se ilustra a continuación, Spark 3.0 tuvo un rendimiento aproximadamente 2 veces mejor que Spark 2.4 en el tiempo de ejecución total. A continuación, explicamos cuatro características nuevas en el motor de Spark SQL.
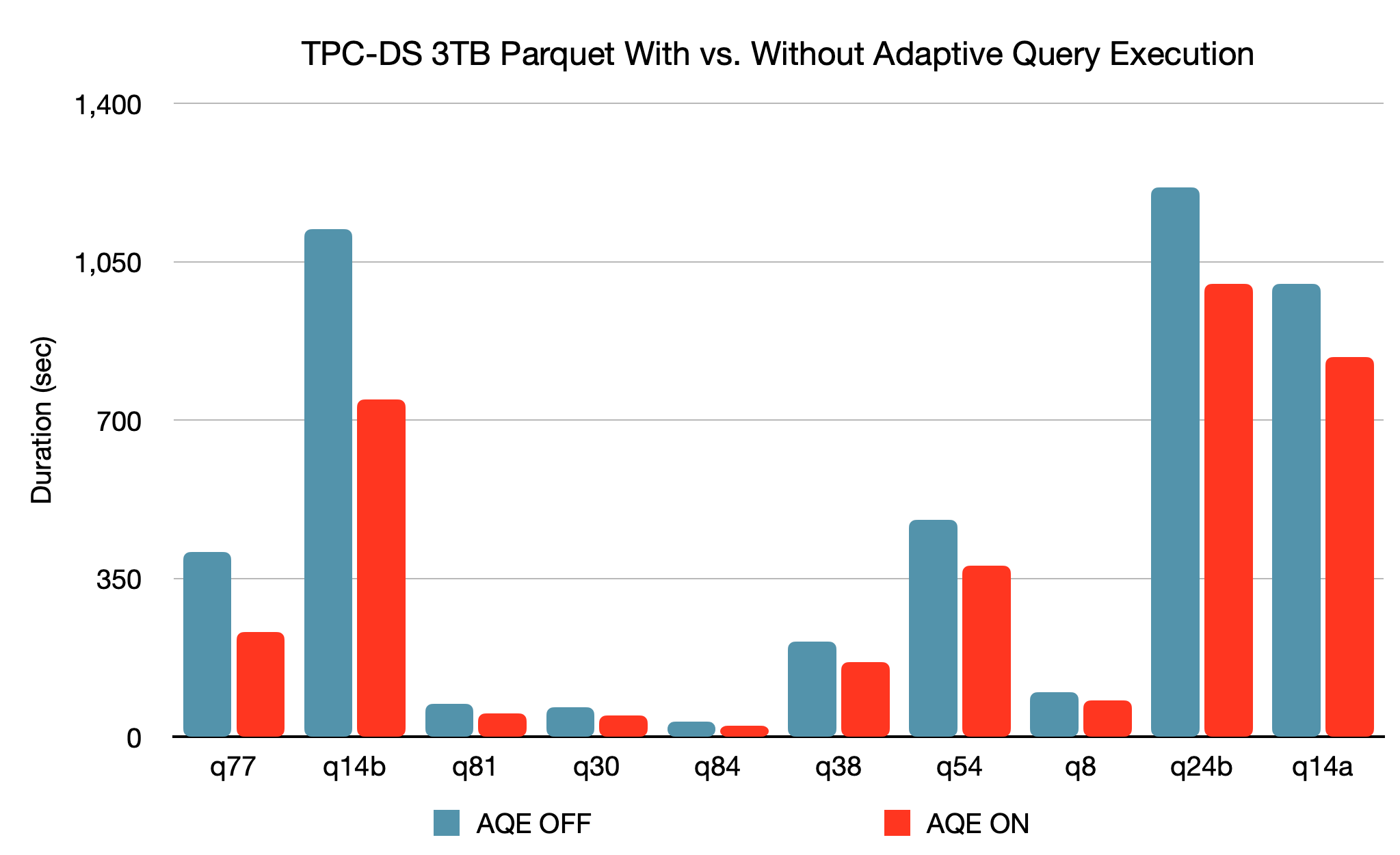
El nuevo marco de ejecución adaptativa de consultas (AQE) mejora el rendimiento y simplifica el ajuste, ya que genera un mejor plan de ejecución en tiempo de ejecución, incluso si el plan inicial es subóptimo debido a estadísticas de datos ausentes o imprecisas y costos mal estimados. Debido a la separación del almacenamiento y la computación en Spark, la llegada de datos puede ser impredecible. Por todas estas razones, la adaptabilidad en tiempo de ejecución se vuelve más fundamental para Spark que para los sistemas tradicionales. Esta versión introduce tres optimizaciones adaptativas principales:
- La unión dinámica de las particiones de shuffle simplifica o, incluso, evita el ajuste del número de particiones de shuffle. Los usuarios pueden establecer un número relativamente grande de particiones de reordenamiento al principio y, luego, AQE puede combinar las particiones pequeñas adyacentes en otras más grandes en tiempo de ejecución.
