Desmistificando 8 mitos sobre layout de dados: por que o Liquid Clustering supera o particionamento
O layout de dados para o lakehouse moderno
por Jeffrey Gong, Yu Xu e Rahul Mahadev
- Liquid Clustering é o layout de dados para formatos de tabela abertos que supera o particionamento, evitando suas limitações
- 8 mitos comuns mantêm as equipes presas ao particionamento, e nenhum deles se sustenta mais
- Clientes que usam Liquid Clustering relatam melhorias drásticas na latência de consulta, taxa de transferência de gravação, eficiência de armazenamento e atualidade dos dados, com os maiores ganhos se acumulando em escala de petabytes
Introdução
Organizar dados é um dos problemas mais antigos da computação.
Por mais de 15 anos, desde o advento do Hadoop e Hive, o particionamento tem sido a maneira padrão de organizar fisicamente os dados para processamento e análise. No entanto, os Lakehouses de hoje atendem a agentes, pipelines em tempo real e padrões de consulta que mudam mais rápido do que qualquer ser humano pode repartitionar.
Liquid Clustering é o padrão moderno e os clientes o estão utilizando em todas as escalas, incluindo dezenas com tabelas em escala de petabytes em produção. Neste blog, abordaremos por que o Liquid Clustering vence no Lakehouse. Ao longo do caminho, desmistificaremos 8 mitos comuns sobre organização de dados, apresentaremos 3 histórias de sucesso de equipes convertendo tabelas particionadas para Liquid Clustering, faremos uma prévia do que está por vir e mostraremos como começar.
Por que o Liquid Clustering vence no Lakehouse moderno
O particionamento no estilo Hive força os usuários a se comprometerem, no momento da criação da tabela, com uma organização física dos dados que se manifesta na estrutura de arquivos. Escolha uma coluna com cardinalidade muito alta e você terá bilhões de arquivos minúsculos. Escolha a coluna errada e as consultas podem ficar mais lentas, não mais rápidas. De qualquer forma, você fica preso reescrevendo a tabela. É comum errar: em nossa análise, o particionamento no estilo Hive leva ao superdimensionamento e a problemas de arquivos pequenos em mais de 75% dos casos.
