¿Qué es Apache Kylin?
Un motor OLAP distribuido que precalcula cubos multidimensionales a partir de datos de Hadoop y ofrece consultas en fracciones de segundo en conjuntos de datos de escala de petabytes.
- Precalcula cubos OLAP mediante MapReduce o Spark, almacenando los resultados en HBase como pares clave-valor que permiten respuestas de consultas en milisegundos en miles de millones de filas.
- Proporciona una interfaz ANSI SQL y una integración perfecta con herramientas de BI como Tableau, Power BI y Excel mediante API JDBC, ODBC y REST para flujos de trabajo de análisis habituales.
- Gestiona esquemas de estrella y copo de nieve con compatibilidad para compilaciones de cubos incrementales, recuentos distintos aproximados mediante HyperLogLog y técnicas de compresión para optimizar el almacenamiento.
¿Qué es Apache Kylin?
Apache Kylin es un motor de procesamiento analítico en línea (OLAP) distribuido y de código abierto para el análisis interactivo de Big Data. Apache Kylin está diseñado para proporcionar una interfaz SQL y análisis multidimensional (OLAP) en Hadoop/Spark. Además, se integra fácilmente con herramientas de BI a través del controlador ODBC, el controlador JDBC y API de REST. Fue creado por eBay en 2014, se convirtió en un proyecto de nivel superior de Apache Software Foundation solo un año después, en 2015, y ganó el premio a la mejor herramienta de Big Data de código abierto en 2015 y en 2016. Actualmente, miles de empresas en todo el mundo la emplean como su aplicación fundamental de análisis de Big Data. Mientras que otros motores de OLAP tienen dificultades con el volumen de datos, Kylin permite respuesta a consultas en milisegundos. Proporciona una latencia de consulta inferior a un segundo en conjuntos de datos a escala de petabytes. Su asombrosa velocidad se logra preprocesando las diversas combinaciones dimensionales y los agregados de medidas a través de consultas de Hive y rellenando HBase con los resultados. 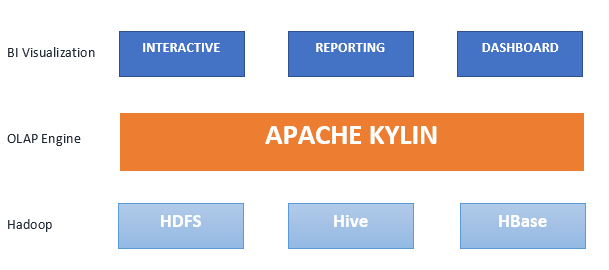
La guía de IA agéntica para la empresa

¿Cómo funciona Apache Kylin?
El motor de consultas de Kylin, al que se puede acceder a través de la interfaz de usuario intuitiva de Kylin, una API o JDBC, aprovecha el procesador de consultas Apache Calcite y las características de HBase para búsquedas rápidas. Kylin se basa en el ecosistema de Hadoop:
- Hive: origen de entrada, esquema de estrella previamente unido durante la creación del cubo
- MapReduce : agregación de métricas durante la creación del cubo
- HDFS: almacena archivos intermedios durante la creación del cubo
- HBase – almacenar y consultar cubos de datos
- Calcite: análisis de SQL, generación de código, optimización ¿Cómo puede Apache Kylin ayudar a tu organización?
- Motor de OLAP muy rápido a escala: Kylin está diseñado para reducir la latencia de consultas en Hadoop para más de 10 000 millones de filas de datos a segundos.
- Interfaz ANSI SQL en Hadoop: Kylin ofrece ANSI SQL en Hadoop y admite la mayoría de las funciones de consulta ANSI SQL. Tanto los analistas como los ingenieros pueden utilizarlo fácilmente, ya que no se requiere programación.
- Integración perfecta con herramientas de BI: Kylin actualmente ofrece capacidad de integración con herramientas de BI como Tableau, JDBC/ODBC/API de REST.
- Capacidad de consulta interactiva: los usuarios pueden interactuar con los datos de Hadoop a través de Kylin con una latencia inferior a un segundo
- Consulta en cubo MOLAP que sirve en miles de millones de filas: los usuarios tienen la capacidad de definir un modelo de datos y precrear en Kylin incluso con más de 10 000 millones de registros de datos sin procesar.
Controlador ODBC de código abierto : el controlador ODBC de Kylin está construido desde cero y funciona muy bien con Tableau.
Recursos adicionales
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.