Latência de subsegundo no Apache Spark Structured Streaming
Melhorando o gerenciamento de offset no Projeto Lightspeed
por Jerry Peng, Pranav Anand, Sourav Gulati, Karthik Ramasamy, Michael Armbrust e Matei Zaharia
Apache Spark Structured Streaming é a principal plataforma de processamento de stream de código aberto. É também a tecnología principal que potencializa a transmissão na Databricks Lakehouse Platform e fornece uma API unificada para processamento em lotes e de stream. Com o rápido crescimento da adoção de transmissão, diversas aplicações querem aproveitá-lo para a tomada de decisões em tempo real. Algumas dessas aplicações, especialmente as de natureza operacional, exigem menor latência. Embora o design do Spark permita alta throughput e facilidade de uso a um custo menor, ele não foi otimizado para latência abaixo de um segundo.
Neste blog, focaremos nas melhorias que fizemos no gerenciamento de offset para reduzir a latência de processamento inerente do Structured Streaming. Essas melhorias visam principalmente casos de uso operacionais, como monitoramento e alerta em tempo real, que são simples e sem estado.
Uma avaliação extensiva dessas melhorias indica que a latência melhorou em 68-75% - ou até 3X - de 700-900 ms para 150-250 ms para throughputs de 100 mil eventos/s, 500 mil eventos/s e 1 milhão de eventos/s. O Structured Streaming agora pode atingir latências inferiores a 250 ms, satisfazendo os requisitos de SLA para uma grande porcentagem de cargas de trabalho operacionais.
Este artigo pressupõe que o leitor tenha um conhecimento básico do Spark Structured Streaming. Consulte a documentação a seguir para saber mais:
https://www.databricks.com/spark/getting-started-with-apache-spark/streaming
https://docs.databricks.com/structured-streaming/index.html
https://www.databricks.com/glossary/what-is-structured-streaming
https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
Motivação
O Apache Spark Structured Streaming é um mecanismo de processamento de fluxo distribuído criado com base no mecanismo Apache Spark SQL. Ele fornece uma API que permite que os desenvolvedores processem fluxos de dados escrevendo consultas de transmissão da mesma forma que as consultas em lotes, facilitando a análise e o teste de aplicações de transmissão. De acordo com os downloads do Maven, o Structured Streaming é o mecanismo de transmissão distribuída de código aberto mais usado atualmente. Um dos principais motivos de sua popularidade é o desempenho: alto throughput a um custo mais baixo com uma latência de ponta a ponta inferior a alguns segundos. O Structured Streaming dá aos usuários a flexibilidade de equilibrar a compensação entre taxa de transferência, custo e latência.
À medida que a adoção de transmissão cresce rapidamente no ambiente corporativo, existe o desejo de permitir que um conjunto diversificado de aplicativos use a arquitetura de dados de transmissão. Em nossas conversas com muitos clientes, encontramos casos de uso que exigem latência consistente de sub-segundo. Esses casos de uso de baixa latência surgem de aplicações como alerta operacional e monitoramento em tempo real, também conhecidos como "cargas de trabalho operacionais". Para acomodar essas cargas de trabalho no Structured Streaming, em 2022, lançamos uma iniciativa de melhoria de desempenho no âmbito do Project Lightspeed. Esta iniciativa identificou áreas e técnicas potenciais que podem ser usadas para melhorar a latência de processamento. Neste blog, descrevemos detalhadamente uma dessas áreas para melhoria: o gerenciamento de offset para acompanhamento do progresso e como ele alcança latência de sub-segundo para cargas de trabalho operacionais.
O que são cargas de trabalho operacionais?
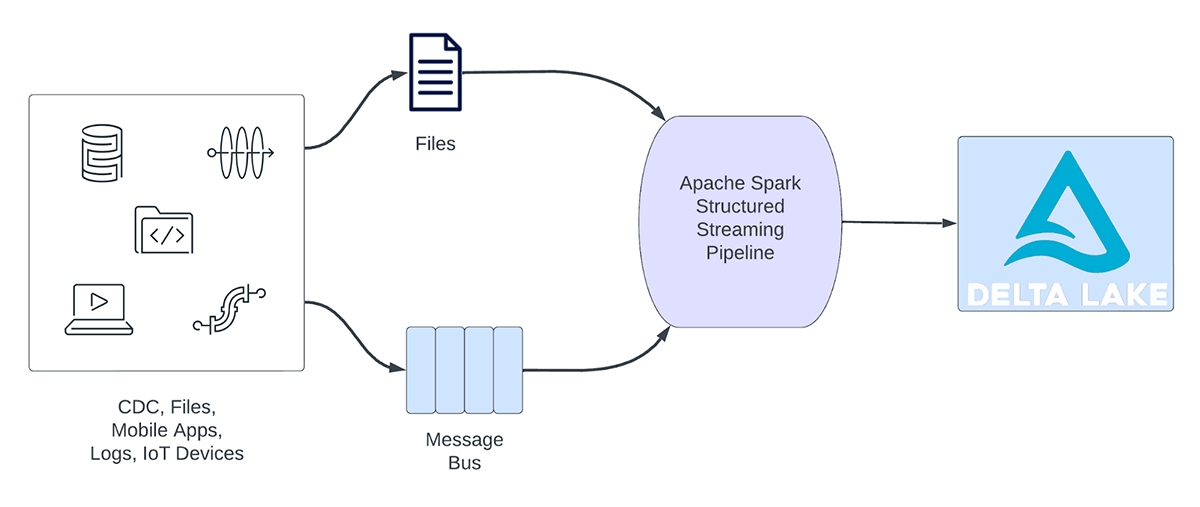
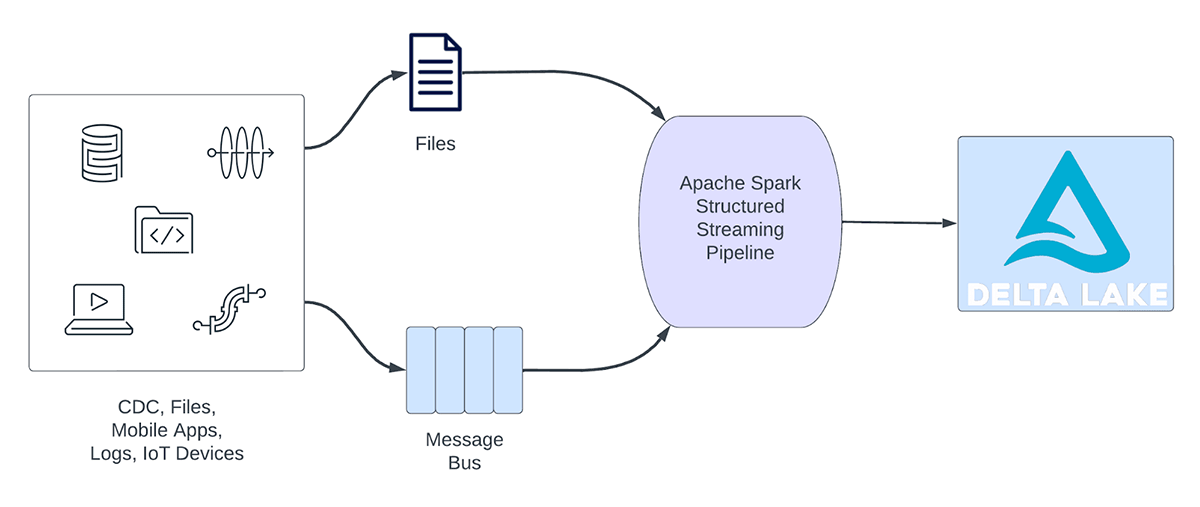
As cargas de trabalho de transmissão podem ser amplamente categorizadas em cargas de trabalho analíticas e cargas de trabalho operacionais. A Figura 1 ilustra tanto as cargas de trabalho analíticas quanto as operacionais. As cargas de trabalho analíticas normalmente ingerem, transformam, processam e analisam dados em tempo real e gravam os resultados no Delta Lake com o respaldo de armazenamento de objetos como AWS S3, Azure Data Lake Gen2 e Google Cloud Storage. Esses resultados são consumidos por mecanismos de data warehousing e ferramentas de visualização subsequentes.