O Liquid trata as chaves de cluster como entrada que o motor usa para guiar a organização ideal dos arquivos. As chaves podem ser alteradas a qualquer momento, ou selecionadas inteligentemente através do Liquid Clustering Automático. A cardinalidade não é uma restrição, e a organização pode evoluir ao longo do tempo sem regravações desnecessárias.
Os benefícios do Liquid Clustering derivam todos do princípio acima: melhor tratamento de assimetria (skew), concorrência em nível de linha, sem problemas de arquivos pequenos, clusterização multidimensional e menor amplificação de gravação.
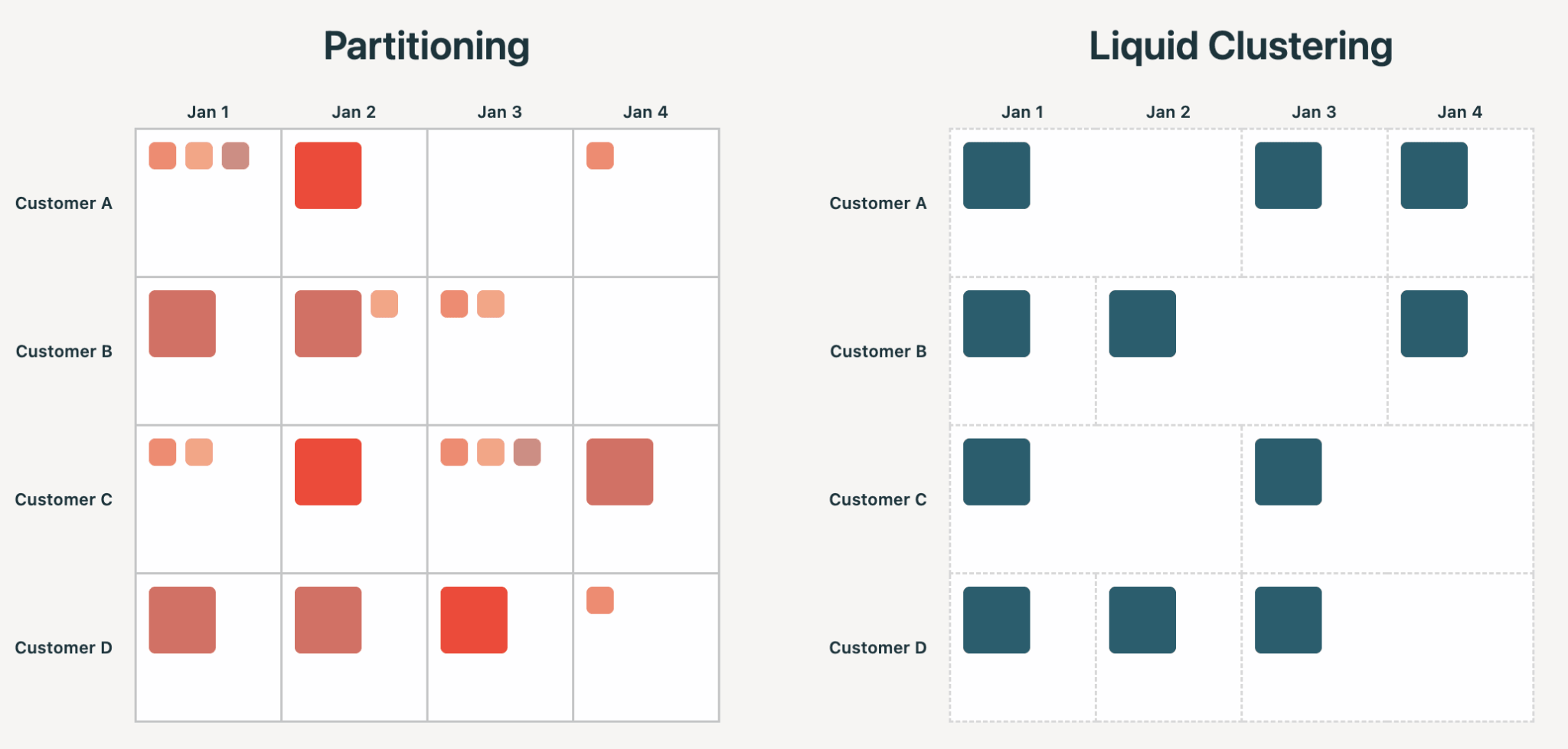
Em 2026, a organização de dados deveria ser um detalhe de implementação da tabela, com todos os motores que leem ou escrevem se beneficiando dela. Isso é cada vez mais importante à medida que os agentes entram no Lakehouse, gerando e consumindo mais dados do que nunca. Humanos e agentes precisam de interfaces flexíveis, livres dos potenciais efeitos colaterais do particionamento no estilo Hive.
Desmistificando 8 mitos comuns sobre organização de dados
O Liquid Clustering se tornou Geralmente Disponível em 2024. Desde então, iteramos continuamente com clientes que o utilizam em escala. Nesse período, alguns mitos comuns sobre Liquid Clustering e particionamento persistiram, e hoje queremos desmistificá-los.
Mito #1: O particionamento é mais rápido porque pode podar diretórios em vez de arquivos
O mito diz: Com o particionamento, Spark ou outros motores podem podar diretórios inteiros sem abrir nenhum arquivo dentro deles.
Realidade: A poda de diretórios não existe em formatos de tabela abertos modernos como Delta e Iceberg. O Delta, por exemplo, usa um log de transações para rastrear cada arquivo de dados junto com estatísticas por coluna, e a poda ocorre contra essas estatísticas, não a estrutura de diretórios. O motor nunca lista diretórios para planejar uma consulta. Ele lê o log de transações, avalia filtros contra estatísticas e pula arquivos que não correspondem. O Liquid Clustering usa o mesmo mecanismo. Se seus dados residem em `date=x/hour=y/` ou em um diretório plano de arquivos clusterizados, o motor poda na granularidade de arquivo. Não há atalho de nível de diretório a ser perdido.
Mito #2: O particionamento é melhor ao filtrar em uma coluna de baixa cardinalidade
O mito diz: Para uma coluna com um pequeno número de valores distintos, o particionamento oferece separação perfeita de dados e bons tamanhos de arquivo.
