coSTAR: How we ship AI agents at Databricks fast, without breaking things
How we went from two-week manual reviews to automated test-and-refine in hours
- We build and deploy agents at Databricks using a comprehensive, automated testing and refinement methodology termed coSTAR (coupled Scenario, Trace, Assess, Refine) which we developed using MLflow. The methodology is structured around an analogy to traditional software development, using LLM judges as the test suite and a coding assistant to automatically refine the agent implementation until the tests pass.
- This methodology has eliminated the prior slow, manual "run, review, fix, repeat" development loop, which was prone to regressions and lacked confidence. coSTAR has reduced the time to verify changes from two weeks down to hours, enabling higher development velocity.
- The same tests run in production to catch problems on actual user traffic, and as part of our CI/CD pipelines, helping us flag regressions caused by changes in dependent infrastructure.
You'd never let a coding assistant refactor your codebase without a test suite. Without tests, the assistant flies blind. It might fix one function and silently break three others. The tests are what close the loop: run them, observe failures, fix the code, run them again. No tests, no confidence.
At Databricks we continuously develop and deploy agents that cover a wide range of functionality, from new features in the Databricks platform (e.g., the data-engineering, trace analysis, and machine learning capabilities in Genie Code), to OSS projects (e.g., the MLflow assistant), to internal engineering workflows (e.g., on-call support or automated code reviewers). These agents can perform long-running tasks, generate thousands of lines of code, and create new data and AI assets among other things. While we had some basic checks in place early on, we lacked the kind of comprehensive, automated test suite that would let us iterate with confidence. This post describes how we closed that gap using MLflow, and the best-practices coSTAR (coupled Scenario, Trace, Assess, Refine) methodology we built around it. coSTAR runs two coupled loops: one that aligns judges with human expert judgment so they can be trusted, and one that uses those trusted judges to automatically refine the agent until it passes all test scenarios.
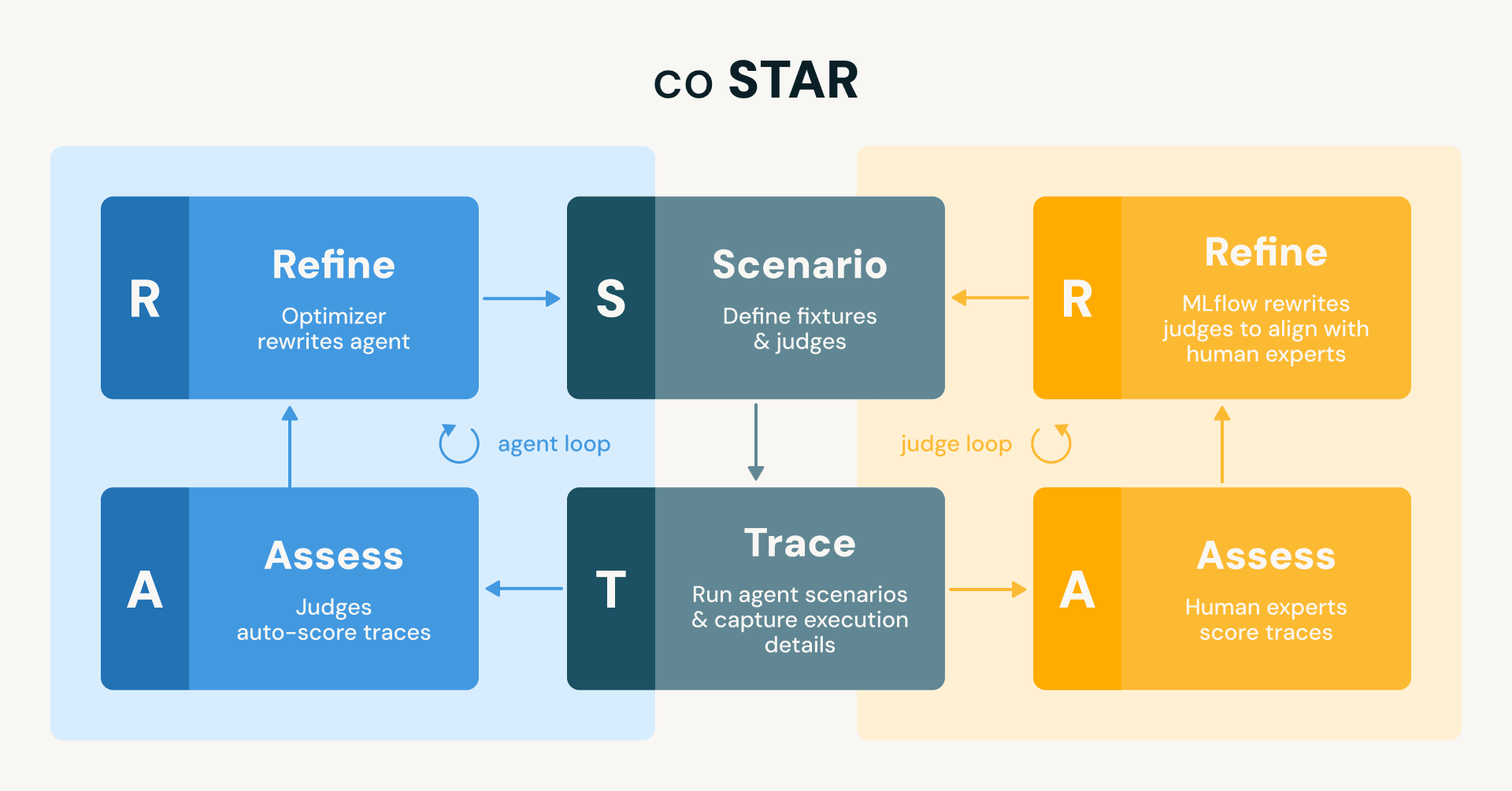
Figure: The coSTAR framework runs two mirrored STAR loops (Scenario → Trace → Assess → Refine) . The agent loop (blue) uses judges to auto-score traces and refines the agent to align with judges. The judge loop (orange) uses human experts to score traces and refines the judges to align with their assessments. Both loops share the same scenarios and traces.
The Problem: Coding Without Tests
Early on, our development loop looked like this: run the agent, manually review its output, spot a flaw, tell a coding assistant to fix it. Repeat.
If this reminds you of writing code without tests and manually QA-ing every change, that's exactly what it was. And it failed in exactly the way you'd predict. The obvious reaction is "so write tests." But agent testing is structurally different from testing a deterministic function, and several challenges compound at once:
