Low-latency Streaming Data Pipelines with Delta Live Tables and Apache Kafka
by Frank Munz
Delta Live Tables (DLT) is the first ETL framework that uses a simple declarative approach for creating reliable data pipelines and fully manages the underlying infrastructure at scale for batch and streaming data. Many use cases require actionable insights derived from near real-time data. Delta Live Tables enables low-latency streaming data pipelines to support such use cases with low latencies by directly ingesting data from event buses like Apache Kafka, AWS Kinesis, Confluent Cloud, Amazon MSK, or Azure Event Hubs.
This article will walk through using DLT with Apache Kafka while providing the required Python code to ingest streams. The recommended system architecture will be explained, and related DLT settings worth considering will be explored along the way.
Streaming platforms
Event buses or message buses decouple message producers from consumers. A popular streaming use case is the collection of click-through data from users navigating a website where every user interaction is stored as an event in Apache Kafka. The event stream from Kafka is then used for real-time streaming data analytics. Multiple message consumers can read the same data from Kafka and use the data to learn about audience interests, conversion rates, and bounce reasons. The real-time, streaming event data from the user interactions often also needs to be correlated with actual purchases stored in a billing database.
Apache Kafka
Apache Kafka is a popular open source event bus. Kafka uses the concept of a topic, an append-only distributed log of events where messages are buffered for a certain amount of time. Although messages in Kafka are not deleted once they are consumed, they are also not stored indefinitely. The message retention for Kafka can be configured per topic and defaults to 7 days. Expired messages will be deleted eventually.
This article is centered around Apache Kafka; however, the concepts discussed also apply to many other event busses or messaging systems.
Streaming data pipelines
In a data flow pipeline, Delta Live Tables and their dependencies can be declared with a standard SQL Create Table As Select (CTAS) statement and the DLT keyword "live."
When developing DLT with Python, the @dlt.table decorator is used to create a Delta Live Table. To ensure the data quality in a pipeline, DLT uses Expectations which are simple SQL constraints clauses that define the pipeline's behavior with invalid records.
Since streaming workloads often come with unpredictable data volumes, Databricks employs enhanced autoscaling for data flow pipelines to minimize the overall end-to-end latency while reducing cost by shutting down unnecessary infrastructure.
Delta Live Tables are fully recomputed, in the right order, exactly once for each pipeline run.
In contrast, streaming Delta Live Tables are stateful, incrementally computed and only process data that has been added since the last pipeline run. If the query which defines a streaming live tables changes, new data will be processed based on the new query but existing data is not recomputed. Streaming live tables always use a streaming source and only work over append-only streams, such as Kafka, Kinesis, or Auto Loader. Streaming DLTs are based on top of Spark Structured Streaming.
You can chain multiple streaming pipelines, for example, workloads with very large data volume and low latency requirements.
Direct Ingestion from Streaming Engines
Delta Live Tables written in Python can directly ingest data from an event bus like Kafka using Spark Structured Streaming. You can set a short retention period for the Kafka topic to avoid compliance issues, reduce costs and then benefit from the cheap, elastic and governable storage that Delta provides.
As a first step in the pipeline, we recommend ingesting the data as is to a bronze (raw) table and avoid complex transformations that could drop important data. Like any Delta Table the bronze table will retain the history and allow to perform GDPR and other compliance tasks.
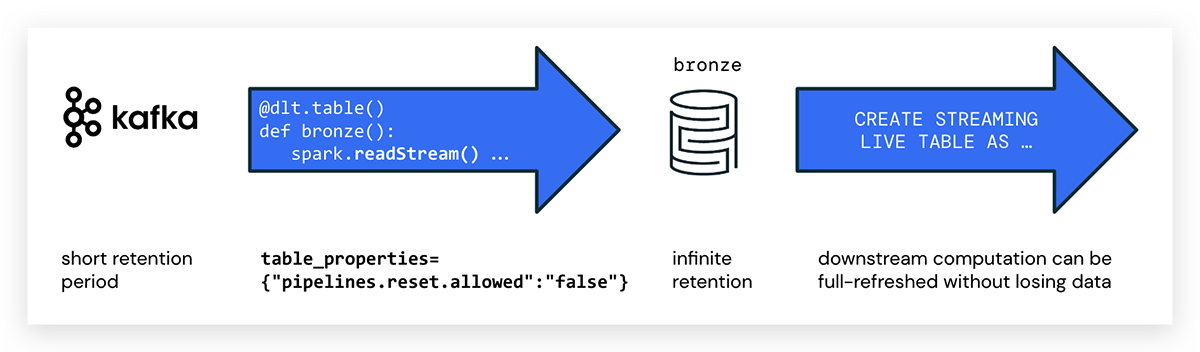
When writing DLT pipelines in Python, you use the @dlt.table annotation to create a DLT table. There is no special attribute to mark streaming DLTs in Python; simply use spark.readStream() to access the stream. Example code for creating a DLT table with the name kafka_bronze that is consuming data from a Kafka topic looks as follows:
pipelines.reset.allowed
Note that event buses typically expire messages after a certain period of time, whereas Delta is designed for infinite retention.
This might lead to the effect that source data on Kafka has already been deleted when running a full refresh for a DLT pipeline. In this case, not all historic data could be backfilled from the messaging platform, and data would be missing in DLT tables. To prevent dropping data, use the following DLT table property:
pipelines.reset.allowed=false
Setting pipelines.reset.allowed to false prevents refreshes to the table but does not prevent incremental writes to the tables or new data from flowing into the table.
