Pipelines de Dados de Streaming de Baixa Latência com Delta Live Tables e Apache Kafka
por Frank Munz
Delta Live Tables (DLT) é o primeiro framework de ETL que usa uma abordagem declarativa simples para criar pipelines de dados confiáveis e gerencia totalmente a infraestrutura subjacente em escala para dados em lote e dados de streaming. Muitos casos de uso exigem insights acionáveis derivados de dados em tempo quase real. O Delta Live Tables permite pipelines de dados de streaming de baixa latência para dar suporte a esses casos de uso com baixas latências, ingerindo dados diretamente de barramentos de eventos como Apache Kafka, AWS Kinesis, Confluent Cloud, Amazon MSK ou Azure Event Hubs.
Este artigo guiará você pelo uso do DLT com Apache Kafka, fornecendo o código Python necessário para ingerir streams. A arquitetura de sistema recomendada será explicada e as configurações relacionadas do DLT a serem consideradas serão exploradas ao longo do caminho.
Plataformas de streaming
Barramentos de eventos ou barramentos de mensagens desacoplam produtores de mensagens de consumidores. Um caso de uso popular de streaming é a coleta de dados de cliques de usuários navegando em um site, onde cada interação do usuário é armazenada como um evento no Apache Kafka. O fluxo de eventos do Kafka é então usado para análise de dados de streaming em tempo real. Múltiplos consumidores de mensagens podem ler os mesmos dados do Kafka e usá-los para aprender sobre interesses do público, taxas de conversão e motivos de rejeição. Os dados de eventos de streaming em tempo real das interações do usuário muitas vezes também precisam ser correlacionados com compras reais armazenadas em um banco de dados de faturamento.
Apache Kafka
Apache Kafka é um barramento de eventos popular de código aberto. O Kafka usa o conceito de um tópico, um log distribuído de eventos somente para anexação, onde as mensagens são armazenadas em buffer por um certo período de tempo. Embora as mensagens no Kafka não sejam excluídas depois de consumidas, elas também não são armazenadas indefinidamente. A retenção de mensagens para Kafka pode ser configurada por tópico e o padrão é de 7 dias. Mensagens expiradas serão excluídas eventualmente.
Este artigo é centrado em Apache Kafka; no entanto, os conceitos discutidos também se aplicam a muitos outros barramentos de eventos ou sistemas de mensagens.
Pipelines de dados de streaming
Em um pipeline de fluxo de dados, o Delta Live Tables e suas dependências podem ser declarados com uma instrução SQL padrão Create Table As Select (CTAS) e a palavra-chave DLT "live".
Ao desenvolver DLT com Python, o decorador @dlt.table é usado para criar uma Tabela Delta Live. Para garantir a qualidade dos dados em um pipeline, o DLT usa Expectations, que são cláusulas de restrição SQL simples que definem o comportamento do pipeline com registros inválidos.
Como as cargas de trabalho de streaming geralmente vêm com volumes de dados imprevisíveis, o Databricks emprega autoscale aprimorado para pipelines de fluxo de dados para minimizar a latência geral de ponta a ponta, reduzindo o custo ao desligar a infraestrutura desnecessária.
Delta Live Tables são totalmente recalculadas, na ordem correta, exatamente uma vez para cada execução de pipeline.
Em contraste, tabelas Delta Live de streaming são stateful, computadas incrementalmente e processam apenas os dados que foram adicionados desde a última execução do pipeline. Se a consulta que define uma tabela live de streaming for alterada, novos dados serão processados com base na nova consulta, mas os dados existentes não serão recalculados. Tabelas live de streaming sempre usam uma fonte de streaming e funcionam apenas sobre fluxos somente para anexação, como Kafka, Kinesis ou Auto Loader. DLTs de streaming são baseadas em Spark Structured Streaming.
Você pode encadear múltiplos pipelines de streaming, por exemplo, cargas de trabalho com volume de dados muito grande e requisitos de baixa latência.
Ingestão Direta de Motores de Streaming
O Delta Live Tables escrito em Python pode ingerir dados diretamente de um barramento de eventos como Kafka usando Spark Structured Streaming. Você pode definir um curto período de retenção para o tópico Kafka para evitar problemas de conformidade, reduzir custos e, em seguida, se beneficiar do armazenamento barato, elástico e governável que o Delta oferece.
Como primeira etapa no pipeline, recomendamos ingerir os dados como estão em uma tabela bronze (bruta) e evitar transformações complexas que possam descartar dados importantes. Como qualquer Tabela Delta, a tabela bronze reterá o histórico e permitirá a realização de tarefas de conformidade com GDPR e outras.
