Implante LLMs privados usando o Databricks Model Serving
por Ahmed Bilal, Ankit Mathur, Kasey Uhlenhuth e Joshua Hartman
Temos o prazer de anunciar o preview público do suporte à otimização de GPU e LLM para o Databricks Model Serving! Com este lançamento, você pode implantar modelos de IA de código aberto ou personalizados de qualquer tipo, incluindo LLMs e modelos de visão, na plataforma lakehouse. O Databricks Model Serving otimiza automaticamente seu modelo para o LLM Serving, oferecendo o melhor desempenho da categoria sem nenhuma configuração.
O Databricks Model Serving é o primeiro produto de serving de GPU serverless desenvolvido em uma plataforma unificada de dados e IA. Isso permite que você crie e implante aplicativos de GenAI, desde a ingestão de dados e o ajuste fino até a implantação e o monitoramento de modelos, tudo em uma única plataforma.
Crie aplicativos de AI generativa com o Databricks Model Serving
"Com a disponibilização de modelos da Databricks, podemos integrar IA generativa aos nossos processos para melhorar a experiência do cliente e aumentar a eficiência operacional. A disponibilização de modelos nos permite implantar modelos de LLM e, ao mesmo tempo, manter o controle total sobre nossos dados e modelos.” —Ben Dias, diretor de ciência de dados e analítica da easyJet - Saiba mais
Hospede modelos de AI com segurança sem se preocupar com o gerenciamento da infraestrutura
O Databricks Model Serving oferece uma solução única para implantar qualquer modelo de AI sem a necessidade de entender infraestruturas complexas. Isso significa que você pode implantar qualquer modelo de linguagem natural, visão, áudio, tabular ou personalizado, independentemente de como foi treinado, seja ele criado do zero, de código aberto ou ajustado com dados proprietários. Basta registrar seu modelo com o MLflow, e nós prepararemos automaticamente um contêiner pronto para produção com bibliotecas de GPU como CUDA e o implantaremos em GPUs serverless. Nosso serviço totalmente gerenciado cuidará de todo o trabalho pesado para você, eliminando a necessidade de gerenciar instâncias, manter a compatibilidade de versões e aplicar patches de versões. O serviço escalonará instâncias automaticamente para atender aos padrões de tráfego, economizando custos de infraestrutura e otimizando o desempenho de latência.
"A disponibilização de modelos da Databricks está acelerando nossa capacidade de infundir inteligência em uma variedade de casos de uso, desde aplicações de pesquisa semântica significativas até a previsão de tendências de mídia. Ao abstrair e simplificar o intrincado funcionamento do dimensionamento de servidores CUDA e GPU, a Databricks nos permite focar nas áreas reais de especialização, ou seja, expandir o uso de IA da Condé Nast em todas as nossas aplicações sem o incômodo e a carga da infraestrutura."
Reduza a latência e o custo com o serviço otimizado de LLMs
O Databricks Model Serving agora inclui otimizações para servir modelos de linguagem grandes com eficiência, reduzindo a latência e o custo em até 3 a 5 vezes. Usar o Optimized LLM Serving é incrivelmente fácil: basta fornecer o modelo junto com seus pesos de OSS ou de ajuste fino, e nós faremos o resto para garantir que o modelo seja servido com desempenho otimizado. Isso permite que você se concentre na integração do LLM em seu aplicativo, em vez de escrever bibliotecas de baixo nível para otimizações de modelo. O Databricks Model Serving otimiza automaticamente a classe de modelos MPT e Llama2, com suporte para mais modelos em breve.
