easyJet bets on Databricks and Generative AI to be an Innovation Leader in Aviation
by Ben Dias, Ioannis Mesionis, Sepideh Ebrahimi and Rafael Pierre
This blog is authored by Ben Dias, Director of Data Science and Analytics and Ioannis Mesionis, Lead Data Scientist at easyJet
Introduction to easyJet
easyJet flies on more of Europe’s most popular routes than any other airline and carried more than 69 million passengers in 2022 – with 9.5 million traveling for business. The airline has over 300 aircraft on nearly 1000 routes to more than 150 airports across 36 countries. Over 300 million Europeans live within one hour's drive of an easyJet airport.
Like many companies in the airline industry, easyJet is currently presented with challenges around customer experience and digitalization. In today’s competitive landscape, customers are changing their preferences quickly, and their expectations around customer service have never been higher. Having a proper data and AI strategy can unlock many business opportunities related to digital customer service, personalization and operational process optimization.
Challenges Faced by easyJet
When starting this project, easyJet was already a customer of Databricks for almost a year. At that point, we were fully leveraging Databricks for data engineering and warehousing and had just migrated all of our data science workloads and started to migrate our analytics workloads onto Databricks. We are also actively decommissioning our old technology stack, as we migrate our workloads over to our new Databricks Data Intelligence Platform.
By migrating data engineering workloads to a lakehouse architecture on Databricks, we were able to reap benefits in terms of platform rationalization, lower cost, less complexity, and the ability to implement real-time data use cases. However, the fact that there was still a significant part of the estate running on our old data hub meant that ideating and productionizing new data science and AI use cases remained complex and time-consuming.
A data lake-based architecture has benefits in terms of volumes of data that customers are able to ingest, process and store. However, the lack of governance and collaboration capabilities impacts the ability for companies to run data science and AI experiments and iterate quickly.
We have also seen the rise of generative AI applications, which presents a challenge in terms of implementation and deployment when we are talking about data lake estates. Here, experimenting and ideating requires constantly copying and moving data across different silos, without the proper governance and lineage. On the deployment stage, with a data lake architecture customers usually see themselves having to either keep adding multiple cloud vendor platforms or develop MLOps, deployment and serving solutions on their own - which is known as the DIY approach.
Both scenarios present different challenges. By adding multiple products from cloud vendors into a company’s architecture, customers more often than not incur high costs, high overheads and an increased need for specialized personnel - resulting in high OPEX costs. When it comes to DIY, there are significant costs both from a CAPEX and OPEX perspective. You need to first build your own MLOps and Serving capabilities - which can already be quite daunting - and once you build it, you need to keep these platforms running, not only from a platform evolution perspective but also from operational, infrastructure and security standpoints.
When we bring these challenges to the realm of generative AI and Large Language Models (LLMs), their impact becomes even more pronounced given the hardware requirements. Graphical Processing Unit cards (GPUs) have significantly higher costs compared to commoditized CPU hardware. It is thus paramount to think of an optimized way to include these resources in your data architecture. Failing to do so represents a huge cost risk to companies wanting to reap all the benefits of generative AI and LLMs; having Serverless capabilities highly mitigates these risks, while also reducing the operational overhead that is associated with maintaining such specialized infrastructure.
Why lakehouse AI?
We chose Databricks primarily because the lakehouse architecture allowed us to separate compute from storage. Databricks unified platform also enabled cross-functional easyJet teams to seamlessly collaborate on a single platform, leading to an increase in productivity.
Through our partnership with Databricks, we also have access to the most recent AI innovations - lakehouse AI - and are able to quickly prototype and experiment with our ideas together with their team of experts. “When it came to our LLM journey, working with Databricks felt like we were one big team and didn’t feel like they were just a vendor and we were a customer,” says Ben Dias, Director of Data Science and Analytics at easyJet.
Deep Dive into the Solution
The aim of this project was to provide a tool for our non-technical users to ask their questions in natural language and get insights from our rich datasets. This insight would be highly valuable in the decision-making process.