- Non-determinism. The same implementation, the same input, can produce different outputs on different runs. Tests need to evaluate properties of the output rather than assert exact outputs.
- Slow feedback loops. A single agent execution can take tens of minutes. There's no iterating the way a sub-second test suite allows. Every evaluation cycle is expensive.
- Cascading errors. A bad decision at step 3 causes a failure at step 7. By the time the symptom surfaces, the root cause is buried several steps back in the agent's execution.
- Subjective quality. For many testing dimensions (is this feature engineering code any good? is this data cleaning approach appropriate?) there's no ground truth. Judging these dimensions depends on domain expertise.
These constraints shaped every design decision that follows. They're also what makes this problem interesting: we're not just building a test runner, we're building a automated optimization methodology for stochastic, long-running, multi-step processes where "correct" is a judgment call.
The Analogy That Guides Our Approach
If you squint, agent development maps cleanly onto the dev loop that every engineer already knows:
| Traditional software | Agent development |
|---|---|
| Source code | Agent implementation (including prompts, choices of FMs, tools) |
| Test suite | LLM judges |
| Test fixtures (setup, input, expected output) | Scenario definitions (initial state, prompt, expectations) |
| Test runner / harness | Test harness executes the agent under test, produces traces |
| Test correctness (do tests check the right thing?) | Judge alignment (does the judge agree with human experts?) |
| Coding assistant fixes code until tests pass | Coding assistant refines implementation until judges pass |
| CI runs all tests on every change | CI runs scenarios + judges on every change |
| Production monitoring | Same judges run on live traffic |
This analogy isn't just illustrative. It's the literal architecture of our system, which we call coSTAR: two coupled loops that use Scenario definitions as test fixtures, Trace capture as the test harness, Assess with judges as the test suite, and Refine as the red-green loop. Let's walk through each piece.
S - Scenario Definitions
In traditional testing, a test fixture sets up the preconditions: create a database, seed it with data, configure the environment. Our equivalent is a scenario definition: a structured description of the initial state, the user prompt, and the expected outcomes.
Here's a simplified scenario for testing a Data Analyst agent against a messy dataset:
Each scenario bundles the setup, the input, and the success criteria in one place, just like a test fixture. We maintain a suite of these across different agents, covering common cases, edge cases, and known past failures. The suite grows over time as we discover new failure modes: every bug we find in production becomes a new scenario, the same way every production bug should become a regression test.
