Apresentando o Databricks Lakeflow: Uma solução unificada e inteligente para engenharia de dados
Ingira dados de bancos de dados, aplicações empresariais e fontes na nuvem, transforme-os em batch e streaming em tempo real, e implante e opere com confiança em produção.
por Michael Armbrust e Bilal Aslam
Hoje, temos o prazer de anunciar o Databricks Lakeflow, uma nova solução que contém tudo o que você precisa para construir e operar pipelines de dados em produção. Ele inclui novos conectores nativos e altamente escaláveis para bancos de dados como SQL Server e para aplicações empresariais como Salesforce, Workday, Google Analytics, ServiceNow e SharePoint. Os usuários podem transformar dados em batch e streaming usando SQL e Python padrão. Também estamos anunciando o Modo em Tempo Real para Apache Spark, permitindo o processamento de streams com latências ordens de magnitude menores do que o microbatch. Finalmente, você pode orquestrar e monitorar fluxos de trabalho e implantar em produção usando CI/CD. O Databricks Lakeflow é nativo da Plataforma de Inteligência de Dados, oferecendo computação serverless e governança unificada com o Unity Catalog.

Neste post do blog, discutimos os motivos pelos quais acreditamos que o Lakeflow ajudará as equipes de dados a atender à crescente demanda por dados e IA confiáveis, bem como as principais capacidades do Lakeflow integradas em uma única experiência de produto.
Desafios na construção e operação de pipelines de dados confiáveis
Engenharia de dados - coletar e preparar dados frescos, de alta qualidade e confiáveis - é um ingrediente necessário para democratizar dados e IA em seu negócio. No entanto, alcançar isso ainda é complexo e requer a junção de muitas ferramentas diferentes.
Primeiro, as equipes de dados precisam ingerir dados de múltiplos sistemas, cada um com seus próprios formatos e métodos de acesso. Isso requer a construção e manutenção de conectores internos para bancos de dados e aplicações empresariais. Apenas acompanhar as mudanças de API das aplicações empresariais pode ser um trabalho em tempo integral para toda uma equipe de dados. Os dados precisam então ser preparados em batch e streaming, o que exige a escrita e manutenção de lógica complexa para acionamento e processamento incremental. Quando a latência aumenta ou ocorre uma falha, isso significa ser notificado, um conjunto de consumidores de dados insatisfeitos e até mesmo interrupções nos negócios que afetam o resultado final. Finalmente, as equipes de dados precisam implantar esses pipelines usando CI/CD e monitorar a qualidade e a linhagem dos ativos de dados. Isso normalmente requer a implantação, aprendizado e gerenciamento de outra ferramenta totalmente nova como Prometheus ou Grafana.
É por isso que decidimos construir o Lakeflow, uma solução unificada para ingestão, transformação e orquestração de dados impulsionada pela inteligência de dados. Seus três componentes principais são: Lakeflow Connect, Lakeflow Pipelines e Lakeflow Jobs.
Lakeflow Connect: Ingestão de dados simples e escalável
O Lakeflow Connect oferece ingestão de dados com um clique de bancos de dados como SQL Server e aplicações empresariais como Salesforce, Workday, Google Analytics e ServiceNow. O roteiro também inclui bancos de dados como MySQL, Postgres e Oracle, bem como aplicações empresariais como NetSuite, Dynamics 365 e Google Ads. O Lakeflow Connect também pode ingerir dados não estruturados como PDFs e planilhas Excel de fontes como SharePoint.
Ele complementa nossos populares conectores nativos para armazenamento em nuvem (por exemplo, conectores S3, ADLS Gen2 e GCS) e filas (por exemplo, conectores Kafka, Kinesis, Event Hub e Pub/Sub), e soluções de parceiros como Fivetran, Qlik e Informatica.
