O que há de novo em Lakeflow Declarative Pipelines: Julho 2025
por Matt Jones
- Lakeflow Declarative Pipelines está Disponível para Todos
- Otimizações recentes reduziram o TCO em até 70% para pipelines sem servidor
- Novos cursos de treinamento estão agora disponíveis e gratuitos para ajudá-lo a começar
Lakeflow Declarative Pipelines agora está Disponível para Todos, e o momentum não diminuiu desde o DAIS. Este post resume tudo o que aconteceu nas últimas semanas - para que você esteja totalmente atualizado sobre o que está aqui, o que vem a seguir e como começar a usá-lo.
- Resumo do DAIS: O que anunciamos no palco
- Melhorias no TCO: Ganhos de desempenho recentes que reduzem custos
- Atualizações de recursos: Novas capacidades agora em pré-visualização ou GA
- Recursos de treinamento: Cursos gratuitos e autodidatas para ajudá-lo a começar
Revisão do DAIS 2025: Lakeflow Declarative Pipelines está aqui
No Data + AI Summit 2025, anunciamos que contribuímos com nossa tecnologia central de pipeline declarativo para o projeto Apache Spark™ como Spark Declarative Pipelines. Essa contribuição estende o modelo declarativo do Spark de consultas individuais para pipelines completos, permitindo que os desenvolvedores definam o que seus pipelines devem fazer enquanto o Spark cuida de como fazer. Já comprovado em milhares de cargas de trabalho em produção, agora é um padrão aberto para toda a comunidade Spark.
Também anunciamos a Disponibilidade Geral do Lakeflow, a solução unificada da Databricks para ingestão de dados, transformação e orquestração na Plataforma de Inteligência de Dados. O marco GA também marcou uma grande evolução para o desenvolvimento de pipelines. DLT agora é Lakeflow Declarative Pipelines, com os mesmos benefícios centrais e total compatibilidade retroativa com seus pipelines existentes. Também introduzimos o novo IDE para engenharia de dados dos Pipelines Declarativos do Lakeflow (mostrado acima), construído do zero para simplificar o desenvolvimento de pipeline com recursos como emparelhamento de código-DAG, visualizações contextuais e autoria assistida por IA.
Finalmente, anunciamos o Lakeflow Designer, uma experiência sem código para construção de pipelines de dados. Torna o ETL acessível a mais usuários - sem comprometer a prontidão para produção ou governança - gerando pipelines Lakeflow reais por trás das cenas. Prévia em breve.
Juntos, esses anúncios representam um novo capítulo na engenharia de dados - mais simples, mais escalável e mais aberto. E nas semanas desde o DAIS, mantivemos o ritmo.
Desempenho mais inteligente, custos mais baixos para Pipelines Declarativos
Fizemos melhorias significativas no backend para ajudar o Lakeflow Declarative Pipelines a funcionar de forma mais rápida e econômica. Em geral, os pipelines serverless agora oferecem melhor relação custo-benefício graças às melhorias no motor do Photon, Enzyme, autoscaling e recursos avançados como AutoCDC e Expectativas de Qualidade de Dados.
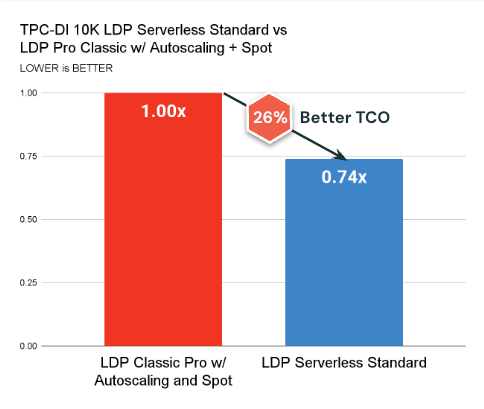
Aqui estão os principais pontos a serem lembrados:
- O Modo Padrão Serverless agora está disponível e supera consistentemente o cálculo clássico em termos de custo (26% melhor TCO em média) e latência.
- O Modo de Desempenho Serverless desbloqueia resultados ainda mais rápidos e é competitivo em termos de TCO para SLAs apertados.
- AutoCDC agora supera o tradicional MERGE em muitas cargas de trabalho, facilitando a implementação de padrões SCD1 e SCD2 sem lógica complexa, especialmente quando combinado com essas otimizações.