{kind=link}
{kind=link}
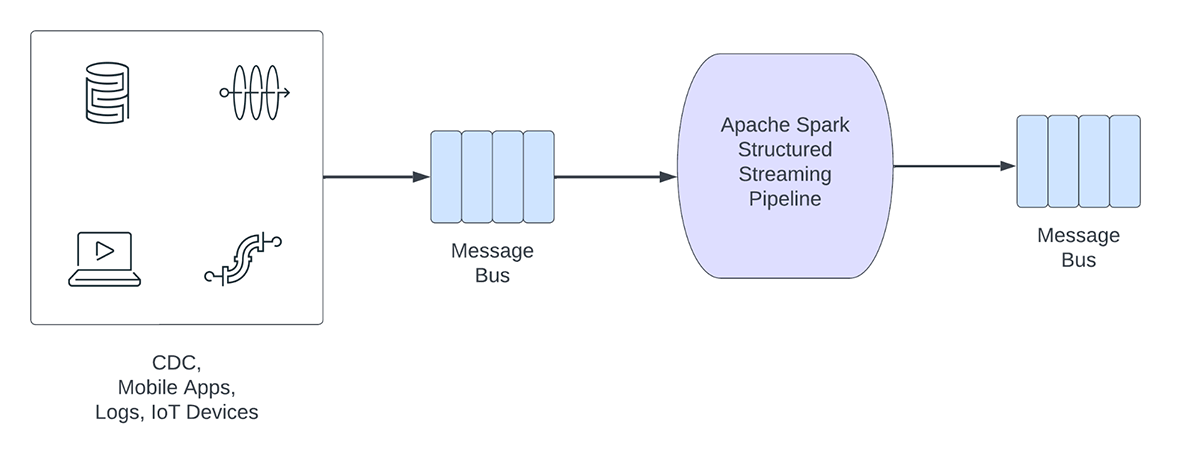
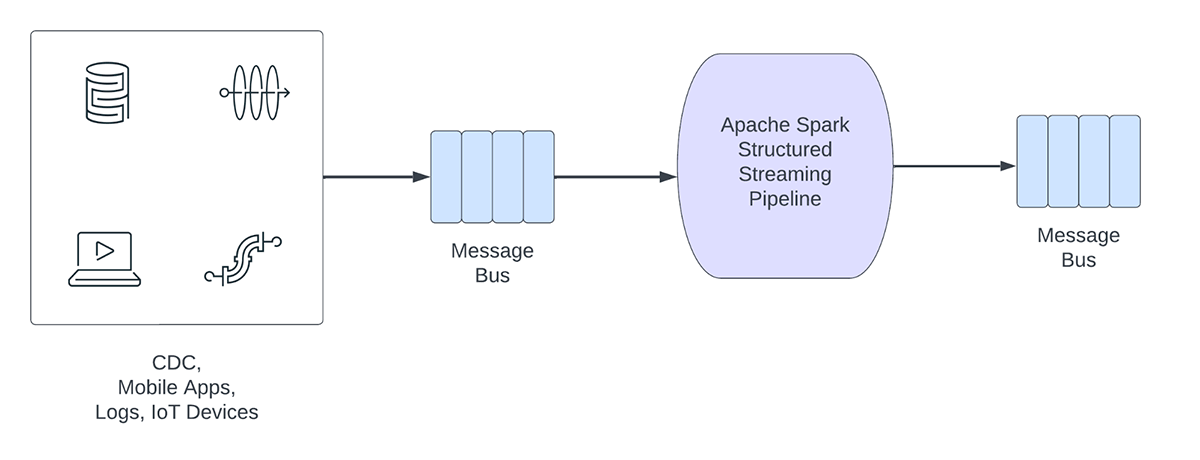
Figura 1. Cargas de trabalho analíticas vs. operacionais
Alguns exemplos de cargas de trabalho analíticas incluem:
- Análise de comportamento do cliente: uma empresa de marketing pode usar a transmissão analítica para analisar o comportamento do cliente em tempo real. Ao processar dados de clickstream, feeds de redes sociais e outras fontes de informação, o sistema pode detectar padrões e preferências que podem ser usados para direcionar os clientes de forma mais eficaz.
- Análise de sentimento: uma empresa pode usar dados de transmissão de suas accounts de redes sociais para analisar o sentimento do cliente em tempo real. Por exemplo, a empresa pode procurar clientes que estejam expressando sentimentos positivos ou negativos sobre os produtos ou serviços da empresa.
- IoT Analítica: uma cidade inteligente pode usar a transmissão analítica para monitorar o fluxo de tráfego, a qualidade do ar e outras métricas em tempo real. Ao processar dados de sensores espalhados pela cidade, o sistema pode detectar tendências e tomar decisões sobre padrões de tráfego ou políticas ambientais.
Por outro lado, as cargas de trabalho operacionais ingerem e processam dados em tempo real e acionam automaticamente um processo de negócio. Alguns exemplos dessas cargas de trabalho incluem:
- Cibersegurança: uma empresa pode usar dados de transmissão de sua rede para monitorar problemas de segurança ou desempenho. Por exemplo, a empresa pode procurar por picos de tráfego ou por acesso não autorizado a redes e enviar um alerta para o departamento de segurança.
- Vazamentos de Informações de Identificação Pessoal: uma empresa pode monitorar os logs de microsserviços, analisar e detectar se alguma informação de identificação pessoal (PII) está sendo vazada e, se estiver, informar por e-mail o proprietário do microsserviço.
- Despacho de elevador: uma empresa pode usar os dados de transmissão do elevador para detectar quando o botão de alarme de um elevador é ativado. Se ativado, ele poderá pesquisar informações adicionais do elevador para aprimorar os dados e enviar uma notificação para a equipe de segurança.
- Manutenção proativa: usar os dados de transmissão de um gerador de energia para monitorar a temperatura e, quando ela exceder um determinado limite, informar o supervisor.
Pipelines de transmissão operacionais compartilham as seguintes características:
- As expectativas de latência geralmente são de subsegundo
- Os pipelines leem de um barramento de mensagens
- Os pipelines geralmente realizam computação simples com transformação ou enriquecimento de dados
- Os pipelines gravam em um barramento de mensagens como o Apache Kafka ou o Apache Pulsar ou em armazenamentos rápidos de chave-valor como o Apache Cassandra ou o Redis para integração downstream com processos de negócios
Para esses casos de uso, quando perfilamos o Structured Streaming, identificamos que o gerenciamento de offsets para acompanhar o progresso dos micro-lotes consome um tempo substancial. Na próxima seção, vamos analisar o gerenciamento de offsets existente e descrever as melhorias nas seções subsequentes.
O que é gerenciamento de offset?
Para acompanhar o progresso de até que ponto os dados foram processados, o Spark Structured Streaming depende da persistência e do gerenciamento de offsets, que são usados como indicadores de progresso. Normalmente, um offset é definido concretamente pelo conector de origem, pois sistemas diferentes têm maneiras diferentes de representar o progresso ou as localizações nos dados. Por exemplo, uma implementação concreta de um offset pode ser o número da linha em um arquivo para indicar até que ponto os dados no arquivo foram processados. Logs duráveis (conforme ilustrado na Figura 2) são usados para armazenar esses offsets e marcar a conclusão de micro-lotes.
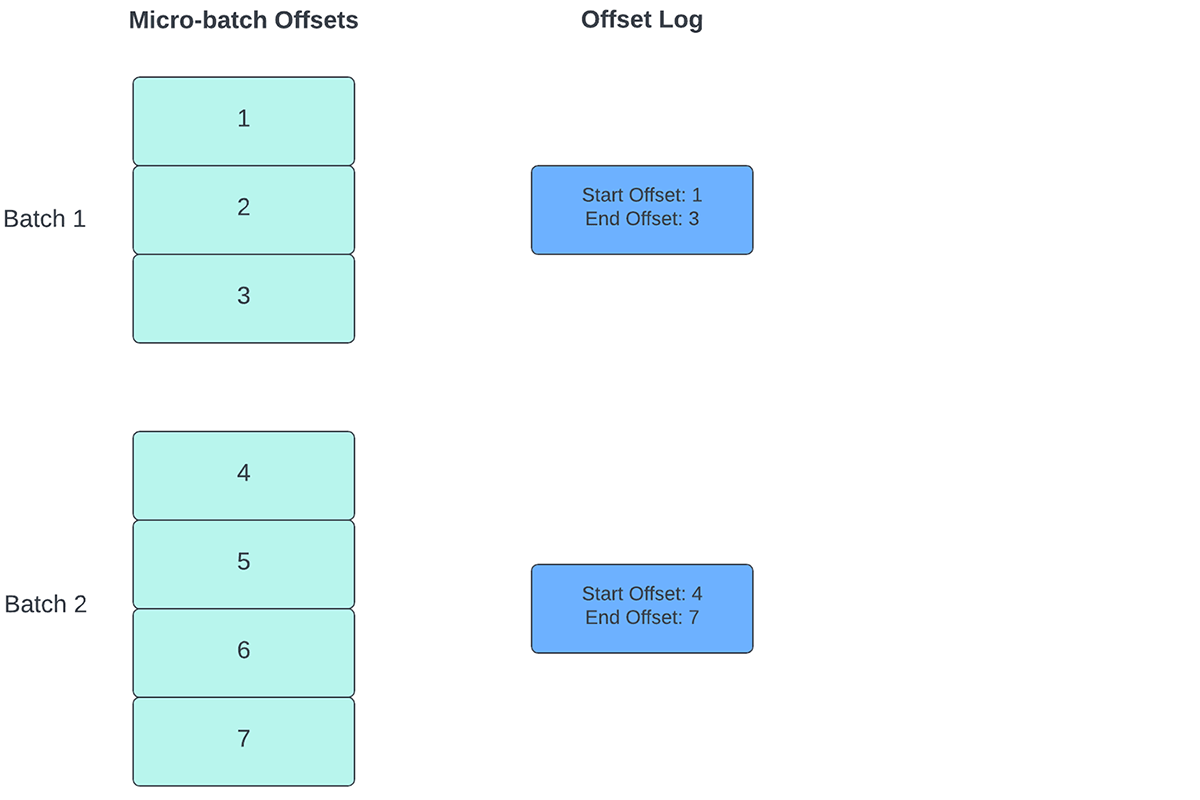
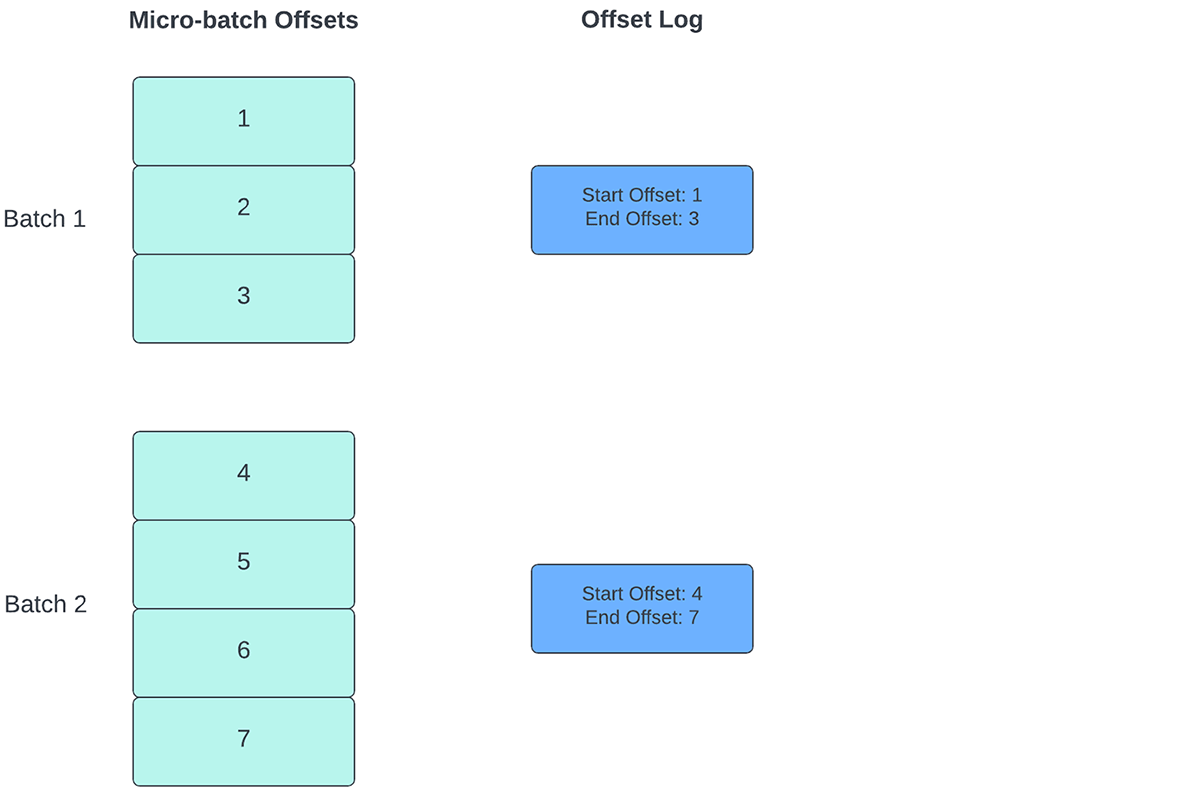{kind=link}
No Structured Streaming, os dados são processados em unidades de micro-lotes. Existem duas operações de gerenciamento de deslocamento realizadas para cada microlotes. Uma no início de cada microlote e outra no final.