Why bother with this structure? Because agent runs are expensive. A single scenario takes minutes to execute. We need to be deliberate about what we test, and we need the scenario definitions to be portable: the same scenario can run against different agent implementations or different versions of the same agent.
T - Trace Capture
To run our test suite, we use a harness that sends each scenario's prompt to the agent under test (AUT). Each execution is captured as a MLflow trace: a structured log of every tool call, every intermediate output, and every artifact the agent produces. Think of it as a flight recorder: it captures everything the agent did, in order, so we can inspect any part of the execution after the fact.
A key architectural decision: we decouple execution from scoring. The test harness produces traces; the judges (which we'll introduce next) score them. These are separate steps. By persisting traces, we can iterate on judges without re-running scenarios. Adjust a threshold? Re-score the recorded traces in seconds. Add a new judge? Run it against every trace you've ever collected. Suspect a judge is wrong? Compare its verdicts against the recordings and debug it offline. One expensive agent run produces data that gets reused many times, including as candidates for the Golden Set we'll use to align judges later.
A - Assess with Judges
Judges operate on traces and reason about properties of the execution: did the agent produce valid code? Did the output meet a quality threshold? Did the agent follow the right process? As mentioned earlier, this evaluation is different from traditional unit tests: agent output is non-deterministic and rich, and so asserting exact outputs is essentially useless.
The standard approach to implementing these judges is "LLM-as-a-Judge": feed the full trace to a model and ask for a score and equally importantly a rationale for that score. However, that's like writing a test that dumps the entire program state into an assertion. It's expensive, fragile, and hard to debug. For our agents, a single trace can be thousands of lines long. Stuffing it into a judge's context window degrades judgment quality.
Instead, we use MLflow’s agentic judges: judges that are themselves agents, equipped with tools to explore the trace selectively. Just like a well-written test calls a specific function and checks a specific return value, an agentic judge calls a specific tool on the trace and checks a specific property.
Here are some example judges that we have used across our agents:
Skill invocation judge explores the trace and identifies whether the agent invoked skills that are targeted by the scenario (if not, then the skill’s purpose is not clear to the AUT):
Best-practices judge explores whether the output follows best practices according to Databricks official documentation:
Outcome Judge inspects the trace for output assets and asserts certain properties. Going back to the Data Analyst example, identify the part of the trace where engineering code was authored and evaluate whether the code is appropriate for the task at hand:
This judge is interesting because it tackles the subjective quality problem head-on: what counts as good feature engineering depends on domain expertise. An LLM judge can't get this right out of the box. It's tempting to try writing out the complete criteria in the judge's prompt: "prefer median imputation over mean for skewed distributions, always scale features before distance-based models, ..." But encoding a domain expert's full judgment into a prompt is laborious and brittle. It's much easier for humans to look at an example and say "this is good" or "this is bad" than to write out the complete spec. This is exactly why alignment works, as we'll cover shortly.
In general, our test suite for a single agent includes judges across several categories:
Deterministic checks, things we can verify mechanically, no LLM needed:
- Syntax/linting on generated code
- Output schema validation (do expected tables exist? are column types correct?)
- Tool sequence linting (did the agent read the error logs before trying to fix the issue, or did it skip straight to editing code?)
LLM-based checks, judgment calls that require understanding context:
- Code diff guidelines (did the agent change unrelated lines? did it introduce deprecated APIs?)
- Best practice adherence (is the generated code following the conventions for this domain?)
Operational metrics, signals that don't pass/fail individually but track health over time:
- Token usage (high token counts often signal the agent is struggling, retrying, backtracking, or going in circles)
- Tool call counts and failure ratios (a spike in failed tool calls indicates something is wrong)
- Latency (wall-clock time for the agent to complete the task)
The operational metrics deserve a note. They don't gate a release the way pass/fail judges do, but they're critical for cost management and early warning. If token usage doubles after a change, something went wrong even if all judges still pass; the agent is probably doing more work than it should. We track these over time and alert on anomalies.
Growing the test suite over time
Test suites don't get authored in one sitting. They evolve over time. They start with the simplest checks that give a signal: does the output exist? Does it parse? Then structural checks follow: does the output have the right schema, the right columns, the right types? Only later come end-to-end data validation judges: does the output actually produce correct results when you run it?