Realidade: O Liquid Clustering detecta automaticamente quando aplicar otimizações de baixa cardinalidade. Por exemplo, se você clusteriza por (date, user_id), e date tem baixa cardinalidade, o sistema visa que cada arquivo contenha linhas de apenas uma única data. Colunas de cardinalidade mais alta, como user_id, são então usadas automaticamente para uma ordenação mais fina dentro dos arquivos de cada data, sem ter que depender de outras técnicas de ordenação como Z-Ordering.
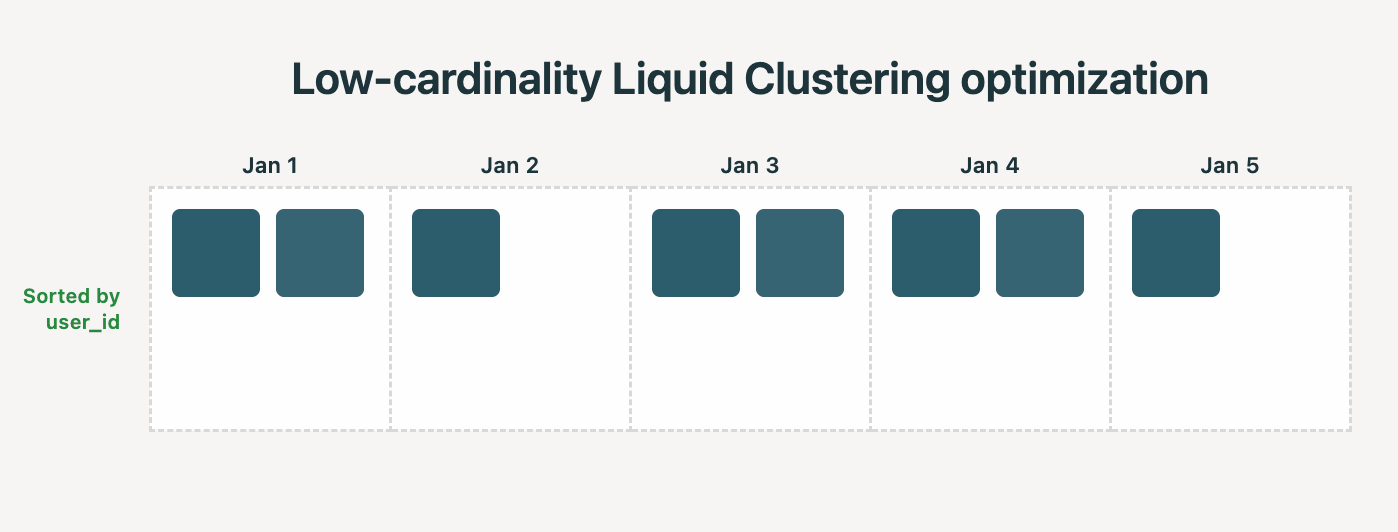
Vimos as seguintes melhorias ao comparar essa otimização do Liquid em um benchmark de data warehousing do mundo real: 35% menos tempo para clusterização e 22% mais rapidez nas consultas.
Além disso, o Liquid Clustering foi projetado para ser melhor que o particionamento ao clusterizar em uma coluna de alta cardinalidade, pois sempre tenta criar arquivos de um bom tamanho.
Mito #3: O Liquid Clustering não suporta operações apenas de metadados
O mito diz: Operações apenas de metadados são suportadas exclusivamente pelo particionamento. Um DELETE alinhado com limites de partição atualiza apenas os metadados da tabela, e agregações em colunas de partição podem ser calculadas sem varrer os arquivos. O Liquid Clustering não pode fazer o mesmo.
Realidade: O Liquid Clustering também suporta operações apenas de metadados, incluindo DELETEs, COUNT, DISTINCT e consultas GROUP BY. O motor usa as mesmas estatísticas min/max por arquivo que usa para pular dados para determinar quando a resposta de uma consulta pode ser calculada apenas a partir de metadados. Em nossos benchmarks, DELETEs apenas de metadados em tabelas com Liquid Clustering foram ~90% mais rápidos do que DELETEs de reescrita completa. Outras consultas de agregação apenas de metadados tiveram acelerações de até 27x.