- No início de cada microlote (antes que qualquer processamento de dados realmente começar), um offset é calculado com base nos novos dados que podem ser lidos do sistema de destino. Este offset é persistido em um log durável chamado "offsetLog" no diretório de checkpoint. Este offset é usado para calcular o intervalo de dados que será processado neste microlote.
- Ao final de cada micro-lote, uma entrada é persistida no log durável chamado de "commitLog" para indicar que "este" micro-lote foi processado com sucesso.
A Figura 3 abaixo descreve as operações atuais de gerenciamento de offset que ocorrem.
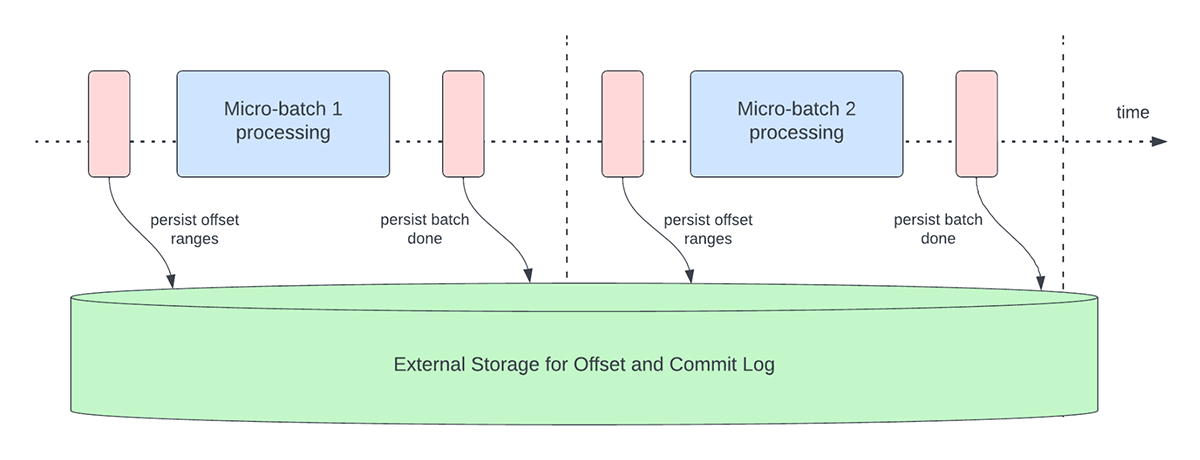
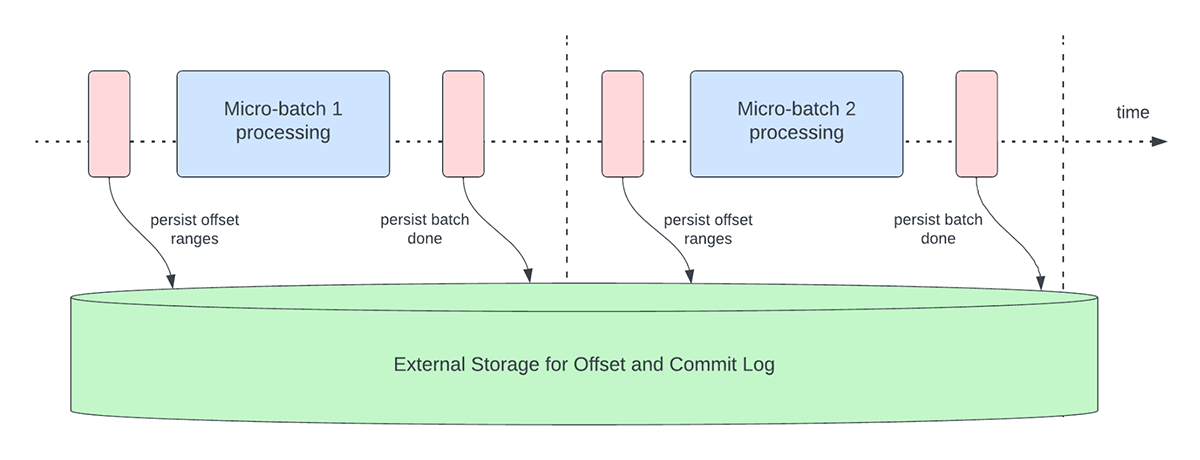{kind=link}
Outra operação de gerenciamento de deslocamento é realizada no final de cada microlote. Essa operação é uma operação de limpeza para excluir/truncar entradas antigas e desnecessárias tanto do offsetLog quanto do commitLog para que esses logs não cresçam de forma ilimitada.
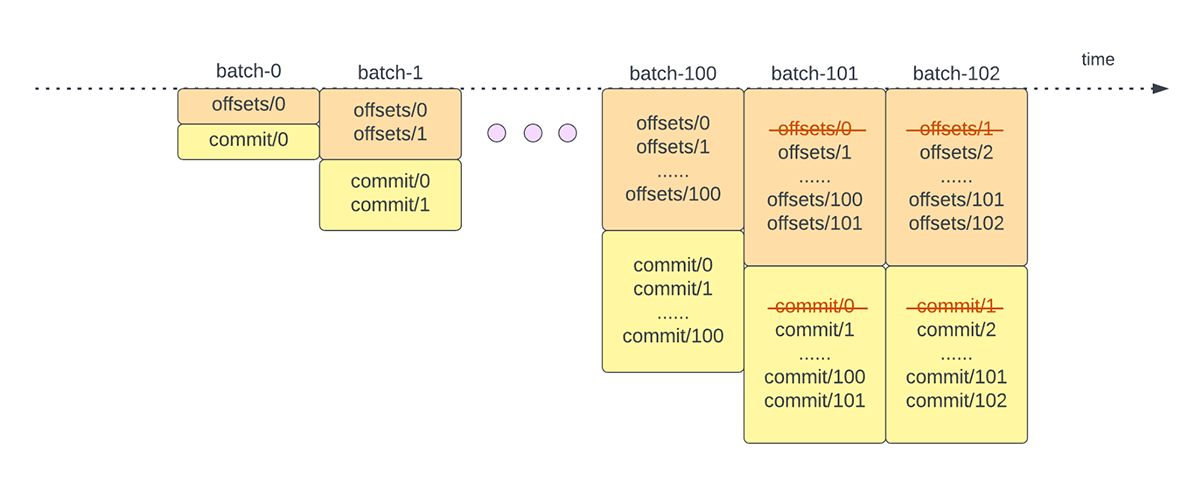
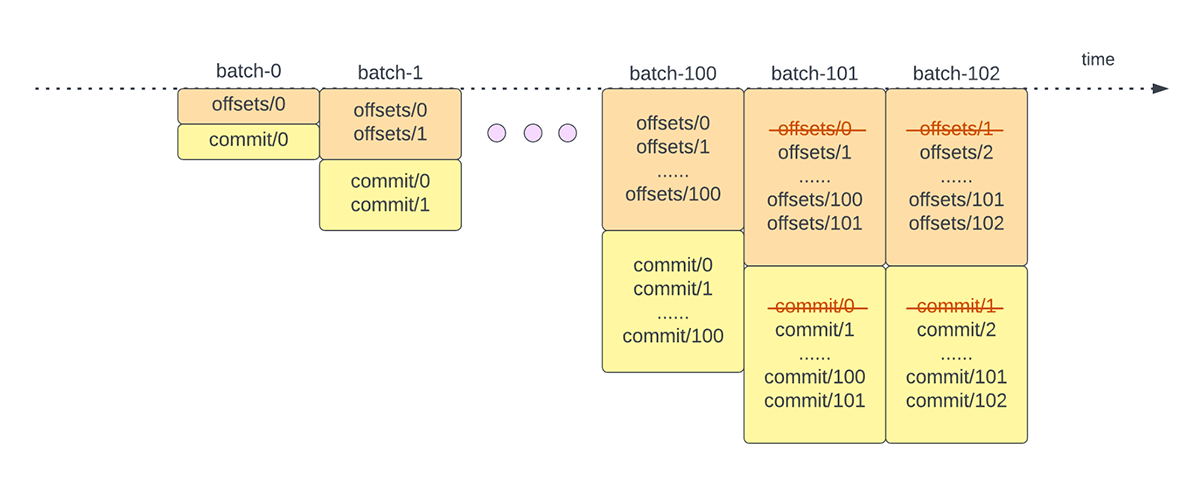{kind=link}
Essas operações de gerenciamento de offset são realizadas no caminho crítico e em linha com o processamento real dos dados. Isso significa que a duração dessas operações afeta diretamente a latência de processamento e nenhum processamento de dados pode ocorrer até que essas operações sejam concluídas. Isso também impacta diretamente a utilização do cluster.
