Apresentando a Prévia Pública da Busca Vetorial do Databricks
por Akhil Gupta, Sergei Tsarev e Eric Peter
Após o anúncio que fizemos ontem sobre a Geração Aumentada de Recuperação (RAG), hoje temos o prazer de anunciar a prévia pública da Busca Vetorial do Databricks. Anunciamos a prévia privada para um grupo seleto de clientes na Data + AI Summit em junho, e agora ela está disponível para todos os nossos clientes. Databricks AI Search permite que os desenvolvedores melhorem a precisão de seus aplicativos de Geração Aumentada de Recuperação (RAG) e AI generativa por meio de busca por similaridade em documentos não estruturados, como PDFs, documentos do Office, wikis e muito mais. A Busca Vetorial faz parte da Databricks Data Intelligence Platform, facilitando para seus aplicativos RAG e AI Generativa o uso dos dados proprietários armazenados em seu Lakehouse de forma rápida e segura, fornecendo respostas precisas.
Projetamos a Busca Vetorial do Databricks para ser rápida, segura e fácil de usar.
- Rápido com baixo custo total de propriedade (TCO) - O AI Search foi projetado para oferecer alto desempenho com menor custo total de propriedade (TCO), com latência até 5 vezes menor do que outros provedores.
- Experiência de desenvolvimento simples e rápida - A Busca Vetorial permite sincronizar qualquer tabela Delta em um índice vetorial com um único clique - sem a necessidade de um pipeline de ingestão de dados/sincronização complexo e personalizado.
- Governança Unificada - O AI Search utiliza as mesmas ferramentas de segurança e governança de dados baseadas no Unity Catalog que já alimentam sua Plataforma de Inteligência de Dados. Isso significa que você não precisa criar e manter um conjunto separado de políticas de governança de dados para seus dados não estruturados.
- EscalabilidadeServerless - Nossa infraestrutura Serverless escala automaticamente de acordo com seu fluxo de trabalho, sem a necessidade de configurar instâncias e tipos de servidor.
O que é busca vetorial?
A busca vetorial é um método utilizado em aplicações de recuperação de informação e Geração Aumentada de Recuperação (RAG) para encontrar documentos ou registros com base em sua similaridade a uma query. A busca vetorial é o motivo pelo qual você pode digitar uma query em linguagem simples, como "sapatos azuis que combinam com sexta à noite", e obter resultados relevantes.
As gigantes da tecnologia usam a busca vetorial há anos para aprimorar a experiência de seus produtos — com o advento da AI generativa, essas capacidades finalmente se tornaram acessíveis a todas
organizações. Segue abaixo uma explicação detalhada de como funciona a Busca Vetorial:
Incorporações (embeddings): Na busca vetorial, os dados e a consulta são representados como vetores em um espaço multidimensional chamado incorporação (embedding), a partir de um modelo AI generativa.
Vamos considerar um exemplo simples em que queremos usar a busca vetorial para encontrar palavras semanticamente semelhantes em um grande conjunto de palavras. Portanto, se você query o corpus com a palavra 'cachorro', você espera que palavras como 'filhote' sejam retornadas. Mas, se você pesquisar por 'carro', você quer encontrar palavras como 'van'. Na busca tradicional, você terá que manter uma lista de sinônimos ou "palavras semelhantes", o que é difícil de gerar ou escalar. Para usar a busca vetorial, você pode, em vez disso, usar um modelo AI generativa para converter essas palavras em vetores em um espaço n-dimensional chamado embeddings. Esses vetores terão a propriedade de que palavras semanticamente semelhantes, como 'cachorro' e 'filhote', estarão mais próximas umas das outras no espaço n-dimensional do que as palavras 'cachorro' e 'carro'.
