¿Qué es el ecosistema Hadoop?
Un conjunto completo de herramientas de código abierto que incluye HDFS, MapReduce, YARN, Hive y Spark que trabajan juntas para almacenar, procesar y analizar conjuntos de datos masivos.
- HDFS proporciona almacenamiento distribuido con tolerancia a fallos mediante la arquitectura NameNode y DataNode, mientras que YARN gestiona los recursos del clúster y MapReduce gestiona el procesamiento de datos en paralelo.
- Apache Hive ofrece consultas similares a SQL a través de HiveQL para operaciones de almacenamiento de datos, y Apache Spark proporciona procesamiento en memoria para análisis en tiempo real y aprendizaje automático.
- El ecosistema incluye herramientas complementarias como Pig para scripting, HBase para almacenamiento NoSQL, Oozie para la programación de flujos de trabajo y Sqoop para la transferencia de datos entre Hadoop y bases de datos relacionales.

¿Qué es el Ecosistema de Hadoop?
El ecosistema de Apache Hadoop hace referencia a los diversos componentes de la biblioteca de software Apache Hadoop; incluye proyectos de código abierto, así como una gama completa de herramientas complementarias. Algunas de las herramientas más conocidas del ecosistema de Hadoop son HDFS, Hive, Pig, YARN, MapReduce, Spark, HBase, Oozie, Sqoop, Zookeeper, etc. Estos son los principales componentes del ecosistema de Hadoop que usan con frecuencia los desarrolladores:
¿Qué es HDFS?
Hadoop Distributed File System (HDFS) es uno de los proyectos más grandes de Apache y el sistema de almacenamiento principal de Hadoop. Usa una arquitectura de NameNode y DataNode. Es un sistema de archivos distribuido capaz de almacenar archivos grandes que se ejecuta en un clúster de hardware común.
¿Qué es Hive?
Hive es una herramienta de ETL y almacenamiento de datos que se usa para consultar o analizar grandes conjuntos de datos almacenados dentro del ecosistema de Hadoop. Hive tiene tres funciones principales: resumen de datos, consulta y análisis de datos no estructurados y semiestructurados en Hadoop. Cuenta con una interfaz similar a SQL, un lenguaje HQL que funciona de forma similar a SQL y traduce automáticamente las consultas en tareas de MapReduce.
¿Qué es Apache Pig?
Se trata de un lenguaje de scripting de alto nivel que se usa para ejecutar consultas en conjuntos de datos más grandes que se usan en Hadoop. El sencillo lenguaje de scripting de Pig, similar a SQL, se conoce como Pig Latin y su principal objetivo es realizar las operaciones necesarias y organizar el resultado final en el formato deseado.
La guía de IA agéntica para la empresa

¿Qué es MapReduce?

Esta es otra capa de procesamiento de datos de Hadoop. Tiene la capacidad de procesar grandes volúmenes de datos estructurados y no estructurados, así como de gestionar archivos de datos muy grandes en paralelo, ya que divide el trabajo en un conjunto de tareas independientes (subtareas).
¿Qué es YARN?
YARN significa Yet Another Resource Negotiator (Otro negociador de recursos más), pero se le suele conocer solo por el acrónimo. Es uno de los componentes principales de Apache Hadoop de código abierto, adecuado para la gestión de recursos. Es responsable de gestionar las cargas de trabajo, monitorear e implementar controles de seguridad. También asigna recursos del sistema a las diversas aplicaciones que se ejecutan en un clúster de Hadoop, asignando las tareas que debe ejecutar cada nodo del clúster. YARN tiene dos componentes principales:
- Administrador de recursos
- Administrador de nodos
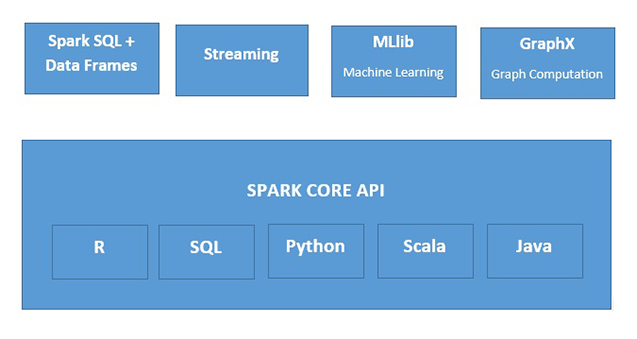
¿Qué es Apache Spark?
Apache Spark es un motor rápido de procesamiento de datos en memoria, adecuado para su uso en una amplia variedad de circunstancias. Spark se puede implementar de varias maneras, cuenta con los lenguajes de programación Java, Python, Scala y R, y es compatible con SQL, datos de transmisión, aprendizaje automático y procesamiento de gráficos, que se pueden usar conjuntamente en una aplicación.
Recursos adicionales
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.