coSTAR: Como Entregamos Agentes de IA na Databricks Rapidamente, Sem Quebrar Nada
Como passamos de revisões manuais de duas semanas para teste e refinamento automatizados em horas
por Alkis Polyzotis
- Nós criamos e implantamos agentes na Databricks usando uma metodologia abrangente e automatizada de teste e refinamento, denominada coSTAR (coupled Scenario, Trace, Assess, Refine), que desenvolvemos usando MLflow. A metodologia é estruturada em torno de uma analogia com o desenvolvimento de software tradicional, usando juízes de LLM como o conjunto de testes e um assistente de codificação para refinar automaticamente a implementação do agente até que os testes passem.
- Essa metodologia eliminou o ciclo de desenvolvimento anterior, lento e manual, de "executar, revisar, corrigir, repetir", que era propenso a regressões e carecia de confiança. O coSTAR reduziu o tempo para verificar alterações de duas semanas para horas, permitindo maior velocidade de desenvolvimento.
- Os mesmos testes são executados em produção para capturar problemas no tráfego real do usuário e como parte de nossos pipelines de CI/CD, ajudando-nos a sinalizar regressões causadas por alterações na infraestrutura dependente.
Você nunca deixaria um assistente de codificação refatorar seu codebase sem um conjunto de testes. Sem testes, o assistente opera no escuro. Ele pode corrigir uma função e quebrar silenciosamente outras três. Os testes são o que fecham o ciclo: execute-os, observe as falhas, corrija o código, execute-os novamente. Sem testes, sem confiança.
Na Databricks, desenvolvemos e implantamos continuamente agentes que cobrem uma ampla gama de funcionalidades, desde novos recursos na plataforma Databricks (por exemplo, as capacidades de engenharia de dados, análise de rastros e machine learning em Genie Code), a projetos OSS (por exemplo, o assistente MLflow), a fluxos de trabalho de engenharia internos (por exemplo, suporte on-call ou revisores de código automatizados). Esses agentes podem executar tarefas de longa duração, gerar milhares de linhas de código e criar novos ativos de dados e IA, entre outras coisas. Embora tivéssemos algumas verificações básicas implementadas no início, faltava o tipo de conjunto de testes abrangente e automatizado que nos permitiria iterar