Modelagem de Dados no Databricks Lakehouse: Mitos, Verdades e Melhores Práticas
A maturidade da modelagem de dados, combinada com novos recursos, reduziu a lacuna na maioria dos recursos que faltavam nos data warehouses empresariais tradicionais
por Shannon Barrow e Kyle Hale
- Modelos relacionais e dimensionais prosperam no Delta Lake com ACID, Photon e views de métricas.
- Chaves, restrições e camadas semânticas têm suporte.
- Novos recursos, como transações de múltiplas instruções e Liquid Clustering, simplificam o desempenho.
Os data warehouses há muito tempo são valorizados por sua estrutura e rigor, mas muitos supõem que um lakehouse sacrifica essa disciplina. Aqui, desfazemos dois mitos relacionados: o de que o Databricks abandona a modelagem relacional e o de que não oferece suporte a chaves ou restrições. Você verá que princípios fundamentais como chaves, restrições e imposição de esquema continuam sendo cidadãos de primeira classe no Databricks SQL. Assista à sessão completa do DAIS 2025 aqui →
Os data warehouses modernos evoluíram, e o Databricks Lakehouse é um excelente exemplo dessa evolução. Nos últimos quatro anos, milhares de organizações migraram seus data warehouses legados para o Databricks lakehouse, obtendo acesso a uma plataforma unificada que combina perfeitamente data warehousing, transmissão analítica e recursos de AI. No entanto, alguns recursos e capacidades dos data warehouses clássicos não são pilares dos data lakes. Este blog desmistifica mitos persistentes sobre modelagem de dados e fornece práticas recomendadas adicionais para operacionalizar seu Lakehouse moderno na cloud.
Este guia abrangente aborda os mitos mais comuns sobre a funcionalidade de data warehousing da Databricks e apresenta os novos e poderosos recursos anunciados no Data + AI Summit 2025. Quer você seja um arquiteto de dados avaliando opções de plataforma ou um engenheiro de dados implementando soluções de lakehouse, esta publicação fornecerá a você o entendimento definitivo dos recursos de modelagem de dados de nível empresarial da Databricks.
- Mito nº 1: "O Databricks não oferece suporte à modelagem relacional."
- Mito nº 2: "Você não pode usar chaves primárias e estrangeiras."
- Mito nº 3: "Restrições de qualidade de dados no nível da coluna são impossíveis."
- Mito n.º 4: "Não é possível fazer modelagem semântica sem ferramentas de BI proprietárias."
- Mito n.º 5: "Você não deveria criar modelos dimensionais no Databricks."
- Mito nº 6: "Você precisa de um mecanismo separado para o desempenho de BI."
- Mito nº 7: A arquitetura do medalhão "é necessária"
- BÔNUS: Mito nº 8: "O Databricks não oferece suporte a transações de múltiplas instruções."
A evolução do data warehouse para o lakehouse
Antes de mergulhar nos mitos, é fundamental entender o que diferencia a arquitetura lakehouse das abordagens tradicionais de data warehousing. O lakehouse combina a confiabilidade e o desempenho dos data warehouses com a flexibilidade e a escala dos data lakes, criando uma plataforma unificada que elimina os trade-offs tradicionais entre o processamento de dados estruturados e não estruturados.
Recursos do Databricks SQL:
- Armazenamento de dados unificado em armazenamento de objetos em cloud de baixo custo com formatos abertos
- Garantias de transações ACID com o Delta Lake
- Otimização avançada de query com o mecanismo Photon
- Governança abrangente com o Unity Catalog
- Suporte nativo para workloads de SQL e machine learning
Essa arquitetura aborda as limitações fundamentais das abordagens tradicionais e, ao mesmo tempo, mantém a compatibilidade com as ferramentas e práticas existentes.
Mito 1: "O Databricks não oferece suporte para modelagem relacional"
Fato: os princípios relacionais são fundamentais para o Lakehouse
Talvez o mito mais difundido seja o de que o Databricks abandona os princípios de modelagem relacional. Isso não poderia estar mais longe da verdade. O termo "lakehouse" enfatiza explicitamente o componente "house" – uma gestão de dados estruturada e confiável que se baseia em décadas de teoria comprovada de bancos de dados relacionais.
