Lakehouse Monitoring: uma solução unificada para a qualidade dos dados e IA
Introdução
Databricks Data Quality Monitoring permite que você monitore todos os seus pipelines de dados — de dados a recursos e modelos de ML — sem ferramentas e complexidade adicionais. Integrado ao Unity Catalog, você pode acompanhar a qualidade juntamente com a governança e obter insights detalhados sobre o desempenho dos seus ativos de dados e IA. O Lakehouse Monitoring é totalmente serverless, então você nunca precisa se preocupar com infraestrutura ou com o ajuste da configuração de compute.
Nossa abordagem única e unificada de monitoramento simplifica o acompanhamento da qualidade, o diagnóstico de erros e a busca por soluções diretamente na Databricks Data Intelligence Platform. Continue lendo para descobrir como você e sua equipe podem aproveitar ao máximo o Lakehouse Monitoring.
Por que o Lakehouse Monitoring?
Imagine o seguinte cenário: seu pipeline de dados parece estar funcionando sem problemas, apenas para descobrir que a qualidade dos dados se degradou silenciosamente com o tempo. É um problema comum entre engenheiros de dados: tudo parece bem até que alguém reclame que os dados estão inutilizáveis.
Para vocês que treinam modelos de ML, acompanhar o desempenho dos modelos em produção e comparar diferentes versões é um desafio constante. Consequentemente, as equipes se deparam com modelos que se tornam obsoletos em produção e têm a tarefa de revertê-los.
A ilusão de pipelines funcionais que mascaram a deterioração da qualidade dos dados torna desafiador para as equipes de dados e AI cumprirem os SLAs de entrega e qualidade. O Lakehouse Monitoring pode ajudar você a descobrir proativamente problemas de qualidade antes que os processos posteriores sejam afetados. Você pode se antecipar a possíveis problemas, garantindo que os pipelines funcionem sem problemas e que os modelos do machine learning permaneçam eficazes ao longo do tempo. Chega de passar semanas depurando e revertendo alterações!
Como funciona

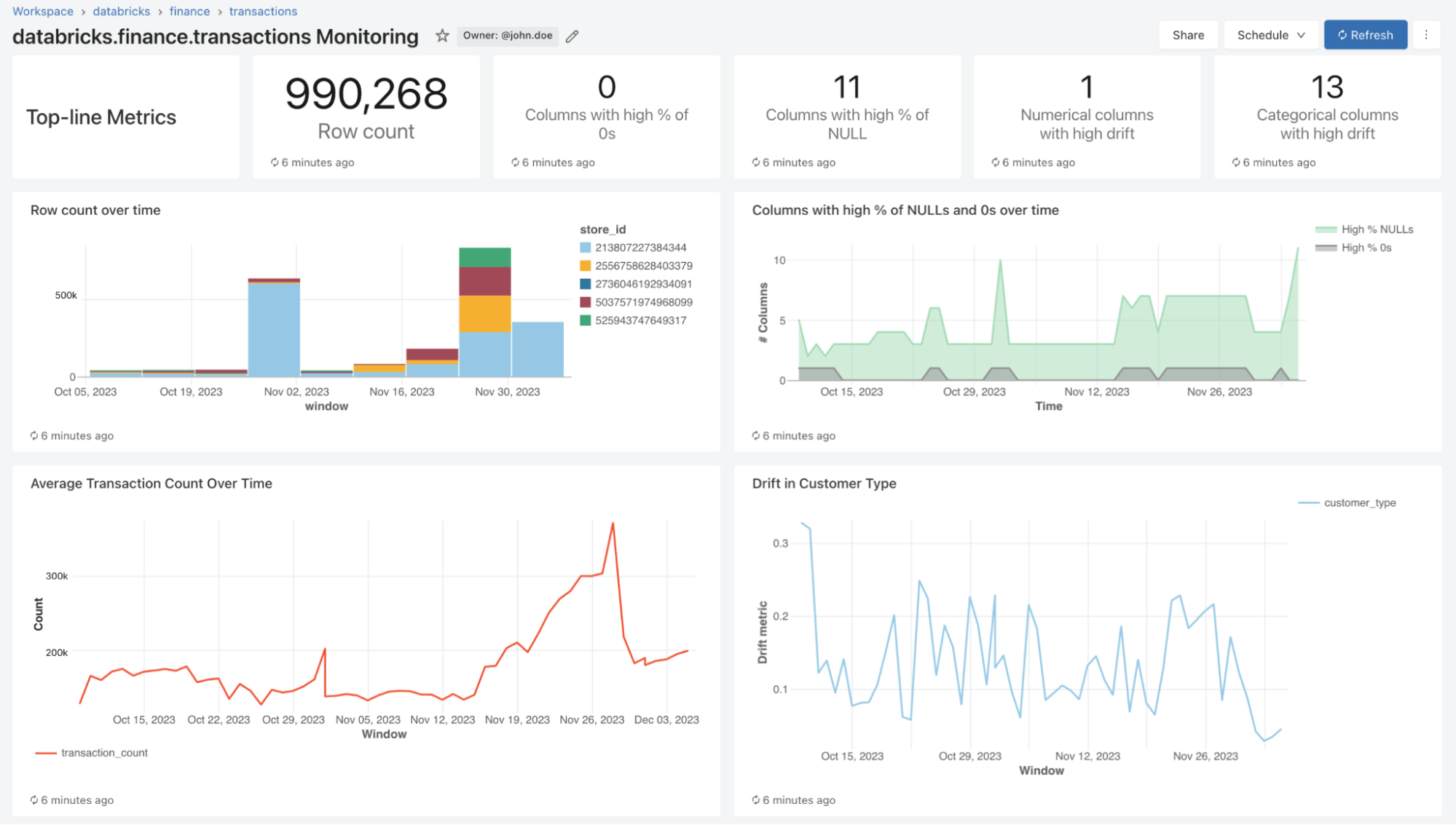
