Simplifique o ciclo de vida de machine learning
Elimine silos organizacionais e tecnológicos com uma plataforma aberta e integrada para todo o ciclo de vida de dados e ML

Criar modelos de machine learning não é fácil. Passar para a produção é ainda mais difícil. Manter a qualidade dos dados e a precisão do modelo ao longo do tempo são apenas alguns dos desafios. A Databricks agiliza exclusivamente o desenvolvimento de ML em escala, incluindo preparação de dados, treinamento de modelo e implantação.
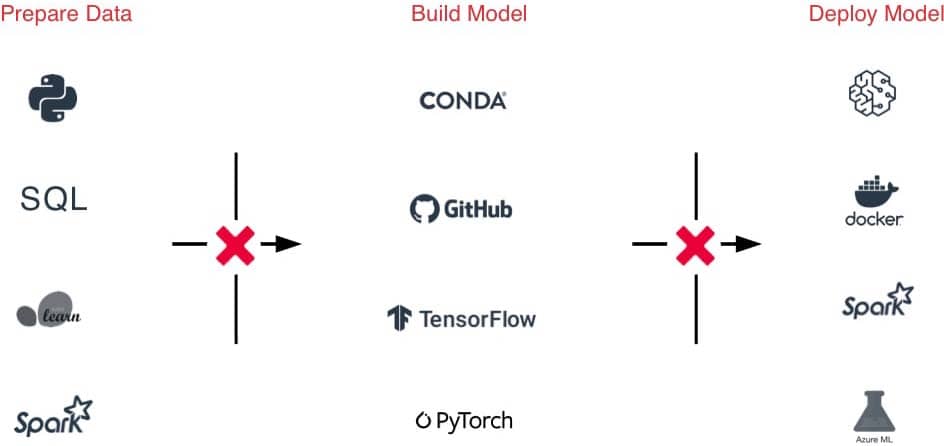
O desafio
A grande diversidade de frameworks de ML dificulta o gerenciamento de ambientes de ML
Transferências difíceis entre equipes devido a ferramentas e processos díspares, desde a preparação de dados até a experimentação e produção
Experimentos difíceis de acompanhar, modelos, dependências e artefatos dificultam a reprodução dos resultados
Riscos de segurança e conformidade
A solução
Acesso com um clique a ambientes ML prontos para uso, otimizados e escalonáveis em todo o ciclo de vida
Uma plataforma para ingestão de dados, preparação, construção de modelos, ajuste e produção que simplifica as transferências
Acompanhamento automático de experimentos, códigos, resultados e artefatos e gerenciamento de modelos em um hub central
Atendimento às necessidades de conformidade com controle de acesso refinado, linhagem de dados e criação de versões
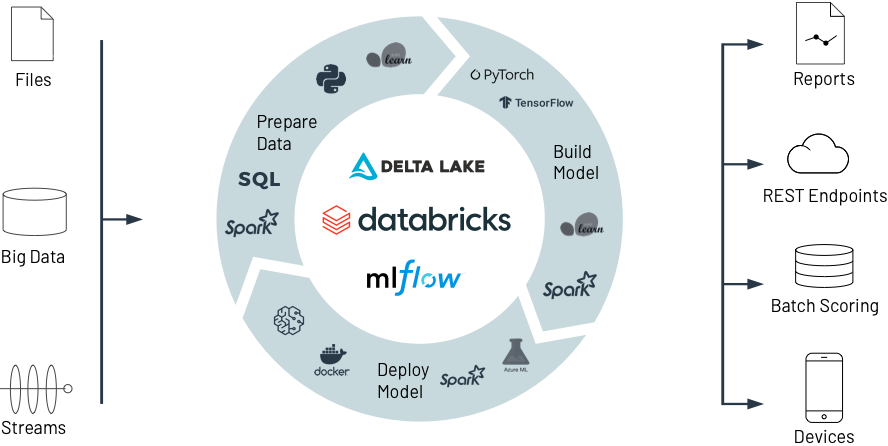
Databricks para Machine Learning
Veja como a Databricks ajuda a preparar dados de forma colaborativa, construir, implantar e gerenciar modelos de ML de última geração, da experimentação à produção, em escala sem precedentes.
