Cinco etapas principais para uma migração bem-sucedida do Hadoop para a arquitetura de lakehouse
por Harsh Narula
A decisão de migrar do Hadoop para uma arquitetura moderna baseada em cloud como a arquitetura lakehouse é uma decisão de negócios, e não uma decisão de tecnología. Em uma postagem de blog anterior, analisamos os motivos pelos quais toda organização deve reavaliar seu relacionamento com o Hadoop. Depois que as partes interessadas das áreas de tecnologia, dados e negócios tomam a decisão de migrar a empresa do Hadoop, há diversas considerações que devem ser levadas em conta antes de iniciar a transição propriamente dita. Neste blog, focaremos especificamente no processo de migração em si. Você aprenderá sobre os key os passos para uma migração bem-sucedida e o papel que a arquitetura lakehouse desempenha em impulsionar a próxima onda de inovação data-driven.
Os passos da migração
Vamos ser sinceros. Migrações nunca são fáceis. No entanto, as migrações podem ser estruturadas para minimizar o impacto adverso, garantir a continuidade dos negócios e gerenciar os custos de forma eficaz. Para fazer isso, sugerimos dividir sua migração do Hadoop nestes cinco passos principais:
- Administração
- Migração de dados
- Processamento de dados
- Segurança e governança
- Camada de SQL e BI
o passo 1: Administração
Vamos analisar alguns dos conceitos essenciais do Hadoop de uma perspectiva de administração e como eles se comparam e contrastam com o Databricks.
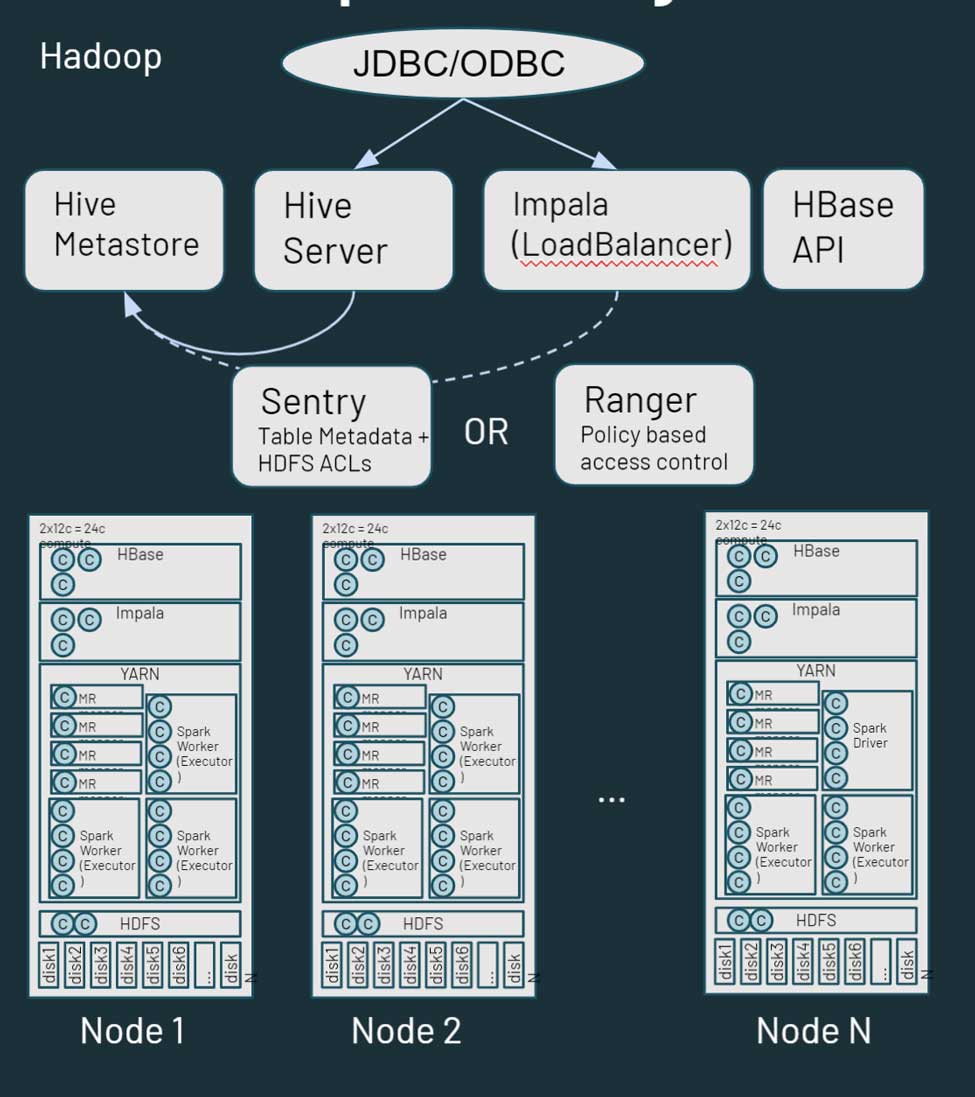
O Hadoop é essencialmente uma plataforma monolítica de armazenamento e computação distribuída. Ele consiste em vários nós e servidores, cada um com seu próprio armazenamento, CPU e memória. O trabalho é distribuído por todos esses nós. O gerenciamento de recurso é feito via YARN, que se esforça para garantir que as cargas de trabalho recebam sua parcela de compute.
