De eventos a percepções: Processamento de estado complexo com evolução do esquema em transformWithState
Saiba como usar a nova API transformWithState com a evolução do esquema para um caso de uso de sessionização operacional do mundo real.
por Thangam Vaiyapuri, Jay Palaniappan, Anish Shrigondekar e Karthikeyan Ramasamy
- Transmissão com estado resiliente: O transformWithStateInPandas do Spark 4.0 permite que os pipelines se adaptem às alterações de esquema, adicionando campos ou modificando tipos, preservando o estado existente e evitando interrupções de serviço.
- Sessionalização adaptativa em ação: Um cenário do StreamShop ilustra como os esquemas de fluxo de cliques em evolução são tratados automaticamente, permitindo que o estado da sessão V1 seja atualizado de forma limpa para V2 sem reprocessamento.
- Continuidade operacional e agilidade: As organizações mantêm uma analítica consistente e aceleram o fornecimento de recurso, evoluindo os esquemas com segurança, reduzindo a sobrecarga de engenharia e eliminando o tempo de inatividade durante as atualizações.
Em todas as indústrias, um dos desafios mais persistentes na engenharia de dados é a evolução do esquema. Os requisitos de negócios mudam, as fontes de dados se alteram e novos campos de evento surgem da noite para o dia, forçando as equipes de engenharia de dados a ajustar constantemente os pipelines e os armazenamentos de estado apenas para manter os sistemas em funcionamento.
Os métodos tradicionais de transmissão são interrompidos quando os esquemas mudam. Os armazenamentos de estado tornam-se incompatíveis e os pipelines falham. As equipes têm a opção de perder data histórica ou passar por um dispendioso tempo de inatividade para migrações de esquemas. Esse não é apenas um problema técnico - é uma barreira para a agilidade dos negócios.
O Apache Spark™ 4.0 introduziu a transformWithStateInPandas, uma API inovadora que torna a evolução do esquema em transmissão com estado não apenas possível, mas transparente. Com gerenciamento de estado inteligente e compatibilidade de esquema automática, seus aplicativos de transmissão evoluem com as necessidades do seu negócio, enquanto preservam informação de estado críticas.
Esta publicação é a quarta e mais recente da série transformWithState:
- Apresentando o transformWithState para o Apache Spark™ Structured Streaming, um mergulho profundo nos princípios de design e na arquitetura por trás da nova API.
- The Evolution of Arbitrary Stateful transmissão Processing in Spark, explora as vantagens exclusivas do
transformWithStateInPandas. - Monitoramento Ambiental Contínuo Usando a Nova API transformWithState, um exemplo prático de aplicação de transformWithState a casos de uso de IoT ambiental.
Juntos, estes blogs demonstram como a API transformWithState permite o processamento stateful avançado para cargas de trabalho em tempo real, dando suporte a casos de uso que vão desde o monitoramento de IoT até a analítica de sessão em tempo real.
O desafio da evolução do esquema no Spark Streaming
A evolução de esquemas no Spark Streaming com estado cria um atrito operacional significativo. Com abordagens tradicionais como applyInPandasWithState e session_window, o estado é serializado com metadados de esquema incorporados, criando um acoplamento rígido entre a estrutura de dados e o estado persistente.
Quando você modifica seu schema — adicionando campos, alterando tipos ou reordenando colunas —, o estado existente se torna incompatível com os novos dados de entrada. Incompatibilidades de schema causam falhas de desserialização, forçando você a usar soluções manuais:
- Incompatibilidade de estado:o estado antigo não pode ser conciliado com as novas estruturas de esquema.
- Migração manual: Os desenvolvedores devem escrever uma lógica de transformação personalizada para fazer a ponte entre os esquemas
- Tempo de inatividade necessário: As alterações de esquema forçam você a interromper as transmissões, migrar o estado off-line e reiniciar
- Risco de perda de dados: O estado histórico pode ser corrompido ou perdido durante a migração
- Sobrecarga no gerenciamento de versões: O suporte a várias versões de esquemas requer um extenso código de boilerplate
Por que o transformWithStateInPandas (TWS) para a evolução do esquema
Embora o Spark ofereça soluções comprovadas, como session_window para a sessionização básica e applyInPandasWithState para o processamento personalizado com estado, os requisitos de negócios em evolução geralmente precisam de flexibilidade adicional para a evolução contínua do esquema. O transformWithStateInPandas baseia-se nesses fundamentos para abordar especificamente cenários em que os dados e a lógica de negócios precisam evoluir continuamente.