Checkpointing
If you are an experienced Spark Structured Streaming developer, you will notice the absence of checkpointing in the above code. In Spark Structured Streaming checkpointing is required to persist progress information about what data has been successfully processed and upon failure, this metadata is used to restart a failed query exactly where it left off.
Whereas checkpoints are necessary for failure recovery with exactly-once guarantees in Spark Structured Streaming, DLT handles state automatically without any manual configuration or explicit checkpointing required.
Mixing SQL and Python for a DLT Pipeline
A DLT pipeline can consist of multiple notebooks but one DLT notebook is required to be either entirely written in SQL or Python (unlike other Databricks notebooks where you can have cells of different languages in a single notebook).
Now, if your preference is SQL, you can code the data ingestion from Apache Kafka in one notebook in Python and then implement the transformation logic of your data pipelines in another notebook in SQL.
Schema mapping
When reading data from messaging platform, the data stream is opaque and a schema has to be provided.
The Python example below shows the schema definition of events from a fitness tracker, and how the value part of the Kafka message is mapped to that schema.
Benefits
Reading streaming data in DLT directly from a message broker minimizes the architectural complexity and provides lower end-to-end latency since data is directly streamed from the messaging broker and no intermediary step is involved.
Streaming Ingest with Cloud Object Store Intermediary
For some specific use cases you may want offload data from Apache Kafka, e.g., using a Kafka connector, and store your streaming data in a cloud object intermediary. In a Databricks workspace, the cloud vendor-specific object-store can then be mapped via the Databricks Files System (DBFS) as a cloud-independent folder. Once the data is offloaded, Databricks Auto Loader can ingest the files.
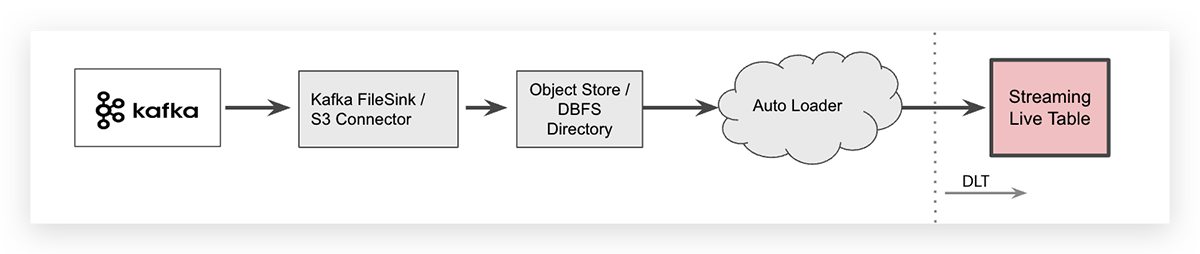
Auto Loader can ingest data with with a single line of SQL code. The syntax to ingest JSON files into a DLT table is shown below (it is wrapped across two lines for readability).
Note that Auto Loader itself is a streaming data source and all newly arrived files will be processed exactly once, hence the streaming keyword for the raw table that indicates data is ingested incrementally to that table.
Since offloading streaming data to a cloud object store introduces an additional step in your system architecture it will also increase the end-to-end latency and create additional storage costs. Keep in mind that the Kafka connector writing event data to the cloud object store needs to be managed, increasing operational complexity.
Therefore Databricks recommends as a best practice to directly access event bus data from DLT using Spark Structured Streaming as described above.
Other Event Buses or Messaging Systems
This article is centered around Apache Kafka; however, the concepts discussed also apply to other event buses or messaging systems. DLT supports any data source that Databricks Runtime directly supports.
Amazon Kinesis
In Kinesis, you write messages to a fully managed serverless stream. Same as Kafka, Kinesis does not permanently store messages. The default message retention in Kinesis is one day.
When using Amazon Kinesis, replace format("kafka") with format("kinesis") in the Python code for streaming ingestion above and add Amazon Kinesis-specific settings with option(). For more information, check the section about Kinesis Integration in the Spark Structured Streaming documentation.
Azure Event Hubs
For Azure Event Hubs settings, check the official documentation at Microsoft and the article Delta Live Tables recipes: Consuming from Azure Event Hubs.
Summary
DLT is much more than just the "T" in ETL. With DLT, you can easily ingest from streaming and batch sources, cleanse and transform data on the Databricks Lakehouse Platform on any cloud with guaranteed data quality.
Data from Apache Kafka can be ingested by directly connecting to a Kafka broker from a DLT notebook in Python. Data loss can be prevented for a full pipeline refresh even when the source data in the Kafka streaming layer expired.
Get started
If you are a Databricks customer, simply follow the guide to get started. Read the release notes to learn more about what's included in this GA release. If you are not an existing Databricks customer, sign up for a free trial, and you can view our detailed DLT Pricing here.
Join the conversation in the Databricks Community where data-obsessed peers are chatting about Data + AI Summit 2022 announcements and updates. Learn. Network.
Last but not least, enjoy the Dive Deeper into Data Engineering session from the summit. In that session, I walk you through the code of another streaming data example with a Twitter live stream, Auto Loader, Delta Live Tables in SQL, and Hugging Face sentiment analysis.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.