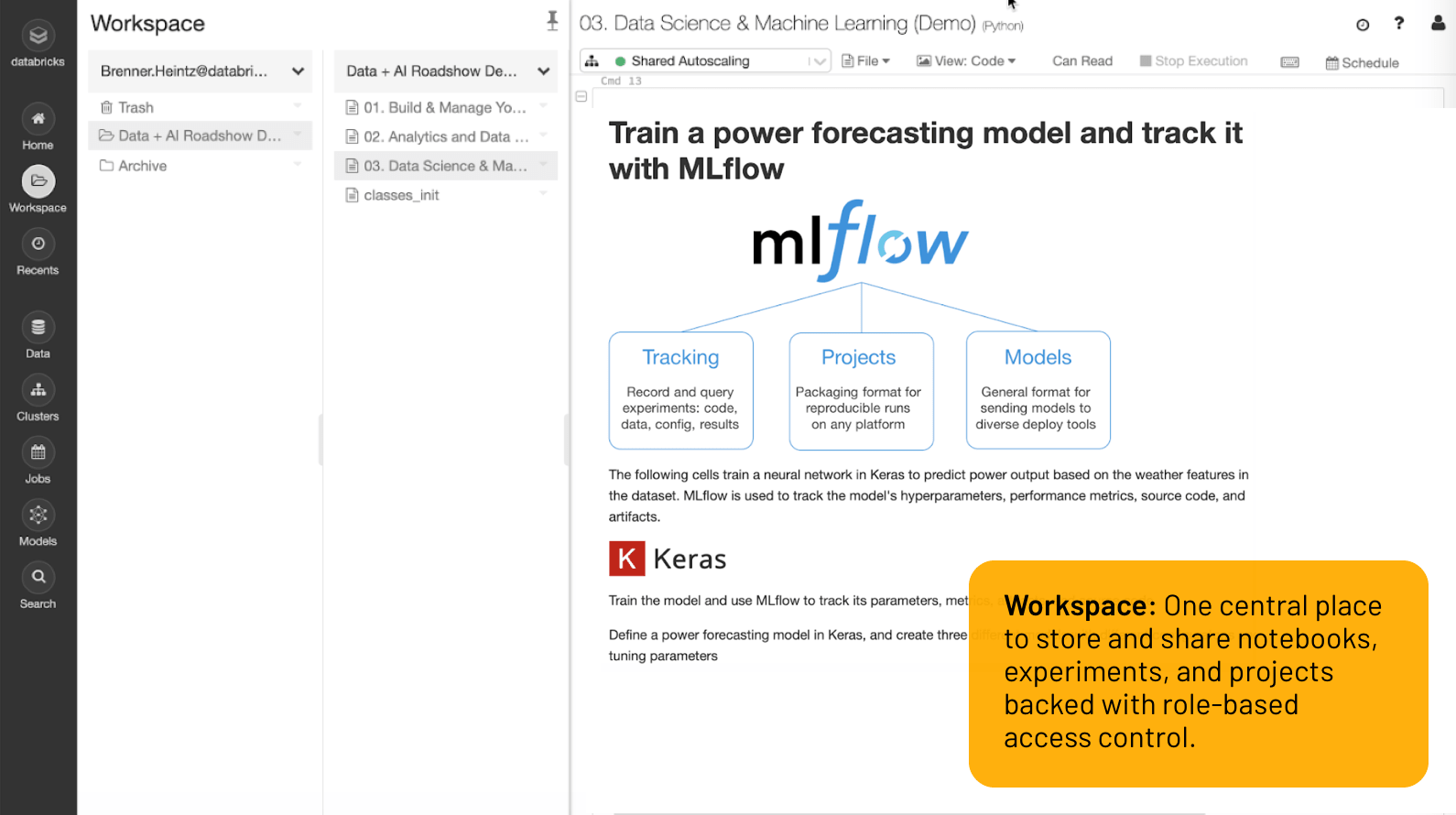
Espaço de trabalho
Um local central para armazenar e compartilhar notebooks, experimentos e projetos com controle de acesso baseado em função.