O Hadoop também consiste em informações de metadados. Há um Hive metastore, que contém informações estruturadas sobre seus ativos que são armazenados no HDFS. Você pode usar o Sentry ou o Ranger para controlar o acesso aos dados. Da perspectiva do acesso a dados, os usuários e aplicativos podem acessar os dados diretamente pelo HDFS (ou pelas CLIs/APIs correspondentes) ou por uma interface do tipo SQL. A interface SQL, por sua vez, pode ser por uma conexão JDBC/ODBC usando o Hive para SQL genérico (ou, em alguns casos, scripts ETL) ou o Hive no Impala ou Tez para interactive queries. O Hadoop também fornece uma API do HBase e serviços de fonte de dados relacionados. Saiba mais sobre o ecossistema Hadoop aqui.
A seguir, vamos discutir como esses serviços são mapeados ou tratados na Databricks Lakehouse Platform. No Databricks, uma das primeiras diferenças a serem observadas é que você lida com vários clusters em um ambiente do Databricks. Cada cluster pode ser usado para um caso de uso específico, um projeto específico, uma unidade de negócios, uma equipe ou um grupo de desenvolvimento. Mais importante ainda, esses clusters devem ser efêmeros. Para clusters de job, a vida útil deles deve durar o mesmo que o fluxo de trabalho. Ele executará o fluxo de trabalho e, assim que for concluído, o ambiente será desativado automaticamente. Da mesma forma, se você pensar em um caso de uso interativo, no qual você tem um ambiente de compute compartilhado entre os desenvolvedores, esse ambiente pode ser iniciado no começo do dia de trabalho, com os desenvolvedores executando seus códigos ao longo do dia. Durante períodos de inatividade, o Databricks o desativará automaticamente por meio da funcionalidade de encerramento automático (configurável) que está integrada à plataforma.
Diferentemente do Hadoop, o Databricks não oferece serviços de armazenamento de dados como HBase ou SOLR. Seus dados residem no seu armazenamento de arquivos, no armazenamento de objetos. Muitos dos serviços como HBase ou SOLR têm alternativas ou ofertas de tecnología equivalentes na cloud. Pode ser uma solução nativa cloud ou de um ISV.