- El cambio dinámico de las estrategias de join evita parcialmente la ejecución de planes subóptimos debido a la falta de estadísticas o a una estimación errónea del tamaño. Esta optimización adaptativa puede convertir automáticamente un join de tipo sort-merge a uno de tipo broadcast-hash en tiempo de ejecución, lo que simplifica aún más el ajuste y mejora el rendimiento.
- La optimización dinámica de las uniones sesgadas es otra mejora de rendimiento fundamental, ya que las uniones sesgadas pueden provocar un desequilibrio extremo del trabajo y reducir gravemente el rendimiento. Después de que AQE detecta cualquier sesgo en las estadísticas de los archivos de shuffle, puede dividir las particiones sesgadas en otras más pequeñas y unirlas con las particiones correspondientes del otro lado. Esta optimización puede paralelizar el procesamiento del sesgo y lograr un mejor rendimiento general.
Según un benchmark TPC-DS de 3 TB, en comparación sin AQE, Spark con AQE puede producir aumentos de rendimiento de más de 1.5x para dos consultas y aumentos de más de 1.1x para otras 37 consultas.
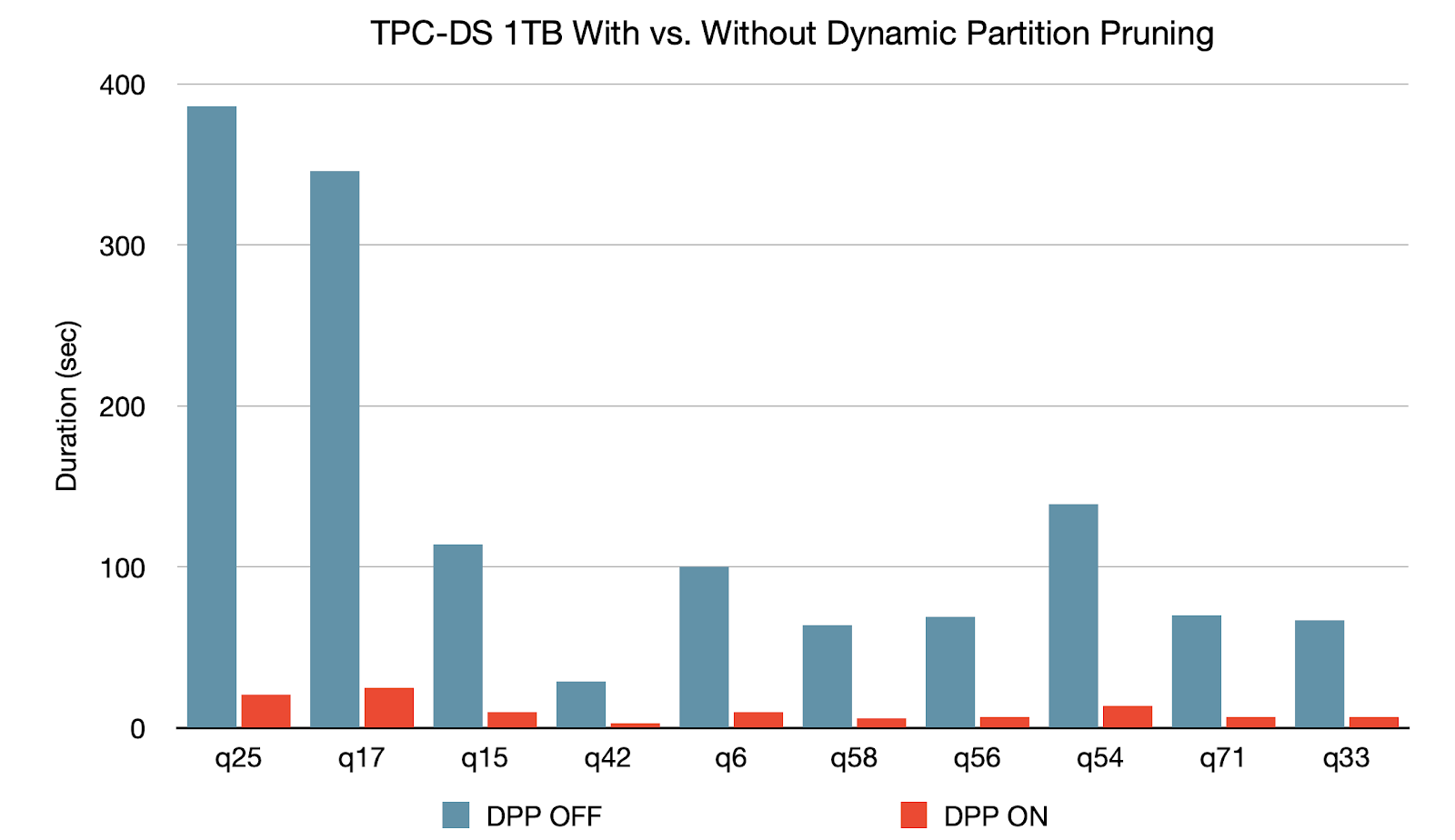
Dynamic Partition Pruning se aplica cuando el optimizador no puede identificar en tiempo de compilación las particiones que puede omitir. Esto es común en los esquemas de estrella, que consisten en una o varias tablas de hechos que hacen referencia a cualquier número de tablas de dimensiones. En