Transformações
O que são transformações?
No Spark, as estruturas de dados principais são imutáveis, o que significa que não podem ser alteradas depois de criadas. Talvez esse seja um conceito estranho no começo: se você não pode alterar, como vai usar? Para modificar um DataFrame, precisamos informar ao Spark como queremos modificar um DataFrame existente. Essa instrução é chamada de transformação. As transformações são essenciais para a forma como você escreve sua lógica de negócios usando o Spark. Existem dois tipos de transformações: dependências estreitas e dependências amplas.
O que são dependências estreitas?
Em uma transformação de dependências estreitas (ou transformações estreitas), cada partição de entrada contribui para uma partição de saída. 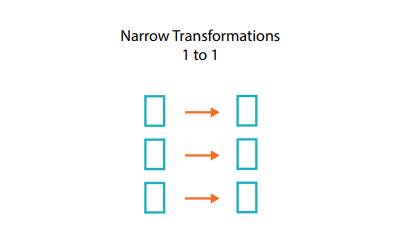
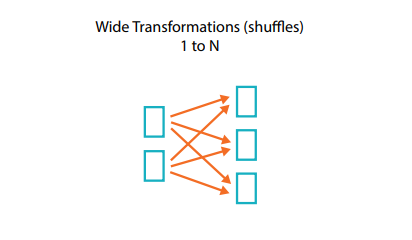
O que são dependências amplas?
Em uma transformação de dependências amplas (ou transformações amplas), as partições de entrada contribuem para várias partições de saída. Isso é chamado de shuffle, e o Spark troca partições no cluster. Em transformações estreitas, o Spark executa automaticamente uma operação chamada pipelining em dependências estreitas. Isso quer dizer que, se você especificar vários filtros para um DataFrame, todos eles serão executados na memória. Mas o mesmo não acontece com shuffles. Quando executamos um shuffle, o Spark grava o resultado no disco. A otimização de shuffle é um assunto importante, e a internet está repleta de informações. Mas o que devemos lembrar por enquanto é que existem dois tipos de transformações.