Essas mudanças reforçam nosso compromisso contínuo de tornar o Lakeflow Declarative Pipelines a opção mais eficiente para ETL em produção em grande escala.
O que mais é novo em Declarative Pipelines
Desde o Data + AI Summit, entregamos uma série de atualizações que tornam os pipelines mais modulares, prontos para produção e mais fáceis de operar - sem a necessidade de configuração adicional ou código de cola.
Simplicidade operacional
Gerenciar a saúde da tabela agora é mais fácil e mais econômico:
- Otimização Preditiva agora gerencia a manutenção de tabelas - como OPTIMIZE e VACUUM - para todos os novos e existentes pipelines do Catálogo Unity. Em vez de funcionar em um cronograma fixo, a manutenção agora se adapta aos padrões de carga de trabalho e ao layout de dados para otimizar custos e desempenho automaticamente. Isso significa:
- Menos tempo gasto em ajustes ou agendamento de manutenção manualmente
- Execução mais inteligente que evita o uso desnecessário de computação
- Melhores tamanhos de arquivo e agrupamento para um desempenho de consulta mais rápido
- Vetores de exclusão agora estão habilitados por padrão para novas tabelas de streaming e visualizações materializadas. Isso reduz reescritas desnecessárias, melhorando o desempenho e reduzindo os custos de computação ao evitar reescritas completas de arquivos durante atualizações e exclusões. Se você tem requisitos rigorosos de exclusão física (por exemplo, para GDPR), você pode desativar vetores de exclusão ou remover dados permanentemente.
Pipelines mais modulares e flexíveis
Novas capacidades dão às equipes maior flexibilidade em como estruturam e gerenciam pipelines, tudo sem qualquer reprocessamento de dados:
- Lakeflow Declarative Pipelines agora suporta a atualização de pipelines existentes para aproveitar a publicação de tabelas em vários catálogos e esquemas. Anteriormente, essa flexibilidade estava disponível apenas ao criar um novo pipeline. Agora, você pode migrar um pipeline existente para este modelo sem a necessidade de reconstruí-lo do zero, permitindo arquiteturas de dados mais modulares ao longo do tempo.
- Agora você pode mover tabelas de streaming e visualizações materializadas de um pipeline para outro usando um único comando SQL e uma pequena alteração de código para mover a definição da tabela. Isso facilita a divisão de grandes pipelines, a consolidação de menores ou a adoção de diferentes cronogramas de atualização em tabelas sem a necessidade de recriar dados ou lógica. Para reatribuir uma tabela a um pipeline diferente, basta executar:
Após executar o comando e mover a definição da tabela da origem para o pipeline de destino, o pipeline de destino assume as atualizações para a tabela.
Novas tabelas de sistema para observabilidade do pipeline
Uma nova tabela de sistema de pipeline agora está em Visualização Pública, dando a você uma visão completa e consultável de todos os pipelines em seu espaço de trabalho. Inclui metadados como criador, tags e eventos de ciclo de vida (como exclusões ou alterações de configuração), e pode ser unido a logs de faturamento para atribuição de custos e relatórios. Isso é especialmente útil para equipes que gerenciam muitos pipelines e procuram acompanhar os custos em ambientes ou unidades de negócios.
Uma segunda tabela de sistema para atualizações de pipeline - cobrindo histórico de atualização, desempenho e falhas - está planejada para o final deste verão.
Pratique com o Lakeflow
 Novo no Lakeflow ou procurando aprofundar suas habilidades? Lançamos três cursos de treinamento gratuitos e autoinstrucionais para ajudá-lo a começar:
Novo no Lakeflow ou procurando aprofundar suas habilidades? Lançamos três cursos de treinamento gratuitos e autoinstrucionais para ajudá-lo a começar:
- Ingestão de Dados com Lakeflow Connect – Aprenda a ingerir dados no Databricks a partir do armazenamento em nuvem ou usando conectores totalmente gerenciados sem código.
- Implante Cargas de Trabalho com Lakeflow Jobs – Orquestre cargas de trabalho de produção com observabilidade e automação integradas.
- Construa Pipelines de Dados com Lakeflow Declarative Pipelines - Vá de ponta a ponta com o desenvolvimento de pipeline, incluindo streaming, qualidade de dados e publicação.
Todos os três cursos estão disponíveis agora sem custo na Databricks Academy.
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.