estas operaciones de join, podemos podar las particiones que el join lee de una tabla de hechos, identificando aquellas particiones que resultan del filtrado de las tablas de dimensiones. En un benchmark TPC-DS, 60 de 102 consultas muestran una aceleración significativa de entre 2x y 18x.
La compatibilidad con ANSI SQL es fundamental para la migración de cargas de trabajo desde otros motores SQL a Spark SQL. Para mejorar la compatibilidad, esta versión cambia al calendario gregoriano proléptico y también permite a los usuarios prohibir el uso de las palabras clave reservadas de ANSI SQL como identificadores. Además, hemos introducido la comprobación de desbordamiento en tiempo de ejecución en operaciones numéricas y la aplicación de tipos en tiempo de compilación al insertar datos en una tabla con un esquema predefinido. Estas nuevas validaciones mejoran la calidad de los datos.
Indicaciones de join: Si bien continuamos mejorando el compilador, no hay garantía de que este siempre pueda tomar la decisión óptima en cada situación; la selección del algoritmo de join se basa en estadísticas y heurísticas. Cuando el compilador no puede tomar la mejor decisión, los usuarios pueden usar indicaciones de join para influir en el optimizador y que elija un plan mejor. Esta versión amplía las indicaciones de join existentes mediante la adición de nuevas indicaciones: SHUFFLE_MERGE, SHUFFLE_HASH y SHUFFLE_REPLICATE_NL.