O Delta Lake, a camada de armazenamento subjacente a todas as tabelas do Databricks, oferece suporte completo para:
- Transações ACID garantem a consistência dos dados
- Imposição de esquema e evolução, mantendo a integridade de dados
- Operações compatíveis com SQL, incluindo joins complexos e funções analíticas
- Conceitos de integridade referencial por meio de definições de chaves primárias e estrangeiras (esses conceitos são para o desempenho da query, mas não são impostos)
Recursos modernos, como as views de métricas do Unity Catalog, agora em visualização pública, dependem inteiramente de modelos relacionais bem estruturados para funcionar com eficácia. Essas camadas semânticas exigem dimensões e tabelas de fatos adequadas para fornecer métricas de negócios consistentes em toda a organização.
O mais importante é que os modelos de AI e do machine learning, também conhecidos como abordagens "schema-on-read", têm o melhor desempenho com dados tabulares, limpos e estruturados que seguem princípios relacionais. O Lakehouse não abandona a estrutura; ele a torna mais flexível e escalável.
Mito nº 2: "Você não pode usar keys primárias e estrangeiras"
**Verdade: o Databricks tem suporte robusto a restrições com benefícios de otimização**
O Databricks oferece suporte a restrições de chave primária e estrangeira desde o Databricks Runtime 11.3 LTS, com Disponibilidade Geral completa a partir do Runtime 15.2. Essas restrições servem a vários propósitos críticos:
- Restrições informacionais que documentam os relacionamentos de dados, com restrições de integridade referencial aplicáveis no roteiro. As organizações que planejam suas migrações para o lakehouse devem projetar agora seus modelos de dados com os relacionamentos de key adequados para aproveitar esses recursos à medida que eles se tornarem disponíveis.
- Dicas de otimização de query:Para organizações que gerenciam a integridade referencial em seus pipelines de ETL, a palavra-chave`RELY`fornece uma poderosa dica de otimização. Quando você declara `FOREIGN KEY ... RELY`, você está informando ao otimizador do Databricks que ele pode assumir com segurança a integridade referencial, permitindo otimizações de query agressivas que podem melhorar drasticamente o desempenho do join.
- Compatibilidade de ferramentas com plataformas de BI como Tableau e Power BI que detectam e utilizam automaticamente esses relacionamentos
Mito n.º 3: "Restrições de qualidade de dados no nível da coluna são impossíveis"
Verdade: o Databricks oferece aplicação abrangente da qualidade dos dados
A qualidade dos dados é fundamental nas plataformas de dados corporativos, e a Databricks oferece várias camadas de aplicação de restrições que vão além do que os data warehouses tradicionais oferecem.
As mais comuns são simples Restrições SQL nativas, incluindo:
- Restrições CHECK para validação de regras de negócio personalizadas
- Restrições NOT NULL para validação de campos obrigatórios
Além disso, o Databricks oferece Soluções Avançadas de Qualidade de Dados que vão além das restrições básicas para fornecer monitoramento da qualidade dos dados de nível empresarial.
Lakehouse Monitoring oferece acompanhamento automatizado da qualidade dos dados com:
- Perfilamento estatístico e detecção de drift
- Definições de métricas personalizadas e alertas
- Integração com o Unity Catalog para governança
- Dashboards de qualidade de dados tempo-real
Databricks Labs DQX biblioteca oferece:
- Regras personalizadas de qualidade de dados para tabelas Delta
- Validações no nível do DataFrame durante o processamento
- Estrutura extensível para verificações de qualidade complexas
Essas ferramentas combinadas fornecem recursos de qualidade de dados que superam os sistemas de restrição de data warehouse tradicionais, oferecendo controles preventivos e de detecção em todo o seu pipeline de dados.
Mito nº 4: "Você não pode fazer modelagem semântica sem ferramentas de BI proprietárias"
Verdade: as views de métricas do Unity Catalog revolucionam o gerenciamento da camada semântica
Um dos anúncios mais importantes no Data + AI Summit 2025 foi o anúncio da prévia pública do Unity Catalog Views de Métricas, uma abordagem revolucionária para a modelagem semântica que elimina a dependência de fornecedores.