This mirrors how test suites mature in traditional software. Exhaustive integration tests don't come on day one. It starts with smoke tests, then unit tests as failure modes emerge, building toward end-to-end coverage over time. The key is that the infrastructure supports adding new judges cheaply, so the test suite grows alongside the agent.
Testing the Tests: Judge Alignment
Here's a problem every engineer knows: a flaky or wrong test suite that greenlights bad code ships bugs with confidence. Similarly, judges who approve poor outcomes give a false sense of security. This is where the second loop of the coSTAR framework comes in: the same scenarios and traces that drive agent refinement also drive judge refinement, with human expert scores as the ground truth. This matters because, unlike traditional testing where test correctness can be verified by inspection, LLM judges are stochastic and can drift in how they interpret natural-language criteria. So we need a way to verify them and keep them aligned with human experts.
To do this alignment, we first curate a Golden Set of typically dozens of examples of agent outputs that our engineers have manually assessed. This is the ground truth the judges must agree with. Then we leverage MLflow's alignment capabilities (powered by techniques like GEPA and MemAlign) to automatically refine the judge against the Golden Set. Notice this is structurally the same STAR loop we use to refine the AUT itself, but the assess step is performed by human experts and the refine step applies to the judge.
R - Refine
With judges that the judge loop has aligned against human expert judgment, we can now trust the agent loop. A coding assistant treats the agent as its codebase and the judges as its test suite. It reads failures, diagnoses root causes, patches the agent, and re-runs everything. The engineer is still the reviewer and final arbiter of the proposed changes to the agent, but this automated iteration saves considerable human effort in analyzing and improving the agent.
Here's what one iteration looked like for the Data Analyst agent:
Red. We ran the initial version of the agent against our scenario suite. The best-practices judge flagged a discrepancy: our agent was generating code for logical views that was different from our official recommendations/documentation. While this discrepancy would not affect correctness, it had implications on the maintenance and deployment of the generated code. This is an example of an insidious regression that would be hard to catch by manual investigation.
Green. The coding assistant analyzed the judge feedback and identified the gap: the agent was using a skill that was not prescriptive about the type of views that should be created (temporary vs permanent). After adding the relevant guidance to the skill, the tests passed successfully and the change was verified to not introduce other regression (based on other test scenarios).
Regression Tests for Infrastructure, Not Just the Agent
So far we've described judges as tests for the agent, catching regressions when the agent implementation changes. But in practice, the agent itself isn't the only thing that changes. The agent depends on external tools and infrastructure, and those change too.
Our agents call MCP tools, standardized interfaces for data access, code execution, environment setup, and more. These tools have their own development teams and release cycles. When a tool changes its implementation (say, a code execution tool starts returning stderr in a different format, or a data access tool changes how it handles null values) the agent hasn't changed at all, but the agent's behavior can break.
Because we run our judges on every nightly build, they act as regression tests against the full stack, not just the agent’s current implementation. When a tool team ships a change that causes an agent to start failing its judges then we catch the error immediately, before it reaches customers. More importantly, the judge's failure tells us what broke (the specific quality dimension that regressed), which makes it far easier to triage whether the root cause is in the agent or in a tool the agent depends on.
This is the same value that integration tests provide in traditional software: they guard the contract between the code and its dependencies. The only difference is that here, the "code" is an agent and the "dependencies" are MCP tools.
From Eval to Production Monitoring
There's one more extension of the testing analogy that turned out to be surprisingly valuable: running the same judges on production traffic.
In traditional software, testing doesn't stop at CI. Production gets monitored too: error rates, latency percentiles, business metrics on live traffic. The same test logic that validates code in dev often reappears as health checks and alerts in prod.
We do the same thing. The judges we built for eval are designed to score any agent conversation, not just eval scenarios. So we run them (or a sampled subset) on real production conversations. This gives us:
- Early warning on drift. If judge's pass rate drops on production conversations, something changed. Maybe a model upgrade degraded quality, maybe user prompts shifted in a way the agent handles poorly. We see it in the judge scores before we see it in user complaints.
- Real-world signal for the test suite. Production conversations that judges flag as failures become candidates for new eval scenarios. This is how the test suite grows organically: real failures feed back into eval, closing the loop between production and development.
- Cost monitoring at the agent level. We track token usage and tool call counts on production conversations. A quality-neutral change that triples cost is still a regression.