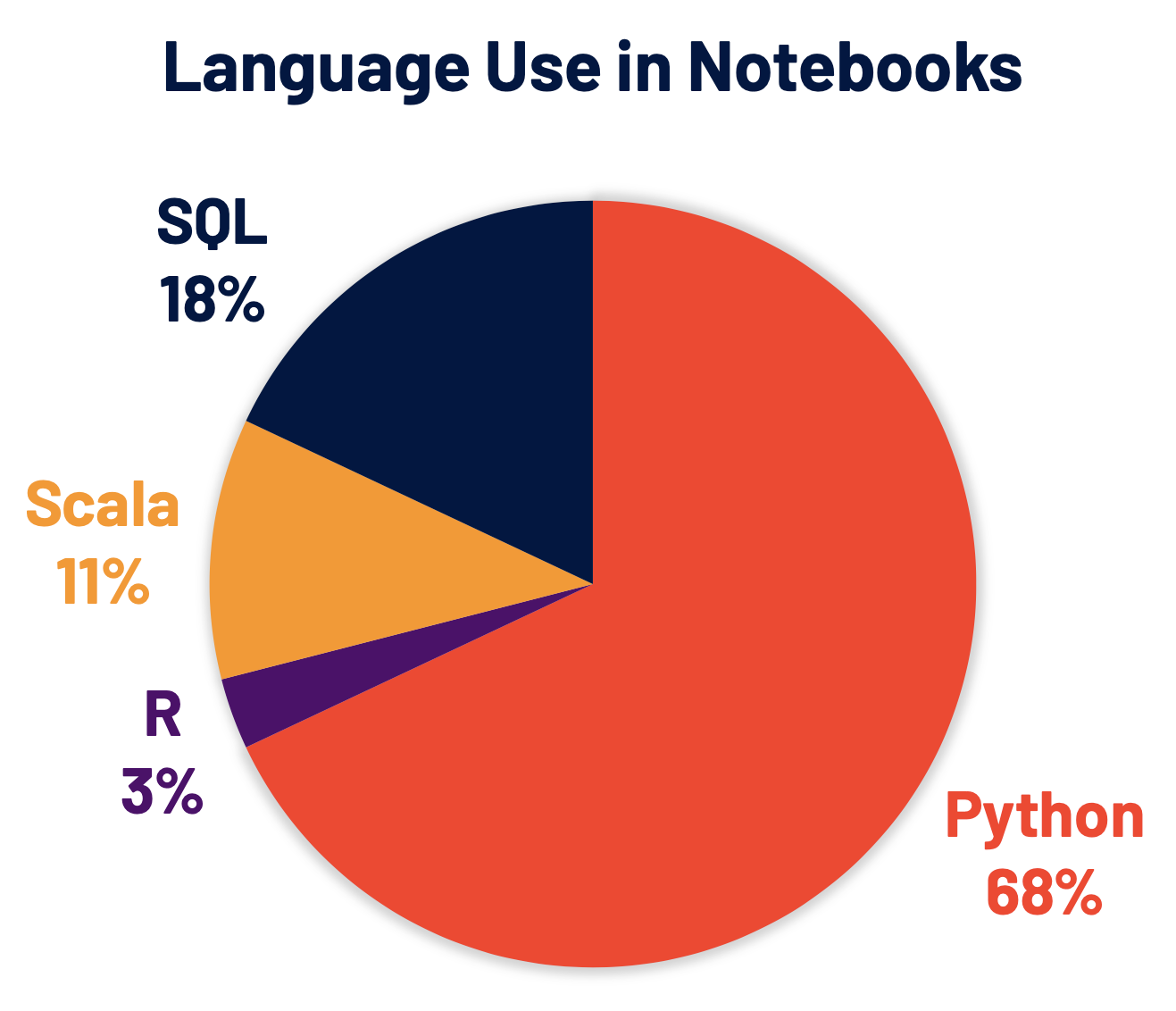
Python es ahora el lenguaje más utilizado en Spark y, por lo tanto, fue un área de enfoque clave del desarrollo de Spark 3.0. El 68 % de los comandos de notebook en Databricks están en Python. PySpark, la API de Python para Apache Spark, tiene más de 5 millones de descargas mensuales en PyPI, el índice de paquetes de Python.