As Views de Métricas do Unity Catalog permitem que você centralize a lógica de negócios:
- Defina as métricas uma vez no nível do catálogo
- Acesse de qualquer lugar – Dashboards, Notebooks, SQL, ferramentas AI
- Manter a consistência em todos os pontos de consumo
- Versionar e governar como qualquer outro ativo de dados
Diferentemente das camadas semânticas de BI proprietárias, as Métricas do Unity Catalog são abertas e acessíveis:
- Endereçável por SQL - query-os como qualquer tabela ou view
- Independente de ferramenta – funciona com qualquer plataforma de BI ou ferramenta analítica
- Pronto para AI – acessível a LLMs e agentes de AI por meio de linguagem natural
Essa abordagem representa uma mudança fundamental de camadas semânticas específicas de ferramentas de BI para uma base semântica unificada, governada e aberta que potencializa a analítica em toda a sua organização.
Mito n.º 5: "Você não deve criar modelos dimensionais no Databricks"
Verdade: Os princípios da modelagem dimensional prosperam no Lakehouse
Longe de desencorajar a modelagem dimensional, o Databricks adota e otimiza ativamente esses padrões analíticos comprovados. Os esquemas estrela e floco de neve se traduzem excepcionalmente bem em tabelas Delta, muitas vezes oferecendo características de desempenho superiores em comparação com os data warehouses tradicionais. Esses padrões aceitos de modelagem dimensional oferecem:
- Compreensão de negócios – padrões familiares para analistas e usuários de negócios
- Desempenho de query – otimizado para cargas de trabalho analíticas e ferramentas de BI
- dimensões que mudam lentamente (SCD) – fáceis de implementar com os recursos de viagem do tempo do Delta Lake
- Agregações escaláveis – views materializadas e processamento incremental
Além disso, o Databricks Lakehouse oferece benefícios exclusivos para a modelagem dimensional, incluindo evolução do esquema e integração com a viagem do tempo. Para ter a melhor experiência usando a modelagem dimensional no Databricks, siga estas práticas recomendadas:
- Use o namespace de três níveis do Unity Catalog (catalog.schema.table) para organizar seus modelos dimensionais
- Implemente restrições de chave primária e estrangeira adequadas para documentação e otimização
- Aproveite as colunas de identidade para geração de key substituta
- Aplique clusters líquidos em colunas unidas com frequência
- Use views materializadas para tabelas de fatos pré-agregadas
Mito nº 6: "Você precisa de um mecanismo separado para o desempenho de BI"
Verdade: O Lakehouse oferece desempenho de BI de classe mundial nativamente
A ideia equivocada de que as arquiteturas lakehouse não conseguem igualar o desempenho dos data warehouses tradicionais para cargas de trabalho de BI está cada vez mais ultrapassada. A Databricks investiu muito na otimização do desempenho de querys, entregando resultados que superam consistentemente os data warehouses MPP tradicionais.
A base das otimizações de desempenho do Databricks é o Photon Engine, que é projetado especificamente para workloads OLAP e queries analíticas.
- Execução vetorizada para operações analíticas complexas
- Pushdown de predicado avançado minimizando a movimentação de dados
- Eliminação inteligente de dados aproveitando as estruturas do modelo dimensional
- Processamento colunar otimizado para agregações e join
Além disso, o Databricks SQL oferece uma experiência de warehouse serverless totalmente gerenciada que é dimensionada automaticamente para cargas de trabalho de BI de alta simultaneidade e se integra perfeitamente às ferramentas populares de BI. Nossos serverless warehouses combinam o melhor TCO e desempenho da categoria para oferecer tempos de resposta ideais para suas consultas analíticas. Os benefícios fundamentais do Delta Lake, ou seja, as otimizações de arquivos, a coleta de estatísticas avançadas e o clustering de dados no formato de dados parquet aberto e eficiente, são frequentemente ignorados nos últimos anos. Os benefícios de desempenho resultantes que as organizações que migram de data warehouses tradicionais para Databricks relatam consistentemente:
- Desempenho de query até 10 a 50 vezes mais rápido para cargas de trabalho analíticas complexas
- Escalabilidade de alta simultaneidade sem degradação de desempenho
- Redução de custos de até 90% em comparação com os data warehouses MPP tradicionais
- Zero sobrecarga de manutenção com compute serverless
Data + AI Summit 2025 trouxe anúncios e otimizações ainda mais empolgantes, incluindo otimização preditiva aprimorada e clusters líquidos automáticos.