com confiança. Este post descreve como fechamos essa lacuna usando MLflow e a metodologia coSTAR (coupled Scenario, Trace, Assess, Refine) de melhores práticas que construímos em torno dela. coSTAR executa dois loops acoplados: um que alinha os juízes com o julgamento de especialistas humanos para que possam ser confiáveis, e um que usa esses juízes confiáveis para refinar automaticamente o agente até que ele passe em todos os cenários de teste.
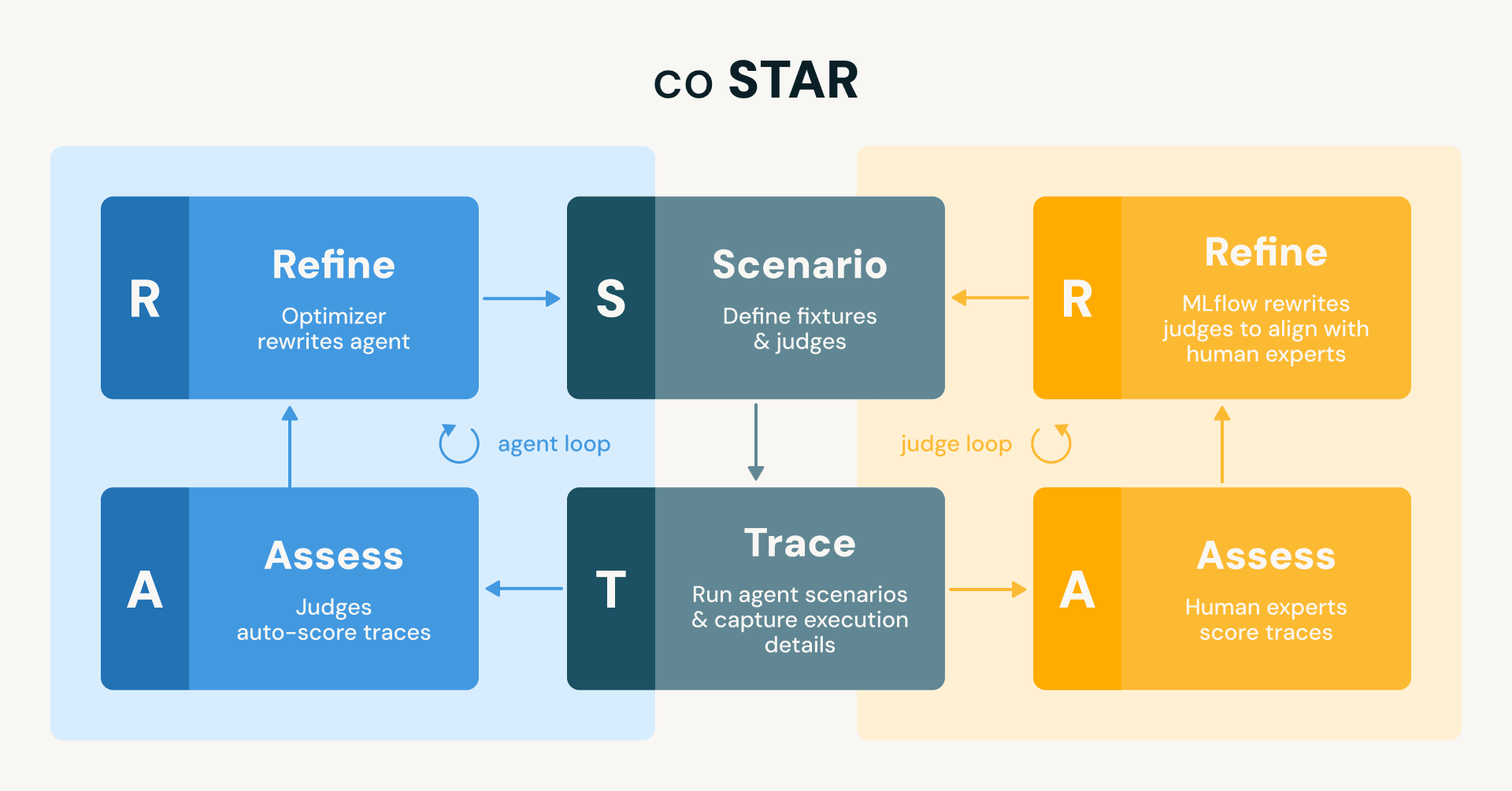
Figura: O framework coSTAR executa dois loops STAR espelhados (Scenario → Trace → Assess → Refine). O loop do agente (azul) usa juízes para pontuar automaticamente os rastros e refina o agente para se alinhar com os juízes. O loop do juiz (laranja) usa especialistas humanos para pontuar os rastros e refina os juízes para se alinharem com suas avaliações. Ambos os loops compartilham os mesmos cenários e rastros.
O Problema: Codificação Sem Testes
No início, nosso loop de desenvolvimento era assim: executar o agente, revisar manualmente sua saída, identificar uma falha, instruir um assistente de codificação a corrigi-la. Repetir.
Se isso te lembra de escrever código sem testes e fazer controle de qualidade manual de cada alteração, é exatamente isso que era. E falhou exatamente da maneira que você preveria. A reação óbvia é "então escreva testes". Mas o teste de agente é estruturalmente diferente de testar uma função determinística, e vários desafios se acumulam ao mesmo tempo:
- Não determinismo. A mesma implementação, a mesma entrada, pode produzir saídas diferentes em execuções diferentes. Os testes precisam avaliar propriedades da saída em vez de afirmar saídas exatas.
- Loops de feedback lentos. Uma única execução de agente pode levar dezenas de minutos. Não há iteração da maneira que um conjunto de testes de subsegundo permite. Cada ciclo de avaliação é caro.
- Erros em cascata. Uma decisão errada na etapa 3 causa uma falha na etapa 7. Quando o sintoma aparece, a causa raiz está enterrada várias etapas atrás na execução do agente.
- Qualidade subjetiva. Para muitas dimensões de teste (este código de engenharia de recursos é bom? esta abordagem de limpeza de dados é apropriada?) não há verdade fundamental. Julgar essas dimensões depende de conhecimento de domínio.