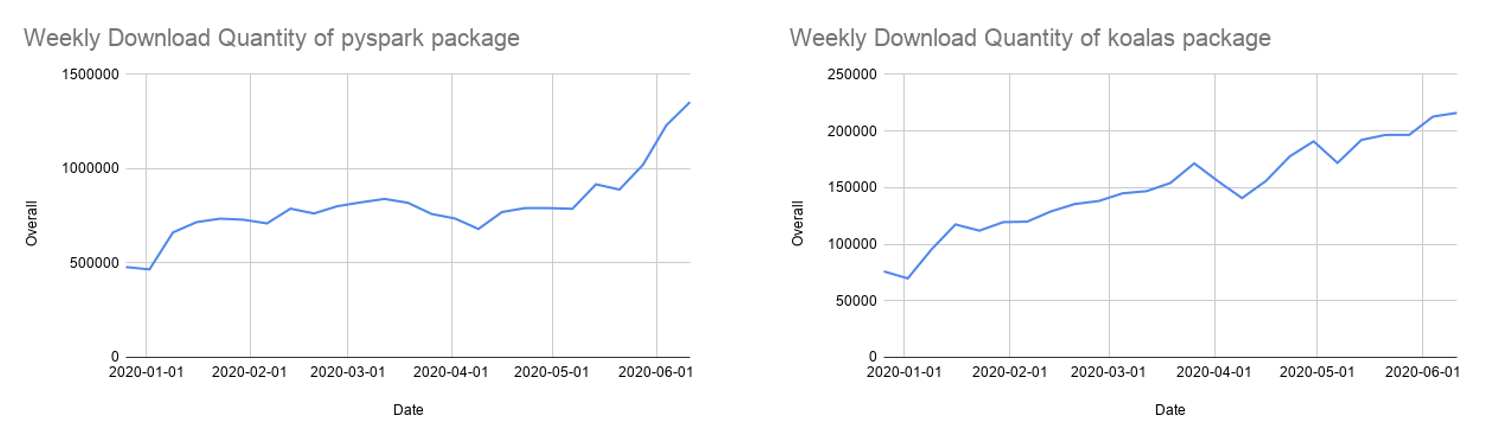
Muchos desarrolladores de Python usan la API de pandas para las estructuras y el análisis de datos, pero está limitada al procesamiento en un solo nodo. También hemos seguido desarrollando Koalas, una implementación de la API de pandas sobre Apache Spark, para que los científicos de datos sean más productivos cuando trabajan con big data en entornos distribuidos. Koalas elimina la necesidad de crear muchas funciones (p. ej., el soporte para gráficos) en PySpark para lograr un rendimiento eficiente en todo un clúster.
Después de más de un año de desarrollo, la cobertura de la API de Koalas para pandas se acerca al 80 %. Las descargas mensuales de Koalas en PyPI han crecido rápidamente hasta 850 000, y Koalas evoluciona rápidamente con una cadencia de lanzamiento quincenal. Si bien Koalas puede ser la forma más fácil de migrar el código de pandas de un solo nodo, muchos todavía usan las API de PySpark, que también están ganando popularidad.
Spark 3.0 trae varias mejoras a las API de PySpark:
- Nuevas API de pandas con sugerencias de tipo: las UDF de pandas se introdujeron inicialmente en Spark 2.3 para escalar funciones definidas por el usuario en PySpark e integrar las API de pandas en las aplicaciones de PySpark. Sin embargo, la interfaz existente es difícil de entender cuando se agregan más tipos de UDF. Esta versión introduce una nueva interfaz de UDF de pandas que aprovecha las sugerencias de tipo de Python para abordar la proliferación de tipos de UDF de pandas. La nueva interfaz se vuelve más pythónica y autodescriptiva.
- Nuevos tipos de UDF de pandas y API de funciones de pandas: Esta versión añade dos nuevos tipos de UDF de pandas, iterador de series a iterador de series e iterador de múltiples series a iterador de series. Es útil para la precarga de datos y la inicialización costosa. Además, se añaden dos nuevas API de funciones de pandas: map y co-grouped map. Hay más detalles disponibles en esta publicación de blog.