Mito nº 7: A arquitetura do medalhão "é necessária"
Verdade: O medalhão é uma diretriz, não um requisito rígido
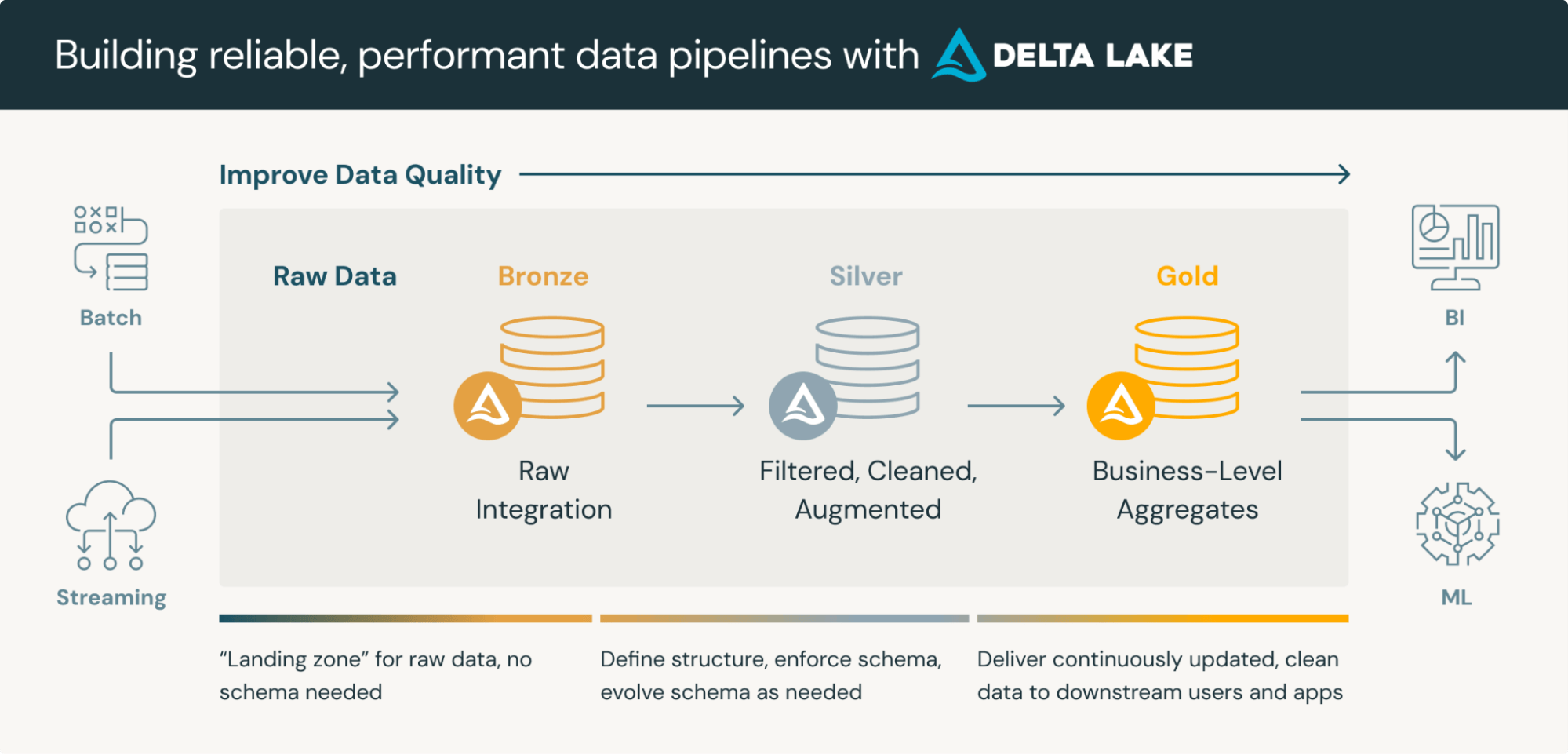
Então, o que é uma arquitetura medalhão? Uma arquitetura medalhão é um padrão de design de dados usado para organizar logicamente os dados em um lakehouse, com o objetivo de melhorar incremental e progressivamente a estrutura e a qualidade dos dados à medida que fluem por cada camada da arquitetura (das tabelas da camada Bronze ⇒ Prata ⇒ Ouro). Embora a arquitetura medalhão, também conhecida como arquitetura "multi-hop", forneça uma estrutura excelente para organizar dados em um lakehouse, é essencial entender que se trata de uma arquitetura de referência, e não de uma estrutura obrigatória. A chave para a modelagem no Databricks é manter a flexibilidade ao modelar a complexidade do mundo real, o que pode adicionar ou até remover camadas da arquitetura medalhão, conforme necessário.