Com o Lakehouse Monitoring, você pode monitorar as propriedades estatísticas e a qualidade de todas as suas tabelas com apenas um clique. Geramos automaticamente um dashboard que visualiza a qualidade dos dados para qualquer tabela Delta no Unity Catalog. Nosso produto computa um rico conjunto de métricas prontas para uso. Por exemplo, se você estiver monitorando uma tabela de inferência, fornecemos métricas de desempenho do modelo, como R-quadrado, acurácia etc. Como alternativa, para quem monitora tabelas de engenharia de dados, fornecemos métricas de distribuição, incluindo média, mín./máx. etc. Além das métricas integradas, você também pode configurar métricas personalizadas (específicas do negócio) que deseja que calculemos. O Lakehouse Monitoring atualiza as métricas e mantém o dashboard atualizado de acordo com o cronograma especificado. Todas as métricas são armazenadas em tabelas Delta para permitir análises ad hoc, visualizações personalizadas e alertas.
Configure o monitoramento
Você pode configurar o monitoramento em qualquer tabela de sua propriedade usando a UI do Databricks (AWS | Azure) ou a API (AWS | Azure). Selecione o tipo de perfil de monitoramento que você deseja em seus pipelines de dados ou modelos:
- Perfil de Snapshot: Se você quiser monitorar a tabela completa ao longo do tempo ou comparar os dados atuais com versões anteriores ou uma linha de base conhecida, um Perfil de Snapshot será a melhor opção. Calcularemos as métricas com base em todos os dados da tabela e as atualizaremos sempre que o monitor for atualizado.
- Perfil de série temporal: Se sua tabela contiver carimbos de data/hora de eventos e você quiser comparar distribuições de dados em janelas de tempo (por hora, dia, semana...), um perfil de série temporal funcionará melhor. Recomendamos que você ative o Change Data Feed (AWS | Azure) para que você possa obter o processamento incremental toda vez que o monitor for atualizado. Observação: você precisará de uma coluna de carimbo de data/hora para configurar este perfil.