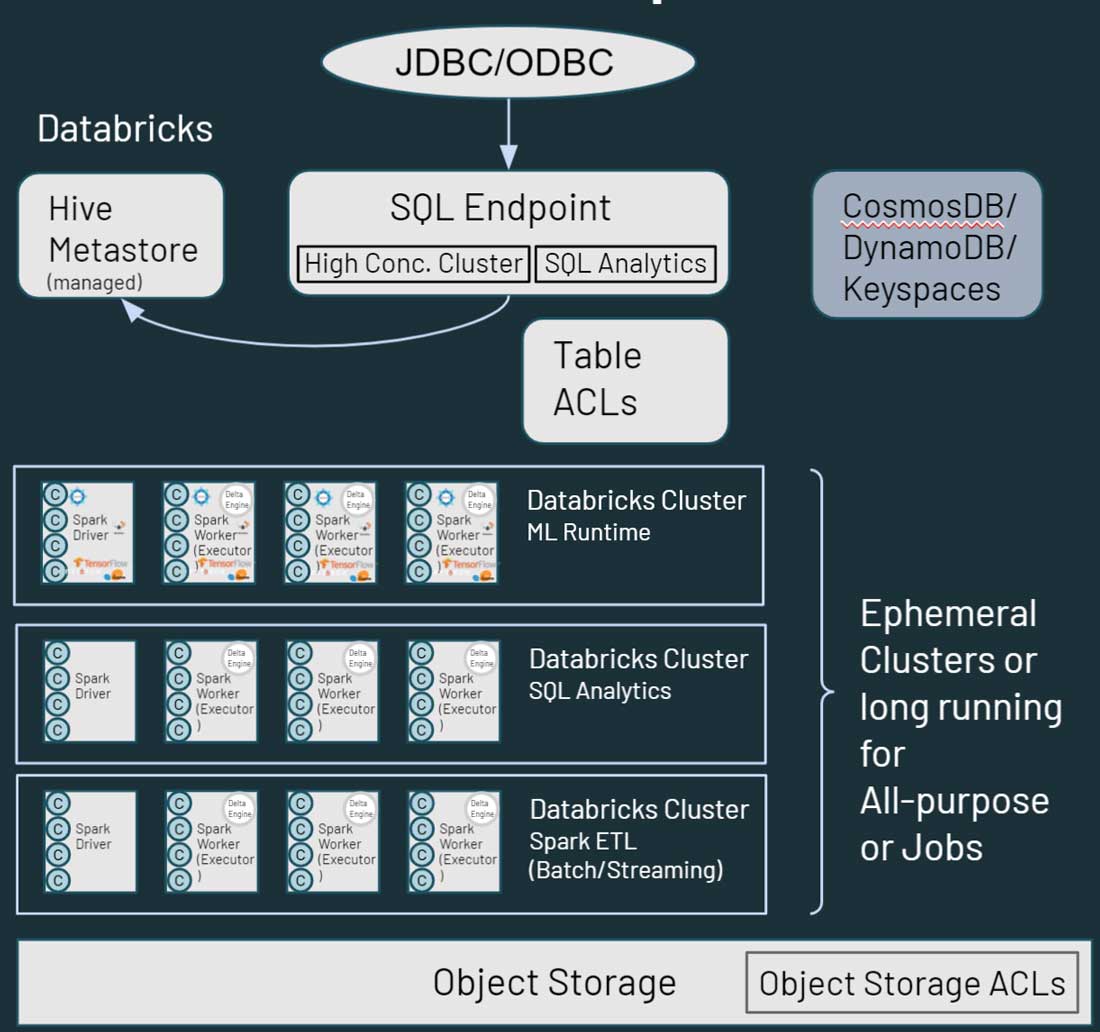
Como você pode ver no diagrama acima, cada nó de cluster no Databricks corresponde a um driver do Spark ou a um worker. O ponto principal aqui é que os diferentes clusters do Databricks são completamente isolados uns dos outros. Isso permite garantir que SLAs rigorosos possam ser atendidos para projetos e casos de uso específicos. Você pode realmente isolar casos de uso de transmissão ou em tempo real de outras cargas de trabalho orientadas a lotes, e não precisa se preocupar em isolar manualmente jobs de longa duração que poderiam monopolizar os recursos do cluster por muito tempo. Você pode simplesmente criar novos clusters como compute para diferentes casos de uso. O Databricks também desacopla o armazenamento do compute e permite que você aproveite o armazenamento em cloud existente, como AWS S3, Azure Blob Storage e Azure Data Lake Store (ADLS).