Muitas implementações bem-sucedidas do Databricks podem até combinar abordagens de modelagem. O Databricks é capaz de uma infinidade de Abordagens de Modelagem Híbrida para acomodar Data Vault, esquemas estrela, floco de neve ou Camadas Específicas de Domínio para lidar com modelos de dados específicos das indústrias (ou seja, saúde, serviços financeiros, varejo).
O key é usar a arquitetura medalhão como ponto de partida e adaptá-la às necessidades específicas da sua organização, mantendo os princípios essenciais de refinamento progressivo de dados e melhoria da qualidade. Existem muitos fatores organizacionais que influenciam sua Arquitetura Lakehouse, e a implementação deve ocorrer após uma análise cuidadosa de:
- Tamanho e complexidade da empresa - organizações maiores geralmente precisam de mais camadas
- Requisitos regulatórios – as necessidades de compliance podem ditar controles adicionais
- Padrões de uso - a analítica em tempo real ou em lotes afeta o design da camada
- Estrutura da equipe – limites entre as equipes de engenharia de dados e de analítica
Mito BÔNUS nº 8: "O Databricks não oferece suporte a transações com várias instruções"
Truth: Recursos avançados de transação já estão disponíveis
Uma das lacunas de capacidade entre os data warehouses tradicionais e as plataformas lakehouse tem sido o suporte a transações de múltiplas tabelas e múltiplas instruções. Isso mudou com o anúncio de Transações de Múltiplas Instruções no Data + AI Summit 2025. Com a adição de MSTs, agora em Private Preview, o Databricks oferece:
- Transações multiformato em tabelas Delta Lake e Apache Iceberg™
- Atomicidade de múltiplas tabelas garante a semântica de tudo ou nada
- Consistência de várias declarações com recursos completos de reversão
- Transações entre catálogos que abrangem diferentes fontes de dados

A abordagem do Databricks oferece vantagens significativas em comparação com seus equivalentes de data warehouse tradicionais:
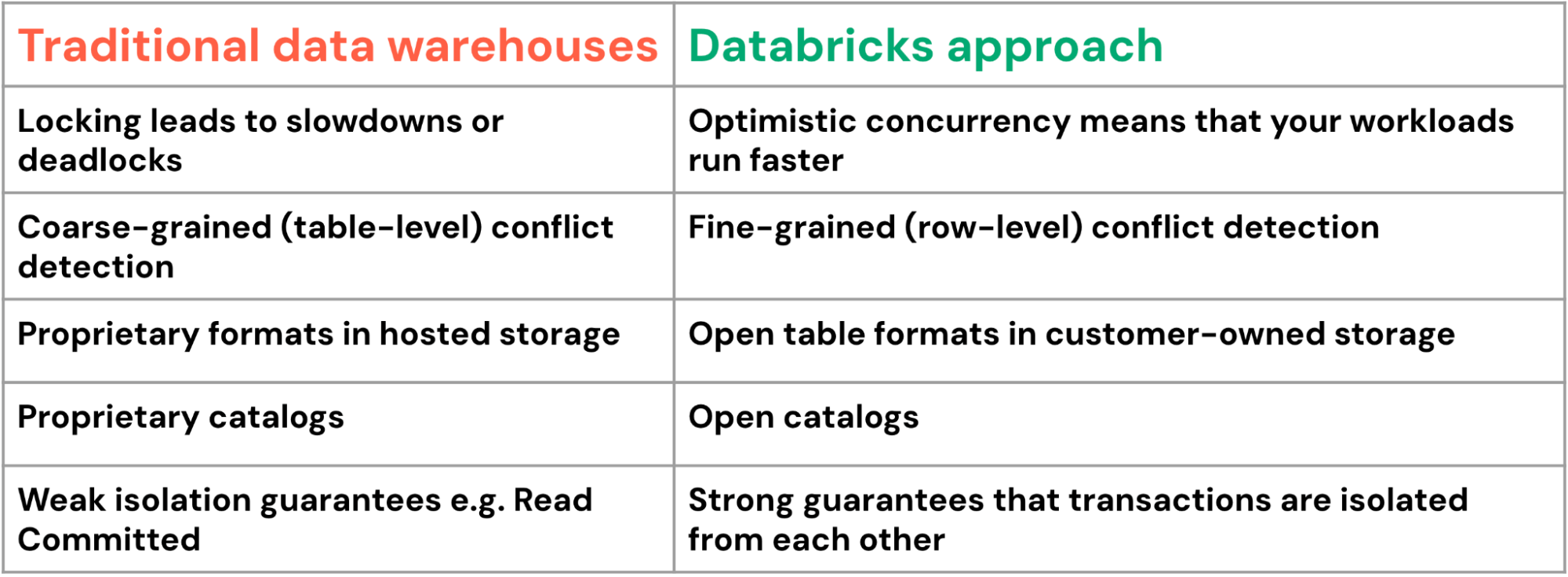
As transações de múltiplas instruções são atraentes para processos de negócios complexos, como o gerenciamento da cadeia de suprimentos, onde as atualizações de centenas de tabelas relacionadas devem manter uma consistência perfeita. As transações de múltiplas instruções permitem padrões poderosos:
Atualizações consistentes em várias tabelas
Orquestração complexa de pipelines de dados
Conclusão: Adotando o data warehouse moderno