Da experimentação à produção de ML em escala inigualável
O melhor ambiente de desenvolvimento da categoria
Tudo o que você precisa para concluir o trabalho está a um clique de distância no workspace: conjuntos de dados, ambientes de ML, notebooks, arquivos, experimentos, modelos, estão disponíveis de forma segura em um só lugar.
Notebooks colaborativos com compatibilidade com várias linguagens (Python, R, Scala, SQL) facilitam o trabalho em equipe enquanto a coautoria, a integração Git, o controle de versões, o controle de acesso baseado em função e muito mais ajudam você a manter o comando. Ou simplesmente use ferramentas populares como Jupyter Lab, PyCharm, IntelliJ, RStudio com a Databricks para se beneficiar de armazenamento e compute de dados ilimitados.
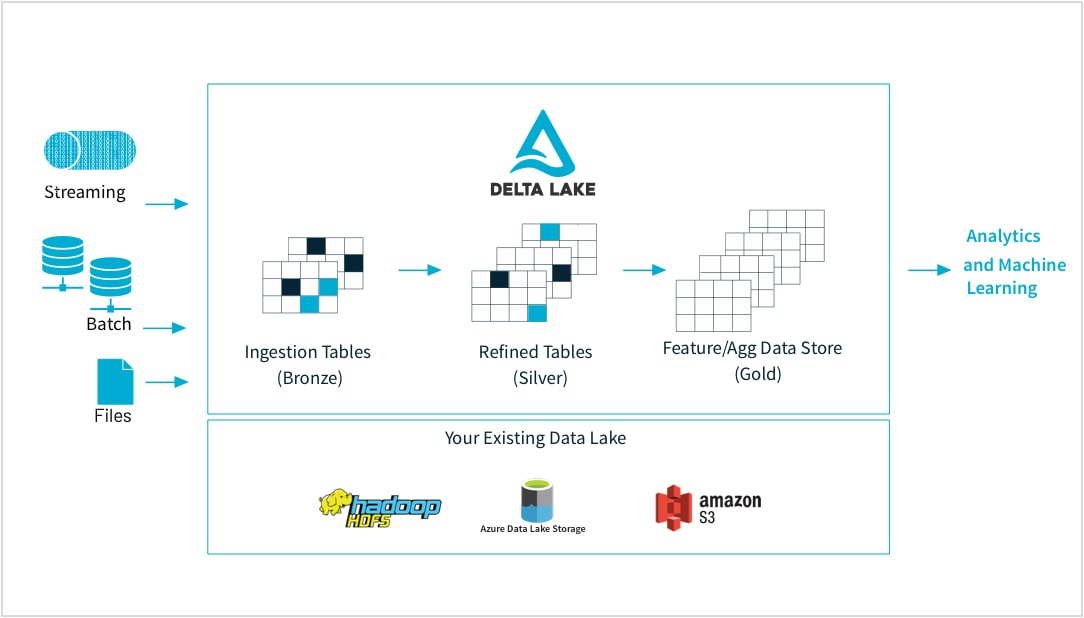
De dados brutos a armazenamento de recursos de alta qualidade
Os profissionais de machine learning treinam modelos em uma grande variedade de formatos e formulários de dados: conjuntos de dados pequenos ou grandes, DataFrames, texto, imagens, batch ou streaming. Todos exigem pipelines e transformações específicas
A Databricks permite que você ingira dados brutos de praticamente qualquer fonte, mescle dados em batch e streaming, agende transformações, controle as versões de tabelas e realize verificações de qualidade para garantir que os dados estejam intactos e prontos para funções analíticas para o resto da organização. Portanto, agora você pode trabalhar de forma transparente e confiável em quaisquer dados, arquivos CSV ou ingestões massivas de data lake, com base nas suas necessidades.

O melhor lugar para executar scikit-learn, TensorFlow, PyTorch e muito mais…
Os frameworks de ML estão evoluindo em um ritmo frenético, dificultando a manutenção de ambientes de ML. O Databricks ML Runtime fornece ambientes de ML otimizados e prontos para uso, incluindo os frameworks de ML mais populares (scikit-learn, TensorFlow, etc…) e compatibilidade com o Conda.