Essas restrições moldaram todas as decisões de design que se seguem. Elas também são o que torna este problema interessante: não estamos apenas construindo um executor de testes, estamos construindo uma metodologia de otimização automatizada para processos estocásticos, de longa duração e multi-etapas onde "correto" é uma questão de julgamento.
A Analogia Que Guia Nossa Abordagem
Se você apertar os olhos, o desenvolvimento de agentes se alinha perfeitamente com o loop de desenvolvimento que todo engenheiro já conhece:
| Software tradicional | Desenvolvimento de agente |
|---|---|
| Código fonte | Implementação do agente (incluindo prompts, escolhas de FMs, ferramentas) |
| Conjunto de testes | Juízes LLM |
| Test fixtures (configuração, entrada, saída esperada) | Definições de cenário (estado inicial, prompt, expectativas) |
| Test runner / harness | O harness de teste executa o agente em teste, produz rastros |
| Correção de teste (os testes verificam a coisa certa?) | Alinhamento do juiz (o juiz concorda com especialistas humanos?) |
| Assistente de codificação corrige o código até que os testes passem | Assistente de codificação refina a implementação até que os juízes passem |
| CI executa todos os testes em cada alteração | CI executa cenários + juízes em cada alteração |
| Monitoramento de produção | Os mesmos juízes são executados em tráfego ao vivo |
Essa analogia não é apenas ilustrativa. É a arquitetura literal do nosso sistema, que chamamos de coSTAR: dois loops coupled que usam definições de Scenario como fixtures de teste, captura de Trace como o harness de teste, Assess com juízes como o conjunto de testes e Refine como o loop vermelho-verde. Vamos analisar cada peça.
S - Definições de Cenário
Em testes tradicionais, um fixture de teste configura as pré-condições: criar um banco de dados, popular com dados, configurar o ambiente. Nosso equivalente é uma definição de cenário: uma descrição estruturada do estado inicial, o prompt do usuário e os resultados esperados.
Aqui está um cenário simplificado para testar um agente de Analista de Dados contra um conjunto de dados confuso:
Cada cenário agrupa a configuração, a entrada e os critérios de sucesso em um só lugar, assim como um fixture de teste. Mantemos um conjunto desses cenários em diferentes agentes, cobrindo casos comuns, casos extremos e falhas passadas conhecidas. O conjunto cresce ao longo do tempo à medida que descobrimos novos modos de falha: cada bug que encontramos em produção se torna um novo cenário, da mesma forma que cada bug de produção deve se tornar um teste de regressão.
Por que se preocupar com essa estrutura? Porque as execuções de agentes são caras. Um único cenário leva minutos para ser executado. Precisamos ser deliberados sobre o que testamos, e precisamos que as definições de cenário sejam portáteis: o mesmo cenário pode ser executado contra diferentes implementações de agente ou diferentes versões do mesmo agente.
T - Captura de Rastro
Para executar nosso conjunto de testes, usamos um harness que envia o prompt de cada cenário para o agente em teste (AUT). Cada execução é capturada como um rastro do MLflow: um log estruturado de cada chamada de ferramenta, cada saída intermediária e cada artefato que o agente produz. Pense nisso como um gravador de voo: ele captura tudo o que o agente fez, em ordem, para que possamos inspecionar qualquer parte da execução posteriormente.
Uma decisão arquitetônica chave: nós desacoplamos a execução da pontuação. O harness de teste produz rastros; os juízes (que introduziremos a seguir) os pontuam. Estas são etapas separadas. Ao persistir os rastros, podemos iterar nos juízes sem reexecutar os cenários. Ajustar um limite? Repontuar os rastros gravados em segundos. Adicionar um novo juiz? Executá-lo contra todos os rastros que você já coletou. Suspeita que um juiz está errado? Compare seus vereditos com as gravações e depure-o offline. Uma execução cara do agente produz dados que são reutilizados várias vezes, incluindo como candidatos para o Conjunto Dourado que usaremos para alinhar os juízes mais tarde.
A - Avaliar com Juízes
Os juízes operam em rastros e raciocinam sobre as propriedades da execução: o agente produziu código válido? A saída atendeu a um limite de qualidade? O agente seguiu o processo correto? Como mencionado anteriormente, essa avaliação é diferente dos testes unitários tradicionais: a saída do agente é não determinística e rica, e, portanto, afirmar saídas exatas é essencialmente inútil.
