¿Qué es un sistema de archivos distribuido de Hadoop (HDFS)?
Almacenamiento distribuido que divide archivos en bloques replicados a través de nodos del clúster, proporcionando tolerancia a fallos, capacidad escalable y acceso de alto rendimiento
- El Hadoop Distributed File System (HDFS) es un sistema de almacenamiento que divide los archivos en bloques y los distribuye entre muchas máquinas para escalabilidad y tolerancia a fallos.
- HDFS fue diseñado para almacenar conjuntos de datos muy grandes en clústeres de hardware común y mantener los datos disponibles incluso cuando fallan nodos individuales.
- Aunque muchas organizaciones ahora utilizan almacenamiento de objetos en la nube con arquitecturas lakehouse, comprender HDFS ayuda a explicar la base de los primeros sistemas de big data.
HDFS
HDFS (Hadoop Distributed File System) es el sistema de almacenamiento principal utilizado por las aplicaciones de Hadoop. Este marco de código abierto funciona transfiriendo datos rápidamente entre nodos. Es utilizado a menudo por empresas que necesitan manejar y almacenar big data. HDFS es un componente clave de muchos sistemas Hadoop, ya que proporciona un medio para gestionar big data, además de admitir el análisis de big data.
Hay muchas empresas en todo el mundo que utilizan HDFS, así que, ¿qué es exactamente y por qué es necesario? Profundicemos en qué es HDFS y por qué puede ser útil para las empresas.
¿Qué es HDFS?
HDFS significa Hadoop Distributed File System. HDFS opera como un sistema de archivos distribuido diseñado para ejecutarse en hardware comercial.
HDFS es tolerante a fallos y está diseñado para ser implementado en hardware económico y comercial. HDFS proporciona acceso a datos de alto rendimiento a los datos de las aplicaciones y es adecuado para aplicaciones que tienen grandes conjuntos de datos y permite el acceso en streaming a los datos del sistema de archivos en Apache Hadoop.