Por meio de nossos esforços de benchmarking e análise de perfil de desempenho, identificamos que essas operações de gerenciamento de offset podem consumir a maior parte do tempo de processamento, especialmente para pipelines sem estado e de estado único que são frequentemente usados em casos de uso de alerta operacional e monitoramento em tempo real.
Melhorias de desempenho no Structured Streaming
Acompanhamento de progresso assíncrono
Este recurso foi criado para lidar com a sobrecarga de latência da persistência de offsets para fins de acompanhamento de progresso. Este recurso, quando ativado, permitirá que os pipelines do Structured Streaming façam o checkpoint do progresso, ou seja, atualizem o offsetLog e o commitLog, de forma assíncrona e em paralelo com o processamento de dados real dentro de um microlote. Em outras palavras, o processamento de dados real não será bloqueado por essas operações de gerenciamento de offset, o que melhorará significativamente a latência das aplicações. A Figura 5 abaixo descreve este novo comportamento para o gerenciamento de offset.
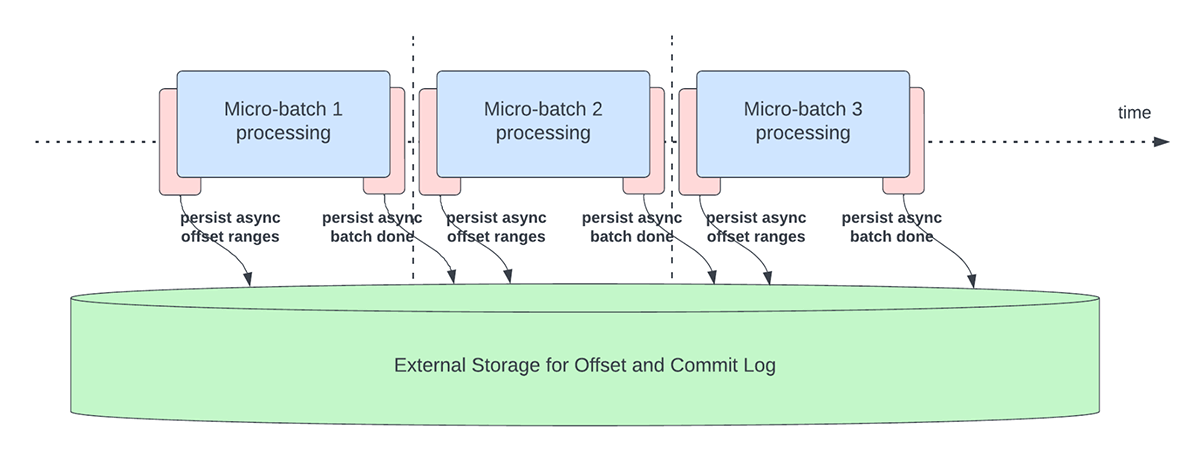
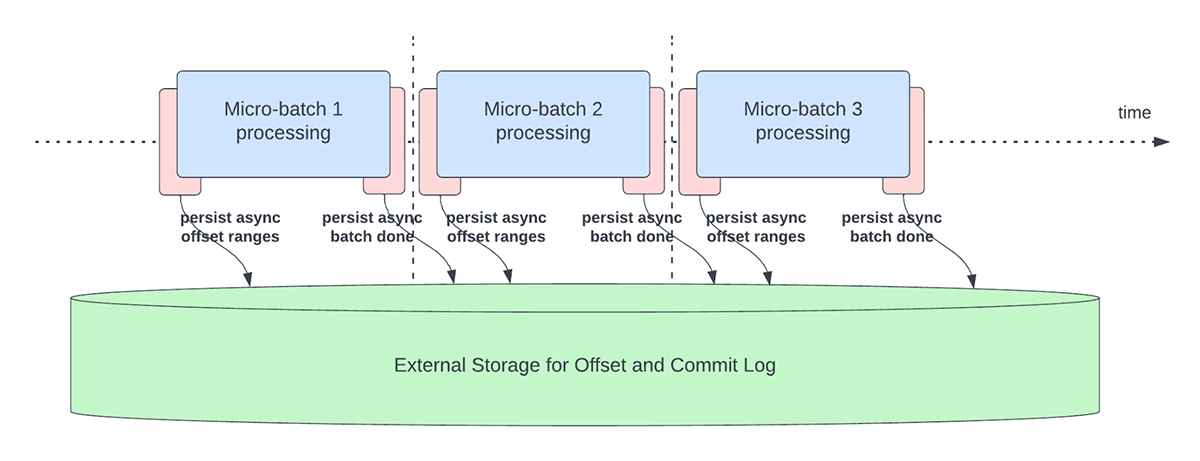{kind=link}
Em conjunto com a execução assíncrona de atualizações, os usuários podem configurar a frequência com que o progresso é salvo em checkpoints. Isso será útil para cenários em que as operações de gerenciamento de deslocamento ocorrem com uma taxa maior do que a que podem ser processadas. Isso acontece em pipelines quando o tempo gasto no processamento real dos dados é significativamente menor em comparação com essas operações de gerenciamento de deslocamento. Nesses cenários, ocorrerá um backlog cada vez maior de operações de gerenciamento de deslocamento. Para conter esse backlog crescente, o processamento de dados terá que ser bloqueado ou retardado, o que essencialmente reverterá o comportamento do processamento para o mesmo que se essas operações de gerenciamento de deslocamento fossem executadas em linha com o processamento de dados. Um usuário normalmente não precisará configurar ou definir a frequência de checkpoint, pois um valor default adequado será definido. É importante notar que o tempo de recuperação de falhas aumentará com o aumento do tempo de intervalo de checkpoint. Em caso de falha, um pipeline precisa reprocessar todos os dados antes do checkpoint bem-sucedido anterior. Os usuários podem considerar esse trade-off entre menor latência durante o processamento regular e o tempo de recuperação em caso de falha.
As configurações a seguir foram introduzidas para habilitar e configurar este recurso:
asyncProgressTrackingEnabled - ativa ou desativa o acompanhamento de progresso assíncronoDefault: falso
asyncProgressCheckpointingInterval - o intervalo no qual realizamos o commit de offsets e confirmações de conclusãoDefault: 1 minuto
O exemplo de código a seguir ilustra como habilitar este recurso:
Observe que este recurso não funcionará com Trigger.once ou Trigger.availableNow, pois esses gatilhos executam pipelines de forma manual/programada. Portanto, o acompanhamento de progresso assíncrono não será relevante. A consulta falhará se for enviada usando qualquer um dos triggers mencionados.
Aplicabilidade e limitações
Existem algumas limitações na(s) versão(ões) atual(is) que podem mudar à medida que evoluímos o recurso:
- Atualmente, o acompanhamento de progresso assíncrono só é compatível em pipelines stateless que usam o Kafka Sink.
- O processamento ponta a ponta exatamente uma vez não terá suporte com este acompanhamento de progresso assíncrono porque os intervalos de offset para um lote podem ser alterados em caso de falha. No entanto, muitos coletores, como o coletor Kafka, só suportam garantias do tipo "pelo menos uma vez", então isso pode não ser uma nova limitação.
Limpeza de log assíncrona
Este recurso foi criado para lidar com a sobrecarga de latência das limpezas de log que eram feitas em linha dentro de um micro-batch. Ao tornar esta operação de limpeza/expurgo de log assíncrona e executada em segundo plano, podemos remover a sobrecarga de latência que esta operação incorre no processamento de dados real. Além disso, essas limpezas não precisam ser feitas a cada micro-lote e podem ocorrer em um cronograma mais flexível.
Observe que este recurso/melhoria não tem nenhuma limitação sobre que tipo de pipelines ou cargas de trabalho podem usá-lo; portanto, este recurso será ativado em segundo plano por default para todos os pipelines de Structured Streaming.
Benchmarks
Para entender o desempenho do acompanhamento de progresso assíncrono e da limpeza de logs assíncrona, criamos alguns benchmarks. Nosso objetivo com os benchmarks é entender a diferença de desempenho que o gerenciamento de offset aprimorado oferece em um pipeline de transmissão de ponta a ponta. Os benchmarks são divididos em duas categorias:
- Taxa da fonte para o coletor de estatísticas - Neste benchmark, usamos uma fonte e um coletor básicos, sem estado e de coleta de estatísticas, o que é útil para determinar a diferença no desempenho do mecanismo principal sem nenhuma dependência externa.