A abordagem padrão para implementar esses juízes é "LLM-como-Juiz": alimente o rastro completo para um modelo e peça uma pontuação e, igualmente importante, uma justificativa para essa pontuação. No entanto, isso é como escrever um teste que despeja todo o estado do programa em uma asserção. É caro, frágil e difícil de depurar. Para nossos agentes, um único rastro pode ter milhares de linhas de comprimento. Colocá-lo na janela de contexto de um juiz degrada a qualidade do julgamento.
Em vez disso, usamos os juízes agenticos do MLflow: juízes que são eles próprios agentes, equipados com ferramentas para explorar o rastro seletivamente. Assim como um teste bem escrito chama uma função específica e verifica um valor de retorno específico, um juiz agentico chama uma ferramenta específica no rastro e verifica uma propriedade específica.
Aqui estão alguns exemplos de juízes que usamos em nossos agentes:
Juiz de invocação de habilidade explora o rastro e identifica se o agente invocou habilidades que são o alvo do cenário (se não, então o propósito da habilidade não é claro para o AUT):
Juiz de melhores práticas explora se a saída segue as melhores práticas de acordo com a documentação oficial da Databricks:
Juiz de Resultado inspeciona o trace em busca de ativos de saída e afirma certas propriedades. Voltando ao exemplo do Analista de Dados, identifique a parte do trace onde o código de engenharia foi criado e avalie se o código é apropriado para a tarefa em questão:
Este juiz é interessante porque aborda o problema subjetivo da qualidade de frente: o que conta como boa engenharia de features depende do conhecimento do domínio. Um juiz LLM não consegue acertar isso de imediato. É tentador tentar escrever todos os critérios na instrução do juiz: "prefira imputação de mediana em vez de média para distribuições assimétricas, sempre escale features antes de modelos baseados em distância, ..." Mas codificar o julgamento completo de um especialista de domínio em uma instrução é trabalhoso e frágil. É muito mais fácil para os humanos olharem para um exemplo e dizerem "isso é bom" ou "isso é ruim" do que escrever a especificação completa. É exatamente por isso que o alinhamento funciona, como veremos em breve.
Em geral, nosso conjunto de testes para um único agente inclui juízes em várias categorias:
Verificações determinísticas, coisas que podemos verificar mecanicamente, sem necessidade de LLM:
- Verificação de sintaxe/linting no código gerado
- Validação do schema de saída (as tabelas esperadas existem? os tipos de coluna estão corretos?)
- Verificação de sequência de ferramentas (o agente leu os logs de erro antes de tentar corrigir o problema, ou foi direto para a edição do código?)
Verificações baseadas em LLM, decisões que exigem compreensão do contexto:
- Diretrizes de diff de código (o agente alterou linhas não relacionadas? introduziu APIs obsoletas?)
- Aderência às melhores práticas (o código gerado segue as convenções para este domínio?)
Métricas operacionais, sinais que não passam/falham individualmente, mas monitoram a saúde ao longo do tempo:
- Uso de tokens (altas contagens de tokens geralmente sinalizam que o agente está com dificuldades, tentando novamente, voltando atrás ou andando em círculos)
- Contagens de chamadas de ferramentas e taxas de falha (um pico em chamadas de ferramentas falhas indica que algo está errado)
- Latência (tempo de relógio para o agente concluir a tarefa)
As métricas operacionais merecem uma nota. Elas não bloqueiam uma liberação da forma como os juízes de aprovação/rejeição fazem, mas são críticas para o gerenciamento de custos e alerta precoce. Se o uso de tokens dobrar após uma mudança, algo deu errado mesmo que todos os juízes ainda passem; o agente provavelmente está fazendo mais trabalho do que deveria. Monitoramos isso ao longo do tempo e alertamos sobre anomalias.
Expandindo o conjunto de testes ao longo do tempo
Conjuntos de testes não são criados em uma única sessão. Eles evoluem com o tempo. Começam com as verificações mais simples que fornecem um sinal: a saída existe? Ela é analisável? Em seguida, vêm as verificações estruturais: a saída tem o schema correto, as colunas corretas, os tipos corretos? Só mais tarde vêm os juízes de validação de dados de ponta a ponta: a saída realmente produz resultados corretos quando executada?