Mito #4: O Liquid Clustering não funciona bem em escala de petabytes
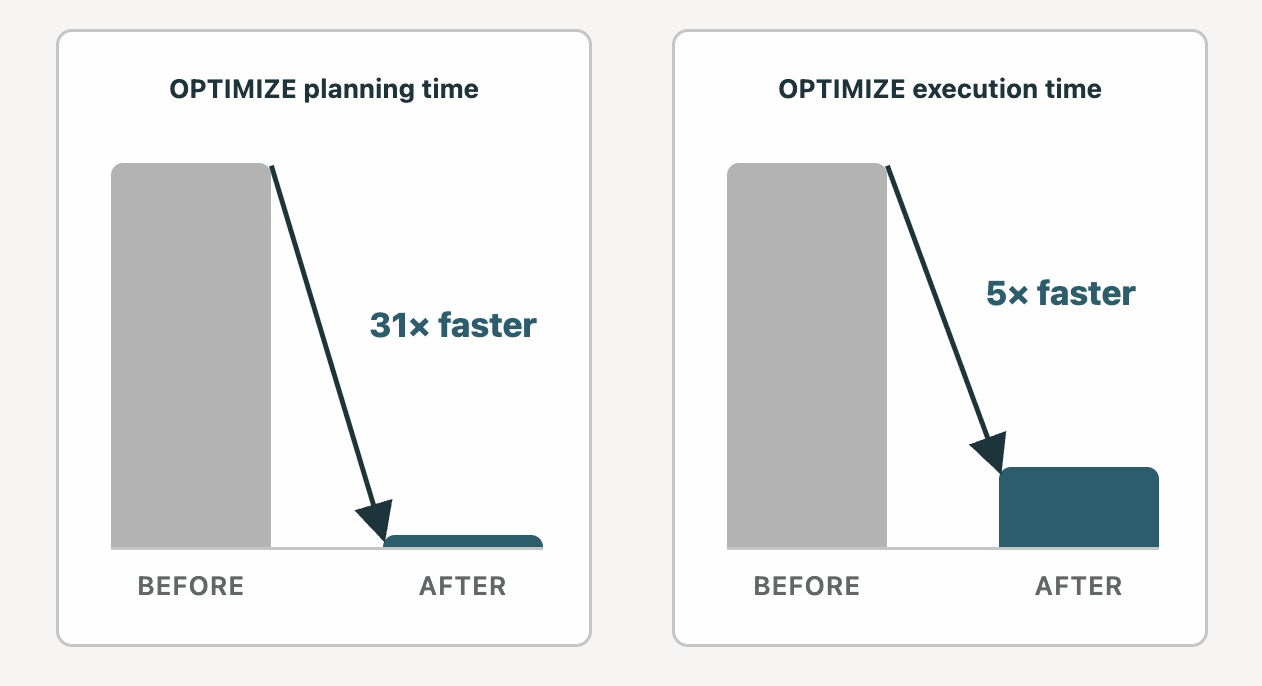
O mito diz: OPTIMIZE em uma tabela de tamanho PB pode levar horas, e o custo de manutenção é muito alto.
Realidade: Fizemos várias melhorias significativas no OPTIMIZE, e dezenas de clientes agora têm tabelas com Liquid Clustering em escala de PB em produção. Dois anos atrás, o planejamento, a primeira fase do OPTIMIZE, poderia levar até 12 horas em uma tabela Liquid de 10 PB em alguns casos. Gastamos o tempo desde então reduzindo o tempo de planejamento para 23 minutos. A execução, a segunda fase do OPTIMIZE, ficou 5x mais rápida em um cluster DBSQL Médio.
Mito #5: O Liquid Clustering beneficia apenas um subconjunto de leitores
O mito diz: O Liquid Clustering só é benéfico para leitores Databricks em tabelas Delta gerenciadas pelo UC.
Realidade: O Liquid Clustering é uma otimização do lado da escrita. É como o motor organiza os arquivos para um pular dados eficiente. A saída são arquivos Parquet padrão com estatísticas min/max, gravados em formatos de tabela abertos como Delta/Iceberg. Qualquer leitor compatível (por exemplo, Apache Spark de código aberto, DuckDB, etc.) pode usar essas estatísticas para pular arquivos. O Liquid Clustering está disponível em tabelas externas / gerenciadas e Delta / Iceberg, e o benefício é aplicável independentemente do leitor.