- Origem Kafka para coletor Kafka - Para este benchmark, movemos dados de uma origem Kafka para um coletor Kafka. Isso é semelhante a um cenário do mundo real para ver qual seria a diferença em um cenário de produção.
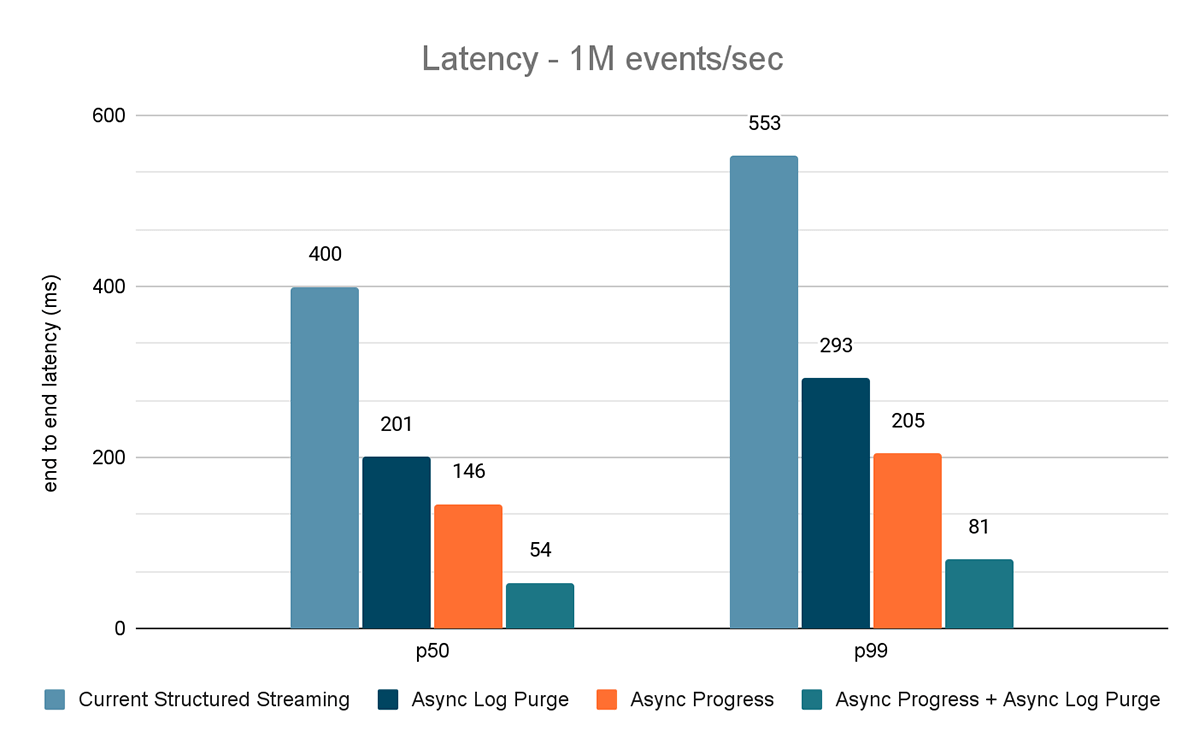
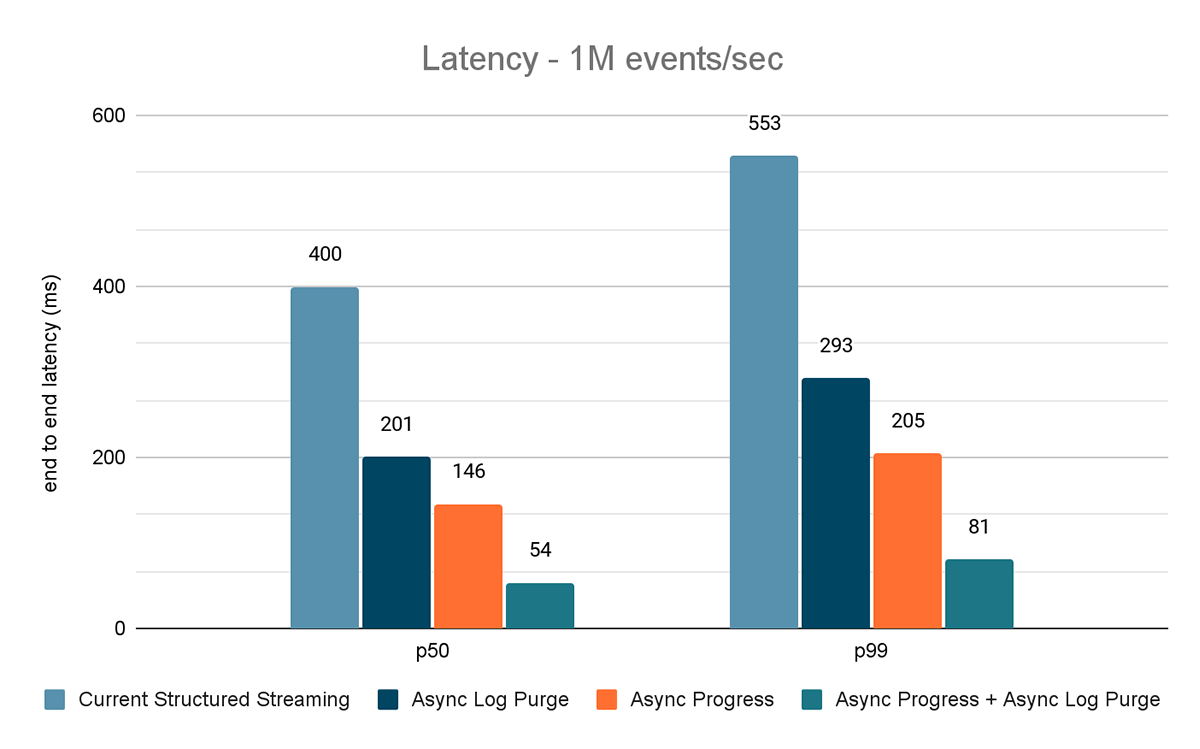
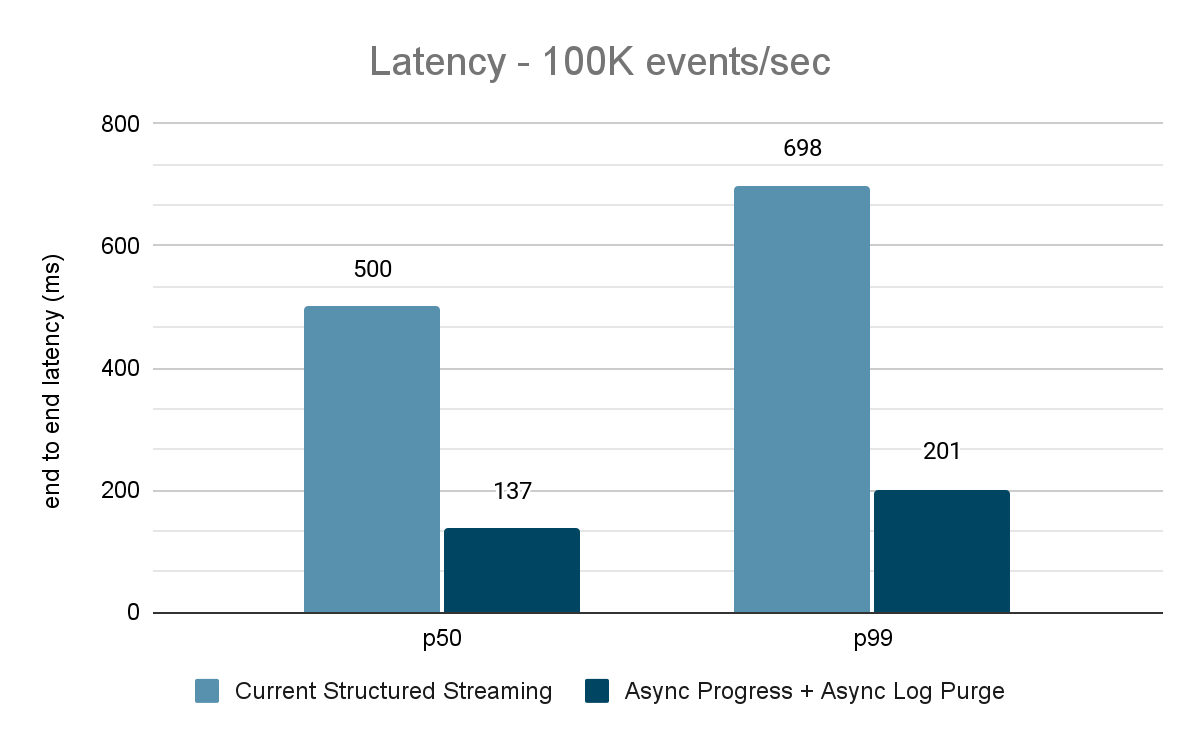
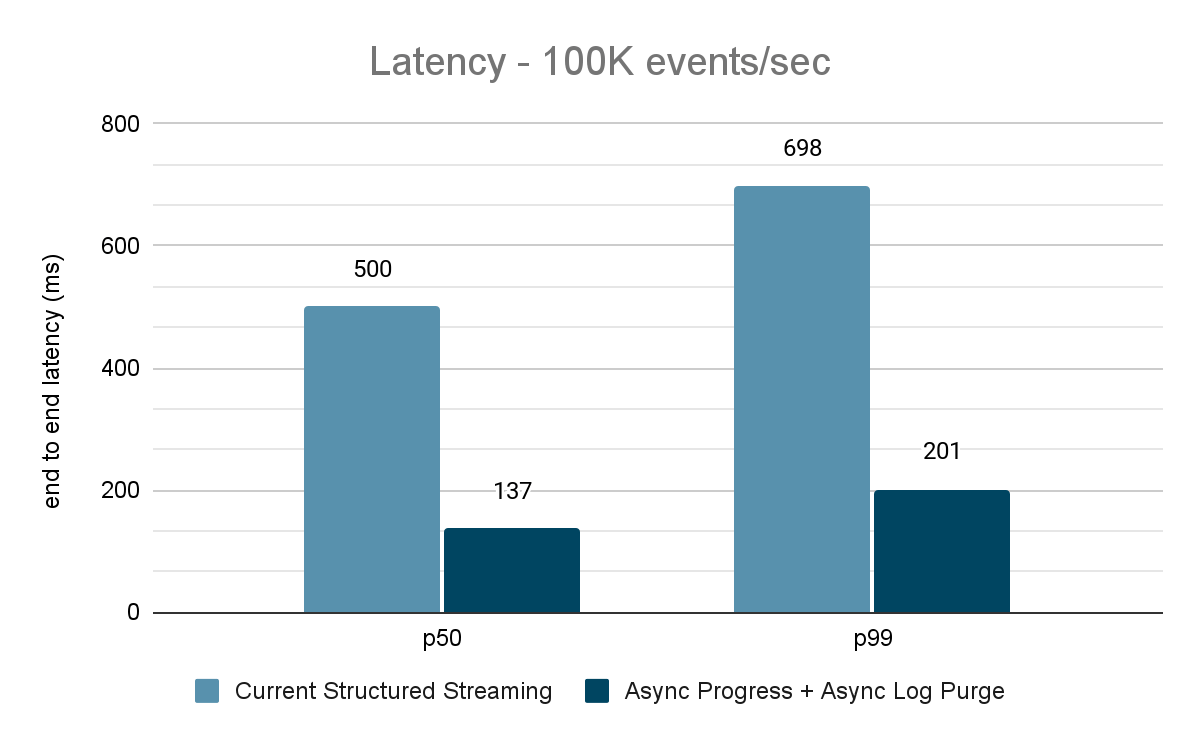
Para ambos os benchmarks, medimos a latência de ponta a ponta (percentil 50, percentil 99) em diferentes taxas de entrada de dados (100 mil eventos/s, 500 mil eventos/s, 1 milhão de eventos/s).