Isso espelha como os conjuntos de testes amadurecem no software tradicional. Testes de integração exaustivos não vêm no primeiro dia. Começa com testes de fumaça, depois testes unitários à medida que os modos de falha surgem, construindo cobertura de ponta a ponta ao longo do tempo. A chave é que a infraestrutura suporta a adição de novos juízes de forma barata, para que o conjunto de testes cresça junto com o agente.
Testando os Testes: Alinhamento de Juízes
Aqui está um problema que todo engenheiro conhece: um conjunto de testes instável ou incorreto que aprova código ruim envia bugs com confiança. Da mesma forma, juízes que aprovam resultados ruins dão uma falsa sensação de segurança. É aqui que entra o segundo loop do framework coSTAR: os mesmos cenários e traces que impulsionam o refinamento do agente também impulsionam o refinamento do juiz, com pontuações de especialistas humanos como a verdade fundamental. Isso é importante porque, ao contrário dos testes tradicionais onde a correção dos testes pode ser verificada por inspeção, os juízes LLM são estocásticos e podem variar em como interpretam critérios de linguagem natural. Portanto, precisamos de uma maneira de verificá-los e mantê-los alinhados com especialistas humanos.
Para fazer esse alinhamento, primeiro curamos um Conjunto Dourado de tipicamente dezenas de exemplos de saídas de agentes que nossos engenheiros avaliaram manualmente. Esta é a verdade fundamental com a qual os juízes devem concordar. Em seguida, aproveitamos as capacidades de alinhamento do MLflow (potencializadas por técnicas como GEPA e MemAlign) para refinar automaticamente o juiz contra o Conjunto Dourado. Observe que isso é estruturalmente o mesmo loop STAR que usamos para refinar o próprio AUT, mas a etapa de avaliação é realizada por especialistas humanos e a etapa de refinamento se aplica ao juiz.
R - Refinar
Com juízes que o loop de juízes alinhou contra o julgamento de especialistas humanos, podemos agora confiar no loop do agente. Um assistente de codificação trata o agente como seu codebase e os juízes como seu conjunto de testes. Ele lê falhas, diagnostica as causas raiz, corrige o agente e reexecuta tudo. O engenheiro ainda é o revisor e árbitro final das mudanças propostas para o agente, mas essa iteração automatizada economiza um esforço humano considerável na análise e melhoria do agente.
Aqui está o que uma iteração parecia para o agente Analista de Dados:
Vermelho. Executamos a versão inicial do agente contra nosso conjunto de cenários. O juiz de melhores práticas sinalizou uma discrepância: nosso agente estava gerando código para visualizações lógicas que era diferente de nossas recomendações/documentação oficial. Embora essa discrepância não afetasse a correção, ela tinha implicações na manutenção e implantação do código gerado. Este é um exemplo de uma regressão insidiosa que seria difícil de capturar por investigação manual.
Verde. O assistente de codificação analisou o feedback do juiz e identificou a lacuna: o agente estava usando uma habilidade que não era prescritiva sobre o tipo de visualizações que deveriam ser criadas (temporárias vs. permanentes). Após adicionar a orientação relevante à habilidade, os testes passaram com sucesso e a mudança foi verificada como não introduzindo outras regressões (com base em outros cenários de teste).
Testes de Regressão para Infraestrutura, Não Apenas para o Agente
Até agora, descrevemos os juízes como testes para o agente, capturando regressões quando a implementação do agente muda. Mas, na prática, o próprio agente não é a única coisa que muda. O agente depende de ferramentas e infraestrutura externas, e essas também mudam.
Nossos agentes chamam ferramentas MCP, interfaces padronizadas para acesso a dados, execução de código, configuração de ambiente e muito mais. Essas ferramentas têm suas próprias equipes de desenvolvimento e ciclos de lançamento. Quando uma ferramenta muda sua implementação (por exemplo, uma ferramenta de execução de código começa a retornar stderr em um formato diferente, ou uma ferramenta de acesso a dados muda como lida com valores nulos) o agente não mudou nada, mas o comportamento do agente pode quebrar.