Entonces, ¿qué es Hadoop? ¿Y cómo se diferencia de HDFS? Una diferencia fundamental entre Hadoop y HDFS es que Hadoop es el marco de código abierto que puede almacenar, procesar y analizar datos, mientras que HDFS es el sistema de archivos de Hadoop que proporciona acceso a los datos. Esto significa esencialmente que HDFS es un módulo de Hadoop.
Echemos un vistazo a la arquitectura de HDFS:
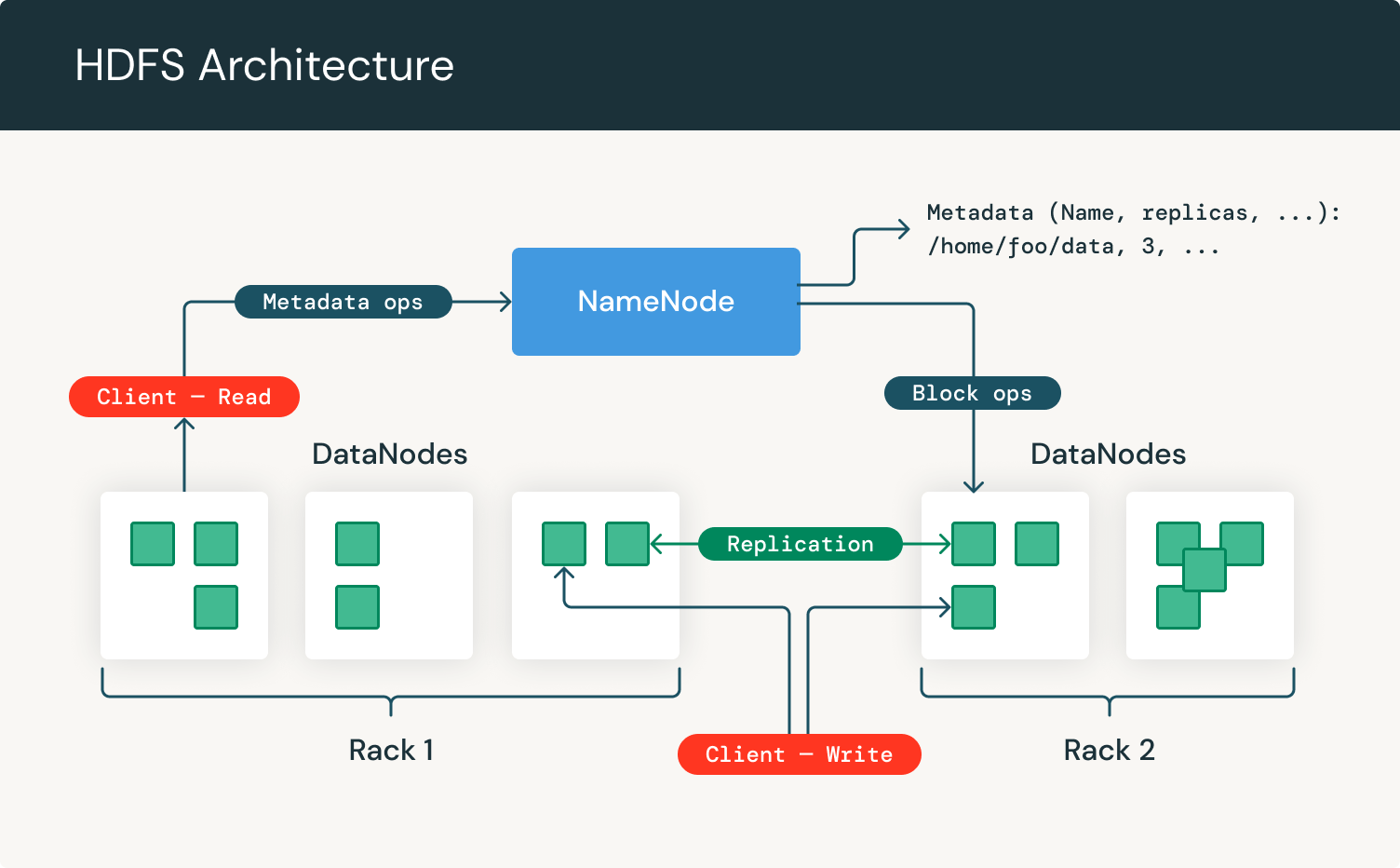
Como podemos ver, se centra en NameNodes y DataNodes. El NameNode es el hardware que contiene el sistema operativo y el software GNU/Linux. El sistema de archivos distribuido de Hadoop actúa como el servidor maestro y puede gestionar los archivos, controlar el acceso de un cliente a los archivos y supervisar los procesos de operación de archivos, como el cambio de nombre, la apertura y el cierre de archivos.
Un DataNode es hardware que tiene el sistema operativo GNU/Linux y el software DataNode. Por cada nodo en un clúster de HDFS, encontrarás un DataNode. Estos nodos ayudan a controlar el almacenamiento de datos de su sistema, ya que pueden realizar operaciones en los sistemas de archivos si el cliente lo solicita, y también crear, replicar y bloquear archivos cuando el NameNode lo indica.
El significado y el propósito de HDFS son lograr los siguientes objetivos:
- Gestionar grandes conjuntos de datos: Organizar y almacenar conjuntos de datos puede ser una tarea difícil de manejar. HDFS se utiliza para gestionar las aplicaciones que tienen que tratar con enormes conjuntos de datos. Para ello, HDFS debe tener cientos de nodos por clúster.
- Detectar fallos: HDFS debe contar con tecnología para escanear y detectar fallos de forma rápida y eficaz, ya que incluye un gran número de hardware comercial. El fallo de componentes es un problema común.
- Eficiencia del hardware: Cuando se trata de grandes conjuntos de datos, puede reducir el tráfico de red y aumentar la velocidad de procesamiento.