Veja o que torna o transformWithStateInPandas ideal para a evolução do esquema:
- Compatibilidade automática de esquema: o estado existente se integra perfeitamente às novas versões de esquema, quer você esteja adicionando campos, ampliando tipos ou reordenando colunas.
- Preservação de estado durante a evolução: sem perda de dados quando os esquemas mudam; seu estado histórico permanece acessível e valioso.
- Evolução com tempo de inatividade mínimo: as alterações de esquema são implementadas com interrupções mínimas de serviço.
Análise aprofundada do cenário
Reconstrução da jornada do cliente em tempo real
Vamos imaginar que você faz parte da equipe de engenharia de dados da "StreamShop", uma plataforma de varejo on-line em rápido crescimento. É segunda-feira de manhã, e seu CEO acabou de entrar na reunião da equipe de engenharia com uma impressão de analítica da concorrência mostrando que eles estão superando vocês nas taxas de conversão. A equipe de marketing está exigindo respostas:
"Estamos gastando milhões em anúncios, mas onde os usuários estão caindo?" "Quais caminhos do cliente realmente levam a compras?" "Podemos personalizar a experiência com base no que os usuários estão fazendo no momento?"
Não se trata de perguntas sobre eventos isolados, mas sim sobre a jornada do usuário, a sequência conectada e a história comportamental que se desenrola à medida que os usuários clicam, navegam, adicionam itens ao carrinho e compram ou abandonam. Essas jornadas são realizadas em sessões.
Seus dados de clickstream chegam de aplicativos web e móveis pelo Apache™ Kafka: cada view de página, clique e "adição ao carrinho", e seu pipeline de transmissão os rastreia, os agrupa em sessões usando um esquema definido e armazena os registros usando flatMapGroupsWithState. No entanto, agora há um novo desafio. Na semana passada, a equipe de desenvolvimento móvel implantou uma nova versão que começou a enviar campos adicionais como device_type e page_category sem informar a equipe de dados.
Sua solução atual de agregação em janelas não suporta esse cenário imediatamente, portanto, você precisa interromper o pipeline, corrigir o esquema e reset os pontos de verificação. Isso não é prático porque você precisa executar essa operação sempre que o esquema for alterado. Você precisa de algo mais robusto, mais flexível e capaz de lidar com a evolução do esquema de forma transparente.
A base: Criando sessões inteligentes com a evolução do esquema
Entendendo a evolução da sessão
Seus eventos de fluxo de cliques começaram simples com um esquema V1 básico: apenas ID de sessão, ID de usuário, timestamp e tipo de evento. Mas, à medida que a StreamShop evolui, o mesmo acontece com os eventos. Agora você está recebendo eventos V2 com informações contextuais avançadas: tipos de dispositivos, categorias de páginas e dados específicos do comércio, como valores de receita.
O desafio não é apenas lidar com dois esquemas - é evoluir os estados existentes sem perdê-los ou começar de novo. Sua lógica de sessionização precisa lidar com essa evolução de forma elegante, mantendo a continuidade da sessão.
transformWithStateInPandas Evolução do esquema :
O que é a evolução do esquema no armazenamento do estado?
A evolução do esquema refere-se à capacidade de uma query de transmissão de lidar com alterações no esquema de armazenamento do estado dos dados sem perder informação de estado ou exigir o reprocessamento completo dos dados históricos. Para transformWithStateInPandas, isso significa que você pode modificar os esquemas de variáveis de estado entre as versões de query, preservando o estado da sessão existente. Vamos dar uma olhada na implementação abaixo.
A Implementação do Sessionizer
Neste exemplo, criamos duas classes personalizadas, SessionizerV1 e SessionizerV2, para processamento avançado de sessões. Elas mostram como o transformWithStateInPandas pode ajudar a rastrear não apenas as métricas básicas, mas também a entender o contexto e a evolução de cada jornada do usuário.
Processador V1: a base
Na V1 do sessionizer, configuramos um schema básico para a sessão para rastrear valores personalizados como event_count e total_revenue.