- Perfil de log de inferência: se você quiser comparar o desempenho do modelo ao longo do tempo ou acompanhar como as entradas e previsões do modelo mudam com o tempo, um perfil de inferência é a melhor opção. Você precisará de uma tabela de inferência (AWS | Azure) que contenha entradas e saídas de um modelo de classificação ou regressão de ML. Você também pode, opcionalmente, incluir rótulos de ground truth para calcular o drift e outros metadados, como informações demográficas, para obter métricas de justiça e viés.
Você pode escolher a frequência com que deseja que nosso serviço de monitoramento seja executado. Muitos clientes escolhem uma programação diária ou de hora em hora para garantir que seus dados estejam sempre atualizados e relevantes. Se você quiser que o monitoramento seja executado automaticamente no final da execução do pipeline de dados, também poderá chamar a API para refresh o monitoramento diretamente em seu Fluxo de Trabalho.
Para personalizar ainda mais o monitoramento, você pode definir expressões de fatiamento para monitorar subconjuntos de recursos da tabela, além da tabela como um todo. Você pode fatiar qualquer coluna específica, por exemplo, etnia, gênero, para gerar métricas de justiça e viés. Você também pode definir métricas personalizadas com base nas colunas da sua tabela principal ou com base nas métricas prontas para uso. Consulte como usar métricas personalizadas (AWS | Azure) para obter mais detalhes.
Visualize a qualidade
Como parte de um refresh, verificaremos suas tabelas e modelos para gerar métricas que acompanham a qualidade ao longo do tempo. Calculamos dois tipos de métricas que armazenamos em tabelas Delta para você:
- Métricas de perfil: Elas fornecem estatísticas resumidas de seus dados. Por exemplo, você pode acompanhar o número de nulos e zeros em sua tabela ou as métricas de acurácia do seu modelo. Consulte o esquema da tabela de métricas de perfil (AWS | Azure) para mais informações.
- Métricas de Drift: Elas fornecem métricas estatísticas de drift que permitem a comparação com suas tabelas de referência. Consulte o esquema da tabela de métricas de drift (AWS | Azure) para mais informações.
Para visualizar todas essas métricas, o Lakehouse Monitoring oferece um dashboard pronto para uso e totalmente personalizável. Você também pode criar alertas do Databricks SQL (AWS | Azure) para ser notificado sobre violações de thresholds, alterações na distribuiç�ão de dados e drift da sua tabela de referência.