La historia de HDFS
¿Cuáles son los orígenes de Hadoop? El diseño de HDFS se basó en el Google File System. Originalmente se construyó como infraestructura para el proyecto del motor de búsqueda web Apache Nutch, pero desde entonces se ha convertido en un miembro del Ecosistema Hadoop.
En los primeros años de Internet, aparecieron rastreadores web como una forma para que las personas buscaran información en páginas web. Esto creó varios motores de búsqueda como Yahoo y Google.
También creó otro motor de búsqueda llamado Nutch, que quería distribuir datos y cálculos en varios ordenadores simultáneamente. Nutch se trasladó a Yahoo y se dividió en dos. Apache Spark y Hadoop son ahora entidades separadas. Mientras que Hadoop está diseñado para el procesamiento por lotes, Spark está hecho para manejar datos en tiempo real de manera eficiente.
Hoy en día, la estructura y el marco de Hadoop son gestionados por la Apache Software Foundation, que es una comunidad global de desarrolladores y colaboradores de software.
HDFS nació de esto y está diseñado para reemplazar las soluciones de almacenamiento de hardware con un método mejor y más eficiente: un sistema de archivos virtual. Cuando apareció por primera vez, MapReduce era el único motor de procesamiento distribuido que podía utilizar HDFS. Más recientemente, componentes alternativos de servicios de datos de Hadoop como HBase y Solr también utilizan HDFS para almacenar datos.
¿Qué es HDFS en el mundo del big data?
Entonces, ¿qué es el big data y cómo entra HDFS en él? El término "big data" se refiere a todos los datos que son difíciles de almacenar, procesar y analizar. El big data de HDFS son datos organizados en el sistema de archivos de HDFS.
Como ya sabemos, Hadoop es un marco que funciona utilizando procesamiento paralelo y almacenamiento distribuido. Esto se puede utilizar para clasificar y almacenar big data, ya que no se puede almacenar de forma tradicional.
De hecho, es el software más utilizado para manejar big data, y es utilizado por empresas como Netflix, Expedia y British Airways, que tienen una relación positiva con Hadoop para el almacenamiento de datos. HDFS en big data es vital, ya que así es como muchas empresas eligen ahora almacenar sus datos.
Hay cinco elementos clave del big data organizados por los servicios de HDFS:
- Velocidad: La rapidez con la que se generan, recopilan y analizan los datos.
- Volumen: La cantidad de datos generados.
- Variedad: El tipo de datos, que pueden ser estructurados, no estructurados, etc.
- Veracidad: La calidad y precisión de los datos.
- Valor: Cómo se pueden utilizar estos datos para obtener información sobre los procesos de su negocio.
Ventajas del Hadoop Distributed File System
Como subproyecto de código abierto dentro de Hadoop, HDFS ofrece cinco beneficios clave al tratar con big data:
- Tolerancia a fallos. HDFS ha sido diseñado para detectar fallos y recuperarse automáticamente rápidamente, garantizando la continuidad y la fiabilidad.
- Velocidad, debido a su arquitectura de clúster, puede mantener 2 GB de datos por segundo.
- Acceso a más tipos de datos, específicamente datos en streaming. Debido a su diseño para manejar grandes cantidades de datos para el procesamiento por lotes, permite altas tasas de rendimiento de datos, lo que lo hace ideal para admitir datos en streaming.
Compatibilidad y portabilidad. HDFS está diseñado para ser portátil en una variedad de configuraciones de hardware y compatible con varios sistemas operativos subyacentes, lo que en última instancia proporciona a los usuarios la opción de utilizar HDFS con su propia configuración personalizada. Estas ventajas son especialmente significativas cuando se trata de big data y se hicieron posibles con la forma particular en que HDFS maneja los datos.
Este gráfico demuestra la diferencia entre un sistema de archivos local y HDFS.
- Escalable. Puede escalar recursos según el tamaño de su sistema de archivos. HDFS incluye mecanismos de escalabilidad vertical y horizontal.
