Implementação de uma rede neural convolucional para classificação de carros
por Dr. Evan Eames e Henning Kropp
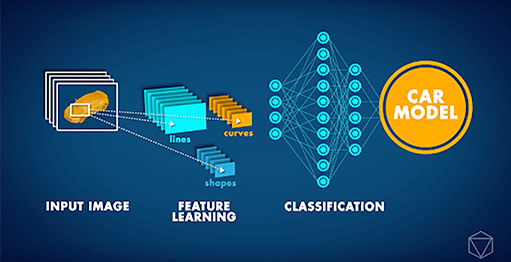
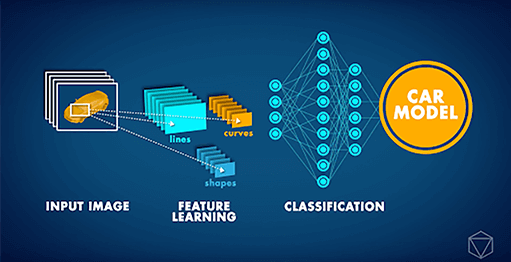
Redes Neurais Convolucionais (CNN) são arquiteturas de Redes Neurais de última geração usadas principalmente para tarefas de visão computacional. As CNNs podem ser aplicadas a várias tarefas diferentes, como reconhecimento de imagem, localização de objetos e detecção de mudanças. Recentemente, nosso parceiro Data Insights recebeu uma solicitação desafiadora de uma grande empresa automobilística: desenvolver um aplicativo de Visão Computacional que pudesse identificar o modelo do carro em uma determinada imagem. Considerando que modelos de carros diferentes podem parecer bastante semelhantes e que qualquer carro pode parecer muito diferente dependendo do ambiente ao redor e do ângulo em que é fotografado, tal tarefa era, até bem pouco tempo, simplesmente impossível.

No entanto, a partir de 2012, a ‘Revolução da aprendizagem profunda’ tornou possível lidar com esse tipo de problema. Em vez de lhes ser explicado o conceito de um carro, os computadores poderiam estudar imagens repetidamente e aprender esses conceitos por conta própria. Nos últimos anos, inovações adicionais em redes neurais artificiais resultaram em uma AI que pode executar tarefas de classificação de imagens com precisão de nível humano. Com base nesses desenvolvimentos, conseguimos ensinar uma Deep CNN para classificar carros por seu modelo. A Rede Neural foi treinada no Stanford Cars Dataset, que contém mais de 16.000 imagens de carros, compreendendo 196 modelos diferentes. Com o tempo, pudemos ver que a precisão das previsões começou a melhorar, à medida que a rede neural aprendia o conceito de um carro e como distinguir entre diferentes modelos.
{kind=link}
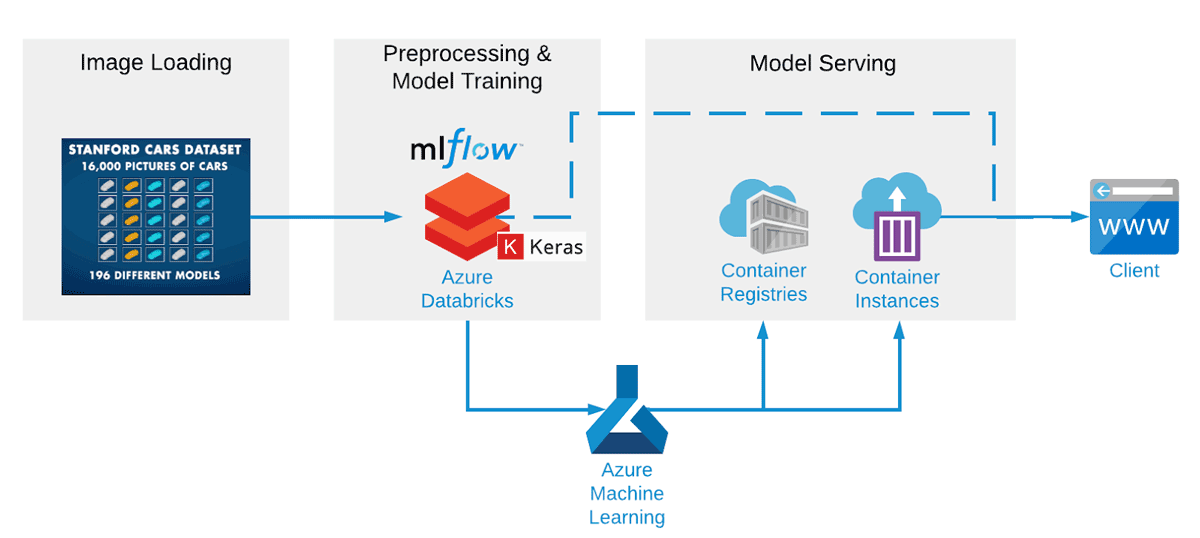
Juntamente com nosso parceiro, construímos um pipeline de machine learning de ponta a ponta usando Apache Spark™ e Koalas para o pré-processamento de dados, Keras com Tensorflow para o treinamento do modelo, MLflow para o acompanhamento de modelos e resultados e Azure ML para a implantação de um serviço REST. Esta configuração no Azure Databricks é otimizada para treinar redes de forma rápida e eficiente e também ajuda a testar muitas configurações de CNN diferentes com muito mais rapidez. Mesmo após apenas algumas tentativas de prática, a precisão da CNN atingiu cerca de 85%.