Processador V2: Definição do esquema evoluído
O V2 demonstra a verdadeira força da evolução do esquema automática. No V2 do processador, adicionamos duas novas colunas e expandimos o tipo de uma coluna existente(event_count), que é perfeitamente atualizada no armazenamento do estado subjacente.
Diferente da sessãonização tradicional baseada em janela, o sessãonizador transformWithStateInPandas pode ajudar a manter um contexto rico sobre a jornada de cada usuário, incluindo seus padrões de engajamento, comportamento de compra e até mesmo quais versões de esquema eles usaram.
Evolução do esquema de estado:
- Ampliação de tipo:
IntegerType→LongTypeparaevent_count(conversão automática) - Novos campos:
device_typeepage_category(aparecem comoNonepara o estado V1 evoluído) - Mesma variável de estado: O uso de "
session_state" name permite a evolução automática - Ordem dos campos: Novos campos adicionados no final para compatibilidade
Processamento de eventos com a evolução do esquema
O método handleInputRows demonstra como o V2 lida de forma inteligente com os novos eventos do V2 e com o estado evoluído do V1:
Dominando a evolução do esquema: a análise técnica aprofundada
Entendendo o desafio da evolução do esquema
A verdadeira complexidade da sessionização moderna não é apenas agrupar eventos - é lidar com a evolução desses eventos ao longo do tempo. Na StreamShop, isso se tornou crítico quando as atualizações de aplicativos móveis começaram a enviar dados aprimorados enquanto a plataforma da Web ainda usava o esquema original.
Veja como a evolução do esquema funciona na prática:
Eventos V1 (esquema original):
Eventos V2 (esquema aprimorado):
A configuração completa do pipeline
Ao usar o mesmo checkpointLocation, a V2 continua o processamento do esquema de armazenamento do estado da V1 a partir do último deslocamento confirmado, permitindo que o esquema evolua sem reprocessar os dados.
Como a Databricks lida com a evolução do esquema automaticamente
A mágica acontece automaticamente quando o processador V2 lê o estado V1. O Databricks realiza essas transformações nos bastidores:
1. Alargamento de tipo (automático)
2. Adição de campo (automática)
3. Detecção de evolução (nossa lógica)