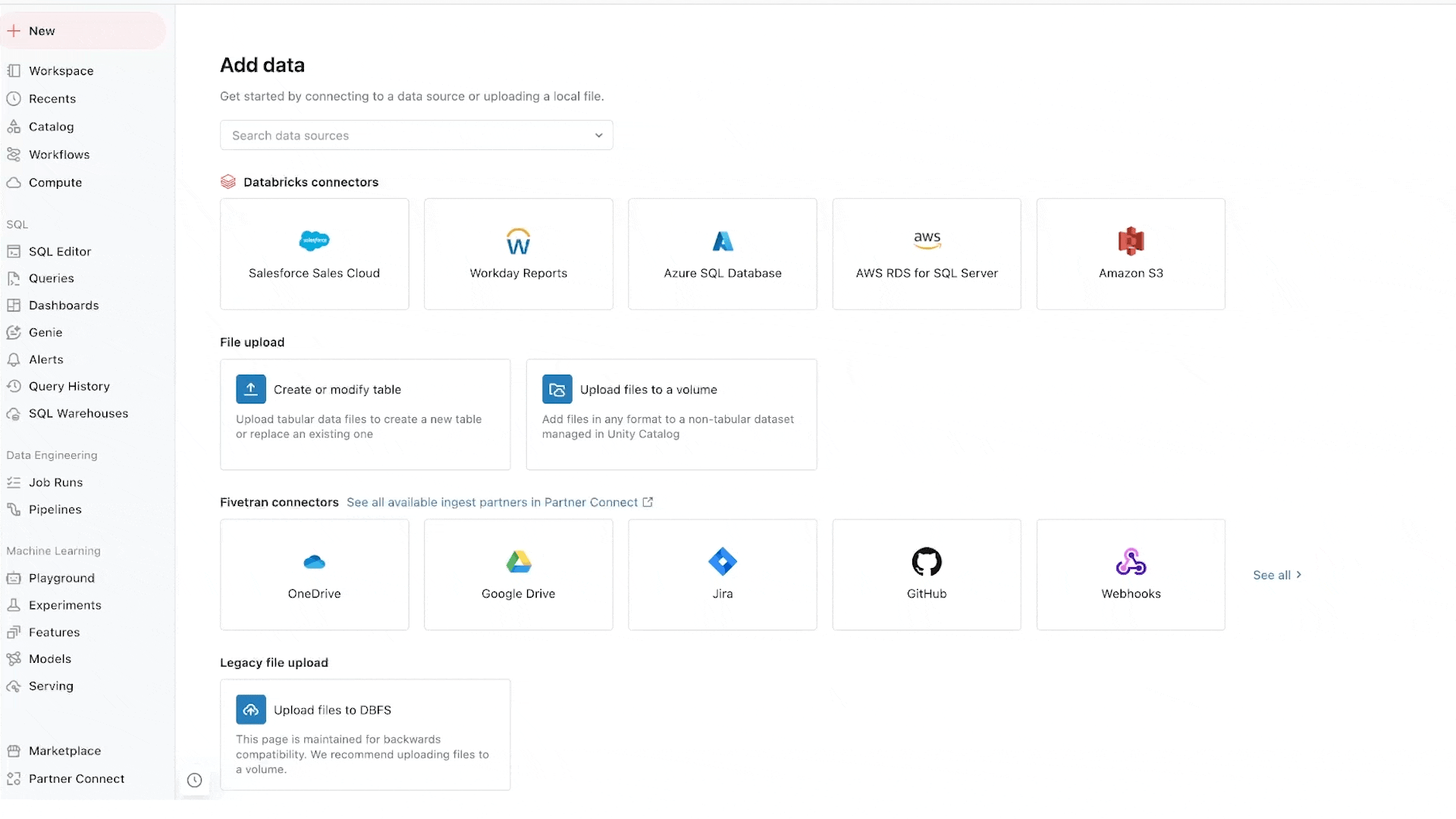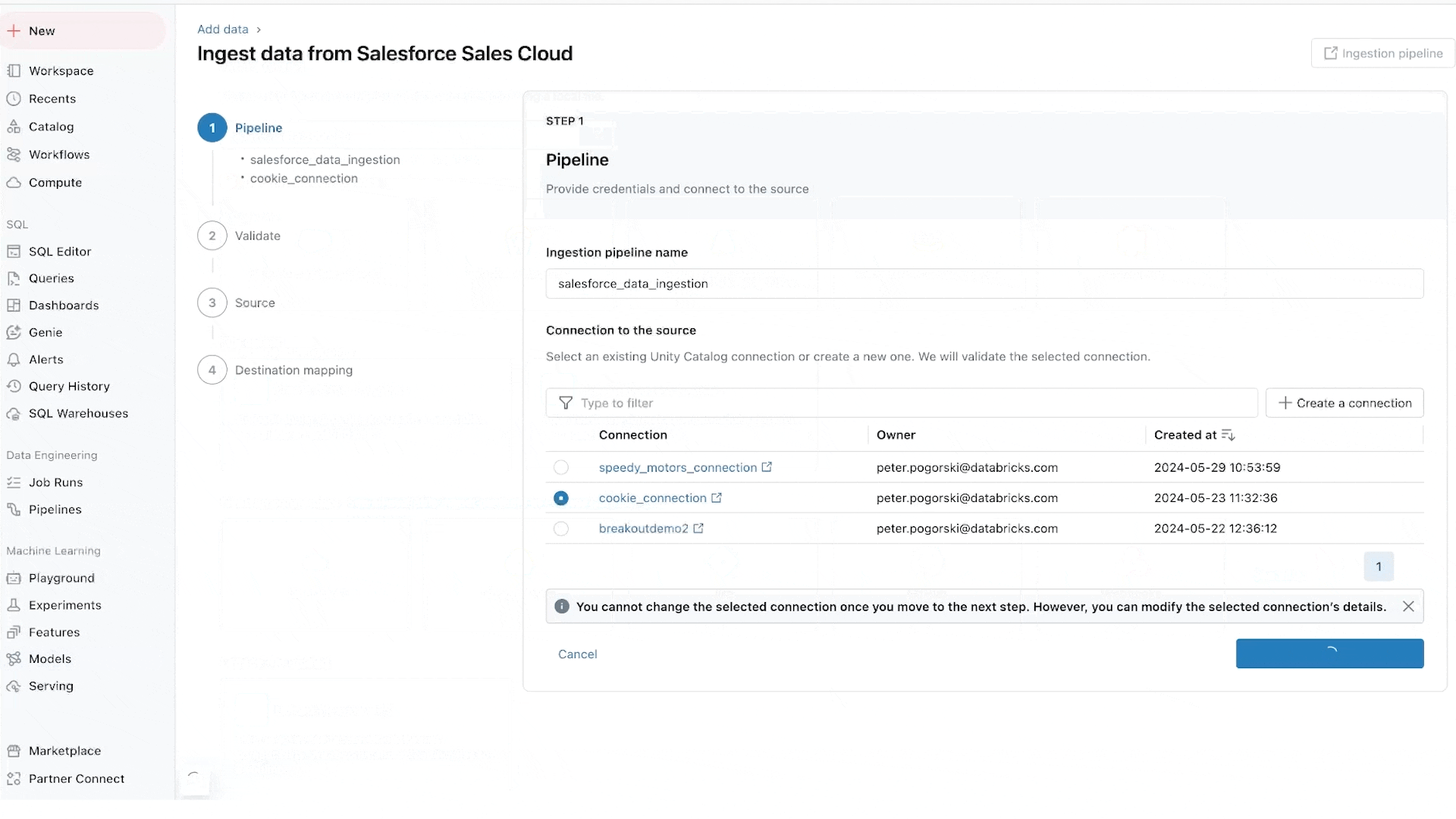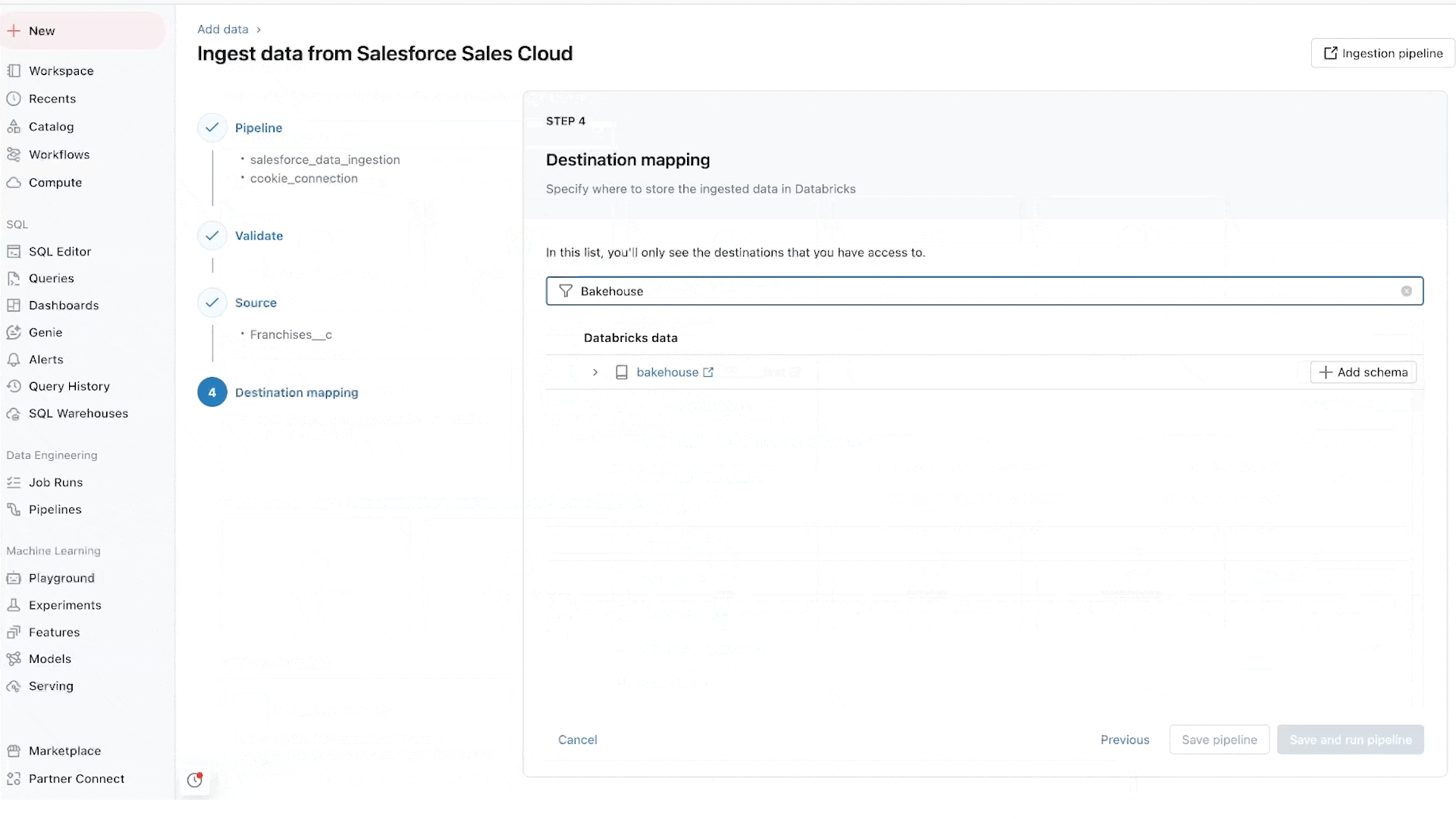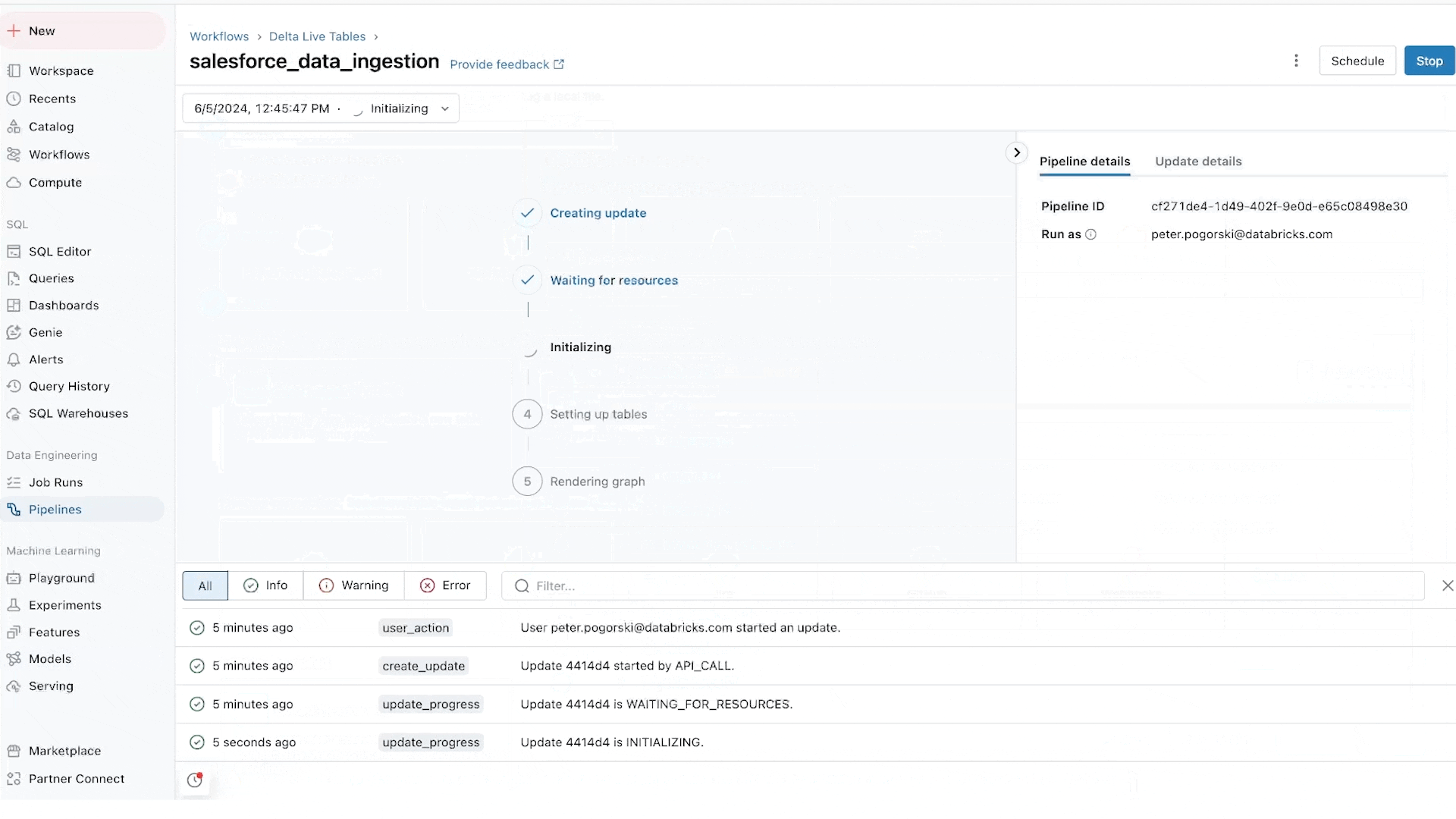
Estamos particularmente entusiasmados com os conectores de banco de dados, que são impulsionados pela nossa aquisição da Arcion. Uma quantidade incrível de dados valiosos está trancada em bancos de dados operacionais. Em vez de abordagens ingênuas para carregar esses dados, que enfrentam problemas operacionais e de escalabilidade, o Lakeflows usa a tecnologia de captura de dados de alteração (CDC) para tornar simples, confiável e operacionalmente eficiente trazer esses dados para o seu lakehouse.