- Localidad de datos. Cuando se trata del sistema de archivos de Hadoop, los datos residen en los nodos de datos, en lugar de que los datos se muevan a donde está la unidad computacional. Al acortar la distancia entre los datos y el proceso de computación, se reduce la congestión de la red y se hace que el sistema sea más efectivo y eficiente.
- Rentable. Inicialmente, cuando pensamos en datos, podemos pensar en hardware caro y ancho de banda saturado. Cuando se produce un fallo de hardware, puede ser muy costoso de reparar. Con HDFS, los datos se almacenan de forma económica ya que es virtual, lo que puede reducir drásticamente los costos de almacenamiento de metadatos del sistema de archivos y datos del espacio de nombres del sistema de archivos. Además, como HDFS es de código abierto, las empresas no tienen que preocuparse por pagar una tarifa de licencia.
- Almacena grandes cantidades de datos. El almacenamiento de datos es de lo que trata HDFS, lo que significa datos de todas las variedades y tamaños, pero particularmente grandes cantidades de datos de corporaciones que luchan por almacenarlos. Esto incluye datos estructurados y no estructurados.
- Flexible. A diferencia de algunas otras bases de datos de almacenamiento más tradicionales, no es necesario procesar los datos recopilados antes de almacenarlos. Puede almacenar tantos datos como desee, con la oportunidad de decidir exactamente qué desea hacer con ellos y cómo utilizarlos más adelante. Esto también incluye datos no estructurados como texto, vídeos e imágenes.
Cómo usar HDFS
Entonces, ¿cómo se usa HDFS? Bueno, HDFS funciona con un NameNode principal y varios otros datanodes, todos en un clúster de hardware comercial. Estos nodos están organizados en el mismo lugar dentro del centro de datos. A continuación, se divide en bloques que se distribuyen entre los múltiples DataNodes para su almacenamiento. Para reducir las posibilidades de pérdida de datos, los bloques se replican a menudo entre nodos. Es un sistema de copia de seguridad en caso de que se pierdan datos.
Veamos los NameNodes. El NameNode es el nodo dentro del clúster que sabe qué contiene el dato, a qué bloque pertenece, el tamaño del bloque y a dónde debe ir. Los NameNodes también se utilizan para controlar el acceso a los archivos, incluido cuándo alguien puede escribir, leer, crear, eliminar y replicar datos en los diversos nodos de datos.
El clúster también se puede adaptar según sea necesario en tiempo real, dependiendo de la capacidad del servidor, lo que puede ser útil cuando hay un aumento en los datos. Se pueden agregar o quitar nodos según sea necesario.
Ahora, pasemos a los DataNodes. Los DataNodes están en comunicación constante con los NameNodes para identificar si necesitan iniciar y completar una tarea. Este flujo de colaboración constante significa que el NameNode es muy consciente del estado de cada DataNode.
Cuando se detecta que un DataNode no está funcionando como debería, el NameNode puede reasignar automáticamente esa tarea a otro nodo que funcione en el mismo datablock. De manera similar, los DataNodes también pueden comunicarse entre sí, lo que significa que pueden colaborar durante las operaciones de archivo estándar. Dado que el NameNode conoce los DataNodes y su rendimiento, son cruciales para mantener el sistema.
Los Datablocks se replican en varios nodos de datos y son accedidos por el NameNode.
Para usar HDFS, necesitas instalar y configurar un clúster de Hadoop. Este puede ser una configuración de un solo nodo, que es más apropiada para usuarios principiantes, o una configuración de clúster para clústeres grandes y distribuidos. Luego, debes familiarizarte con los comandos de HDFS, como los siguientes, para operar y administrar tu sistema.