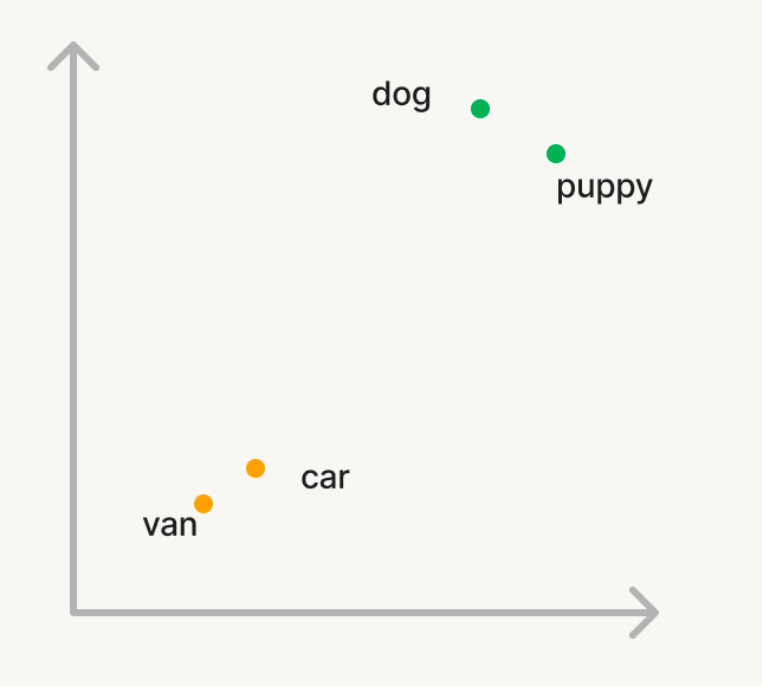
Cálculo de similaridade: Para encontrar documentos relevantes para uma query, calcula-se a similaridade entre o vetor query e o vetor de cada documento, a fim de medir o quão próximos eles estão uns dos outros no espaço n-dimensional. Normalmente, isso é feito usando a similaridade de cosseno, que mede o cosseno do ângulo entre os dois vetores. Existem diversos algoritmos utilizados para encontrar vetores semelhantes de forma eficiente, sendo os algoritmos baseados em HNSW consistentemente os que apresentam melhor desempenho.
Aplicações: A busca vetorial tem muitos casos de uso:
- Recomendações - recomendações personalizadas e contextuais para os usuários.
- RAG - fornecendo documentos não estruturados relevantes para ajudar um aplicativo RAG a responder às perguntas do usuário.
- Busca semântica - permitindo consultas de busca em linguagem natural que fornecem resultados relevantes.
- clustering de documentos - compreender semelhanças e diferenças entre dados
Por que os clientes adoram a Busca Vetorial do Databricks?
"Estamos muito satisfeitos em aproveitar as poderosas soluções da Databricks para transformar nossas operações de suporte ao cliente na Lippert." Gerir um ambiente de call center dinâmico para uma empresa do nosso porte representa um desafio significativo, especialmente no que diz respeito à integração rápida de novos agentes em meio à rotatividade típica da equipe. Databricks fornece a key para nossas soluções: ao configurar uma experiência de assistência ao agente, impulsionada pela Busca Vector, podemos capacitar nossos agentes a encontrar rapidamente respostas para as dúvidas dos clientes. Ao incorporar conteúdo de manuais de produtos, vídeos do YouTube e casos de suporte em nossa Busca Vetorial, Databricks garante que nossos agentes tenham o conhecimento necessário ao alcance de suas mãos. Essa abordagem inovadora é um divisor de águas para a Lippert, aumentando a eficiência e elevando a experiência de suporte ao cliente.”-Chris Nishnick, Inteligência Artificial, Lippert
Ingestão automática de dados
Antes que um banco de dados vetorial possa armazenar informações, ele requer um pipeline de ingestão de dados, onde dados brutos e não processados de várias fontes precisam ser limpos, processados (analisados/fragmentados) e incorporados a um modelo AI antes de serem armazenados como vetores no banco de dados. Esse processo de construção e manutenção de outro conjunto de pipelines de ingestão de dados é caro e demorado, consumindo tempo de recursos valiosos da engenharia. Databricks AI Search está totalmente integrado à Databricks Data Intelligence Platform, permitindo extrair e incorporar dados automaticamente, sem a necessidade de criar e manter novos pipelines de dados.