Metodologia de Benchmark
A principal metodologia foi gerar dados de uma fonte com um throughput constante específico. Os registros gerados contêm informações sobre quando os registros foram criados. No lado do sink, usamos a biblioteca Apache DataSketches para coletar a diferença entre o tempo em que o sink processa o registro e o tempo em que ele foi criado em cada lote. Isso é usado para calcular a latência. Usamos o mesmo cluster com o mesmo número de nós para todos os experimentos.
Observação: para o benchmark do Kafka, reservamos alguns nós de um cluster para executar o Kafka e gerar os dados para alimentá-lo. Calculamos a latência de um registro somente depois que o registro for publicado com sucesso no Kafka (no coletor)
Benchmark do Rate Source para o Stat Sink
Para este benchmark, usamos um cluster Spark de 7 nós de worker (i3.2xlarge - 4 núcleos, 61 GiB de memória) usando o Databricks runtime (11.3). Medimos a latência de ponta a ponta para os seguintes cenários para quantificar a contribuição de cada melhoria.
- Structured Streaming atual - esta é a latência de referência sem nenhuma das melhorias mencionadas anteriormente
- Limpeza de logs assíncrona - mede a latência após aplicar somente a limpeza de logs assíncrona
- Progresso Assíncrono - mede a latência após a aplicação do acompanhamento de progresso assíncrono
- Progresso assíncrono + Limpeza de log assíncrona - isso mede a latência após a aplicação de ambas as melhorias
Os resultados desses experimentos são mostrados nas Figuras 6, 7 e 8. Como você pode ver, a limpeza assíncrona de logs reduz consistentemente a latência em aproximadamente 50%. Da mesma forma, o acompanhamento de progresso assíncrono por si só melhora a latência em aproximadamente 65%. Combinados, a latência é reduzida em 85-86% e fica abaixo de 100 ms.
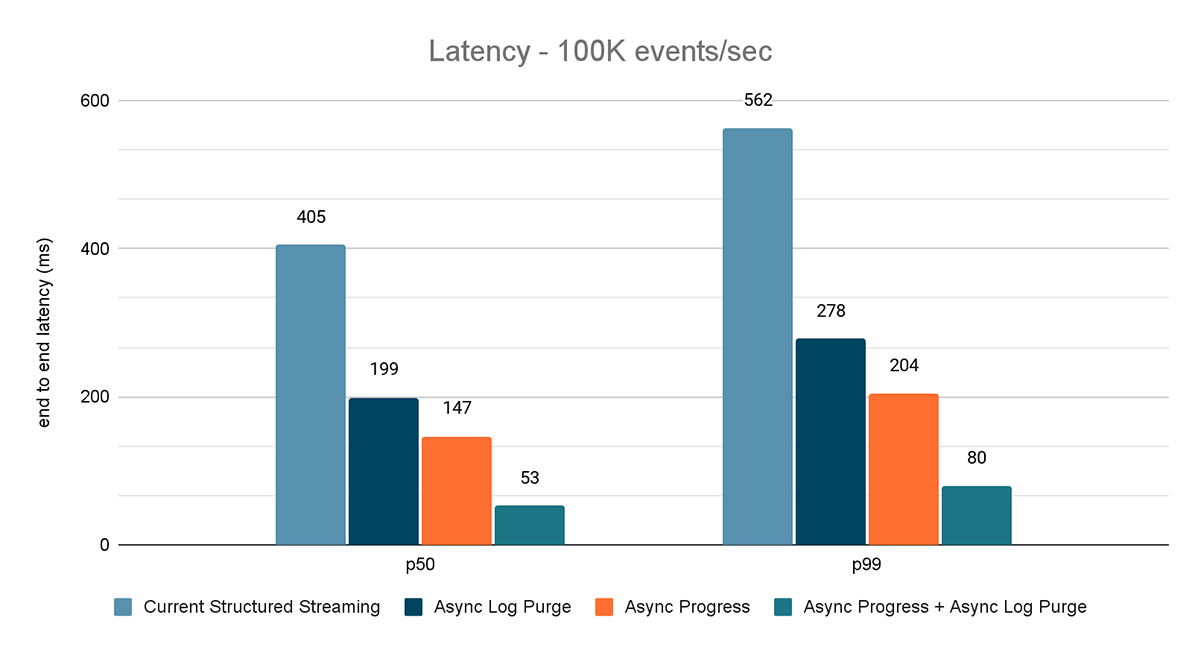
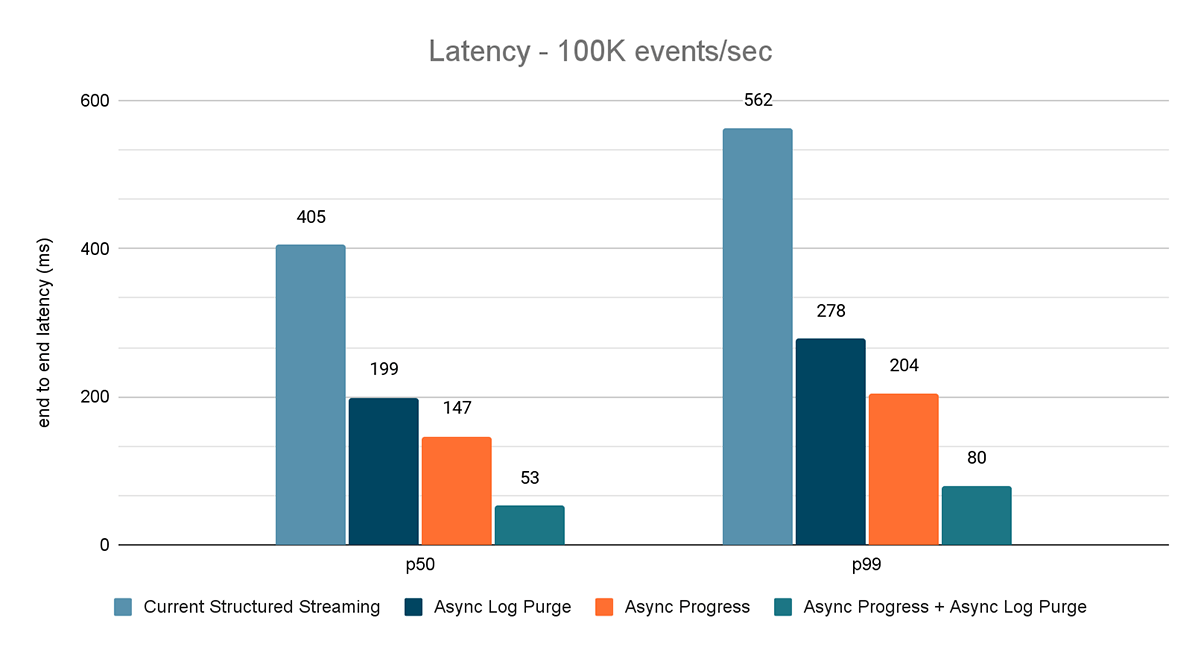{kind=link}
{kind=link}
{kind=link}
Benchmark do Kafka Source para o Kafka Sink
Para os benchmarks do Kafka, usamos um cluster Spark com 5 nós worker (i3.2xlarge - 4 núcleos, 61 GiB de memória), um cluster separado de 3 nós para executar o Kafka e 2 nós adicionais para gerar dados adicionados à fonte do Kafka. Nosso tópico Kafka tem 40 partições e um fator de replicação de 3.
