Apache Spark y Hadoop: Trabajando juntos
por Ion Stoica
A menudo nos preguntan cómo Apache Spark encaja en el ecosistema de Hadoop y cómo se puede ejecutar Spark en un clúster de Hadoop existente. Este blog busca responder estas preguntas.
Primero, Spark está diseñado para mejorar, no para reemplazar, el stack de Hadoop. Desde el primer día, Spark fue diseñado para leer y escribir datos desde y hacia HDFS, así como en otros sistemas de almacenamiento, como HBase y S3 de Amazon. Como tal, los usuarios de Hadoop pueden enriquecer sus capacidades de procesamiento combinando Spark con Hadoop MapReduce, HBase y otros frameworks de big data.
En segundo lugar, nos hemos centrado constantemente en que sea lo más fácil posible para que todos los usuarios de Hadoop aprovechen las capacidades de Spark. No importa si ejecutas Hadoop 1.x o Hadoop 2.0 (YARN), y no importa si tienes privilegios administrativos para configurar el clúster de Hadoop o no, ¡hay una forma de que puedas ejecutar Spark! En particular, existen tres formas de implementar Spark en un clúster de Hadoop: independiente, YARN y SIMR.
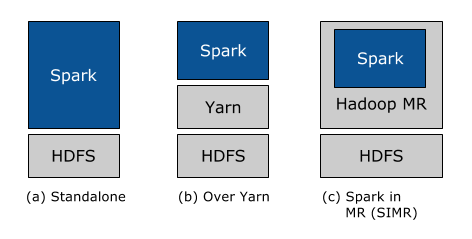
Implementación independiente: con la implementación independiente, se pueden asignar recursos de forma estática en todas las máquinas o en un subconjunto de ellas en un clúster de Hadoop y ejecutar Spark en paralelo con Hadoop MR. El usuario puede entonces ejecutar trabajos de Spark arbitrarios en sus datos de HDFS. Su simplicidad hace que esta sea la implementación preferida para muchos usuarios de Hadoop 1.x.
Implementaciónde Hadoop Yarn: los usuarios de Hadoop que ya implementaron o planean implementar Hadoop Yarn pueden simplemente ejecutar Spark en YARN sin necesidad de preinstalación ni de acceso administrativo. Esto permite a los usuarios integrar fácilmente Spark en su pila de Hadoop y aprovechar toda la potencia de Spark, así como de otros componentes que se ejecutan sobre Spark.
Spark In MapReduce (SIMR): Para los usuarios de Hadoop que aún no ejecutan YARN, otra opción, además del despliegue autónomo, es usar SIMR para lanzar trabajos de Spark dentro de MapReduce. ¡Con SIMR, los usuarios pueden empezar a experimentar con Spark y usar su shell a los pocos minutos de descargarlo! Esto reduce enormemente la barrera de la implementación y permite que prácticamente todo el mundo experimente con Spark.
Interoperabilidad con otros sistemas
Spark no solo interopera con Hadoop, sino también con otras tecnologías populares de big data.
- Apache Hive: a través de Shark, Spark permite a los usuarios de Apache Hive ejecutar sus consultas sin modificar mucho más rápido. Hive es una popular solución de almacén de datos que se ejecuta sobre Hadoop, mientras que Shark es un sistema que permite que el framework de Hive se ejecute sobre Spark en lugar de Hadoop. Como resultado, Shark puede acelerar las consultas de Hive hasta 100 veces cuando los datos de entrada caben en la memoria, y hasta 10 veces cuando los datos de entrada se almacenan en el disco.
- AWS EC2: Los usuarios pueden ejecutar fácilmente Spark (y Shark) sobre EC2 de Amazon, ya sea usando los scripts que vienen con Spark o las versiones alojadas de Spark y Shark en Elastic MapReduce de Amazon.
- Apache Mesos: Spark se ejecuta sobre Mesos, un sistema de gestión de clústeres que proporciona un aislamiento de recursos eficiente entre aplicaciones distribuidas, incluyendo MPI y Hadoop. Mesos permite el uso compartido detallado, lo que posibilita que una tarea de Spark aproveche dinámicamente los recursos inactivos en el clúster durante su ejecución. Esto conduce a mejoras considerables en el rendimiento, especialmente para las tareas de Spark de larga duración.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.