Clientes Databricks que usam o Lakeflow Connect descobrem que uma solução de ingestão simples melhora a produtividade e permite que eles avancem mais rapidamente de dados para insights. A Insulet, fabricante de um sistema vestível de gerenciamento de insulina, o Omnipod, usa o conector de ingestão Salesforce para ingerir dados relacionados ao feedback do cliente em sua solução de dados construída no Databricks. Esses dados são disponibilizados para análise por meio do Databricks SQL para obter insights sobre problemas de qualidade e rastrear reclamações de clientes. A equipe encontrou valor significativo no uso das novas capacidades do Lakeflow Connect.
"Com o novo conector de ingestão Salesforce do Databricks, simplificamos significativamente nosso processo de integração de dados, eliminando middleware frágeis e problemáticos. Essa melhoria permite que o Databricks SQL analise diretamente os dados do Salesforce dentro do Databricks. Como resultado, nossos praticantes de dados agora podem entregar insights atualizados em tempo quase real, reduzindo a latência de dias para minutos." —Bill Whiteley, Senior Director of AI, Analytics, and Advanced Algorithms, Insulet
Lakeflow Pipelines: Pipelines de dados declarativos eficientes
O Lakeflow Pipelines reduz a complexidade de construir e gerenciar pipelines de dados eficientes em batch e streaming. Construído na estrutura declarativa Delta Live Tables, ele libera você para escrever lógica de negócios em SQL e Python enquanto o Databricks automatiza a orquestração de dados, o processamento incremental e o auto-escalonamento da infraestrutura de computação em seu nome. Além disso, o Lakeflow Pipelines oferece monitoramento de qualidade de dados integrado e seu Modo em Tempo Real permite a entrega consistente de baixa latência de conjuntos de dados sensíveis ao tempo sem nenhuma alteração de código.
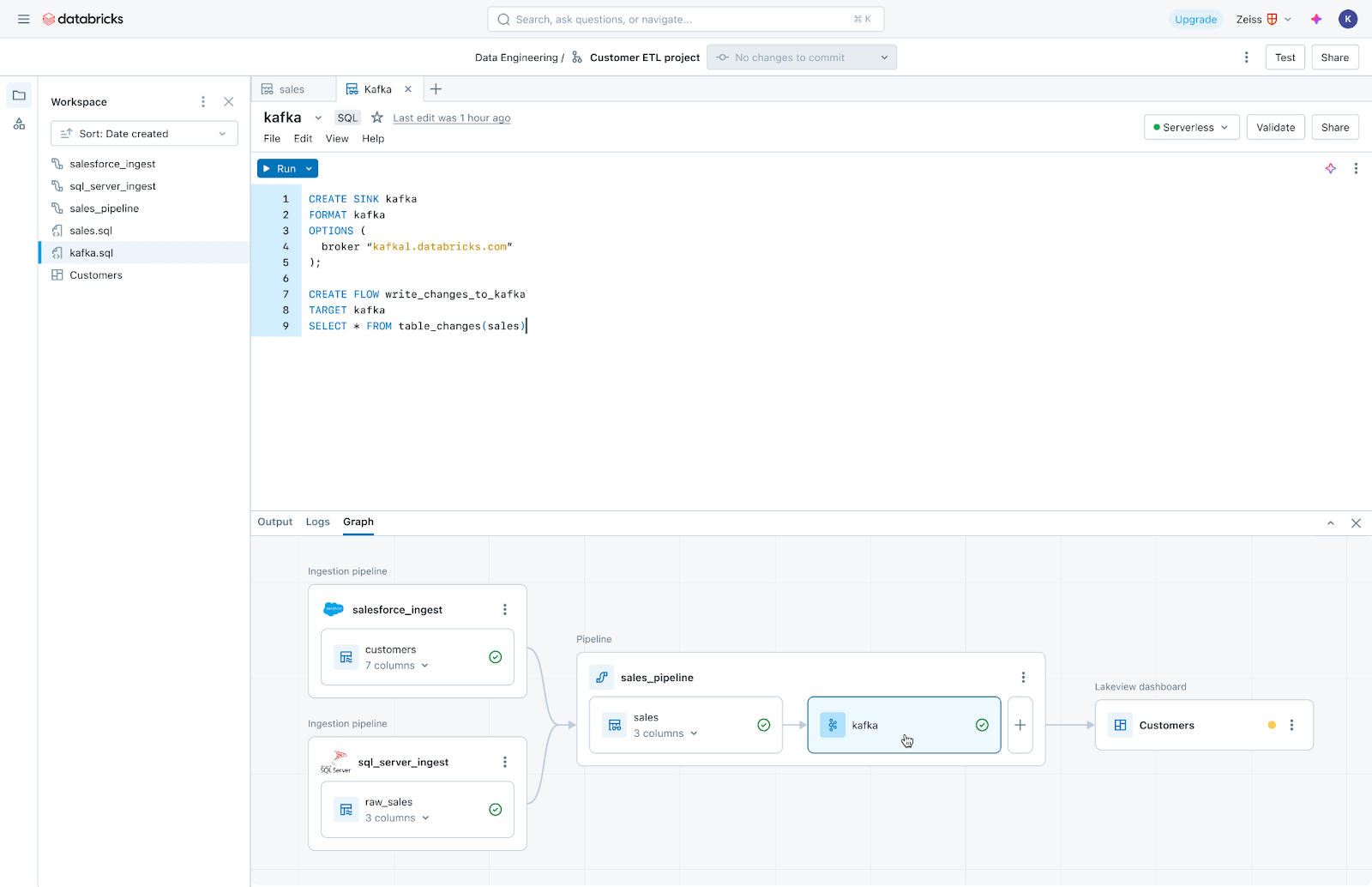
Lakeflow Jobs: Orquestração confiável para cada carga de trabalho