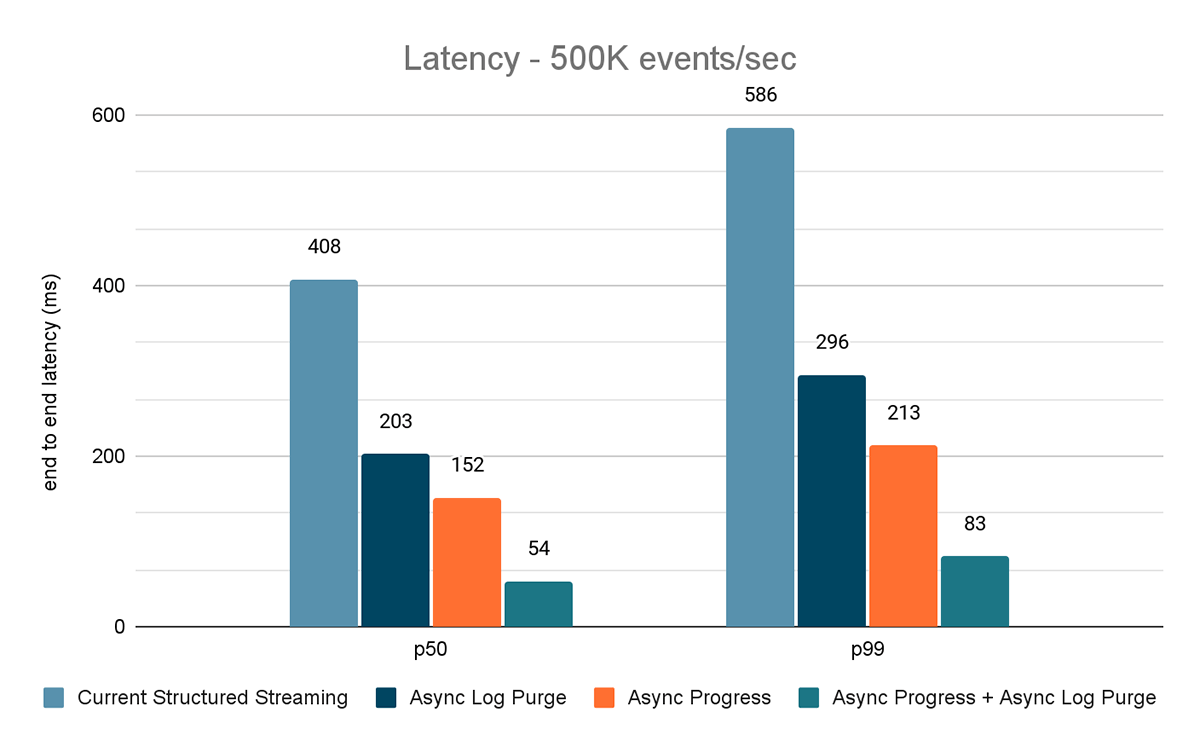
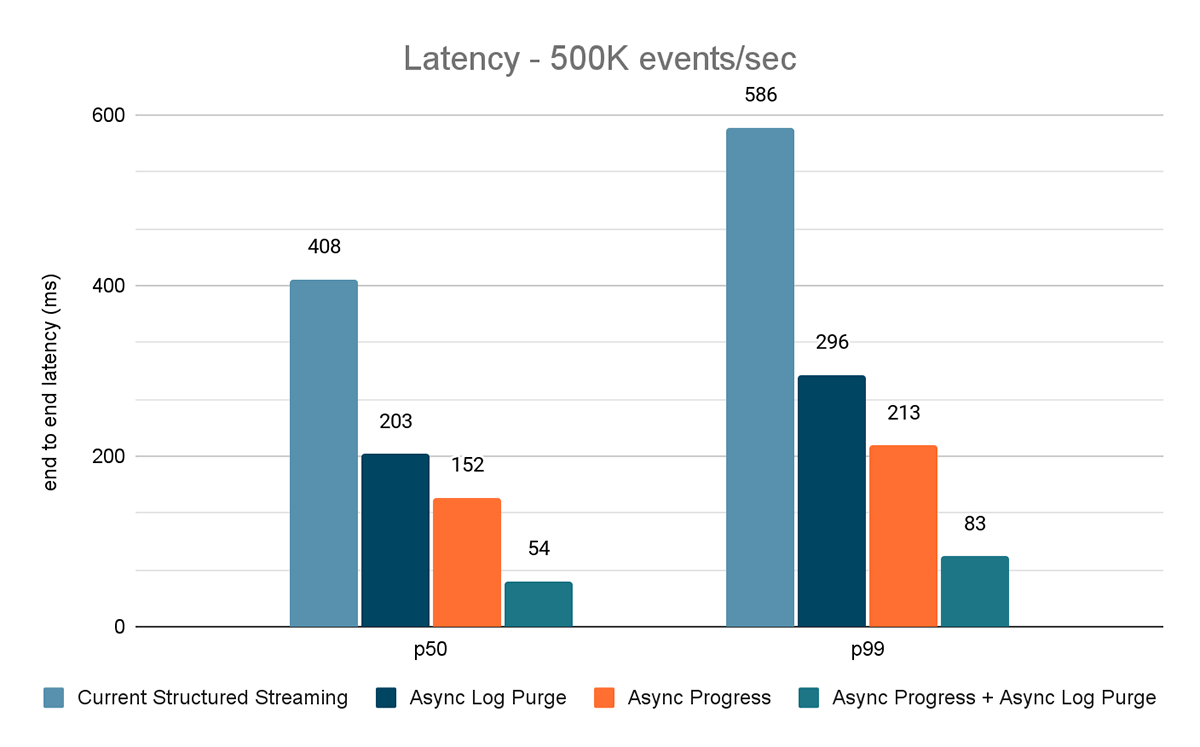
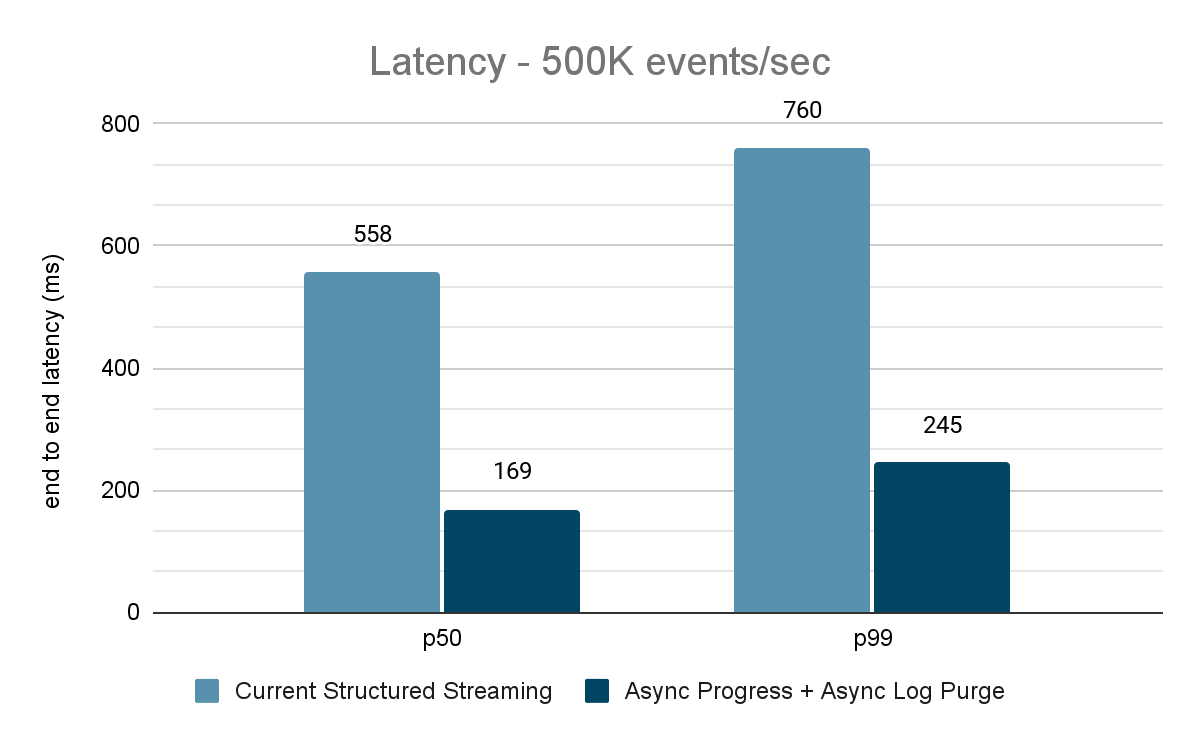
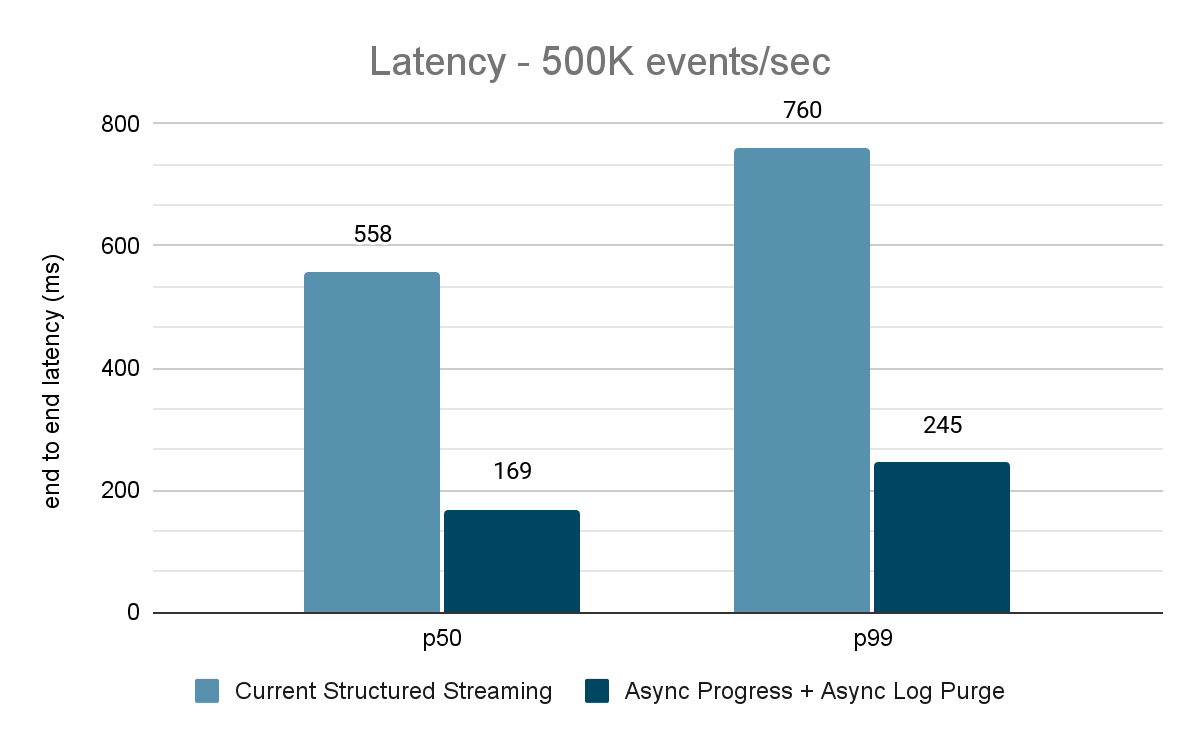
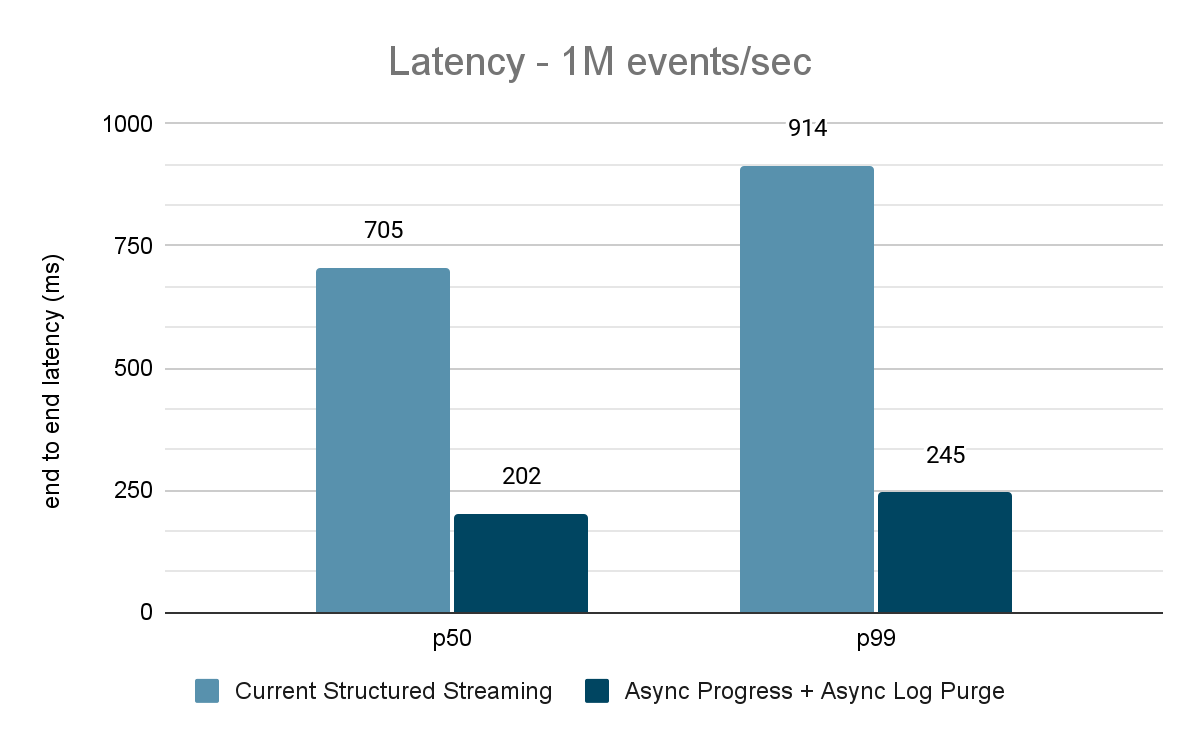
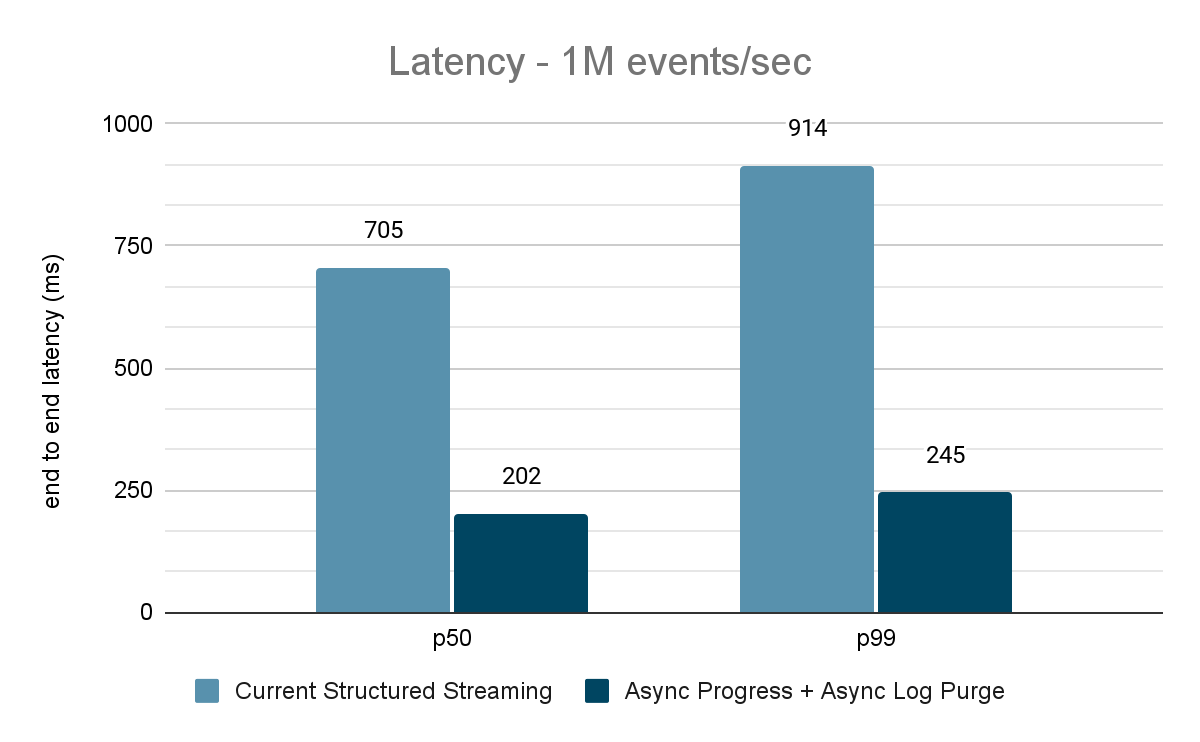
O gerador de dados publica os dados em um tópico do Kafka, e o pipeline de transmissão estructurada consome os dados e os republica em outro tópico do Kafka. Os resultados da avaliação de desempenho são mostrados nas Figuras 9, 10 e 11. Como podemos ver, após aplicar o progresso assíncrono e a limpeza de log assíncrona, a latência se reduz em 65-75% ou 3-3,5x em diferentes throughput.
{kind=link}
{kind=link}
{kind=link}
Resumo dos resultados de desempenho
Com o novo acompanhamento de progresso assíncrono e a limpeza de log assíncrona, podemos ver que ambas as configurações reduzem a latência em até 3X. Trabalhando em conjunto, a latência é bastante reduzida em todos os throughputs. Os gráficos também mostram que a quantidade de tempo economizado geralmente é uma quantidade constante de tempo (200 a 250 ms para cada configuração) e, juntas, elas podem reduzir cerca de 500 ms em geral (deixando tempo suficiente para o planejamento de lotes e o processamento de query).
Disponibilidade
Essas melhorias de desempenho estão disponíveis na Databricks Lakehouse Platform a partir do DBR 11.3. A limpeza de log assíncrona está habilitada por padrão no DBR 11.3 e versões posteriores. Além disso, essas melhorias foram contribuídas para o código aberto Spark e estão disponíveis a partir do Apache Spark 3.4.
Trabalhos Futuros
Atualmente, existem algumas limitações para os tipos de cargas de trabalho e coletores compatíveis com o recurso de acompanhamento de progresso assíncrono. Analisaremos o suporte a mais tipos de cargas de trabalho com este recurso no futuro.
Este é apenas o começo dos recursos de baixa latência previsível que estamos desenvolvendo no Structured Streaming como parte do Project Lightspeed. Além disso, continuaremos a fazer benchmark e a analisar o perfil do Structured Streaming para encontrar mais áreas de melhoria. Fique ligado!
Junte-se a nós no Data and AI Summit em São Francisco, de 26 a 29 de junho, para saber mais sobre o Projeto Lightspeed e a transmissão de dados na Databricks Lakehouse Platform.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.