Como executamos nossos juízes em cada build noturno, eles agem como testes de regressão contra toda a pilha, não apenas a implementação atual do agente. Quando uma equipe de ferramentas envia uma mudança que faz com que um agente comece a falhar em seus juízes, pegamos o erro imediatamente, antes que ele chegue aos clientes. Mais importante ainda, a falha do juiz nos diz o que quebrou (a dimensão de qualidade específica que regrediu), o que torna muito mais fácil triar se a causa raiz está no agente ou em uma ferramenta da qual o agente depende.
Este é o mesmo valor que os testes de integração fornecem no software tradicional: eles protegem o contrato entre o código e suas dependências. A única diferença é que aqui, o "código" é um agente e as "dependências" são ferramentas MCP.
De Avaliação a Monitoramento de Produção
Há mais uma extensão da analogia de testes que se mostrou surpreendentemente valiosa: executar os mesmos juízes em tráfego de produção.
No software tradicional, os testes não param na CI. A produção também é monitorada: taxas de erro, percentis de latência, métricas de negócios em tráfego ao vivo. A mesma lógica de teste que valida o código em desenvolvimento geralmente reaparece como verificações de integridade e alertas em produção.
Fazemos o mesmo. Os juízes que construímos para avaliação são projetados para pontuar qualquer conversa de agente, não apenas cenários de avaliação. Portanto, os executamos (ou um subconjunto amostrado) em conversas de produção reais. Isso nos dá:
- Alerta precoce sobre desvios. Se a taxa de aprovação dos juízes cair em conversas de produção, algo mudou. Talvez uma atualização de modelo tenha degradado a qualidade, talvez os prompts do usuário tenham mudado de uma forma que o agente lida mal. Vemos isso nas pontuações dos juízes antes de vermos reclamações de usuários.
- Sinal do mundo real para o conjunto de testes. Conversas de produção que os juízes marcam como falhas se tornam candidatas a novos cenários de avaliação. É assim que o conjunto de testes cresce organicamente: falhas reais retornam à avaliação, fechando o loop entre produção e desenvolvimento.
- Monitoramento de custos no nível do agente. Monitoramos o uso de tokens e as contagens de chamadas de ferramentas em conversas de produção. Uma mudança neutra em termos de qualidade que triplica o custo ainda é uma regressão.
O insight principal é que a mesma infraestrutura de pontuação (juízes, métricas, traces registradas) serve a um propósito duplo. Construa-a uma vez para avaliação e o monitoramento de produção se torna um efeito colateral.
Onde Estamos Agora
Adotamos essa metodologia em vários agentes que lançamos na plataforma Databricks (por exemplo, as capacidades de Engenharia de Dados, Machine Learning e Análise de Traces no Genie), agentes internos para produtividade do desenvolvedor, bem como outros agentes voltados para o cliente (por exemplo, AI Dev Kit, ou o Assistente MLflow OSS). No geral, vimos benefícios tangíveis:
- Comparado com avaliações manuais, os conjuntos de testes automatizados reduziram o tempo para verificar alterações de 2 semanas para horas. Consequentemente, isso permitiu que nossas equipes entregassem melhorias com maior velocidade.
- Vários conjuntos de testes cresceram para centenas de cenários de teste por agente, aumentando nossa confiança em detectar regressões.
- Testes de integração sinalizaram alterações na infraestrutura dependente, o que nos permitiu evitar regressões em produção. Exemplos dessas alterações incluem comportamento de gerenciamento de TODO no modelo subjacente, alterações que impactam a latência ou alterações no modelo.
O MLflow também tem sido fundamental como plataforma de teste GenAI, ajudando nossos engenheiros a padronizar a metodologia, acelerar o desenvolvimento de testes e compartilhar as melhores práticas entre as equipes.
O Que Não Funciona (Ainda)
A analogia de teste também é útil aqui. Nossas limitações se mapeiam em problemas de teste familiares:
A geração de cenários é manual (escrever casos de teste é caro). Automatizamos a pontuação, o alinhamento e a otimização, mas a geração dos cenários em si ainda é uma tarefa humana. Cada cenário requer a criação de um estado inicial realista, um prompt significativo e expectativas corretas. Este é o gargalo que limita o tamanho do conjunto de testes, e um conjunto de testes restrito leva diretamente ao próximo problema. A automação da geração de cenários (sintetizando casos de teste diversos e realistas a partir de padrões de tráfego de produção ou da especificação do agente) é uma área ativa de trabalho para nós.
