What’s New in Lakeflow Declarative Pipelines: July 2025
by Matt Jones
- Lakeflow Declarative Pipelines is Generally Available
- Recent optimizations cut TCO by up to 70% for serverless pipelines
- New training courses are now live and free to help you get started
Lakeflow Declarative Pipelines is now Generally Available, and momentum hasn’t slowed since DAIS. This post rounds up everything that’s landed in the past few weeks - so you’re fully caught up on what’s here, what’s coming next, and how to start using it.
- DAIS recap: What we announced on stage
- TCO improvements: Recent performance gains that cut costs
- Feature updates: New capabilities now in preview or GA
- Training resources: Free self-paced courses to help you get started
DAIS 2025 in Review: Lakeflow Declarative Pipelines Is Here
At Data + AI Summit 2025, we announced that we’ve contributed our core declarative pipeline technology to the Apache Spark™ project as Spark Declarative Pipelines. This contribution extends Spark’s declarative model from individual queries to full pipelines, letting developers define what their pipelines should do while Spark handles how to do it. Already proven across thousands of production workloads, it’s now an open standard for the entire Spark community.
We also announced the General Availability of Lakeflow, Databricks’ unified solution for data ingestion, transformation, and orchestration on the Data Intelligence Platform. The GA milestone also marked a major evolution for pipeline development. DLT is now Lakeflow Declarative Pipelines, with the same core benefits and full backward compatibility with your existing pipelines. We also introduced Lakeflow Declarative Pipelines’ new IDE for data engineering (shown above), built from the ground up to streamline pipeline development with features like code-DAG pairing, contextual previews, and AI-assisted authoring.
Finally, we announced Lakeflow Designer, a no-code experience for building data pipelines. It makes ETL accessible to more users - without compromising on production readiness or governance - by generating real Lakeflow pipelines under the hood. Preview coming soon.
Together, these announcements represent a new chapter in data engineering—simpler, more scalable, and more open. And in the weeks since DAIS, we’ve kept the momentum going.
Smarter Performance, Lower Costs for Declarative Pipelines
We’ve made significant backend improvements to help Lakeflow Declarative Pipelines run faster and more cost-effectively. Across the board, serverless pipelines now deliver better price-performance thanks to engine enhancements to Photon, Enzyme, autoscaling, and advanced features like AutoCDC and Data Quality expectations.
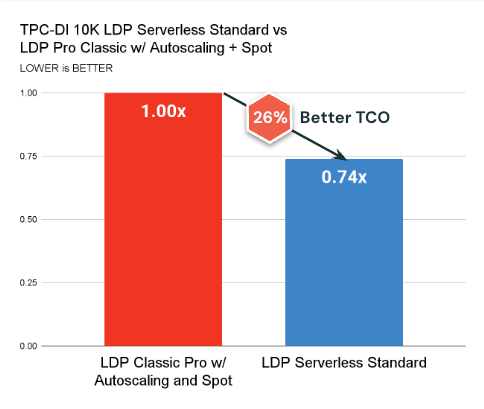
Here are the key takeaways:
- Serverless Standard Mode is now available and consistently outperforms classic compute in terms of cost (26% better TCO on average) and latency.
- Serverless Performance Mode unlocks even faster results and is TCO competitive for tight SLAs.
- AutoCDC now outperforms traditional MERGE in many workloads, while making it easier to implement SCD1 and SCD2 patterns without complex logic, especially when paired with these optimizations.
These changes build on our ongoing commitment to make Lakeflow Declarative Pipelines the most efficient option for production ETL at scale.
What Else is New in Declarative Pipelines
Since the Data + AI Summit, we’ve delivered a series of updates that make pipelines more modular, production-ready, and easier to operate—without requiring additional configuration or glue code.
Operational simplicity
Managing table health is now easier and more cost-effective:
- Predictive Optimization now manages table maintenance - like OPTIMIZE and VACUUM - for all new and existing Unity Catalog pipelines. Instead of running on a fixed schedule, maintenance now adapts to workload patterns and data layout to optimize cost and performance automatically. This means:
- Less time spent tuning or scheduling maintenance manually
- Smarter execution that avoids unnecessary compute usage
- Better file sizes and clustering for faster query performance
- Deletion vectors are now enabled by default for new streaming tables and materialized views. This reduces unnecessary rewrites, improving performance and lowering compute costs by avoiding full file rewrites during updates and deletes. If you have strict physical deletion requirements (e.g., for GDPR), you can disable deletion vectors or permanently remove data.
More modular, flexible pipelines
New capabilities give teams greater flexibility in how they structure and manage pipelines, all without any data reprocessing:
- Lakeflow Declarative Pipelines now supports upgrading existing pipelines to take advantage of publishing tables to multiple catalogs and schemas. Previously, this flexibility was only available when creating a new pipeline. Now, you can migrate an existing pipeline to this model without needing to rebuild it from scratch, enabling more modular data architectures over time.
- You can now move streaming tables and materialized views from one pipeline to another using a single SQL command and a small code change to move the table definition. This makes it easier to split large pipelines, consolidate smaller ones, or adopt different refresh schedules across tables without needing to recreate data or logic. To reassign a table to a different pipeline, just run:
After running the command and moving the table definition from the source to the destination pipeline, the destination pipeline takes over updates for the table.
New system tables for pipeline observability
A new pipeline system table is now in Public Preview, giving you a complete, queryable view of all pipelines across your workspace. It includes metadata like creator, tags, and lifecycle events (like deletions or config changes), and can be joined with billing logs for cost attribution and reporting. This is especially useful for teams managing many pipelines and looking to track cost across environments or business units.
A second system table for pipeline updates - covering refresh history, performance, and failures - is planned for later this summer.
Get hands-on with Lakeflow
 New to Lakeflow or looking to deepen your skills? We’ve launched three free self-paced training courses to help you get started:
New to Lakeflow or looking to deepen your skills? We’ve launched three free self-paced training courses to help you get started:
- Data Ingestion with Lakeflow Connect – Learn how to ingest data into Databricks from cloud storage or using no-code, fully managed connectors.
- Deploy Workloads with Lakeflow Jobs – Orchestrate production workloads with built-in observability and automation.
- Build Data Pipelines with Lakeflow Declarative Pipelines – Go end-to-end with pipeline development, including streaming, data quality, and publishing.
All three courses are available now at no cost in Databricks Academy.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.