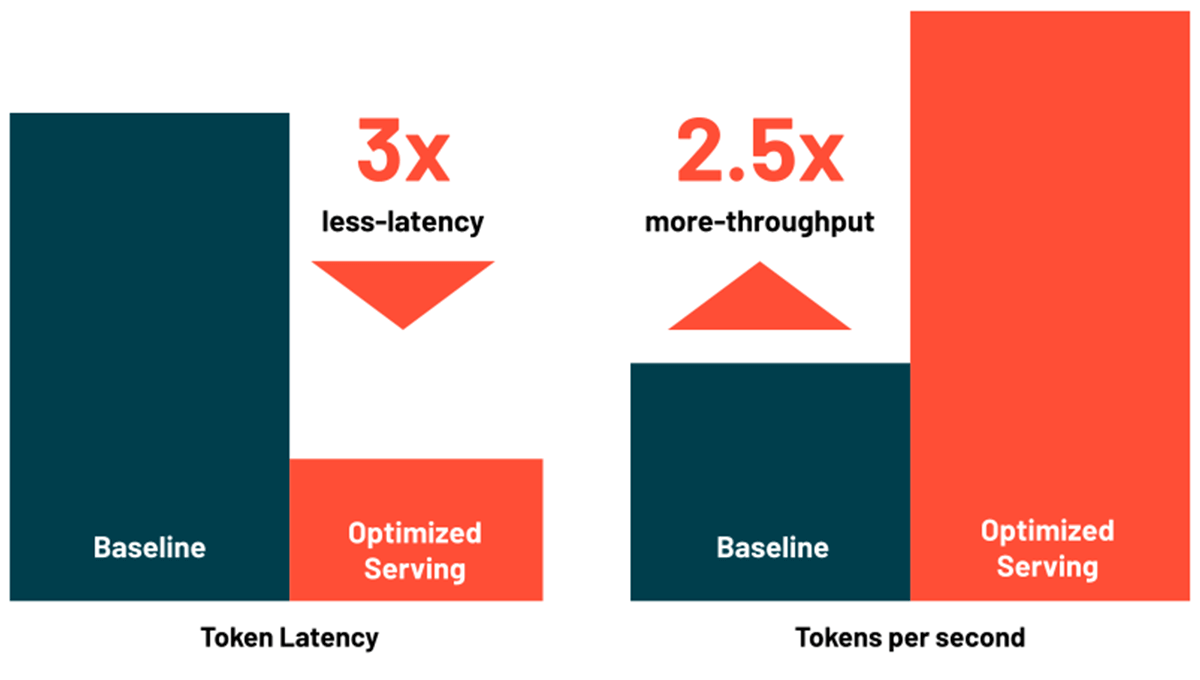
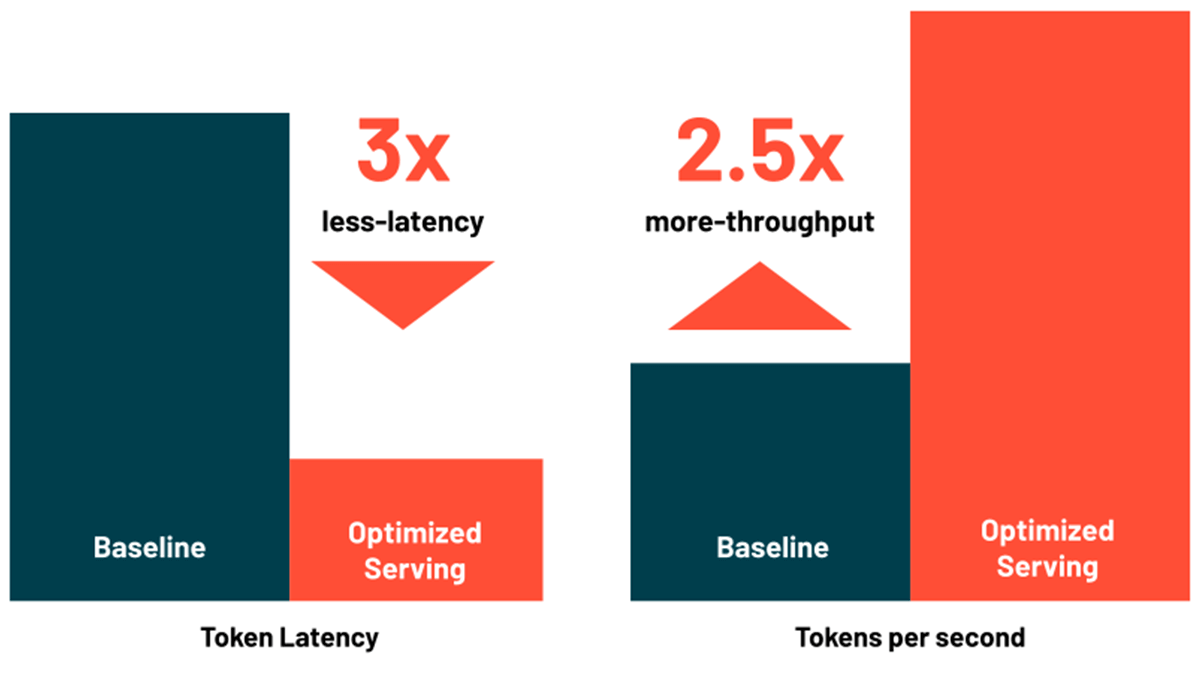{kind=link}
Acelere as implantações por meio de integrações do Lakehouse AI
Ao colocar LLMs em produção, não se trata apenas de implantar modelos. Você também precisa complementar o modelo usando técnicas como geração aumentada por recuperação (RAG), ajuste fino com eficiência de parâmetros (PEFT) ou ajuste fino padrão. Além disso, você precisa avaliar a qualidade do LLM e monitorar continuamente o modelo para desempenho e segurança. Isso geralmente resulta em equipes gastando um tempo considerável na integração de ferramentas distintas, o que aumenta a complexidade operacional e cria sobrecarga de manutenção.
O Databricks Model Serving é construído sobre uma plataforma unificada de dados e IA, permitindo que você gerenciar todo o LLMOps, desde a ingestão de dados e o ajuste fino até a implantação e o monitoramento, tudo em uma única plataforma, criando uma consistente view em todo o ciclo de vida da IA que acelera a implantação e minimiza erros. O Model Serving se integra a vários serviços de LLM no Lakehouse, incluindo:
- Ajuste fino: melhore a precisão e diferencie-se ajustando modelos fundacionais com seus dados proprietários diretamente no Lakehouse.