Nossas APIs Delta Sync sincronizam automaticamente os dados de origem com os índices vetoriais. À medida que os dados de origem são adicionados, atualizados ou excluídos, atualizamos automaticamente o índice do vetor correspondente para que haja correspondência. Nos bastidores, o AI Search gerencia falhas, lida com novas tentativas e otimiza os tamanhos Batch para fornecer o melhor desempenho e throughput sem qualquer trabalho ou intervenção sua. Essas otimizações reduzem o custo total de propriedade devido ao aumento da utilização do seu Endpoint do modelo de incorporação.
Vejamos um exemplo onde criamos um índice vetorial em três passos simples. Todas as funcionalidades de Busca Vetorial estão disponíveis através de APIs REST, do nosso SDK em Python ou na interface de usuário do Databricks.
o passo 1. Crie um Endpoint de pesquisa vetorial que será usado para criar e query um índice vetorial usando a interface do usuário ou nossa API REST /SDK.
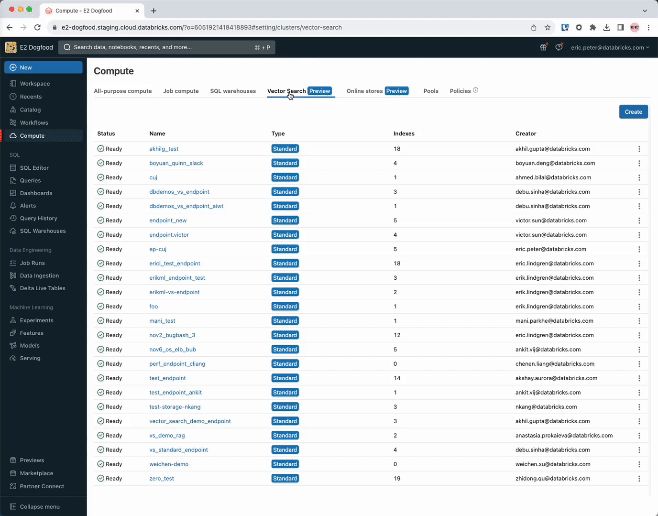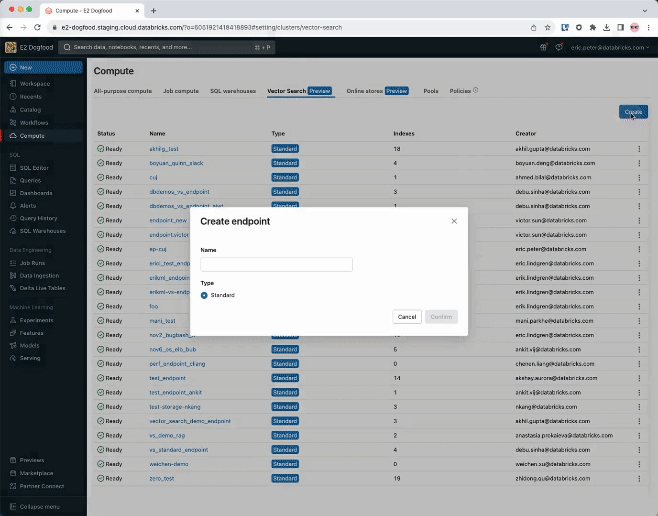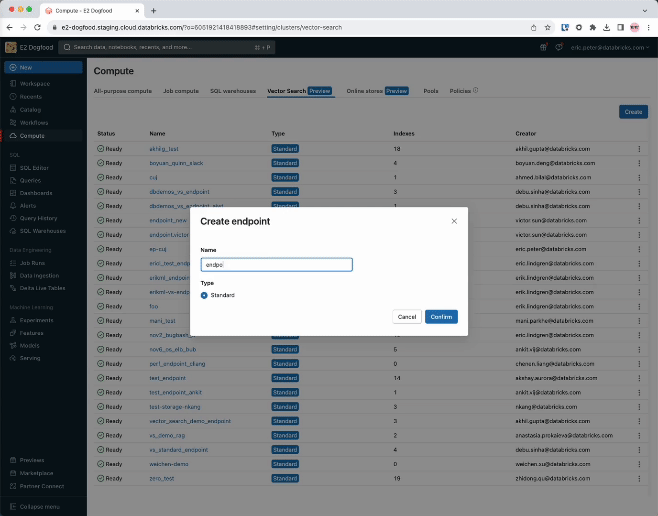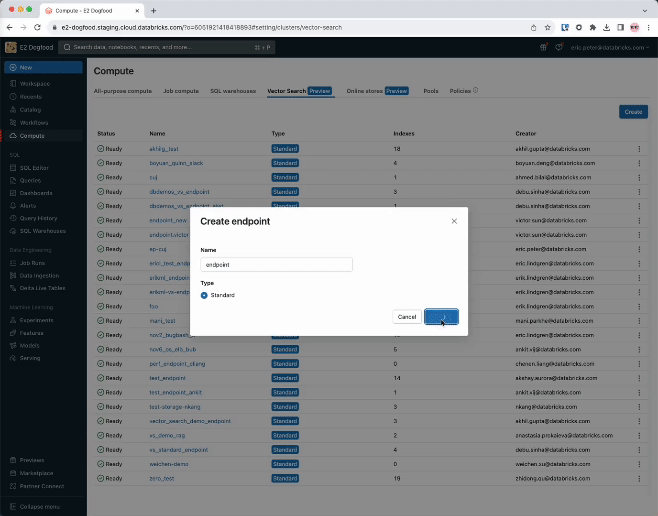
Na etapa 2, após criar uma tabela Delta com seus dados de origem, você seleciona uma coluna na tabela Delta para incorporar e, em seguida, seleciona um Endpoint Model Serving que será usado para gerar incorporações para os dados.
O modelo de incorporação pode ser:
- Um modelo que você aperfeiçoou
- Um modelo de código aberto pronto para uso (como E5, BGE, InstructorXL, etc.)
- Um modelo de incorporação proprietário disponível via API (como OpenAI, Cohere, Anthropic, etc.)
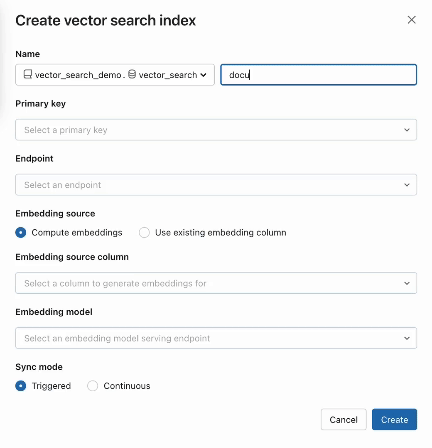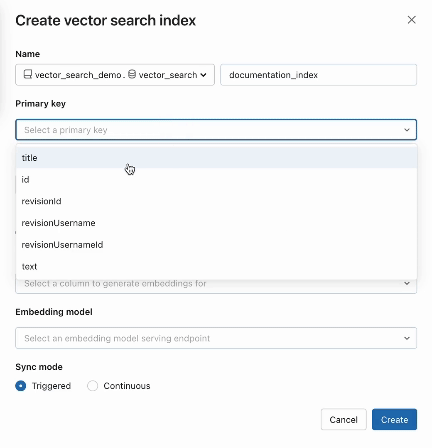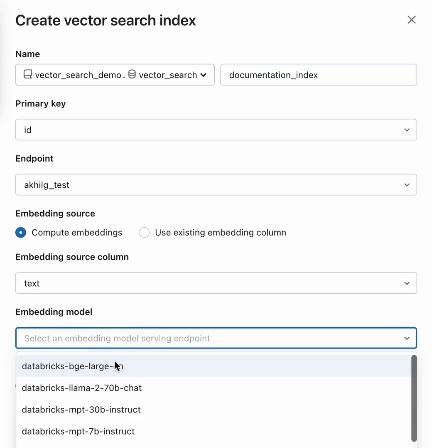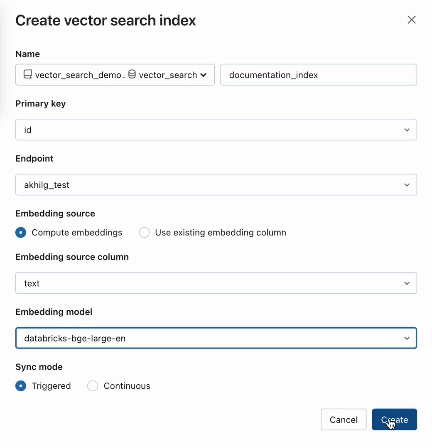
O AI Search também oferece modos avançados para clientes que preferem gerenciar seus embeddings em uma tabela Delta ou criar um pipeline de ingestão de dados usando APIs REST . Para exemplos, consulte a documentação da Pesquisa Vetorial.