| Comando | Descripción |
| -rm | Elimina archivo o directorio |
| -ls | Lista archivos con permisos y otros detalles |
| -mkdir | Crea un directorio llamado path en HDFS |
| -cat | Muestra el contenido del archivo |
| -rmdir | Elimina un directorio |
| -put | Sube un archivo o carpeta desde un disco local a HDFS |
| -rmr | Elimina el archivo identificado por path o la carpeta y subcarpetas |
| -get | Mueve un archivo o carpeta de HDFS a un archivo local |
| -count | Cuenta el número de archivos, el número de directorios y el tamaño del archivo |
| -df | Muestra el espacio libre |
| -getmerge | Fusiona varios archivos en HDFS |
| -chmod | Cambia los permisos del archivo |
| -copyToLocal | Copia archivos al sistema local |
| -Stat | Imprime estadísticas sobre el archivo o directorio |
| -head | Muestra el primer kilobyte de un archivo |
| -usage | Devuelve la ayuda para un comando individual |
| -chown | Asigna un nuevo propietario y grupo a un archivo |
¿Cómo funciona HDFS?
Como se mencionó anteriormente, HDFS utiliza NameNodes y DataNodes. HDFS permite la transferencia rápida de datos entre nodos de cómputo. Cuando HDFS ingiere datos, puede dividir la información en bloques, distribuyéndolos a diferentes nodos en un clúster.
Los datos se dividen en bloques y se distribuyen entre los DataNodes para su almacenamiento; estos bloques también se pueden replicar entre nodos, lo que permite un procesamiento paralelo eficiente. Puedes acceder, moverte y ver datos a través de varios comandos. Las opciones de HDFS DFS como "-get" y "-put" te permiten recuperar y mover datos según sea necesario.
Además, HDFS está diseñado para estar muy alerta y puede detectar fallos rápidamente. El sistema de archivos utiliza la replicación de datos para garantizar que cada pieza de datos se guarde varias veces y luego la asigna a nodos individuales, asegurando que al menos una copia esté en un rack diferente al de las otras copias.
Esto significa que cuando un DataNode deja de enviar señales al NameNode, este elimina el DataNode del clúster y opera sin él. Si este nodo de datos regresa, se le puede asignar un nuevo clúster. Además, dado que los datablocks se replican en varios DataNodes, eliminar uno no provocará ninguna corrupción de archivo de ningún tipo.
Componentes de HDFS
Es importante saber que hay tres componentes principales de Hadoop. Hadoop HDFS, Hadoop MapReduce y Hadoop YARN. Veamos qué aportan estos componentes a Hadoop:
- Hadoop HDFS - Hadoop Distributed File System (HDFS) es la unidad de almacenamiento de Hadoop.
- Hadoop MapReduce - Hadoop MapReduce es la unidad de procesamiento de Hadoop. Este framework de software se utiliza para escribir aplicaciones que procesan grandes cantidades de datos.
- Hadoop YARN - Hadoop YARN es un componente de gestión de recursos de Hadoop. Procesa y ejecuta datos para procesamiento por lotes, en flujo, interactivo y gráfico, todo lo cual se almacena en HDFS.
Cómo crear un sistema de archivos HDFS
¿Quieres saber cómo crear un sistema de archivos HDFS? Sigue los pasos a continuación que te guiarán sobre cómo crear el sistema, editarlo y eliminarlo si es necesario.
Listando tu HDFS
Tu listado de HDFS debería ser /user/tuNombreDeUsuario. Para ver el contenido de tu directorio principal de HDFS, introduce:
Como estás empezando, no podrás ver nada en esta etapa. Cuando quieras ver el contenido de un directorio no vacío, introduce:
Luego podrás ver los nombres de los directorios principales de todos los demás usuarios de Hadoop.
Creando un directorio en HDFS
Ahora puedes crear un directorio de prueba, llamémoslo testHDFS. Aparecerá dentro de tu HDFS. Simplemente introduce lo siguiente:
Ahora debes verificar que el directorio existe usando el comando que introdujiste al listar tu HDFS. Deberías ver el directorio testHDFS listado.
Verifícalo de nuevo usando la ruta completa de HDFS a tu HDFS. Introduce:
Verifica que esto funciona antes de dar los siguientes pasos.