Mito #6: O particionamento é necessário para ETL concorrente
O mito diz: ETL concorrente precisa de limites de gravação. Sem particionamento, dois gravadores atualizando a mesma tabela correm o risco de colidir, e o controle de concorrência Delta/Iceberg força um deles a tentar novamente ou falhar. Particione e dê a cada gravador sua própria fatia da tabela, para que dois pipelines nunca toquem nos mesmos arquivos.
Realidade: Operar na granularidade de partição era uma solução alternativa para um modelo de concorrência mais antigo. Ao contrário do particionamento, que tem apenas concorrência em nível de arquivo, o Liquid oferece concorrência em nível de linha. Dois gravadores atualizando linhas diferentes não entram mais em conflito, mesmo que essas linhas residam no mesmo arquivo. Isso remove um dos principais motivos pelos quais as equipes particionavam tabelas: manter limites de gravação para evitar serialização. Com o Liquid Clustering, o ETL pode operar facilmente de forma concorrente na mesma tabela.
Mito #7: Z-Ordering compensa as deficiências do particionamento
O mito diz: O particionamento lida com os filtros da coluna de partição, e o Z-Ordering lida com o resto. Ao executar OPTIMIZE ZORDER BY, o mecanismo classifica os dados para um saltamento ideal em filtros que não se alinham com o esquema de particionamento.
Realidade: O Z-Ordering não salva o particionamento. Na verdade, ele tem seus próprios problemas estruturais.
- O primeiro é a baixa qualidade de clusterização. O Z-Order não mantém uma ordenação verdadeira em toda a tabela. Valores da mesma coluna podem ser espalhados por muitos arquivos, de modo que os intervalos min/max por arquivo são mais amplos e as consultas saltam menos arquivos do que com o Liquid.
- O segundo são as re-gravações desnecessárias. O Z-Order precisa ser executado periodicamente à medida que novos dados chegam, e cada reexecução reescreve grandes quantidades de dados antigos, possivelmente já clusterizados, para restaurar a qualidade da clusterização. Com ingestão contínua, o custo de manter os dados bem clusterizados com Z-Order cresce junto com a tabela.
O Liquid clusteriza incrementalmente, inclusive no momento da gravação, para que o layout permaneça otimizado sem re-gravações desnecessárias.
Mito #8: O particionamento é necessário para sobrescritas seletivas de dados
O mito diz: A capacidade de sobrescrever dados seletivamente só está disponível através de Dynamic Partition Overwrites.
Realidade: Sobrescritas seletivas funcionam nativamente em tabelas Liquid. O Databricks suporta REPLACE USING e REPLACE ON, duas sintaxes SQL para sobrescrever seletivamente dados em qualquer layout de dados: tabelas Liquid Clustered, particionadas ou simplesmente não clusterizadas. Ao contrário do Dynamic Partition Overwrite, que requer uma configuração do Spark, REPLACE USING e REPLACE ON podem ser usados em qualquer computação: clusters clássicos, SQL warehouses e Serverless. A operação é atômica e corresponde a qualquer coluna que você escolher.
Histórias de sucesso: migrando do particionamento para o Liquid Clustering
Aceleração de consulta 7,7x na tabela de telemetria de segurança de 3,8 PB da Arctic Wolf
Arctic Wolf executa uma tabela de telemetria de seguran�ça de mais de 3,8 PB, ingerindo mais de 1 trilhão de eventos por dia, onde os caçadores de ameaças dependem de dados atualizados para detectar ataques ativos.