o passo 3. Assim que o índice estiver pronto, você poderá fazer uma consulta para encontrar vetores relevantes para sua query. Esses resultados podem então ser enviados para o seu aplicativo de Geração Aumentada de Recuperação (RAG) .
"Este produto é fácil de usar e estávamos a começar a utilizá-lo em poucas horas." Todos os nossos dados já estão em Delta , então a experiência de gerenciamento integrado do AI Search com sincronização Delta é incrível." —- Alex Dalla Piazza (EQT Corporation)“
Governança integrada
As organizações empresariais exigem controles de segurança e acesso rigorosos sobre seus dados, portanto, os usuários não podem usar modelos AI generativa para obter dados confidenciais aos quais não deveriam ter acesso. No entanto, os bancos de dados Vector atuais ou não possuem controles de segurança e acesso robustos, ou exigem que as organizações criem e mantenham um conjunto separado de políticas de segurança, independente de sua plataforma de dados. Ter vários conjuntos de segurança e governança aumenta o custo e a complexidade, além de ser propenso a erros na manutenção confiável.
A Busca Vetorial do Databricks utiliza os mesmos controles de segurança e governança de dados que já protegem o restante da Plataforma de Inteligência de Dados, possibilitada pela integração com o Unity Catalog. Os índices vetoriais são armazenados como entidades dentro do seu Unity Catalog e utilizam a mesma interface unificada para definir políticas sobre os dados, com controle preciso sobre as incorporações.
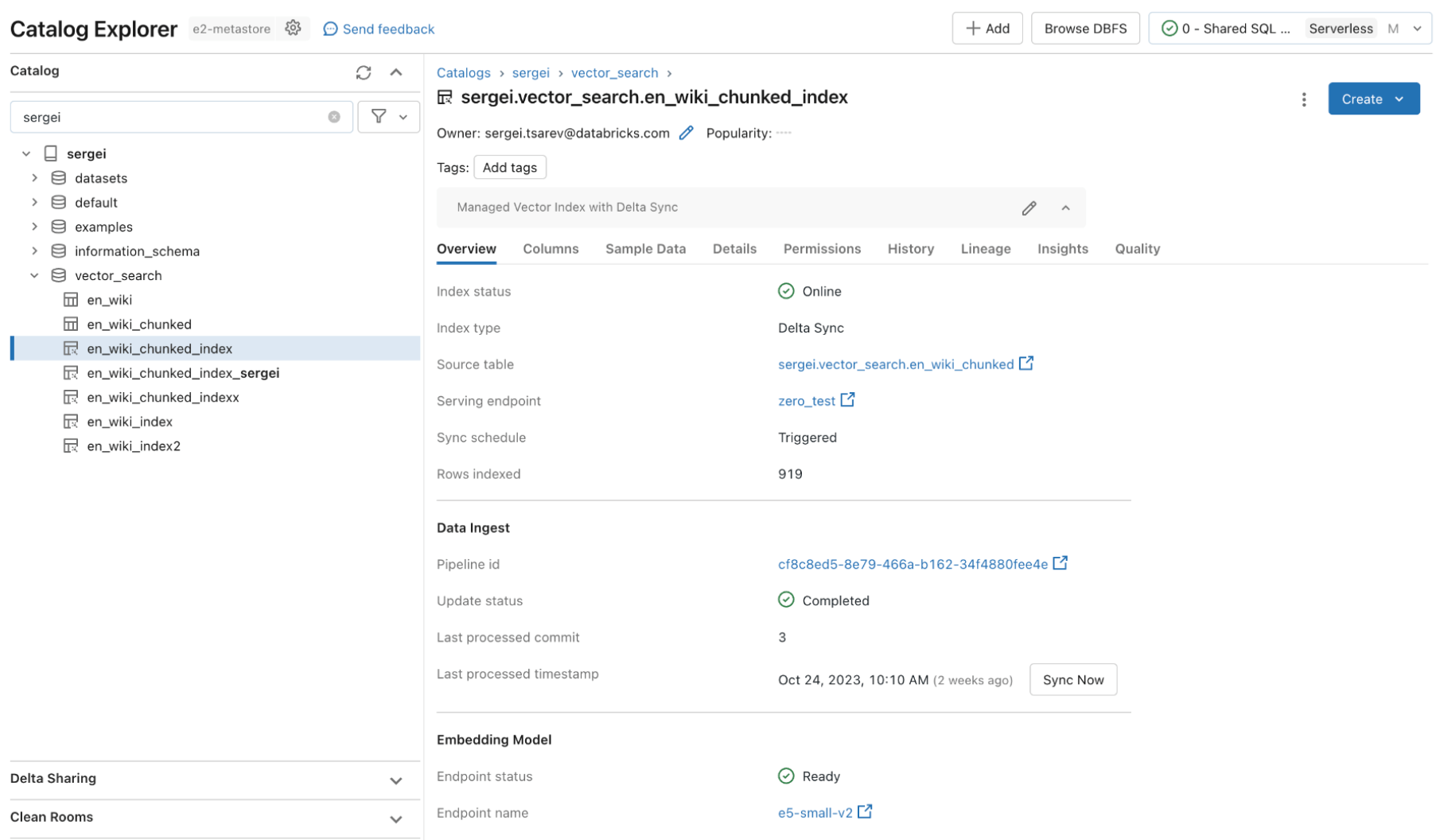
Desempenho de consulta rápido
Devido à maturidade do mercado, muitos bancos de dados vetoriais apresentam bons resultados em provas de conceito (POCs) com pequenas quantidades de dados. No entanto, muitas vezes deixam a desejar em termos de desempenho ou escalabilidade para implantações em produção. Com um desempenho inicial ruim, os usuários terão que descobrir como ajustar e escalar os índices de pesquisa, o que consome tempo e é difícil de fazer bem. Eles são forçados a entender sua carga de trabalho e a fazer escolhas difíceis sobre quais instâncias compute selecionar e qual configuração usar.