Configurando uma Rede Neural Artificial para Classificar Imagens
Neste artigo, descrevemos algumas das principais técnicas usadas para colocar uma Rede Neural em produção. Se você quiser tentar executar a Rede Neural por conta própria, os notebooks completos com um guia passo a passo detalhado podem ser encontrados abaixo.
Esta demonstração usa o Stanford Cars Dataset, disponível publicamente, que é um dos datasets públicos mais abrangentes, embora um pouco desatualizado. Por isso, você não encontrará modelos de carros posteriores a 2012 (embora, depois de treinado, o aprendizado por transferência possa facilmente permitir a substituição por um novo dataset). Os dados são fornecidos por meio de uma conta de armazenamento do ADLS Gen2 que você pode montar no seu workspace.

Para o primeiro passo do pré-processamento de dados, as imagens são compactadas em arquivos hdf5 (um para treinamento e outro para teste). Isso pode, então, ser lido pela rede neural. Este passo pode ser totalmente omitido, se desejar, pois os arquivos hdf5 fazem parte do armazenamento ADLS Gen2 fornecido como parte dos Notebooks aqui disponibilizados.
- Carregar o dataset Stanford Cars em arquivos HDF5
- Use o Koalas para aumentação de imagem
- Treine a CNN com o Keras
- Implantar modelo como serviço REST no Azure ML
Aumento de imagem com Koalas
A quantidade e a diversidade dos dados coletados têm um grande impacto nos resultados que se pode alcançar com modelos de aprendizagem profunda. O aumento de dados é uma estratégia que pode melhorar significativamente os resultados de aprendizagem sem a necessidade de coletar novos dados. Com diferentes técnicas, como recorte, preenchimento e inversão horizontal, que são comumente usadas para treinar grandes redes neurais, os conjuntos de dados podem ser artificialmente inflados, aumentando o número de imagens para treinamento e teste.
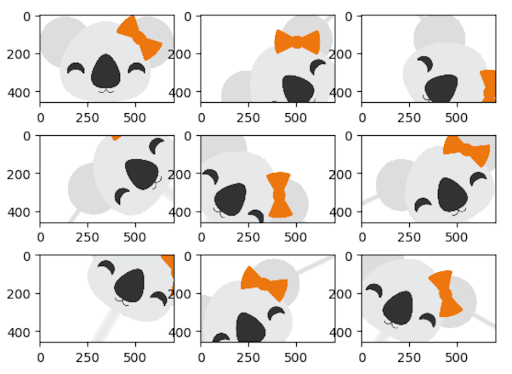
Aplicar aumento a um grande corpus de dados de treinamento pode ser muito caro, especialmente ao comparar os resultados de diferentes abordagens. Com o Koalas, torna-se fácil experimentar frameworks existentes para aumento de imagem em Python e escalar o processo em um cluster com vários nós usando a API do Pandas, familiar à ciência de dados.