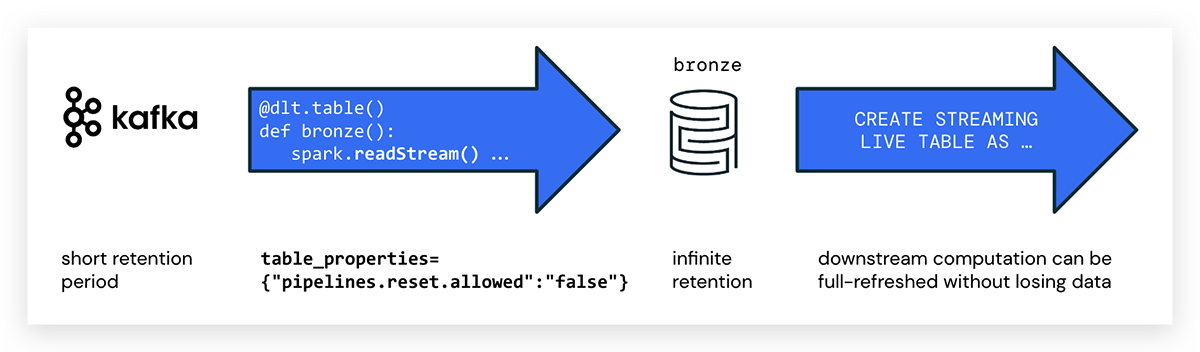
Ao escrever pipelines DLT em Python, você usa a anotação @dlt.table para criar uma tabela DLT. Não há atributo especial para marcar DLTs de streaming em Python; basta usar spark.readStream() para acessar o stream. Um exemplo de código para criar uma tabela DLT com o nome kafka_bronze que consome dados de um tópico Kafka é o seguinte:
pipelines.reset.allowed
Observe que barramentos de eventos normalmente expiram mensagens após um certo período de tempo, enquanto o Delta é projetado para retenção infinita.
Isso pode levar ao efeito de que os dados de origem no Kafka já foram excluídos ao executar uma atualização completa para um pipeline DLT. Nesse caso, nem todos os dados históricos poderiam ser preenchidos a partir da plataforma de mensagens, e os dados estariam faltando nas tabelas DLT. Para evitar a perda de dados, use a seguinte propriedade de tabela DLT:
pipelines.reset.allowed=false
Definir pipelines.reset.allowed como false impede atualizações na tabela, mas não impede escritas incrementais nas tabelas ou que novos dados fluam para a tabela.
Checkpointing
Se você for um desenvolvedor experiente de Spark Structured Streaming, notará a ausência de checkpointing no código acima. No Spark Structured Streaming, o checkpointing é necessário para persistir informações de progresso sobre quais dados foram processados com sucesso e, em caso de falha, esses metadados são usados para reiniciar uma consulta com falha exatamente de onde parou.
Enquanto os checkpoints são necessários para recuperação de falhas com garantias de exatamente uma vez no Spark Structured Streaming, o DLT gerencia o estado automaticamente sem qualquer configuração manual ou checkpointing explícito necessário.
Misturando SQL e Python para um Pipeline DLT
Um pipeline DLT pode consistir em vários notebooks, mas um notebook DLT deve ser escrito inteiramente em SQL ou Python (ao contrário de outros notebooks Databricks onde você pode ter células de diferentes linguagens em um único notebook).
Agora, se sua preferência for SQL, você pode codificar a ingestão de dados do Apache Kafka em um notebook em Python e, em seguida, implementar a lógica de transformação de seus pipelines de dados em outro notebook em SQL.
Mapeamento de esquema
Ao ler dados de uma plataforma de mensagens, o fluxo de dados é opaco e um esquema deve ser fornecido.
O exemplo Python abaixo mostra a definição do esquema de eventos de um rastreador de fitness e como a parte de valor da mensagem Kafka é mapeada para esse esquema.
Benefícios
Ler dados de streaming em DLT diretamente de um broker de mensagens minimiza a complexidade arquitetural e fornece menor latência de ponta a ponta, pois os dados são transmitidos diretamente do broker de mensagens e nenhuma etapa intermediária é envolvida.
Ingestão de Streaming com Intermediário de Armazenamento de Objetos na Nuvem
Para alguns casos de uso específicos, você pode querer descarregar dados do Apache Kafka, por exemplo, usando um conector Kafka, e armazenar seus dados de streaming em um intermediário de objetos na nuvem. Em um workspace Databricks, o armazenamento de objetos específico do fornecedor de nuvem pode então ser mapeado através do Databricks Files System (DBFS) como uma pasta independente da nuvem. Uma vez que os dados são descarregados, o Databricks Auto Loader pode ingerir os arquivos.