- Mejor manejo de errores: El manejo de errores de PySpark no siempre es fácil de usar para los usuarios de Python. Esta versión simplifica las excepciones de PySpark, oculta el seguimiento de pila de JVM innecesario y las hace más pitónicas.
Mejorar el soporte y la usabilidad de Python en Spark sigue siendo una de nuestras principales prioridades.
Hydrogen, streaming y extensibilidad
Con Spark 3.0, hemos finalizado componentes clave para el Proyecto Hydrogen, además de introducir nuevas capacidades para mejorar el streaming y la extensibilidad.
- Planificación compatible con aceleradores: El Proyecto Hydrogen es una iniciativa importante de Spark para unificar mejor el aprendizaje profundo y el procesamiento de datos en Spark. Las GPU y otros aceleradores se han utilizado ampliamente para acelerar las cargas de trabajo de aprendizaje profundo. Para que Spark aproveche los aceleradores de hardware en las plataformas de destino, esta versión mejora el planificador existente para que el administrador del clúster sea compatible con aceleradores. Los usuarios pueden especificar aceleradores a través de la configuración con la ayuda de un script de detección. Luego, los usuarios pueden llamar a las nuevas API de RDD para aprovechar estos aceleradores.
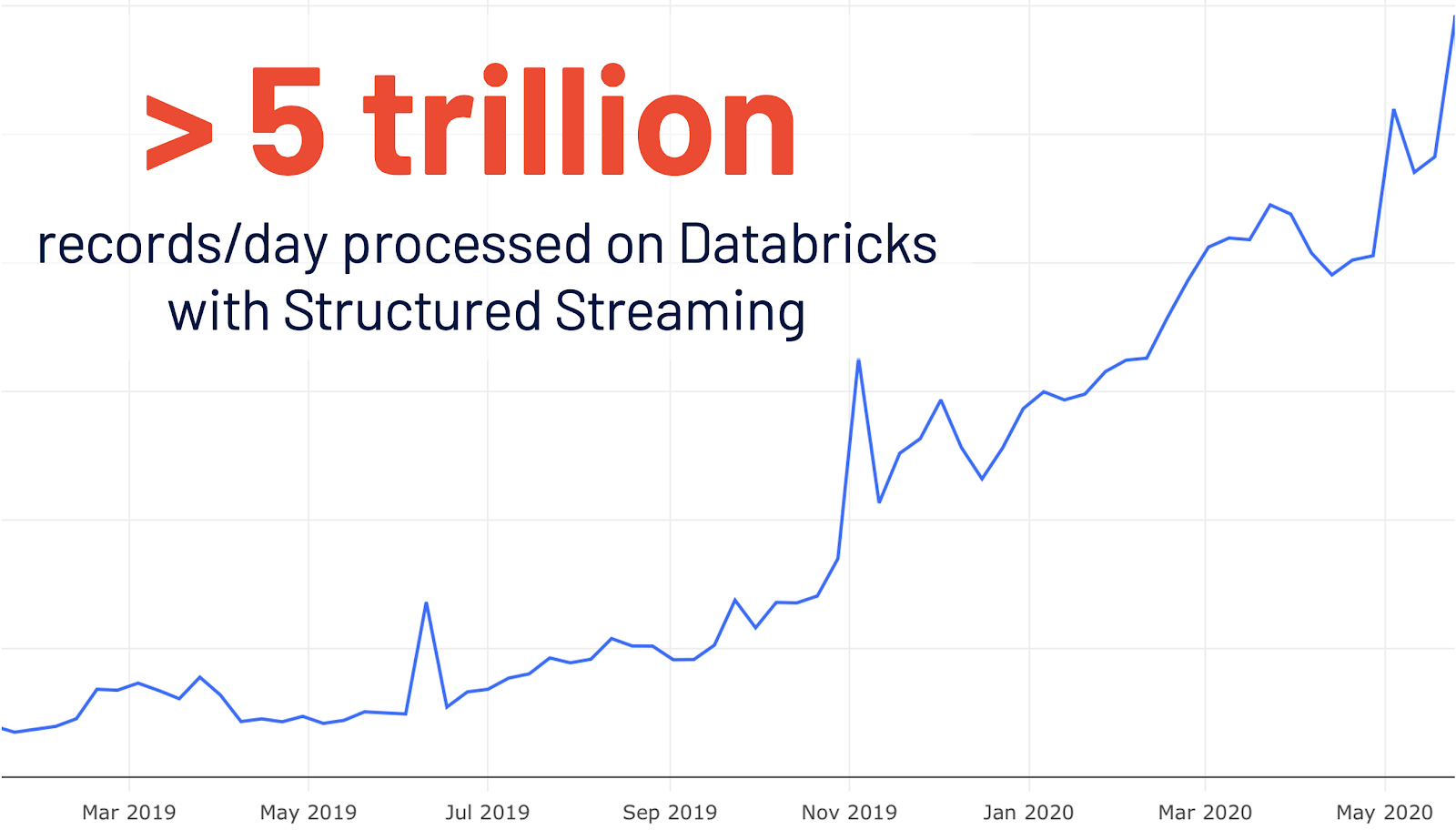
- Nueva IU para la transmisión estructurada: La transmisión estructurada se introdujo inicialmente en Spark 2.0. Tras un crecimiento interanual (YoY) del uso en Databricks de 4 veces, se procesan más de 5 billones de registros al día en Databricks con la transmisión estructurada. Esta versión añade una nueva IU de Spark dedicada para la inspección de estos trabajos de transmisión. Esta nueva UI ofrece dos conjuntos de estadísticas: 1) información agregada de los trabajos de consulta de streaming completados y 2) información estadística detallada sobre las consultas de streaming.
- Métricas observables: el monitoreo continuo de los cambios en la calidad de los datos es una característica muy deseable para administrar las canalizaciones de datos. Esta versión introduce el monitoreo para aplicaciones tanto por lotes como de transmisión. Las métricas observables son funciones de agregación arbitrarias que se pueden definir en una consulta (DataFrame). Tan pronto como la ejecución de un DataFrame llega a un punto de finalización (p. ej., finaliza la consulta por lotes o llega a una época de streaming), se emite un evento con nombre que contiene las métricas de los datos procesados desde el último punto de finalización.