O assistente de codificação pode ter overfitting (conjunto de testes muito restrito). Se o conjunto de testes não cobrir casos suficientes, o assistente de codificação criará uma implementação de agente que se sai bem com essas entradas específicas, mas falha em novas. Este é o equivalente do agente de escrever código que passa em testes unitários, mas falha em produção. Mitigamos isso alimentando falhas de produção de volta para a avaliação e expandindo a cobertura ao longo do tempo, mas até que a geração de cenários seja automatizada, o conjunto de testes cresce mais lentamente do que gostaríamos.
O alinhamento do juiz é caro (calibrar testes requer trabalho humano). Construir o Conjunto Dourado requer que especialistas no domínio avaliem manualmente as saídas, o gargalo exato que estamos tentando eliminar. E não é um custo único: à medida que os agentes evoluem, os juízes precisam de recalibração. Estamos investigando maneiras de tornar isso mais inteligente medindo a incerteza do juiz, identificando os exemplos específicos onde o juiz está subespecificado e um rótulo humano resolveria a ambiguidade. O objetivo é o aprendizado ativo para alinhamento do juiz: em vez de pedir aos especialistas para avaliar uma amostra aleatória, apresentamos apenas os exemplos onde o juiz está incerto e a entrada de um especialista no domínio aprimoraria seus critérios ao máximo.
Falhas em várias etapas são difíceis de atribuir (análise de causa raiz). Quando um agente falha na etapa 7 de um pipeline de 10 etapas, a causa raiz foi na etapa 7 ou na etapa 3? Nossos juízes detectam o sintoma, mas o assistente de codificação às vezes corrige a etapa errada, como corrigir uma falha de teste alterando a função errada. Uma melhor rastreabilidade causal é uma área ativa de trabalho.
Novos modos de falha passam despercebidos (lacunas de cobertura). O coSTAR otimiza dentro das dimensões que os juízes cobrem. Se uma nova classe de falha surgir para a qual nenhum juiz verifica, ela é invisível, assim como um bug em um código que nenhum teste exercita. O coSTAR melhora *dentro* de seu conjunto de testes, mas não pode expandir o conjunto de testes por conta própria. Os humanos ainda precisam notar novos modos de falha e adicionar juízes.
Principais Conclusões
- O desenvolvimento de agentes tem um problema de teste. Sem avaliação automatizada, você está codificando sem testes e terá as regressões que merece.
- Dê ferramentas aos juízes, não traces. Um juiz agentivo que chama ferramentas direcionadas é como um teste unitário focado. Despejar o trace completo em um juiz é como despejar o estado do programa em uma asserção. Não escala.
- Teste seus testes. Juízes LLM são estocásticos. Alinhe-os contra conjuntos dourados avaliados por humanos da mesma forma que você validaria um conjunto de testes contra uma especificação.
- Feche o ciclo. A verdadeira vitória é o ciclo coSTAR completo: cenários confiáveis, traces registrados, juízes alinhados e um assistente de codificação que refina o agente até que os testes passem. A avaliação sem refinamento automatizado é apenas metade da história.
- Construa uma vez, monitore em todos os lugares. Os mesmos juízes que validam na avaliação podem monitorar a produção. Um investimento, dois retornos.
- O acoplamento é crítico. Refinar o agente é tão confiável quanto os juízes que o dirigem. Os dois loops acoplados do coSTAR — um que ganha confiança nos juízes, outro que usa essa confiança para refinar o agente — são o que tornam o refinamento automatizado significativo, em vez de apenas rápido.
Estamos construindo o coSTAR como parte do MLflow. Se você está enfrentando problemas semelhantes, adoraríamos saber.
- Experimente o Genie Code para ver a funcionalidade que lançamos usando a metodologia coSTAR.
- Siga os tutoriais no MLflow para começar a definir e usar juízes LLM para refinamento iterativo de agentes.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.