Copiando un archivo
Para copiar un archivo desde tu sistema de archivos local a HDFS, comienza creando un archivo que deseas copiar. Para hacer esto, introduce:
Eso creará un nuevo archivo llamado testFile, que incluye los caracteres HDFS test file. Para verificar esto, introduce:
ls
Y luego, para verificar que el archivo se creó, introduce:
Luego necesitarás copiar el archivo a HDFS. Para copiar archivos de Linux a HDFS, necesitas usar:
Observa que tienes que usar el comando "-copyFromLocal" porque el comando "-cp" se usa para copiar archivos dentro de HDFS.
Ahora solo necesitas confirmar que el archivo se ha copiado correctamente. Haz esto introduciendo lo siguiente:
Moviendo y copiando archivos
Al copiar el testfile, se colocó en el directorio principal base. Ahora puedes moverlo al directorio testHDFS que ya creaste. Usa lo siguiente:
La primera parte movió tu testFile desde el directorio principal de HDFS al directorio de prueba que creaste. La segunda parte de este comando nos muestra que ya no está en el directorio principal de HDFS, y la tercera parte confirma que ahora se ha movido al directorio HDFS de prueba.
Para copiar un archivo, introduce:
Comprobando el uso del disco
Comprobar el espacio en disco es útil cuando usas HDFS. Para hacer esto, puedes introducir el siguiente comando:
Esto te permitirá ver cuánto espacio estás usando en tu HDFS. También puedes ver cuánto espacio está disponible en HDFS en todo el clúster introduciendo:
Eliminando un archivo/directorio
Puede llegar un momento en que necesites eliminar un archivo o directorio en HDFS. Esto se puede lograr con el comando:
Verás que todavía tienes el directorio testHDFS y testFile2 que creaste. Elimina el directorio introduciendo:
Aparecerá un mensaje de error, pero no te asustes. Dirá algo como "rmdir: testhdfs: Directory is not empty". El directorio debe estar vacío antes de poder eliminarlo. Puedes usar el comando "rm" para omitir esto y eliminar un directorio, incluidos todos los archivos que contiene. Introduce:
La guía de IA agéntica para la empresa

Cómo instalar HDFS
Para instalar Hadoop, debes recordar que existe una configuración de un solo nodo y de varios nodos. Dependiendo de lo que necesites, puedes usar un clúster de un solo nodo o de varios nodos.
Un clúster de un solo nodo significa que solo se está ejecutando un DataNode. Incluirá el NameNode, DataNode, el gestor de recursos y el gestor de nodos en una sola máquina.
Para algunas industrias, esto es todo lo que se necesita. Por ejemplo, en el campo de la medicina, si estás realizando estudios y necesitas recopilar, clasificar y procesar datos en secuencia, puedes usar un clúster de un solo nodo. Este puede manejar fácilmente los datos a menor escala, en comparación con datos distribuidos en cientos de máquinas. Para instalar un clúster de un solo nodo, sigue estos pasos:
- Descarga el Paquete Java 8. Guarda este archivo en tu directorio de inicio.
- Extrae el Archivo Tar de Java.
- Descarga el Paquete Hadoop 2.7.3.
- Extrae el Archivo Tar de Hadoop.
- Agrega las rutas de Hadoop y Java en el archivo bash (.bashrc).
- Edita los archivos de configuración de Hadoop.
- Abre core-site.xml y edita la propiedad.
- Edita hdfs-site.xml y edita la propiedad.
- Edita el archivo mapred-site.xml y edita la propiedad.
- Edita yarn-site.xml y edita la propiedad.
- Edita hadoop-env.sh y agrega la ruta de Java.
- Ve al directorio de inicio de Hadoop y formatea el NameNode.
- Ve al directorio hadoop-2.7.3/sbin y inicia todos los daemons.
- Verifica que todos los servicios de Hadoop estén en funcionamiento.
Y listo, ahora deberías tener un HDFS instalado correctamente.