- Nueva API de plug-in de catálogo: la API de fuente de datos existente carece de la capacidad para acceder y manipular los metadatos de las fuentes de datos externas. Esta versión enriquece la API V2 de la fuente de datos e introduce la nueva API de plug-in de catálogo. Para las fuentes de datos externas que implementan tanto la API de plug-in de catálogo como la API V2 de la fuente de datos, los usuarios pueden manipular directamente los datos y los metadatos de las tablas externas a través de identificadores de varias partes, después de que se registre el catálogo externo correspondiente.
Otras actualizaciones en Spark 3.0
Spark 3.0 es una versión importante para la comunidad, con más de 3400 tickets de Jira resueltos. Es el resultado de las contribuciones de más de 440 colaboradores, que incluyen tanto a particulares como a empresas como Databricks, Google, Microsoft, Intel, IBM, Alibaba, Facebook, Nvidia, Netflix, Adobe y muchas más. Para esta publicación de blog, hemos destacado varios de los avances clave de SQL, Python y streaming en Spark, pero hay muchas otras capacidades en este hito de la versión 3.0 que no se tratan aquí. Obtenga más información en las notas de la versión y descubra todas las demás mejoras de Spark, que incluyen fuentes de datos, ecosistema, supervisión y más.
Comience a usar Spark 3.0 hoy mismo
Si quiere probar Apache Spark 3.0 en Databricks Runtime 7.0, regístrese para obtener una cuenta de prueba gratuita y comience en cuestión de minutos. Usar Spark 3.0 es tan simple como seleccionar la versión “7.0” al iniciar un clúster.
Obtén más información sobre los detalles de las funciones y los lanzamientos:
- O’Reilly's New Learning Spark, 2nd Edition descarga gratuita del libro electrónico
- Ejecución adaptativa de consultas (blog)
- Pandas UDFs y Python Type Hints (blog)
- Vista previa de Spark 3.0: seminario web bajo demanda
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.