Impacto nos Negócios: A História dos Resultados
Como ver a evolução do esquema em ação
Após a implantação do nosso pipeline de sessionização, os resultados demonstram uma evolução bem-sucedida do esquema. O que acontece é o seguinte:
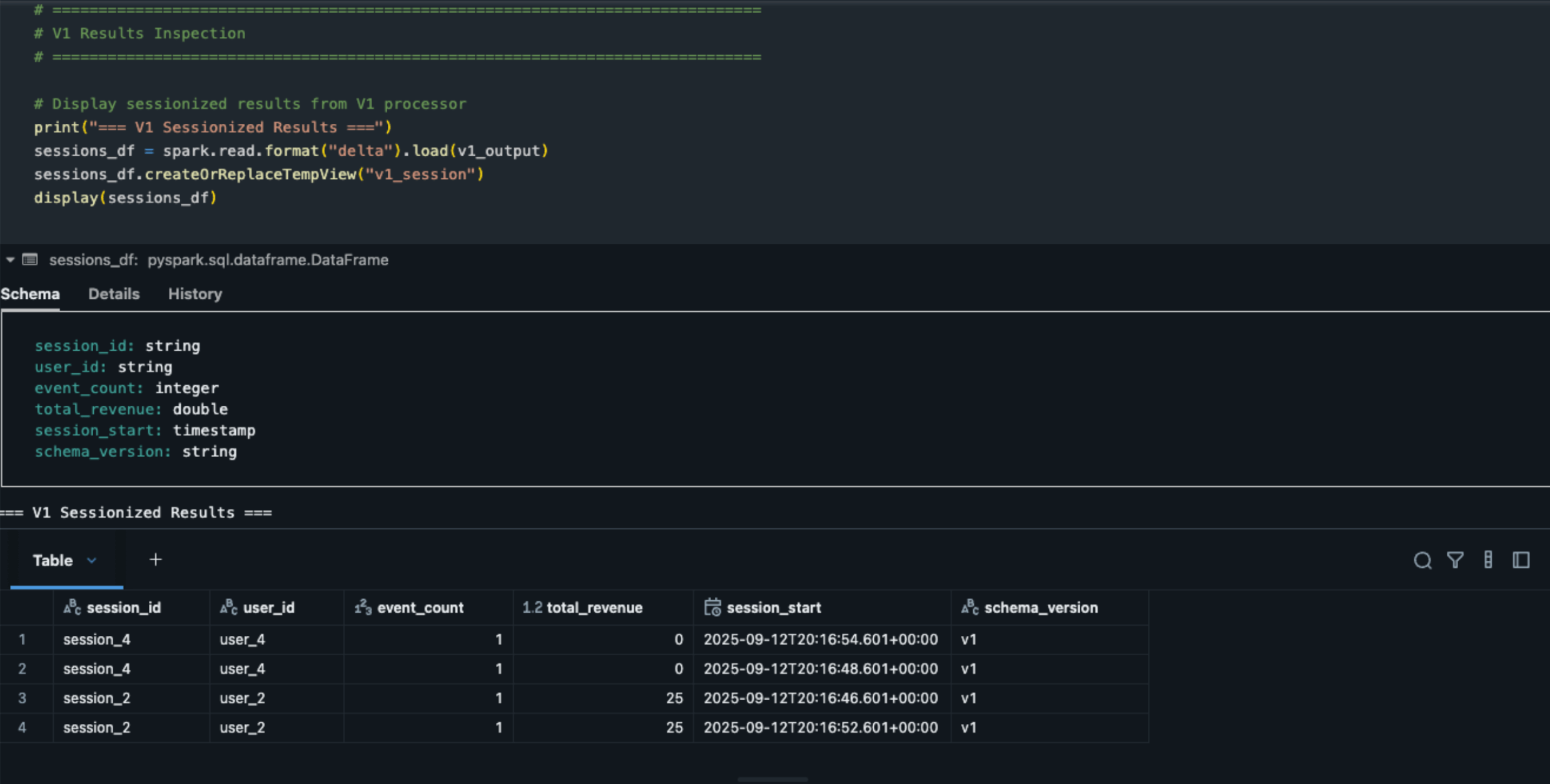
Resultados da V1 - Sessões iniciais com schema básico:
- session_2 e session_4 concluídas com eventos terminais (compra/logout)
- session_1, session_3, session_5, session_6 permanecem ativas com eventos não terminais (page_view)
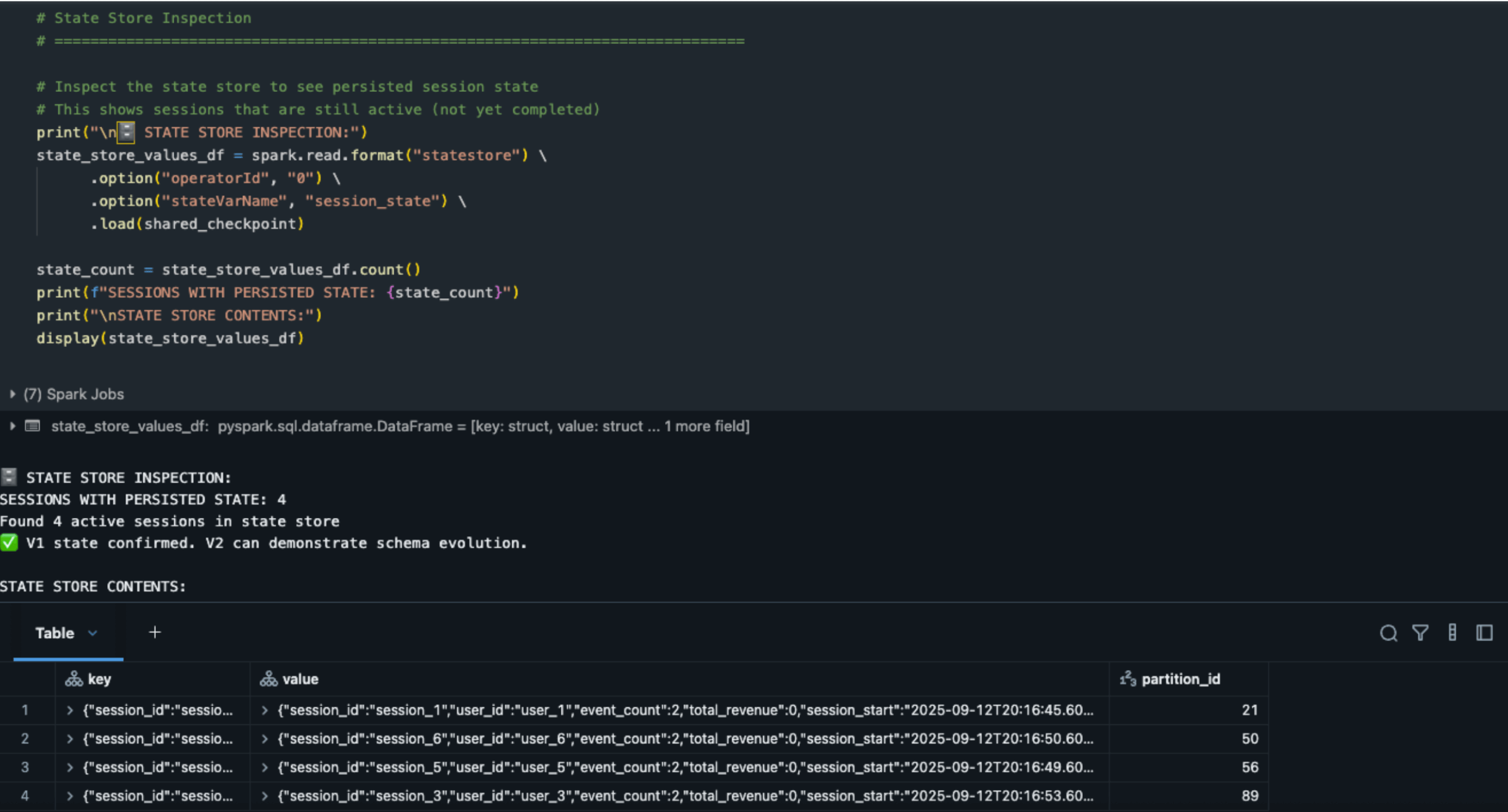
- O estado persiste nas sessões 1, 3, 5, 6
Saída Delta:
Saída da sessionalização da V1:
Inspecionando o StateStore:
Saída da sessãonização V2:
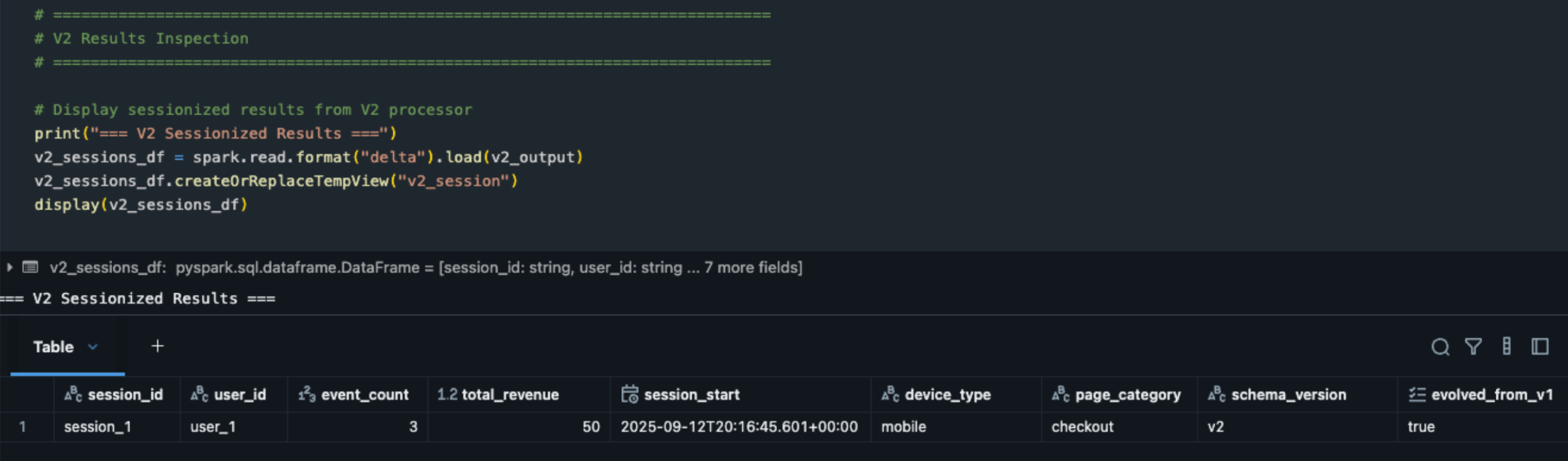
Leitura de registros versão V2 do esquema de estado - Sessões aprimoradas com esquema evoluído:
- sessão_1 concluída usando o estado V1 evoluído + novos campos V2
evolved_from_v1: true confirma a evolução do esquema bem-sucedida- Contexto aprimorado: device_type (celular, desktop, tablet), page_category (checkout, perfil, produto)
- Acumulação de eventos: 3 eventos totais com receita de US$ 50.