Após migrar do particionamento para o Liquid Clustering em tabelas gerenciadas pelo Unity Catalog com Predictive Optimization, a Arctic Wolf observou:
- Consultas de 90 dias reduzidas de 51 segundos para 6,6 segundos
- Contagem de arquivos reduzida de 4M para 2M
- Atualização de dados melhorada de horas para minutos
Melhorias de leitura e gravação em tabelas críticas de CDC para a Bolt
A Bolt experimentou recentemente a Conversão Liquid (atualmente em Private Preview), que converte tabelas particionadas para Liquid in-place usando ALTER TABLE .. REPLACE PARTITIONED BY WITH CLUSTER BY. Eles observaram os seguintes benefícios de leitura e gravação em uma tabela de CDC em escala de TB após a conversão para Liquid Clustering:
- Taxa de transferência de gravação (linhas/seg) aumentou em 138%
- Tempos de leitura reduzidos em até 63%, com uma média de 21% de redução em 9 consultas representativas
O Liquid Clustering reduziu drasticamente o trabalho que cada gravação estava fazendo, aumentando significativamente nossa taxa de transferência em nossa tabela CDC mais crítica. As leituras também melhoraram em geral. A melhor parte foi: executamos a conversão do particionamento junto com a ingestão ao vivo sem tempo de inatividade. Com isso, o Liquid Clustering nos forneceu exatamente o tipo de desempenho e confiabilidade que precisávamos em escala de plataforma. —Marcin, engenheiro de plataforma sênior na Bolt
Aceleração de 5,9x no tempo de consulta em uma carga de trabalho interna em escala de petabyte
Executamos uma tabela de 1,1 PB internamente que é consultada milhares de vezes por dia, principalmente por engenheiros executando investigações de produção e painéis de observabilidade. Originalmente, ela era particionada por date e hour, assumindo que os escaneamentos de intervalo de tempo dominariam. No entanto, essa suposição se mostrou incompleta. Embora os escaneamentos de intervalo de tempo fossem comuns, a tabela também era frequentemente consultada por source e id, forçando o mecanismo a escanear todos os arquivos nas partições de data e hora relevantes para encontrar um punhado de linhas.
Adicionar source e id como partições não era viável, pois havia muitos valores distintos. Isso teria criado bilhões de arquivos minúsculos. O Liquid Clustering removeu o trade-off, permitindo a clusterização por tempo e as colunas de identificador adicionais simultaneamente, mantendo bons tamanhos de arquivo.
| Layout | |
|---|---|
| Antes | Particionado por date, hour |
| Depois | Agrupado por date, hour, source, id |
Benchmarks mostraram melhorias massivas em 16 consultas de produção representativas:
| Métrica | Antes (particionado) | Depois (Liquid) | Melhorias |
|---|---|---|---|
| Tempo de Relógio de Parede | 406s | 70s | 5.9x de aceleração |
| Bytes Lidos | 3.5 TB | 0.48 TB | 86% menos bytes lidos |
A própria tabela ficou menor. O tamanho total caiu de 1.1 PB para 0.8 PB, uma redução de 27% sem alteração nos dados subjacentes. Arquivos mais bem agrupados comprimem com mais eficiência, e o imposto de arquivos pequenos que acompanha o particionamento excessivo desaparece.
O que vem a seguir para o Agrupamento Líquido
Otimizando junções Líquido-a-Líquido: até 51% mais rápido com 87% menos shuffle
Hoje, juntar tabelas Líquidas em suas colunas de agrupamento pode exigir um shuffle completo dos dados, mesmo quando os dados já estão organizados por essas colunas. Junções co-agrupadas (agora em Pré-visualização Privada) removem esse shuffle automaticamente. Em um benchmark de data warehousing do mundo real, uma junção Líquido-a-Líquido foi executada ~51% mais rápido (28 minutos → 14 minutos) e embaralhou 87% menos dados (1.2 TiB → 150 GiB) do que a mesma consulta sem a otimização.
Conversão Líquida Fácil de tabelas particionadas
Antes, converter uma tabela particionada para Agrupamento Líquido exigia uma reescrita completa da tabela e alterações de quebra downstream com REPLACE TABLE ou um corte com escritas duplas e tempo de inatividade planejado. Estamos introduzindo um novo comando (agora em Pré-visualização Privada) que torna essa conversão mais fácil, minimizando o tempo de inatividade e as reescritas.
Começando com o Agrupamento Líquido
Crie uma tabela com Agrupamento Líquido:
Ou, se você estiver usando tabelas gerenciadas UC com Otimização Preditiva, use Agrupamento Líquido Automático para selecionar inteligentemente as chaves de agrupamento com base em sua carga de trabalho e padrões de consulta:
O Agrupamento Líquido é o layout para o Lakehouse moderno. Experimente em sua próxima tabela, ou entre em contato com sua equipe de contas hoje para experimentar as Pré-visualizações Privadas de Conversão de Particionado para Líquido e junções Co-Agrupadas!
Não se esqueça de nos encontrar no DAIS!
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.