O Databricks também tem um Hive metastore default gerenciado, que armazena informações estruturadas sobre ativos de dados que residem no armazenamento em cloud. Ele também oferece suporte ao uso de um metastore externo, como o AWS Glue, o Azure SQL Server ou o Azure Purview. Você também pode especificar controles de segurança, como ACLs de tabela, no Databricks, bem como permissões de armazenamento de objetos.
Quando se trata de acesso a dados, o Databricks oferece recursos semelhantes ao Hadoop em termos de como seus usuários interagem com os dados. Os dados armazenados no armazenamento em cloud podem ser acessados por vários caminhos no ambiente Databricks. Os usuários podem usar SQL Endpoints e Databricks SQL para queries e analítica interativas. Eles também podem usar os Notebooks da Databricks para recursos de engenharia de Dados e Machine Learning nos dados armazenados no armazenamento em cloud. O HBase no Hadoop corresponde ao Azure CosmosDB ou AWS DynamoDB/Keyspaces, que podem ser usados como uma camada de serviço para aplicações downstream.
Passo 2: Migração de dados
Vindo de um background em Hadoop, presumo que a maior parte do público já esteja familiarizada com o HDFS. O HDFS é o sistema de arquivos de armazenamento usado com implantações do Hadoop que utiliza os discos nos nós do cluster Hadoop. Portanto, ao escalar o HDFS, é necessário adicionar capacidade ao cluster como um todo (ou seja, é preciso escalar o compute e o armazenamento juntos). Se isso envolver a aquisição e a instalação de hardware adicional, pode haver uma quantidade significativa de tempo e esforço envolvidos.
Na cloud, você tem capacidade de armazenamento quase ilimitada na forma de armazenamento em cloud, como AWS S3, Azure Data Lake Storage, Blob Storage ou Google Storage. Não são necessárias manutenções ou verificações de integridade, e ele oferece redundância integrada e altos níveis de durabilidade e disponibilidade a partir do momento em que é implantado. Recomendamos o uso de serviços de cloud nativos para migrar seus dados e, para facilitar a migração, existem vários parceiros/ISVs.
Então, como começar? O caminho mais comumente recomendado é começar com uma estratégia de ingestão dupla (ou seja, adicione um feed que faz upload de dados para o armazenamento em nuvem, além do seu ambiente on-premises). Isso permite que você comece com novos casos de uso (que aproveitam novos dados) na cloud sem afetar sua configuração existente. Se você estiver procurando pela adesão de outros grupos dentro da organização, pode posicionar isso como uma estratégia de backup para começar. Tradicionalmente, fazer backup do HDFS tem sido um desafio devido ao seu enorme tamanho e ao esforço envolvido, portanto, fazer backup dos dados na cloud pode ser uma iniciativa produtiva.
Na maioria dos casos, você pode aproveitar as ferramentas de entrega de dados existentes para bifurcar o feed e gravar não apenas no Hadoop, mas também no armazenamento em nuvem. Por exemplo, se você estiver usando ferramentas/frameworks como Informatica e Talend para processar e gravar dados no Hadoop, é muito fácil adicionar o passo adicional e fazer com que eles gravem no armazenamento em nuvem. Quando os dados estão na cloud, há muitas maneiras de trabalhar com esses dados.
Em termos de direção de dados, os dados podem ser extraídos do on-premises para a cloud ou enviados para a cloud a partir do on-premises. Algumas das ferramentas que podem ser aproveitadas para enviar os dados para a cloud são soluções nativas cloud (Azure Data Box, AWS Snow Family etc.), DistCP (uma ferramenta do Hadoop), outras ferramentas de terceiros, bem como quaisquer frameworks internos. A opção de envio geralmente é mais fácil em termos de obtenção das aprovações necessárias das equipes de segurança.