- Demonstra uma migração limpa do processador V1 para o V2 com continuidade de estado.
Análise da evolução do esquema:
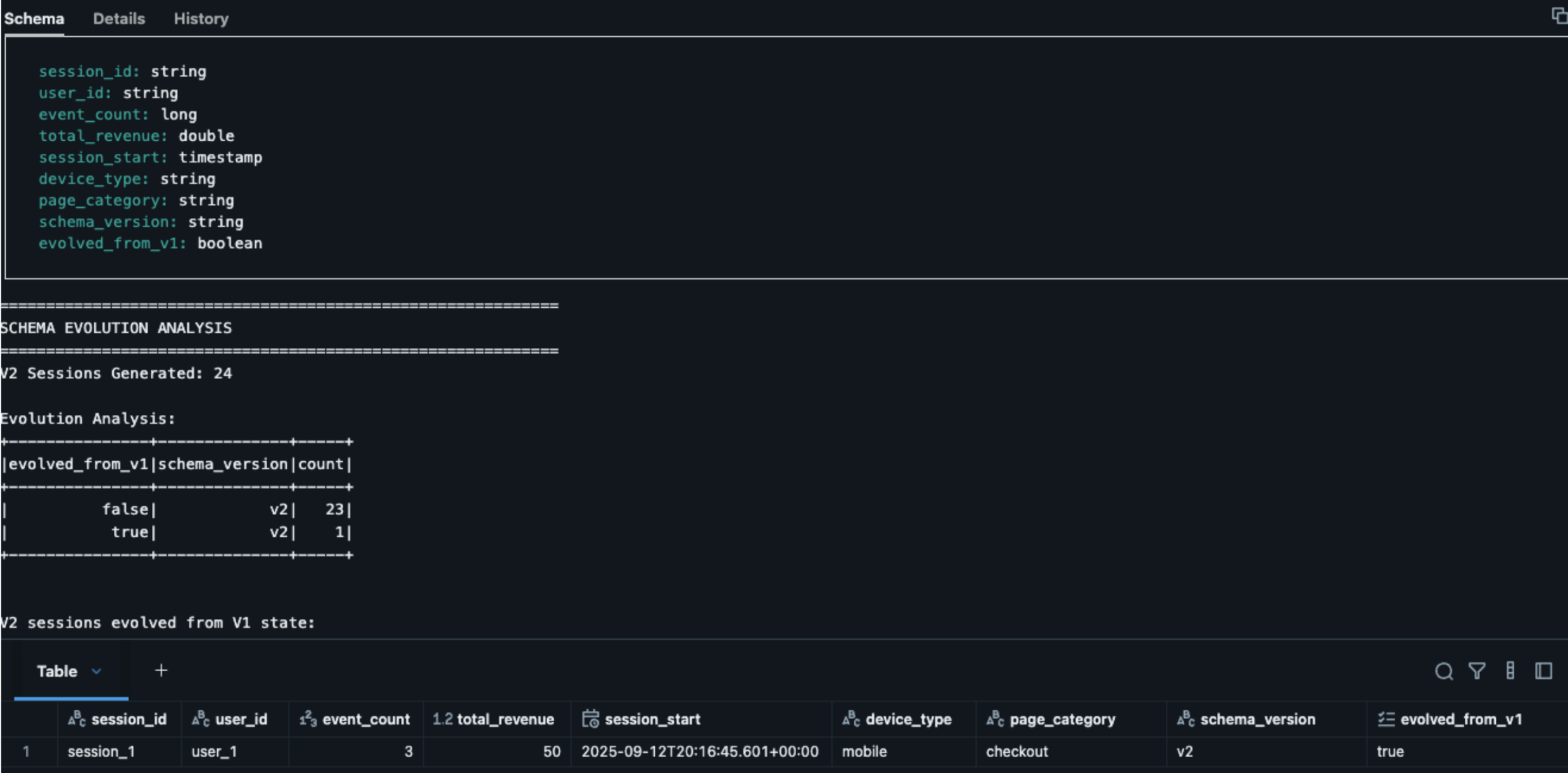
Sucesso na evolução do esquema no mundo real
A principal percepção: as sessões 1 em V2 mostram evolved_from_v1: true porque:
- Eventos não terminais em V1 (page_view) → o estado persistiu
- O processador V2 detectou automaticamente valores None em novos campos ao ler o estado V1
- O Databricks converteu de forma transparente o estado V1 (5 campos) para o estado V2 (7 campos).