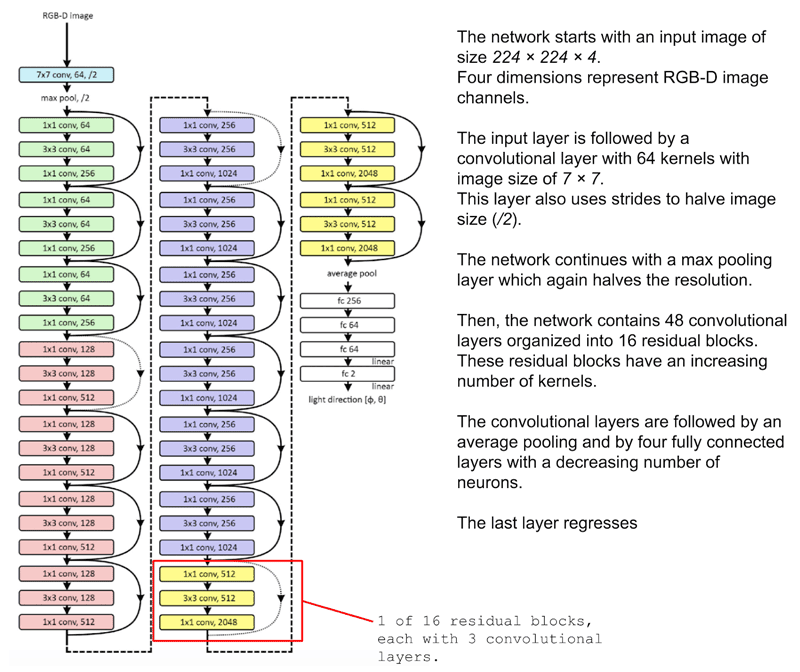
Codificando uma ResNet no Keras
Quando você decompõe uma CNN, ela é composta por diferentes 'blocos', em que cada bloco simplesmente representa um grupo de operações a serem aplicadas a alguns dados de entrada. Estes blocos podem ser amplamente categorizados em:
- Bloco de Identidade: uma série de operações que mantêm a mesma forma dos dados.
- Bloco de convolução: uma série de operações que reduzem o formato dos dados de entrada para um formato menor.
Uma CNN é uma série de Blocos de Identidade e Blocos de Convolução (ou ConvBlocks) que reduzem uma imagem de entrada a um grupo compacto de números. Cada um desses números resultantes (se treinado corretamente) deve, com o tempo, informar algo útil para classificar a imagem. Uma CNN Residual adiciona um passo a mais para cada bloco. Os dados são salvos como uma variável temporária antes da aplicação das operações que constituem o bloco e, em seguida, esses dados temporários são adicionados aos dados de saída. Geralmente, esse passo adicional é aplicado a cada bloco. Como exemplo, a figura abaixo demonstra uma CNN simplificada para detectar números manuscritos:
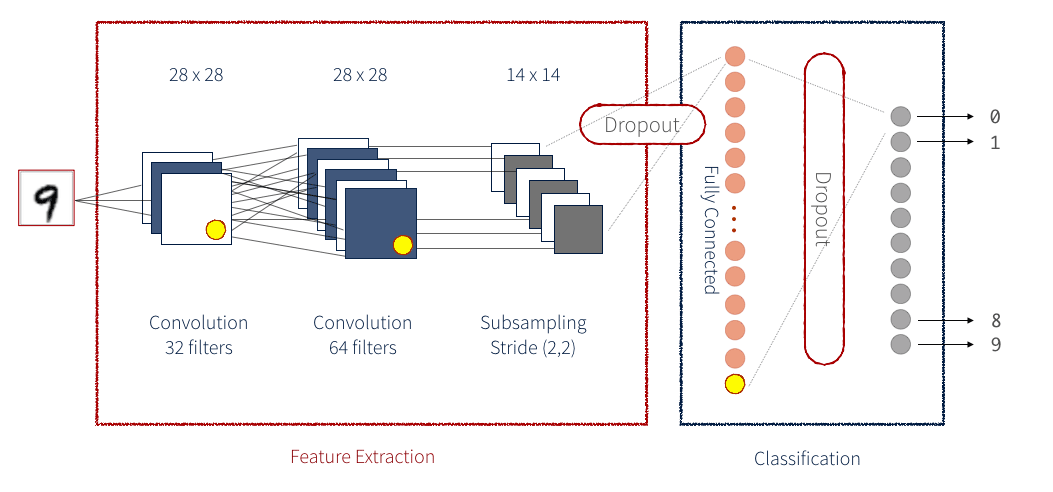
Existem muitos métodos diferentes para implementar uma Rede Neural. Uma das maneiras mais intuitivas é por meio do Keras. O Keras oferece uma biblioteca de front-end simples para executar os passos individuais que compõem uma rede neural. O Keras pode ser configurado para funcionar com um back-end do Tensorflow ou um back-end do Theano. Aqui, usaremos um back-end do Tensorflow. Uma rede Keras é dividida em várias camadas, como visto abaixo. Para nossa rede, também estamos definindo nossa implementação personalizada de uma camada.