Configuração de alertas
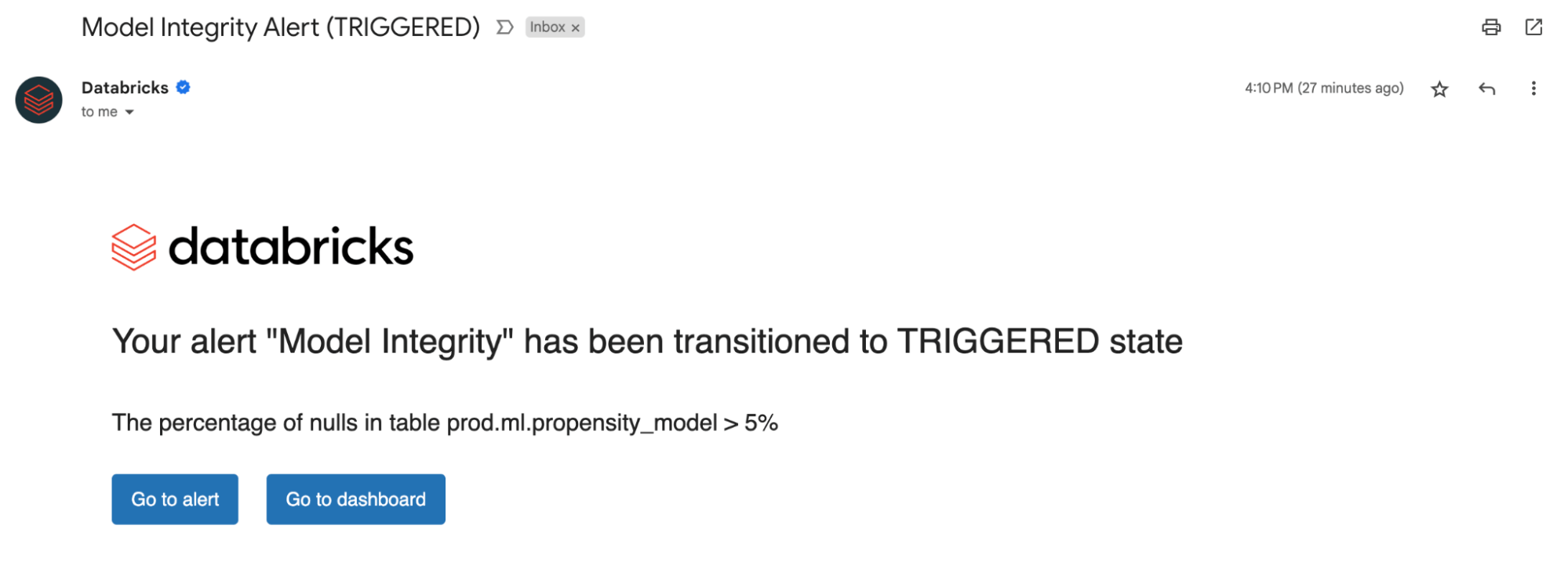
Seja no monitoramento de tabelas de dados ou modelos, a configuração de alertas em nossas métricas calculadas notifica sobre possíveis erros e ajuda a prevenir riscos downstream.
Você pode receber alertas se a porcentagem de nulos e zeros exceder um determinado limite ou sofrer alterações ao longo do tempo. Se você estiver monitorando modelos, poderá receber um alerta se as métricas de desempenho do modelo, como toxicidade ou drift, ficarem abaixo de determinados limites de qualidade.
Agora, com as percepções obtidas com nossos alertas, você pode identificar se um modelo precisa de um novo treinamento ou se há possíveis problemas com seus dados de origem. Depois de resolver os problemas, você pode chamar manualmente a API de refresh para obter as métricas mais recentes do seu pipeline atualizado. O Lakehouse Monitoring ajuda você a tomar medidas proativamente para manter a integridade e a confiabilidade gerais dos seus dados e modelos.
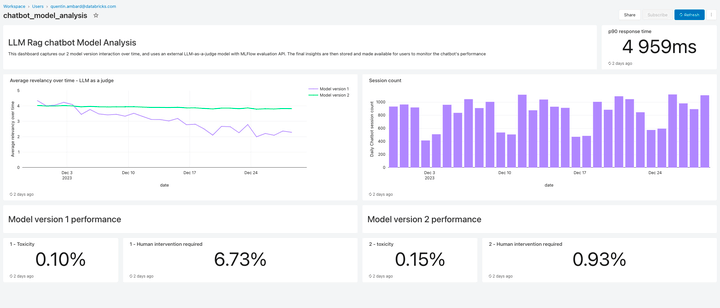
Monitorar a qualidade do LLM
O Lakehouse Monitoring oferece uma solução de qualidade totalmente gerenciada para aplicações de Geração Aumentada por Recuperação (RAG). Ele verifica as saídas da sua aplicação em busca de conteúdo tóxico ou inseguro. Você pode diagnosticar rapidamente erros relacionados, por exemplo, a pipelines de dados obsoletos ou comportamento inesperado do modelo. O Lakehouse Monitoring gerencia totalmente os pipelines de monitoramento, liberando os desenvolvedores para se concentrarem em suas aplicações.
O que vem a seguir?
Estamos entusiasmados com o futuro do Lakehouse Monitoring e ansiosos para oferecer suporte a:
- Classificação de dados/Detecção de PII – Inscreva-se em nosso Private Preview aqui!
- Expectations para aplicar automaticamente regras de qualidade de dados e orquestrar seus pipelines
- Uma visão holística dos seus monitores para resumir a qualidade e a integridade em suas tabelas
Para saber mais sobre o monitoramento do Lakehouse e começar hoje mesmo, visite a documentação do nosso produto (AWS | Azure). Além disso, confira os anúncios recentes sobre a criação de aplicações RAG de alta qualidade e participe do nosso webinar sobre GenAI.
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.