- A ampliação de tipo (
IntegerType→LongType) aconteceu automaticamente - Novos campos (device_type, page_category) preenchidos a partir de eventos V2
- Sessão concluída com 3 eventos acumulados, demonstrando a continuidade bem-sucedida do estado
Configurações de pré-requisito
A evolução do esquema só é compatível com uma combinação de configurações do Spark .
1. Codificação Avro (OBRIGATÓRIO)
2. RocksDB armazenamento do estado (OBRIGATÓRIO)
O valor de negócio da evolução do esquema
A evolução do esquema permite que as organizações adicionem novos recursos e percepções sem interromper as operações diárias. Essa flexibilidade permite que as empresas melhorem continuamente, inovem mais rapidamente e permaneçam competitivas.
- Tempo mínimo de inatividade entre implementações: Novos campos de dados ou recursos de acompanhamento podem ser introduzidos com o mínimo de tempo de inatividade. Os clientes e as equipes internas têm um serviço ininterrupto, enquanto a empresa obtém percepções mais ricas.
- Implantações graduais: as alterações de schema podem ser introduzidas gradualmente, reduzindo o risco e tornando a adoção mais tranquila entre equipes e sistemas. Líderes de negócios podem testar e validar novos recursos sem se commit a mudanças disruptivas e em grande escala de uma só vez.
- Continuidade histórica: As organizações evitam o reprocessamento de dados dispendioso, mantendo os estados de sessão existentes e o contexto histórico. Isso fornece uma view integrada do passado e do presente, ajudando os tomada de decisão a confiar em tendências e percepções de longo prazo.
- Continuidade da analítica: Métricas consistentes são mantidas mesmo com a evolução da plataforma. Essa estabilidade permite que executivos e analistas se concentrem na tomada de decisões em vez de se preocuparem com inconsistências de dados ou relatórios.
Em última análise, a capacidade de evoluir esquemas e, ao mesmo tempo, preservar o estado muda a forma como as empresas abordam a analítica em tempo real. Isso garante que a inovação e a excelência operacional andem de mãos dadas, apoiando o crescimento contínuo com o mínimo de interrupções de serviço, ou mesmo nenhuma.
Conclusão
A API transformWithState do Apache Spark™ 4.0 é mais do que uma atualização técnica — é uma mudança na forma como a analítica de clientes em tempo real é construída.
Na StreamShop, ele possibilitou visibilidade em tempo real entre as equipes:
- O marketing acompanha as jornadas do cliente em tempo real
- O produto mede o impacto do recurso em poucas horas
- A engenharia obtém percepções profundas do sistema através da transparência do estado.
Com a evolução do esquema integrada, nosso pipeline de sessionização se adapta automaticamente à medida que a empresa evolui - novos eventos, plataformas e pontos de contato são tratados sem problemas.
Seja acompanhando jornadas, engajamento ou funis de conversão, o transformWithStateInPandas transforma eventos brutos em percepções acionáveis, criando um entendimento contínuo do cliente que alimenta o crescimento.
Esta publicação conclui nossa série transformWithState, destacando como a API permite o processamento escalonável e com estado em casos de uso de IoT e analítica baseada em sessão.
Recursos relacionados
- Guia de programação do Spark Structured Streaming
- Evolução do esquema de aplicativos com estado
- Melhorias de desempenho em pipelines com estado
- Repo do Github
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.