O AutoML integrado, como o ajuste de hiperparâmetros, ajuda a obter resultados mais rapidamente, e o dimensionamento simplificado ajuda você a passar de pequenos a grandes volumes de dados sem esforço, para que você não precise mais se limitar à quantidade de compute disponível para você. Por exemplo, treine modelos de deep learning com mais rapidez distribuindo compute em seus clusters com o HorovodRunner e obtenha mais desempenho de cada GPU em seu cluster executando a versão otimizada para CUDA do TensorFlow.
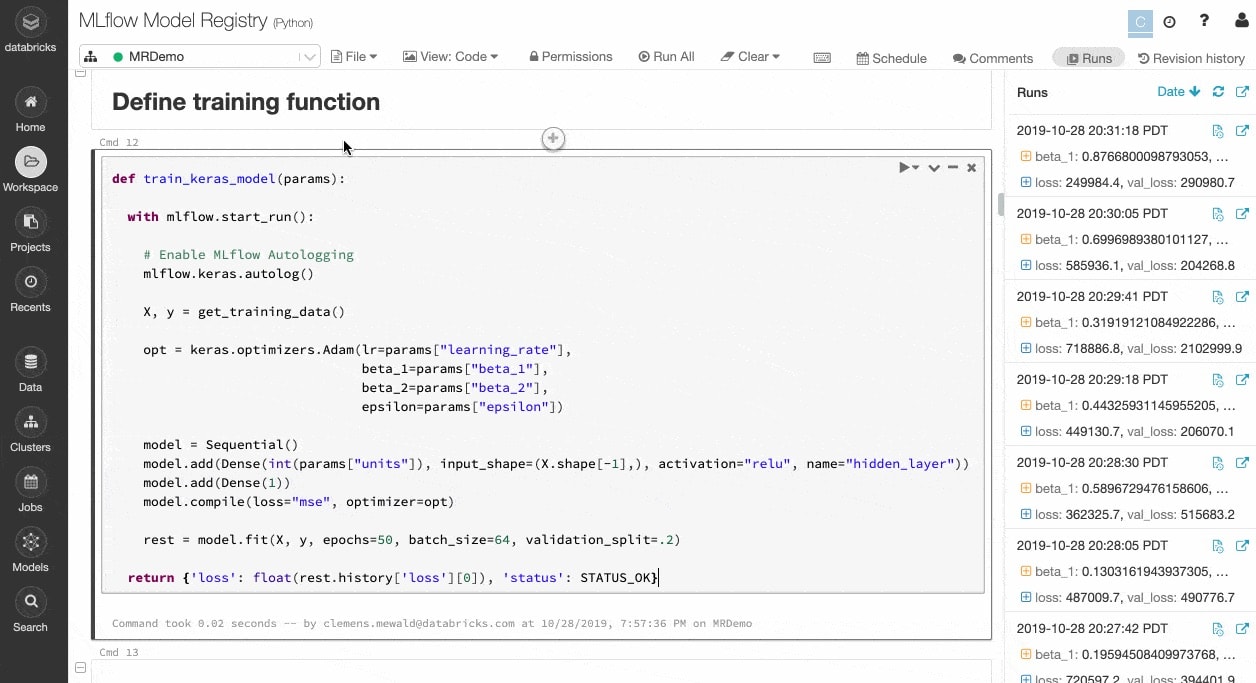
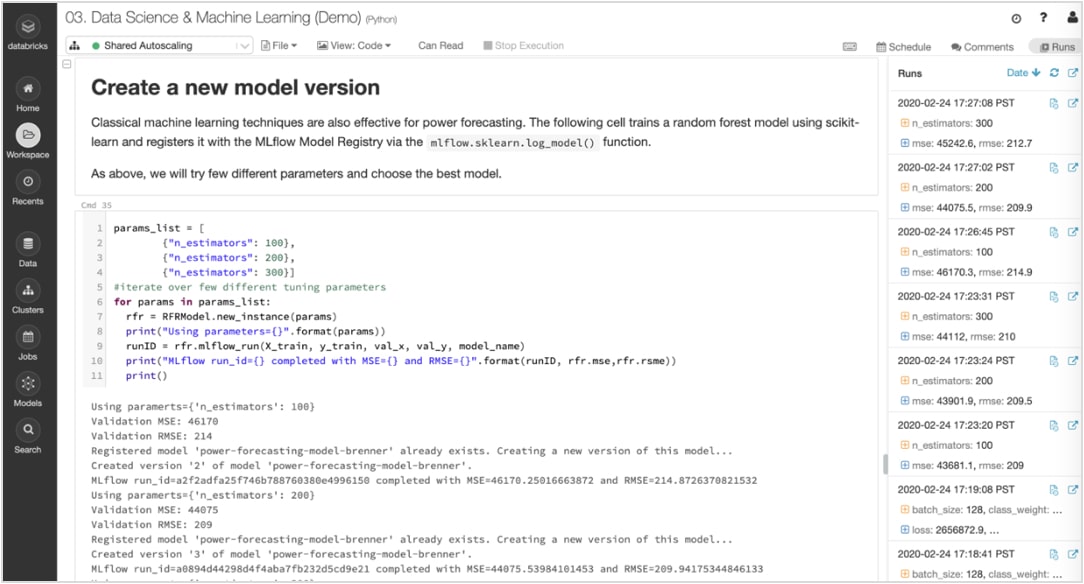
Acompanhe experimentos e artefatos para reproduzir execuções mais tarde
Algoritmos de ML têm dezenas de parâmetros configuráveis, e seja trabalhando por conta própria ou como equipe, é difícil acompanhar quais parâmetros, código e dados entraram em cada experimento para produzir um modelo.