Os avanços tecnológicos e as implementações do mundo real desmistificaram completamente os mitos em torno das capacidades de data warehousing do Databricks. A plataforma não só oferece suporte a conceitos tradicionais de data warehousing, como também os aprimora com recursos modernos que superam as limitações dos sistemas legados.
Para organizações que estão avaliando ou implementando o Databricks para data warehousing:
- Comece com padrões comprovados: Implemente modelos dimensionais e princípios relacionais que sua equipe entenda
- Aproveite as otimizações modernas: Use Liquid clustering, Predictive Optimization e Unity Catalog métricas para obter um desempenho superior.
- Projete para escalabilidade: Crie modelos de dados que possam crescer com sua organização e se adaptar às mudanças de requisitos
- Adote a governança: Implemente controles de acesso abrangentes e acompanhamento de linhagem desde o primeiro dia.
- Planeje a integração da AI: Projete seu data warehouse para dar suporte a futuras iniciativas de AI e machine learning
O Databricks Lakehouse representa a próxima evolução do data warehousing, combinando a confiabilidade e o desempenho das abordagens tradicionais com a flexibilidade e a escala necessárias para a analítica moderna e a AI. Os mitos que antes questionavam suas capacidades foram substituídos por resultados comprovados e inovação contínua.
À medida que avançamos para um futuro cada vez mais orientado por AI, as organizações que adotam a arquitetura Lakehouse estarão mais bem posicionadas para extrair valor de seus dados, responder às mudanças nos requisitos de negócios e fornecer soluções de analítica inovadoras que geram vantagem competitiva.
A questão não é mais se o Lakehouse pode substituir os data warehouses tradicionais — é a rapidez com que você pode começar a perceber seus benefícios para a gestão de dados corporativos.
A arquitetura Lakehouse combina abertura, flexibilidade e total confiabilidade transacional — uma combinação que os data warehouses legados têm dificuldade em alcançar. Da arquitetura medalhão a modelos específicos de domínio e de atualizações de tabela única a transações de múltiplas instruções, o Databricks oferece uma base que cresce com o seu negócio.
Pronto para transformar seu data warehouse? O melhor data warehouse é um lakehouse! Para saber mais sobre o Databricks SQL, faça um tour pelo produto. Acesse databricks.com/sql para explorar o Databricks SQL e ver como organizações do mundo todo estão revolucionando suas plataformas de dados.
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.