Para extrair os dados para a cloud, você pode usar pipelines de ingestão do Spark/Kafka transmissão ou em lotes que são acionados da cloud. Para lotes, você pode ingerir arquivos diretamente ou usar conectores JDBC para se conectar às plataformas de tecnologia de origem relevantes e extrair os dados. Existem, é claro, ferramentas de terceiros disponíveis para isso também. A opção de push é a mais amplamente aceita e compreendida das duas, então vamos nos aprofundar um pouco mais na abordagem de pull.
A primeira coisa que você precisará é configurar a conectividade entre seu ambiente on-premises e a nuvem. Isso pode ser feito com uma conexão com a internet e um gateway. Você também pode aproveitar opções de conectividade dedicada, como AWS Direct Connect, Azure ExpressRoute, etc. Em alguns casos, se sua organização não for nova na cloud, isso já pode ter sido configurado para que você possa reutilizá-lo em seu projeto de migração do Hadoop.
Outra consideração é a segurança no ambiente Hadoop. Se for um ambiente Kerberized, isso pode ser acomodado do lado do Databricks. Você pode configurar scripts de inicialização do Databricks que são executados na inicialização do cluster, instalar e configurar o cliente Kerberos necessário, acessar os arquivos krb5.conf e keytab, que são armazenados em um local de armazenamento em nuvem e, por fim, executar a função kinit(), o que permitirá que o cluster do Databricks interaja diretamente com seu ambiente Hadoop.
Finalmente, você também precisará de um metastore externo compartilhado. Embora o Databricks tenha um serviço de metastore que é implantado por padrão, ele também oferece suporte ao uso de um externo. O metastore externo será compartilhado pelo Hadoop e pelo Databricks e pode ser implantado on-premises (no seu ambiente Hadoop) ou na cloud. Por exemplo, se você tiver processos de ETL existentes em execução no Hadoop e ainda não puder migrá-los para o Databricks, poderá aproveitar essa configuração com o metastore on-premises existente, para que o Databricks consuma o conjunto de dados final curado do Hadoop.
Passo 3: Processamento de dados
O principal a se ter em mente é que, da perspectiva do processamento de dados, tudo no Databricks utiliza o Apache Spark. Todas as linguagens de programação do Hadoop, como MapReduce, Pig, Hive QL e Java, podem ser convertidas para rodar no Spark, seja por meio de Pyspark, Scala, Spark SQL ou até mesmo R. Com relação ao código e à IDE, tanto os notebooks do Apache Zeppelin quanto do Jupyter podem ser convertidos em notebooks do Databricks, mas é um pouco mais fácil importar notebooks do Jupyter. Os notebooks do Zeppelin precisarão ser convertidos para Jupyter ou Ipython antes de poderem ser importados. Se sua equipe de ciência de dados quiser continuar a codificar no Zeppelin ou no Jupyter, eles podem usar o Databricks Connect, que permite que você aproveite sua IDE local (Jupyter, Zeppelin ou até mesmo IntelliJ, VScode, RStudio etc.) para executar o código no Databricks.
Quando se trata de migrar jobs do Apache Spark™, a maior consideração são as versões do Spark. Seu cluster Hadoop on-premises pode estar executando uma versão mais antiga do Spark, e você pode usar o guia de migração do Spark para identificar quais alterações foram feitas para ver os impactos em seu código. Outra área a ser considerada é a conversão de RDDs para dataframes. Os RDDs eram comumente usados com as versões do Spark até a 2.x e, embora ainda possam ser usados com o Spark 3.x, isso pode impedir que você aproveite todos os recursos do otimizador do Spark. Recomendamos que você altere seus RDDs para dataframes sempre que possível.