Cómo acceder a los archivos de HDFS
No sorprende que la seguridad sea estricta cuando se trata de HDFS, dado que estamos lidiando con datos. Como HDFS es técnicamente almacenamiento virtual, se extiende por todo el clúster, por lo que solo puedes ver los metadatos en tu sistema de archivos, no podrás ver los datos específicos reales.
Para acceder a los archivos de HDFS, puedes descargar el archivo "jar" de HDFS a tu sistema de archivos local. También puedes acceder a HDFS usando su interfaz de usuario web. Simplemente abre tu navegador y escribe "localhost:50070" en la barra de búsqueda. Desde allí, puedes ver la interfaz de usuario web de HDFS y moverte a la pestaña de utilidades en el lado derecho. Luego haz clic en "browse file system", esto te mostrará una lista completa de los archivos ubicados en tu HDFS.
Ejemplos de HDFS DFS
Aqu�í tienes algunos de los ejemplos de comandos de Hadoop más comunes.
Ejemplo A
Para eliminar un directorio, necesitas aplicar lo siguiente (nota: esto solo se puede hacer si los archivos están vacíos):
O
Ejemplo B
Cuando tienes varios archivos en un HDFS, puedes usar un comando "-getmerge". Esto fusionará varios archivos en un solo archivo, que luego puedes descargar a tu sistema de archivos local. Puedes hacer esto con lo siguiente:
O
Ejemplo C
Cuando quieras subir un archivo de HDFS a local, puedes usar el comando "-put". Especificas desde dónde quieres copiar y qué archivo quieres copiar en HDFS. Usa lo siguiente:
O
Ejemplo D
El comando count se usa para rastrear el número de directorios, archivos y el tamaño de los archivos en HDFS. Puedes usar lo siguiente:
O
Ejemplo E
El comando "chown" se puede usar para cambiar el propietario y el grupo de un archivo. Para activarlo, usa lo siguiente:
O
¿Qué es el almacenamiento HDFS?
Como ya sabemos, los datos de HDFS se almacenan en algo llamado bloques. Estos bloques son la unidad de datos más pequeña que el sistema de archivos puede almacenar. Los archivos se procesan y se dividen en estos bloques, que luego se distribuyen por el clúster y también se replican por seguridad. Típicamente, cada bloque puede ser replicado tres veces. Este diagrama muestra big data y cómo puede ser almacenado con HDFS.
El primero lo encuentras en el DataNode, el segundo se almacena en un DataNode separado dentro del clúster, y un tercero se almacena en un DataNode en un clúster diferente. Esto es como un paso de seguridad de triple protección. Así, si lo peor sucede y una réplica falla, los datos no se pierden para siempre.
El NameNode mantiene información importante, como el número de bloques y dónde se almacenan las réplicas. En comparación, un DataNode almacena los datos reales y puede crear bloques, eliminar bloques y replicar bloques por comando. Se ve así:
Esto determina dónde deben almacenar sus bloques los DataNodes.
¿Cómo almacena datos HDFS?
El sistema de archivos HDFS consta de un conjunto de servicios maestros (NameNode, secondary NameNode y DataNodes). El NameNode y el secondary NameNode administran los metadatos de HDFS. Los DataNodes alojan los datos subyacentes de HDFS.
El NameNode rastrea qué DataNodes contienen el contenido de un archivo dado en HDFS. HDFS divide los archivos en bloques y almacena cada bloque en un DataNode. Múltiples DataNodes están vinculados al clúster. El NameNode luego distribuye réplicas de estos bloques de datos por todo el clúster. También indica al usuario o aplicación dónde localizar la información deseada.
¿Para qué está diseñado el sistema de archivos distribuido de Hadoop (HDFS)?
En pocas palabras, al preguntar "¿para qué está diseñado el sistema de archivos distribuido de Hadoop?", la respuesta es, ante todo, el big data. Esto puede ser invaluable para grandes corporaciones que de otro modo tendrían dificultades para administrar y almacenar datos de sus negocios y clientes.