The key insight is that the same scoring infrastructure (judges, metrics, recorded traces) serves double duty. Build it once for eval, and production monitoring comes as a side effect.
Where We Are Now
We have adopted this methodology across several agents that we have released in the Databricks platform (e.g., the Data Engineering, Machine Learning, and Trace analysis capabilities in Genie), internal agents for developer productivity, as well as other customer-facing agents (e.g., AI Dev Kit, or the OSS MLflow Assistant). Overall we have seen tangible benefits:
- Compared to manual evals, the automated test suites have reduced the time to verify changes from 2 weeks down to hours. Accordingly, this has enabled our teams to ship improvements with higher velocity.
- Several test suites have grown to hundreds of test scenarios per agent, increasing our confidence in catching regressions.
- Integration tests flagged changes in dependent infrastructure which allowed us to prevent regressions in production. Examples of these changes include TODO management behavior in the underlying model, latency-impacting changes, or model changes.
MLflow has also been instrumental as a GenAI testing platform, helping our engineers standardize on the methodology, accelerate the development of tests, and share best practices across teams.
What Doesn't Work (Yet)
The testing analogy is useful here too. Our limitations map onto familiar testing problems:
Scenario generation is manual (writing test cases is expensive). We've automated scoring, alignment, and optimization, but generating the scenarios themselves is still a human task. Each scenario requires crafting realistic initial state, a meaningful prompt, and correct expectations. This is the bottleneck that limits test suite size, and a narrow test suite leads directly to the next problem. Automating scenario generation (synthesizing diverse, realistic test cases from production traffic patterns or from the agent’s specification) is an active area of work for us.
The coding assistant can overfit (test suite too narrow). If the test suite doesn't cover enough cases, the coding assistant will engineer an agent implementation that aces those specific inputs but fails on novel ones. This is the agent equivalent of writing code that passes unit tests but breaks in production. We mitigate this by feeding production failures back into eval and expanding coverage over time, but until scenario generation is automated, the test suite grows slower than we'd like.
Judge alignment is expensive (calibrating tests requires human labor). Building the Golden Set requires domain experts to manually grade outputs, the exact bottleneck we're trying to eliminate. And it's not a one-time cost: as agents evolve, judges need recalibration. We're investigating ways to make this smarter by measuring judge uncertainty, identifying the specific examples where the judge is underspecified and a human label would actually resolve ambiguity. The goal is active learning for judge alignment: instead of asking experts to grade a random sample, surface only the examples where the judge is uncertain and a domain expert's input would sharpen its criteria the most.
Multi-step failures are hard to attribute (root cause analysis). When an agent fails at step 7 of a 10-step pipeline, was the root cause at step 7 or step 3? Our judges catch the symptom but the coding assistant sometimes patches the wrong step, like fixing a test failure by changing the wrong function. Better causal tracing is an active area of work.
Novel failure modes slip through (coverage gaps). coSTAR optimizes within the dimensions the judges cover. If a new class of failure emerges that no judge checks for, it's invisible, just like a bug in code that no test exercises. coSTAR improves within its test suite, but it can't expand the test suite on its own. Humans still need to notice new failure modes and add judges.
Key Takeaways
- Agent development has a testing problem. Without automated evaluation, you're coding without tests, and you'll get the regressions you deserve.
- Give judges tools, not traces. An agentic judge that calls targeted tools is like a focused unit test. Dumping the full trace into a judge is like dumping program state into an assertion. It doesn't scale.
- Test your tests. LLM judges are stochastic. Align them against human-graded golden sets the same way you'd validate a test suite against a specification.
- Close the loop. The real win is the full coSTAR loop: trusted scenarios, recorded traces, aligned judges, and a coding assistant that refines the agent until the tests pass. Evaluation without automated refinement is only half the story.
- Build once, monitor everywhere. The same judges that validate in eval can monitor production. One investment, two returns.
- Couping is critical. Refining the agent is only as reliable as the judges driving it. coSTAR's two coupled loops — one that earns trust in the judges, one that uses that trust to refine the agent — are what make automated refinement meaningful rather than just fast.
We're building coSTAR as part of MLflow. If you're tackling similar problems, we'd love to hear about it.
- Try out Genie Code to see the functionality we shipped using the coSTAR methodology.
- Follow the tutorials on MLflow to get started on defining and using LLM judges for iterative agent refinement.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.