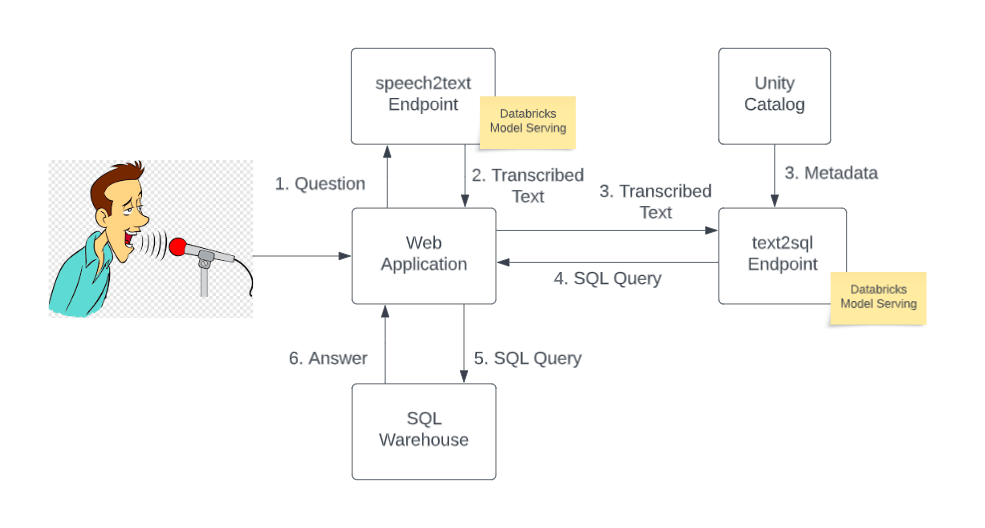
The entry point to the application is a web UI. The web UI allows users to ask questions in natural language using a microphone (e.g., their laptop’s built-in microphone). The speech is then sent to an open source LLM (Whisper) for transcription. Once transcribed, the question and the metadata of relevant tables in the Unity Catalog are put together to craft a prompt and then submitted to another open source LLM for text-to-SQL conversion. The text2sql model returns a syntactically correct SQL query which is then sent to a SQL warehouse and the answer is returned and displayed on the web UI.
To solve the text2sql task, we experimented with multiple open source LLMs. Thanks to LLMOps tools available on Databricks, in particular their integration with Hugging Face and different LLM flavors in MLflow, we found a low entry barrier to start working with LLMs. We could seamlessly swap the underlying models for this task as better open source models got released.
Both transcription and text2sql models are served at a REST API endpoint using Databricks Model Serving with support for Nvidia’s A10G GPU. As one of the first Databricks customers to leverage GPU serving, we were able to serve our models on GPU with a few clicks, going from development to production in a few minutes. Being serverless, Model Serving eliminated the need to manage complicated infrastructure and let our team focus on the business problem and massively reduced the time to market.
“With lakehouse AI, we could host open source generative AI models in our own environment, with full control. Additionally, Databricks Model Serving automated deployment and inferencing these LLMs, removing any need to deal with complicated infrastructure. Our teams could just focus on building the solution - in fact, it took us only a couple of weeks to get to an MVP.” says Ioannis Mesionis, Lead Data Scientist at easyJet.
Business Outcomes Achieved as a Result of Choosing Databricks
This project is one of the first steps in our GenAI roadmap and with Databricks we were able to get to an MVP within a couple of weeks. We were able to take an idea and transform it into something tangible our internal customers can interact with. This application paves the way for easyJet to be a truly data-driven business. Our business users have easier access to our data now. They can interact with data using natural language and can base their decisions on the insight provided by LLMs.
What’s Next for easyJet?
This initiative allowed easyJet to easily experiment and quantify the benefit of a cutting-edge generative AI use case. The solution was showcased to more than 300 people from easyJet’s IT, Data & Change department, and the excitement helped spark new ideas around innovative Gen AI use cases, such as personal assistants for travel recommendations, chatbots for operational processes and compliance, as well as resource optimization.
Once presented with the solution, easyJet’s board of executives quickly agreed that there is significant potential in including generative AI in their roadmap. As a result, there is now a specific part of the budget dedicated to exploring and bringing these use cases to life in order to augment the capabilities of both easyJet’s employees and customers, while providing them with a better, more data-driven user experience.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.