A Camada de Escala
Para qualquer operação personalizada que tenha pesos treináveis, o Keras permite que você implemente sua própria camada. Ao lidar com grandes volumes de dados de imagem, podem ocorrer problemas de memória. Inicialmente, as imagens RGB contêm dados inteiros (0-255). Ao executar a descida de gradiente como parte da otimização durante a retropropagação, percebe-se que os gradientes inteiros não oferecem precisão suficiente para ajustar adequadamente os pesos da rede. Portanto, é necessário mudar para a precisão de ponto flutuante. É aqui que os problemas podem surgir. Mesmo quando as imagens são redimensionadas para 224x224x3, ao usarmos dez mil imagens de treinamento, estamos lidando com mais de 1 bilhão de entradas de ponto flutuante. Em vez de converter um dataset inteiro para a precisão de ponto flutuante, a melhor prática é usar uma 'camada de escala', que dimensiona os dados de entrada uma imagem de cada vez e somente quando necessário. Isso deve ser aplicado após a lotes Normalization no modelo. Os parâmetros desta escala Layer também são parâmetros que podem ser aprendidos por meio do treinamento.
Para usar esta camada personalizada também durante a pontuação, temos que empacotar a classe junto com nosso modelo. Com o MLflow, podemos fazer isso com um dicionário custom_objects do Keras que mapeia nomes (strings) para classes ou funções personalizadas associadas ao modelo Keras. O MLflow salva essas camadas personalizadas usando o CloudPickle e as restaura automaticamente quando o modelo é carregado com mlflow.keras.load_model(). e mlflow.pyfunc.load_model().
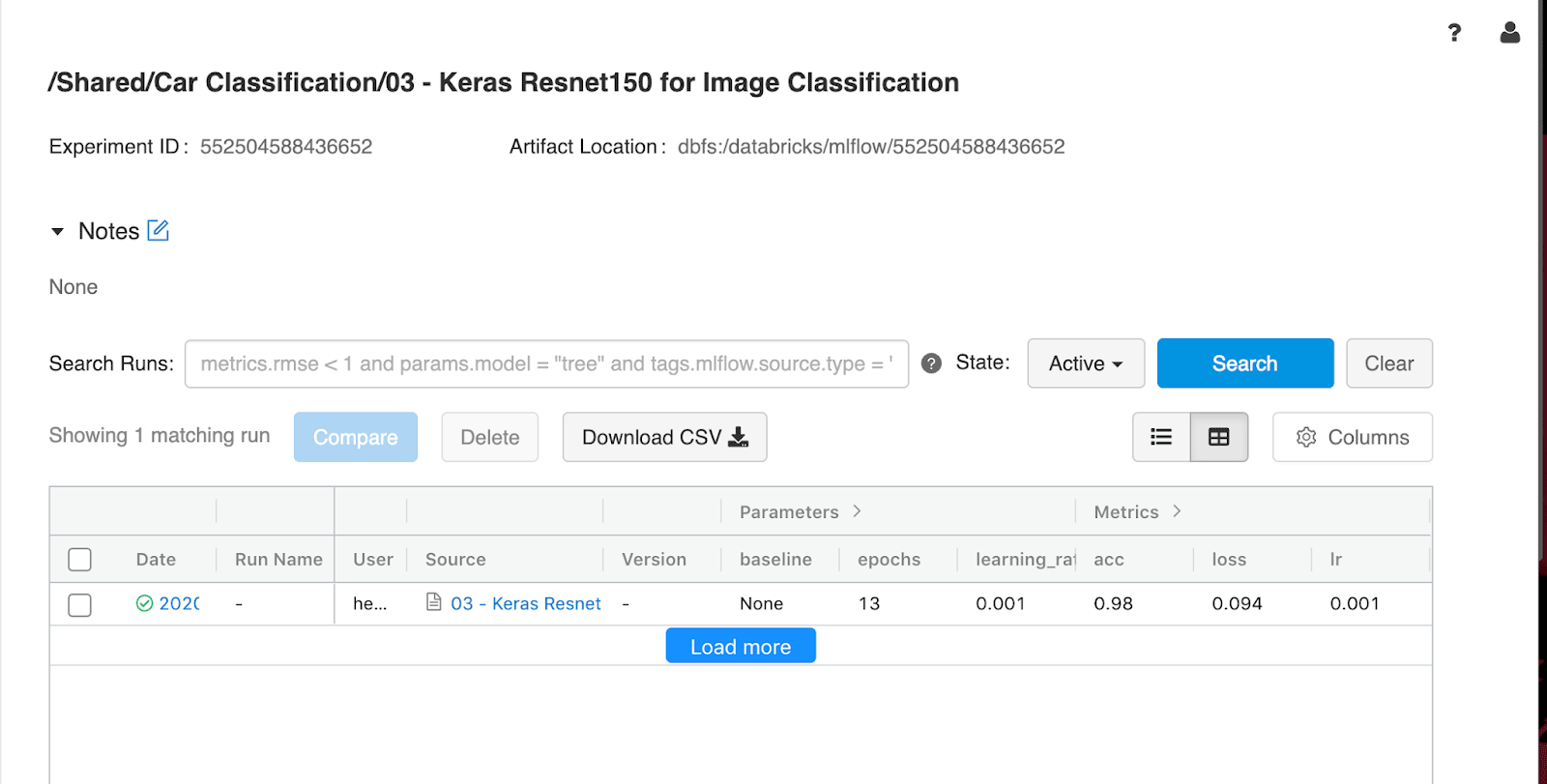
Acompanhamento de resultados com o MLflow e o Azure Machine Learning
O desenvolvimento de machine learning envolve complexidades adicionais além do desenvolvimento de software. O fato de haver uma infinidade de ferramentas e frameworks torna difícil rastrear experimentos, reproduzir resultados e implantar modelos do machine learning. Juntamente com o Azure Machine Learning, é possível acelerar e gerenciar o ciclo de vida do machine learning de ponta a ponta usando o MLflow para criar, compartilhar e implantar aplicativos de machine learning de forma confiável usando o Azure Databricks.
Para rastrear resultados automaticamente, um workspace do Azure ML existente ou novo pode ser vinculado ao seu workspace do Azure Databricks. Além disso, o MLflow oferece suporte a log automático para modelos Keras (mlflow.keras.autolog()), tornando a experiência quase sem esforço.