O MLflow mantém de maneira automática o controle dos seus experimentos, juntamente com artefatos como dados, código, parâmetros e resultados para cada execução de treinamento a partir de notebooks. Assim, você pode ver com facilidade as execuções anteriores, comparar resultados e reverter para uma versão anterior do seu código, conforme necessário. Depois de identificar a melhor versão de um modelo para produção, registre-a em um repositório central para enviá-la para implantação e simplificar as transferências.
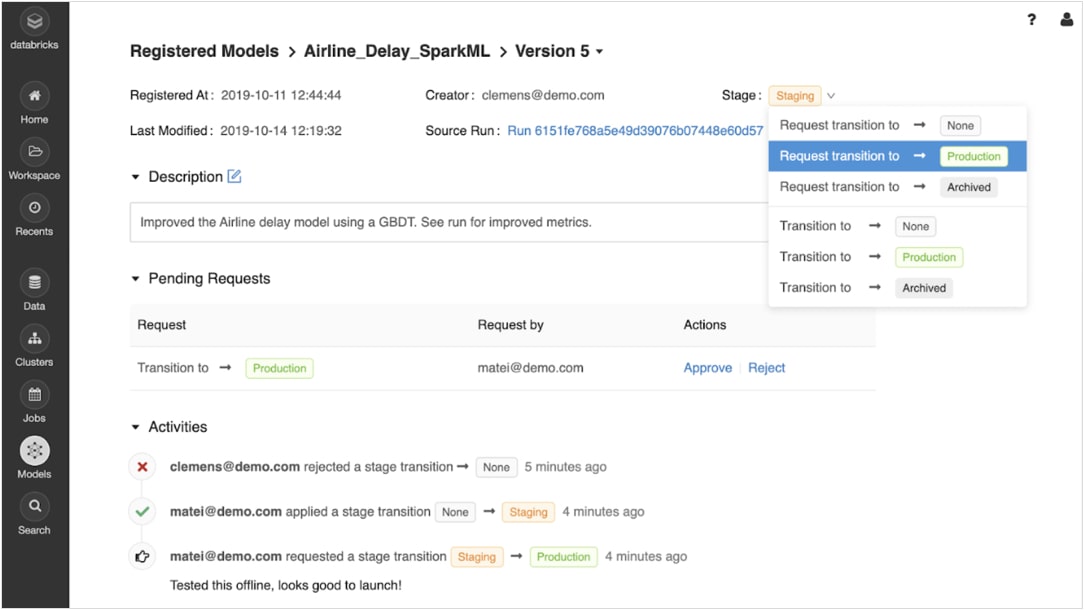
Passe com confiança do protótipo para a produção
Depois que os modelos treinados forem registrados, você poderá gerenciá-los de forma colaborativa durante todo o ciclo de vida usando o registro de modelos MLflow.