- Integração com a AI Search: integre e execute buscas vetoriais de modo transparente para casos de uso de geração aumentada por recuperação e busca semântica. Inscreva-se no preview aqui.
- Gerenciamento de LLM integrado: integrado ao Databricks AI Gateway como uma camada de API central para todas as suas chamadas de LLM.
- MLflow: Avalie, compare e gerencie LLMs com o PromptLab do MLflow.
- Qualidade e diagnóstico: capture automaticamente solicitações e respostas em uma tabela Delta para monitorar e depurar modelos. Você também pode combinar esses dados com seus rótulos para gerar datasets de treinamento por meio de nossa parceria com a Labelbox.
- Governança unificada: gerencie e governe todos os ativos de dados e IA, incluindo aqueles consumidos e produzidos pelo Model Serving, com o Unity Catalog.
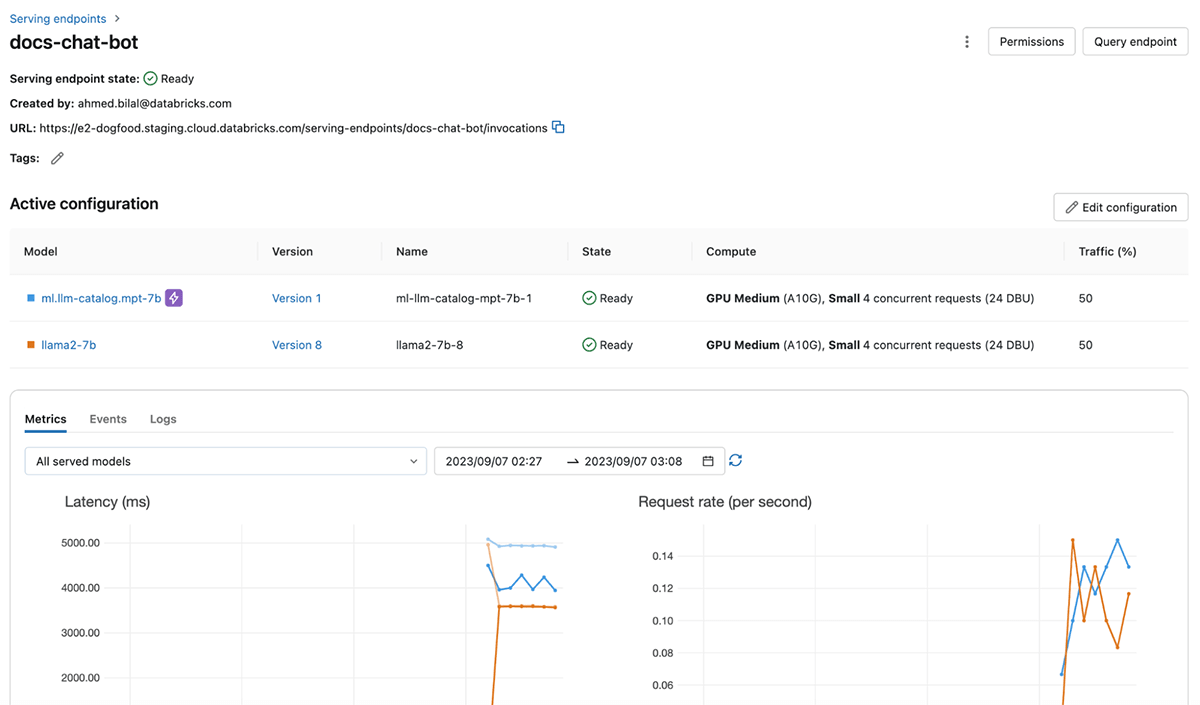
Traga confiabilidade e segurança para a disponibilização de LLMs
O Databricks Model Serving fornece recursos de compute dedicados que permitem inferência em escala, com controle total sobre os dados, o modelo e a configuração de implantação. Ao obter capacidade dedicada na região de cloud de sua escolha, você se beneficia de baixa latência de sobrecarga, desempenho previsível e garantias com suporte de SLA. Além disso, suas cargas de trabalho de disponibilização são protegidas por várias camadas de segurança, garantindo um ambiente seguro e confiável até mesmo para as tarefas mais confidenciais. Implementamos vários controles para atender às necessidades exclusivas de compliance de indústrias altamente regulamentadas. Para mais detalhes, visite esta página ou entre em contato com sua equipe de conta da Databricks.
Primeiros passos com o serviço de GPUs e LLMs
- Experimente! Implante seu primeiro LLM no Databricks Model Serving lendo o tutorial de primeiros passos (AWS | Azure).
- Aprofunde-se na documentação do Databricks Model Serving.
- Saiba mais sobre a abordagem da Databricks para AI generativa aqui.
- Trilha de Aprendizagem de Engenheiro de IA Generativa: faça cursos no seu próprio ritmo, sob demanda e ministrados por instrutores sobre IA Generativa
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.