Por último, mas não menos importante, um dos problemas comuns que encontramos com os clientes durante a migração são as referências hard-coded para o ambiente Hadoop local. Estes, é claro, precisarão ser atualizados, caso contrário, o código falhará na nova configuração.
A seguir, vamos falar sobre a conversão de workloads que não são do Spark, o que, na maior parte, envolve a reescrita do código. No caso do MapReduce, em alguns casos, se você estiver usando uma lógica compartilhada na forma de uma biblioteca Java, o código pode ser aproveitado pelo Spark. No entanto, talvez ainda seja necessário reescrever algumas partes do código para executá-lo em um ambiente Spark em vez do MapReduce. O Sqoop é relativamente fácil de migrar, pois nos novos ambientes você executa um conjunto de comandos do Spark (em vez de comandos do MapReduce) usando uma fonte JDBC. Você pode especificar parâmetros no código Spark da mesma forma que os especifica no Sqoop. Para o Flume, a maioria dos casos de uso que vimos envolve o consumo de dados do Kafka e a gravação no HDFS. Esta é uma tarefa que pode ser facilmente realizada com o Spark Streaming. A principal tarefa ao migrar o Flume é que você precisa converter a abordagem baseada em arquivo de configuração em uma abordagem mais programática no Spark. Por fim, temos o Nifi, que é usado principalmente fora do Hadoop, como uma ferramenta de ingestão de autoatendimento do tipo arrastar e soltar. O Nifi também pode ser aproveitado na cloud, mas vemos muitos clientes aproveitando a oportunidade de migrar para a cloud para substituir o Nifi por outras ferramentas mais novas disponíveis na cloud.
Migrar o HiveQL é, talvez, a tarefa mais fácil de todas. Há um alto grau de compatibilidade entre o Hive e o Spark SQL, e a maioria das queries deve ser capaz de ser executada no Spark SQL sem alterações. Existem algumas pequenas alterações na DDL entre o HiveQL e o Spark SQL, como o fato de que o Spark SQL usa a cláusula “USING” em vez da cláusula “FORMAT” do HiveQL. Recomendamos alterar o código para usar o formato do Spark SQL, pois isso permite que o otimizador prepare o melhor plano de execução possível para seu código no Databricks. Você ainda pode aproveitar os Serdes e UDFs do Hive, o que torna as coisas ainda mais fáceis na hora de migrar o HiveQL para o Databricks.
Com relação à orquestração do fluxo de trabalho, você precisa considerar possíveis mudanças na forma como seus jobs serão enviados. Você pode continuar a usar a semântica de envio do Spark, mas também há outras opções disponíveis mais rápidas e mais perfeitamente integradas. Você pode aproveitar os Jobs do Databricks e as Delta Live Tables para ETL sem código para substituir os Jobs do Oozie e definir pipelines de dados de ponta a ponta no Databricks. Para fluxos de trabalho que envolvem dependências de processamento externo, você precisará criar os fluxos de trabalho/pipelines equivalentes em tecnologias como Apache Airflow, Azure Data Factory, etc., para automação/agendamento. Com as APIs REST do Databricks, quase qualquer plataforma de agendamento pode ser integrada e configurada para funcionar com o Databricks.
Há também uma ferramenta automatizada chamada MLens (criada pela KnowledgeLens), que pode ajudar a migrar suas cargas de trabalho do Hadoop para o Databricks. O MLens pode ajudar a migrar códigos PySpark e HiveQL, incluindo a tradução de algumas das especificidades do Hive para o Spark SQL, para que você possa aproveitar todos os benefícios de funcionalidade e desempenho do otimizador do Spark SQL. Eles também estão planejando oferecer suporte em breve para a migração de fluxos de trabalho do Oozie para Airflow, Azure Data Factory etc.
Passo 4: Segurança e governança
Vamos dar uma olhada em segurança e governança. No mundo do Hadoop, temos integração LDAP para conectividade com consoles de administração como Ambari ou Cloudera Manager, ou até mesmo Impala ou Solr. O Hadoop também tem o Kerberos, que é usado para autenticação com outros serviços. Do ponto de vista da autorização, Ranger e Sentry são as ferramentas mais usadas.