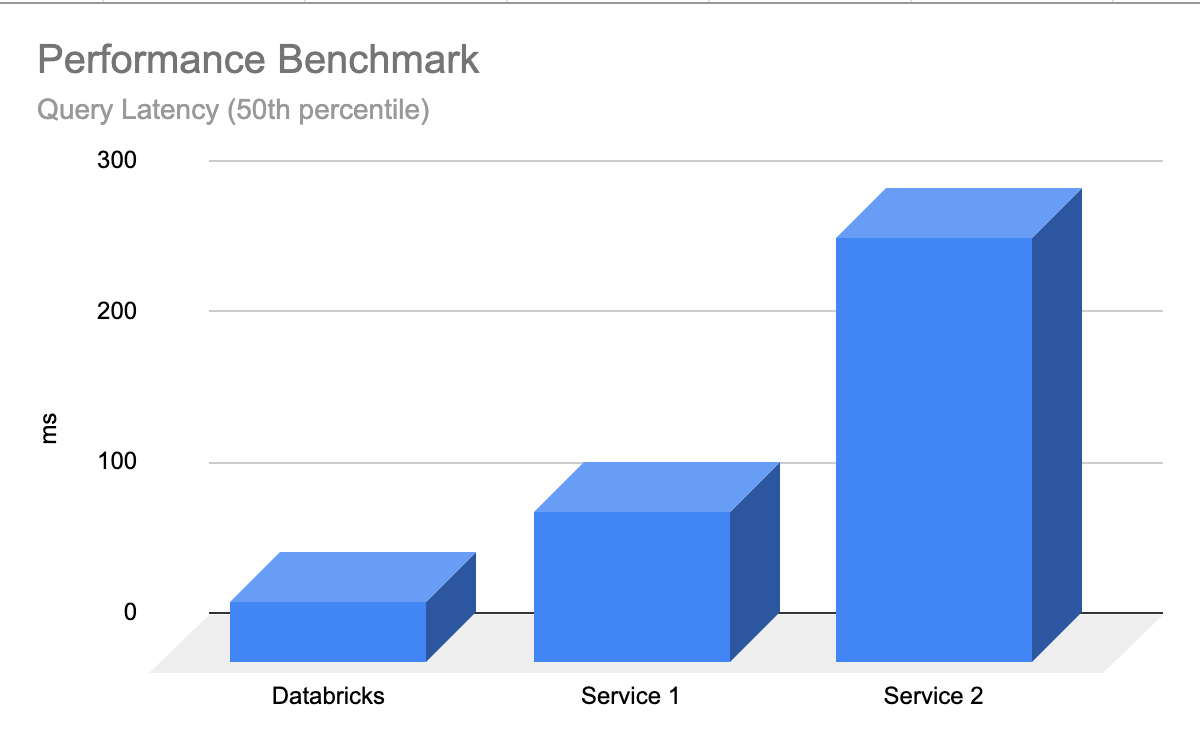
A Busca Vetorial Databricks oferece alto desempenho logo de início, com os Modelos de Aprendizado de Liderança (LLMs) retornando resultados relevantes rapidamente, com latência mínima e sem necessidade de ajustes ou escalonamento do banco de dados. A Busca Vetorial foi projetada para ser extremamente rápida em consultas com ou sem filtragem. Apresenta desempenho até 5 vezes melhor do que alguns dos outros principais bancos de dados vetoriais. É fácil de configurar: basta nos informar o tamanho esperado da sua carga de trabalho (por exemplo, consultas por segundo), a latência necessária e o número esperado de embeddings — nós cuidamos do resto. Você não precisa se preocupar com tipos de instância, RAM/CPU ou entender o funcionamento interno de como os bancos de dados vetoriais operam.
Investimos muito esforço na personalização Databricks AI Search para dar suporte a cargas de trabalho AI que milhares de nossos clientes já executam no Databricks. As otimizações incluíram a avaliação comparativa e a identificação do hardware mais adequado para a busca semântica, a otimização do algoritmo de busca subjacente e a redução da sobrecarga de rede para proporcionar o melhor desempenho em grande escala.
Próximos passos
start lendo nossa documentação e, especificamente, criando um índice de Busca Vetorial.
Saiba mais sobre os preçosda Busca Vetorial.
Iniciando a implantação do seu próprio aplicativo RAG (demonstração)
Inscreva-se no webinar AI generativa Databricks
Está procurando soluções para casos de uso AI generativa? Participe do Hackathon AI Generativa Databricks e AWS ! Inscreva-se aqui
Trilha de Aprendizagem para Engenheiro AI Generativa: faça cursos no seu próprio ritmo, sob demanda e com instrutor sobre AIGenerativa.
Leia os comunicados resumidos feitos no início desta semana
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.