Embora as utilidades integradas de persistência de modelo do MLflow sejam convenientes para empacotar modelos de várias bibliotecas de ML populares, como o Keras, elas não cobrem todos os casos de uso. Por exemplo, você pode querer usar um modelo de uma biblioteca de ML que não tenha suporte explícito dos 'flavours' integrados do MLflow. Como alternativa, você pode querer empacotar código de inferência e dados personalizados para criar um Modelo MLflow. Felizmente, o MLflow oferece duas soluções que podem ser usadas para realizar essas tarefas: Modelos Python personalizados e Tipos personalizados.
Neste cenário, queremos garantir que podemos usar um mecanismo de inferência de modelo que dê suporte ao atendimento de solicitações de um cliente de API REST. Para isso, estamos usando um modelo personalizado com base no modelo Keras criado anteriormente para aceitar um objeto Dataframe JSON que contém uma imagem codificada em Base64.
Na próximo passo, podemos usar este py_model e implantá-lo em um servidor Azure Container Instances, o que pode ser feito por meio da integração do MLflow com o Azure ML.
Implantar um Modelo de Classificação de Imagem no Azure Container Instances
Até agora, temos um modelo do machine learning treinado e registramos um modelo em nosso workspace com o MLflow na cloud. Como etapa final, gostaríamos de implantar o modelo como um serviço da web no Azure Container Instances.
Um serviço Web é uma imagem, neste caso, uma Docker Image. Ele encapsula a lógica de pontuação e o próprio modelo. Neste caso, estamos usando nossa representação de modelo MLflow personalizada, que nos dá controle sobre como a lógica de pontuação lida com imagens de um cliente REST e como a resposta é formatada.
O Container Instances é uma ótima solução para testar e entender o fluxo de trabalho. Para implantações de produção escaláveis, considere usar o Azure Kubernetes Service. Para mais informações, consulte como e onde implantar.
Introdução à Classificação de Imagens com CNN
Este artigo e estes Notebooks demonstram as principais técnicas usadas na configuração de um fluxo de trabalho de ponta a ponta para treinamento e implantação de uma rede neural em produção no Azure. Os exercícios do Notebook vinculado guiarão você pelos passos necessários para criar isso em seu próprio ambiente do Azure Databricks usando ferramentas como Keras, Databricks Koalas, MLflow e Azure ML.
Recursos do Desenvolvedor
- Notebooks
- Vídeo: https://www.youtube.com/watch?v=mxEqcIbPqPs
- GitHub: https://github.com/EvanEames/Cars
- Apresentações: https://www.slideshare.net/jonbros/deep-learning-with-databricks
- PDF: https://github.com/EvanEames/Cars/blob/master/CNN_howto.pdf
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.