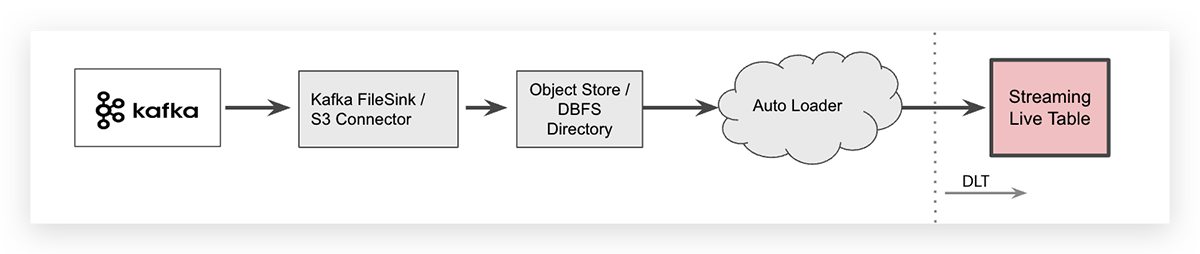
O Auto Loader pode ingerir dados com uma única linha de código SQL. A sintaxe para ingerir arquivos JSON em uma tabela DLT é mostrada abaixo (está dividida em duas linhas para facilitar a leitura).
Note que o Auto Loader em si é uma fonte de dados de streaming e todos os arquivos recém-chegados serão processados exatamente uma vez, daí a palavra-chave de streaming para a tabela bruta que indica que os dados são ingeridos incrementalmente para essa tabela.
Como descarregar dados de streaming para um armazenamento de objetos na nuvem introduz uma etapa adicional na arquitetura do seu sistema, isso também aumentará a latência de ponta a ponta e criará custos adicionais de armazenamento. Tenha em mente que o conector Kafka que grava dados de eventos no armazenamento de objetos na nuvem precisa ser gerenciado, aumentando a complexidade operacional.
Portanto, a Databricks recomenda, como uma boa prática, acessar diretamente os dados do barramento de eventos do DLT usando Spark Structured Streaming conforme descrito acima.
Outros Barramentos de Eventos ou Sistemas de Mensagens
Este artigo é centrado em Apache Kafka; no entanto, os conceitos discutidos também se aplicam a outros barramentos de eventos ou sistemas de mensagens. O DLT suporta qualquer fonte de dados que o Databricks Runtime suporta diretamente.
Amazon Kinesis
No Kinesis, você grava mensagens em um stream totalmente gerenciado e sem servidor. Assim como o Kafka, o Kinesis não armazena mensagens permanentemente. A retenção padrão de mensagens no Kinesis é de um dia.
Ao usar o Amazon Kinesis, substitua format("kafka") por format("kinesis") no código Python para ingestão de streaming acima e adicione configurações específicas do Amazon Kinesis com option(). Para mais informações, verifique a seção sobre Integração com Kinesis na documentação do Spark Structured Streaming.
Azure Event Hubs
Para configurações do Azure Event Hubs, verifique a documentação oficial da Microsoft e o artigo Receitas do Delta Live Tables: Consumindo do Azure Event Hubs.
Resumo
DLT é muito mais do que apenas o "T" em ETL. Com DLT, você pode facilmente ingerir de fontes de streaming e em lote, limpar e transformar dados na Databricks Lakehouse Platform em qualquer nuvem com qualidade de dados garantida.
Dados do Apache Kafka podem ser ingeridos conectando-se diretamente a um broker Kafka de um notebook DLT em Python. A perda de dados pode ser evitada para uma atualização completa do pipeline, mesmo quando os dados de origem na camada de streaming Kafka expiraram.
Comece
Se você é um cliente Databricks, basta seguir o guia para começar. Leia as notas de lançamento para saber mais sobre o que está incluído nesta versão GA. Se você não é um cliente Databricks existente, inscreva-se para um teste gratuito e você pode ver nossos Preços Detalhados de DLT aqui.
Participe da conversa na Comunidade Databricks onde colegas obcecados por dados estão conversando sobre os anúncios e atualizações do Data + AI Summit 2022. Aprenda. Conecte-se.
Por último, mas não menos importante, aproveite a sessão Aprofunde-se em Engenharia de Dados do summit. Nessa sessão, eu o guio pelo código de outro exemplo de dados de streaming com um stream ao vivo do Twitter, Auto Loader, Delta Live Tables em SQL e análise de sentimento Hugging Face.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.