Os modelos podem ser versionados e passar por diferentes etapas, como teste, preparação, produção e arquivamento. As partes interessadas podem comentar e enviar solicitações de mudança de estágio. Toda a gestão do ciclo de vida se integra aos fluxos de trabalho de aprovação e governança e aos controles de acesso baseados em funções.
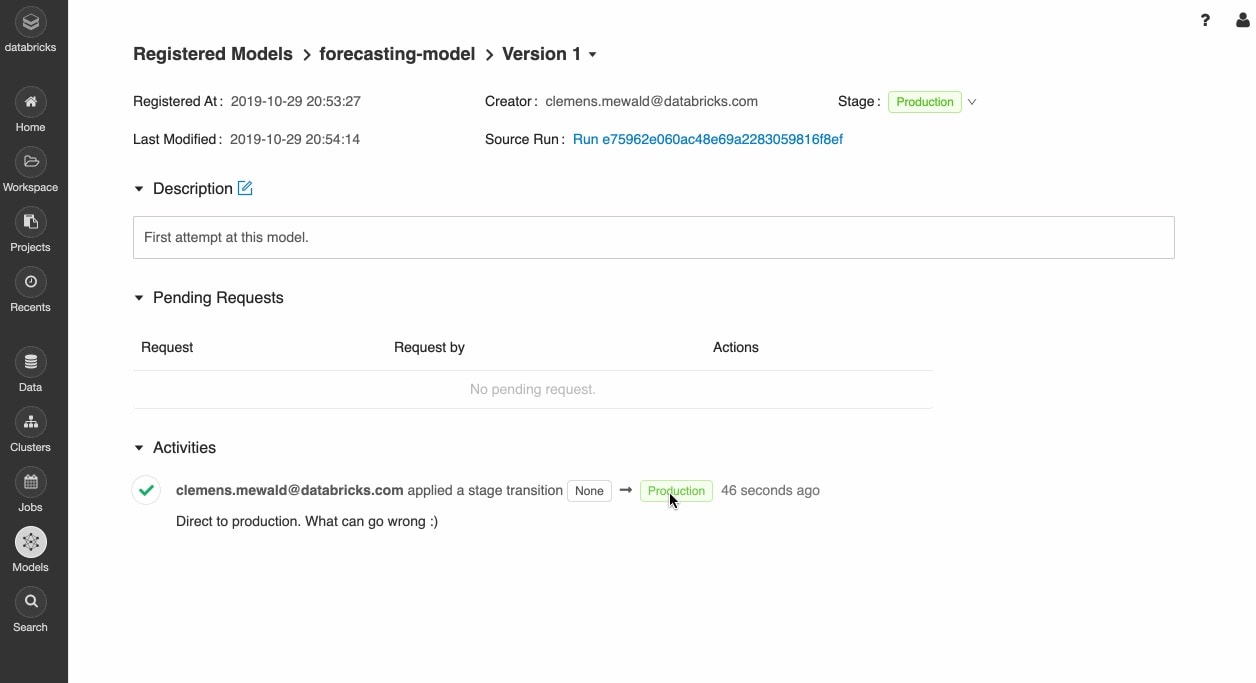
Implemente modelos em qualquer lugar
Implemente rapidamente modelos de produção para inferência em batch no Apache Spark™ ou como APIs REST usando integração com containers do Docker, Azure ML e Amazon SageMaker.
Operacionalize modelos de produção usando programador de jobs e clusters gerenciados automaticamente para dimensionar conforme necessário com base nas necessidades da empresa.
Envie rapidamente as versões mais recentes dos seus modelos para a produção e monitore o drift do modelo com Delta Lake e MLflow.
Recursos
Relatório

e-books

e-books

Ready to get started?