O Lakeflow Jobs orquestra e monitora cargas de trabalho de produção de forma confiável. Construído sobre as capacidades avançadas do Databricks Workflows, ele orquestra qualquer carga de trabalho, incluindo ingestão, pipelines, notebooks, consultas SQL, treinamento de machine learning, implantação de modelos e inferência. As equipes de dados também podem alavancar gatilhos, ramificações e loops para atender a casos de uso complexos de entrega de dados.
O Lakeflow Jobs também automatiza e simplifica o processo de compreensão e rastreamento da saúde e entrega dos dados. Ele adota uma visão de saúde orientada a dados, fornecendo às equipes de dados a linhagem completa, incluindo relacionamentos entre ingestão, transformações, tabelas e dashboards. Além disso, ele rastreia a atualidade e a qualidade dos dados, permitindo que as equipes de dados adicionem monitores por meio do Lakehouse Monitoring com um clique.
Construído na Plataforma de Inteligência de Dados
O Databricks Lakeflow é integrado nativamente à nossa Plataforma de Inteligência de Dados, que traz estas capacidades:
- Inteligência de dados: A inteligência impulsionada por IA não é apenas um recurso do Lakeflow, é uma capacidade fundamental que afeta todos os aspectos do produto. O Databricks Assistant impulsiona a descoberta, autoria e monitoramento de pipelines de dados, para que você possa gastar mais tempo construindo dados confiáveis.
- Governança unificada: O Lakeflow também é profundamente integrado ao Unity Catalog, que impulsiona a linhagem e a qualidade dos dados.
- Computação serverless: Construa e orquestre pipelines em escala e ajude sua equipe a focar no trabalho sem ter que se preocupar com a infraestrutura.
O futuro da engenharia de dados é simples, unificado e inteligente
Acreditamos que o Lakeflow permitirá que nossos clientes entreguem dados mais frescos, completos e de maior qualidade para seus negócios. O Lakeflow entrará em preview em breve, começando com o Lakeflow Connect. Se você gostaria de solicitar acesso, inscreva-se aqui. Nos próximos meses, fique atento a mais anúncios do Lakeflow à medida que capacidades adicionais se tornarem disponíveis.
Quer ver em ação?
Experimente o Tour do Produto Lakeflow para ingerir, transformar e implantar dados de várias fontes de forma integrada em batch e em tempo real para produção.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.