Con Hadoop, puedes almacenar y unificar datos, ya sean transaccionales, científicos, de redes sociales, publicitarios y de machine learning. También significa que puedes volver a estos datos y obtener información valiosa sobre el rendimiento empresarial y el análisis.
Como fue diseñado para almacenar datos, HDFS también puede manejar datos brutos que son comúnmente utilizados por científicos o personas en el campo de la medicina que buscan analizar dichos datos. Estos se llaman data lakes. Les permite abordar preguntas más difíciles sin restricciones.
Además, como Hadoop fue diseñado principalmente para manejar enormes volúmenes de datos de diversas maneras, también se puede usar para ejecutar algoritmos con fines analíticos. Esto significa que ayuda a las empresas a procesar y analizar datos de manera más eficiente, permitiéndoles descubrir nuevas tendencias y anomalías. Algunos conjuntos de datos incluso se están eliminando de los data warehouses y se están moviendo a Hadoop. Simplemente hace que sea más fácil almacenar todo en un lugar de fácil acceso.
Cuando se trata de datos transaccionales, Hadoop también está equipado para manejar millones de transacciones. Gracias a sus capacidades de almacenamiento y procesamiento, se puede utilizar para almacenar y analizar datos de clientes. También puedes profundizar en los datos para descubrir tendencias y patrones emergentes que ayuden con los objetivos comerciales. No olvides que Hadoop se actualiza constantemente con datos nuevos, y puedes comparar datos nuevos y antiguos para ver qué ha cambiado y por qué.
Consideraciones con HDFS
Por defecto, HDFS está configurado con replicación 3x, lo que significa que los conjuntos de datos tendrán dos copias adicionales. Si bien esto mejora la probabilidad de datos localizados durante el procesamiento, introduce costos de almacenamiento adicionales.
- HDFS funciona mejor cuando se configura con almacenamiento conectado localmente. Esto garantiza el mejor rendimiento para el sistema de archivos.
- Aumentar la capacidad de HDFS requiere la adición de nuevos servidores (cómputo, memoria, disco), no solo medios de almacenamiento.
HDFS vs. Almacenamiento de Objetos en la Nube
Como se mencionó anteriormente, la capacidad de HDFS está estrechamente ligada a los recursos de cómputo. Aumentar la capacidad de almacenamiento implica aumentar los recursos de CPU, incluso si esto último no es necesario. Al agregar más nodos de datos a HDFS, se requiere una operación de reequilibrio para distribuir los datos existentes a los servidores recién agregados.
Esta operación puede llevar algún tiempo. Escalar un clúster de Hadoop en un entorno local también puede ser difícil desde el punto de vista del costo y el espacio. HDFS utiliza almacenamiento conectado localmente, lo que puede proporcionar beneficios de rendimiento de IO, asumiendo que YARN puede aprovisionar el procesamiento en los servidores que almacenan los datos a procesar.
En entornos muy utilizados, es posible que la mayoría de las operaciones de lectura/escritura de datos se realicen a través de la red en lugar de localmente. El almacenamiento de objetos en la nube incluye tecnologías como Azure Data Lake Storage, AWS S3 o Google Cloud Storage. Es independiente de los recursos de cómputo que acceden a él y, por lo tanto, los clientes pueden almacenar mucha más cantidad de datos en la nube.
Los clientes que buscan almacenar Petabytes de datos pueden hacerlo fácilmente en el almacenamiento de objetos en la nube. Sin embargo, todas las operaciones de lectura y escritura contra el almacenamiento en la nube se realizarán a través de la red. Por lo tanto, es importante que las aplicaciones que accedan a sus datos aprovechen el almacenamiento en caché siempre que sea posible o incluyan lógica para minimizar las operaciones de E/S.
Recursos Adicionales
- Guía de migración de Hadoop a Lakehouse
- Centro de migración
- Ebook de modernización en la nube: Una guía empresarial sobre el valor oculto de la migración desde Hadoop
- Demos rápidas bajo demanda de la plataforma Databricks Lakehouse
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.