Com o Databricks, a integração de Single Sign On (SSO) está disponível com qualquer provedor de identidade que suporte SAML 2.0. Isso inclui o Azure Active Directory, o Google Workspace SSO, o AWS SSO e o Microsoft Active Directory. Para autorização, o Databricks fornece ACLs (listas de controle de acesso) para objetos do Databricks, o que permite definir permissões em entidades como Notebooks, Jobs e clusters. Para permissões de dados e controle de acesso, você pode definir ACLs de tabela e visualizações para limitar o acesso a colunas e linhas, bem como aproveitar algo como o credential passthrough, com o qual o Databricks repassa suas credenciais de login do workspace para a camada de armazenamento (S3, ADLS, Blob Storage) para determinar se você tem autorização para acessar os dados. Se você precisar de recursos como controles baseados em atributos ou mascaramento de dados, poderá aproveitar as ferramentas de parceiros como Immuta e Privacera. Do ponto de vista da governança corporativa, você pode conectar o Databricks a um catálogo de dados corporativo como AWS Glue, Informatica Data Catalog, Alation e Collibra.
Passo 5: camada de SQL & BI
No Hadoop, conforme discutido anteriormente, você tem o Hive e o Impala como interfaces para fazer ETL, bem como queries ad-hoc e analítica. No Databricks, você tem recursos semelhantes via Databricks SQL. O Databricks SQL também oferece desempenho extremo por meio do mecanismo Delta, bem como suporte para casos de uso de alta simultaneidade com clusters de autoescalonamento. O mecanismo Delta também inclui o Photon, que é um novo mecanismo MPP criado do zero em C++ e é vetorizado para explorar o paralelismo em nível de dados e de instrução.
O Databricks oferece integração nativa com ferramentas de BI, como Tableau, PowerBI, Qlik e Looker, bem como conectores JDBC/ODBC altamente otimizados que podem ser aproveitados por essas ferramentas. Os novos drivers JDBC/ODBC têm um overhead muito pequeno (¼ s) e uma taxa de transferência 50% maior usando o Apache Arrow, bem como várias operações de metadados que suportam operações de recuperação de metadados significativamente mais rápidas. O Databricks também oferece suporte a SSO para PowerBI, com suporte para SSO com outras ferramentas de BI/dashboarding em breve.
O Databricks tem uma UX de SQL integrada, além da experiência com notebooks mencionada acima, que oferece aos usuários de SQL sua própria visão com um workbench de SQL, bem como recursos leves de painéis e alertas. Isso permite transformações de dados baseadas em SQL e analítica exploratória de dados no data lake, sem a necessidade de movê-los para um data warehouse ou outras plataformas.
Passos seguintes
Ao pensar em sua jornada de migração para uma arquitetura de nuvem moderna, como a arquitetura lakehouse, aqui estão duas coisas a serem lembradas:
- Lembre-se de trazer os chave stakeholders de negócios junto na jornada. Esta é tanto uma decisão de tecnologia quanto uma decisão de negócios, e você precisa que seus stakeholders de negócios estejam engajados na jornada e em seu estado final.
- Além disso, lembre-se de que você não está só, e há recursos qualificados no Databricks e em nossos parceiros que já fizeram isso o suficiente para desenvolver melhores práticas replicáveis, economizando tempo, dinheiro e recursos das organizações, e reduzindo o estresse geral.
- Faça o download do guia técnico de migração do Hadoop para o Databricks para obter orientações passo a passo, notebooks e código para iniciar sua migração.
Para saber mais sobre como o Databricks aumenta o valor de negócios e começar a planejar sua migração do Hadoop, acesse www.databricks.com/solutions/migration.

Guia de migração: do Hadoop para o Databricks
Libere todo o potencial dos seus dados com este manual autoguiado.
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.