Central de segurança e confiança
A segurança dos seus dados é a nossa prioridade

Abordagem da Databricks para IA responsável
A Databricks acredita que o avanço da IA depende da construção de confiança em aplicativos inteligentes, seguindo práticas responsáveis no desenvolvimento e uso da IA. Isso exige que cada organização tenha propriedade e controle sobre seus dados e modelos de IA com monitoramento abrangente, controles de privacidade e governança durante todo o desenvolvimento e implantação da IA.
Databricks and the EU AI Act
Databricks is committed to responsible AI development and deployment consistent with applicable laws, including laws such as the European Union Artificial Intelligence Act (EU AI Act).
Databricks is an AI system provider and downstream model distributor for third-party general purpose AI models. We are responsible for our assessments of the AI systems we provide directly. We do not place general-purpose AI foundation models on the market as an upstream provider in the AI value chain. Where Databricks integrates third-party foundation models downstream into our services, or offer models downstream of model providers, those models remain subject to the obligations applicable to their respective model providers under the EU AI Act. The upstream model providers are responsible for compliance with applicable laws and regulations.
Databricks services are use-case agnostic and data agnostic. They are not placed on the market for specific high-risk use cases.
Customers are responsible for assessing whether their intended use of Databricks AI systems, or models through Databricks, constitute high-risk AI uses under the EU AI Act, and for complying with applicable obligations in connection with such uses.
Databricks supports customers’ compliance efforts through:
- Platform-level governance controls;
- Security and monitoring capabilities; and
- Documentation describing use and functionality.
Databricks continues to monitor EU AI Act implementation guidance and harmonised standards and will update its governance approach as appropriate.
Estrutura de teste de IA responsável da Databricks – Equipe vermelha de modelos de IA generativa
A equipe vermelha de IA, especialmente para grandes modelos de linguagem, é um componente importante do desenvolvimento e da implantação de modelos com segurança. A Databricks emprega equipes vermelhas regulares de IA de modelos e sistemas desenvolvidos internamente. Uma visão geral de nossa estrutura de teste de IA responsável está incluída abaixo, apresentando as técnicas que usamos internamente em nosso Adversarial ML Lab para testar nossos modelos, bem como técnicas adicionais da equipe vermelha que estamos avaliando para uso futuro em nosso laboratório.
NOTA: é crucial reconhecer que o campo das equipes vermelhas de IA ainda está nos estágios iniciais, e o ritmo acelerado da inovação traz oportunidades e desafios. Estamos comprometidos com a avaliação contínua de novas abordagens para ataques e contra-ataques e em incluí-las no processo de teste de nossos modelos, quando apropriado.
Esta é a representação diagramática da nossa estrutura de teste de IA generativa:
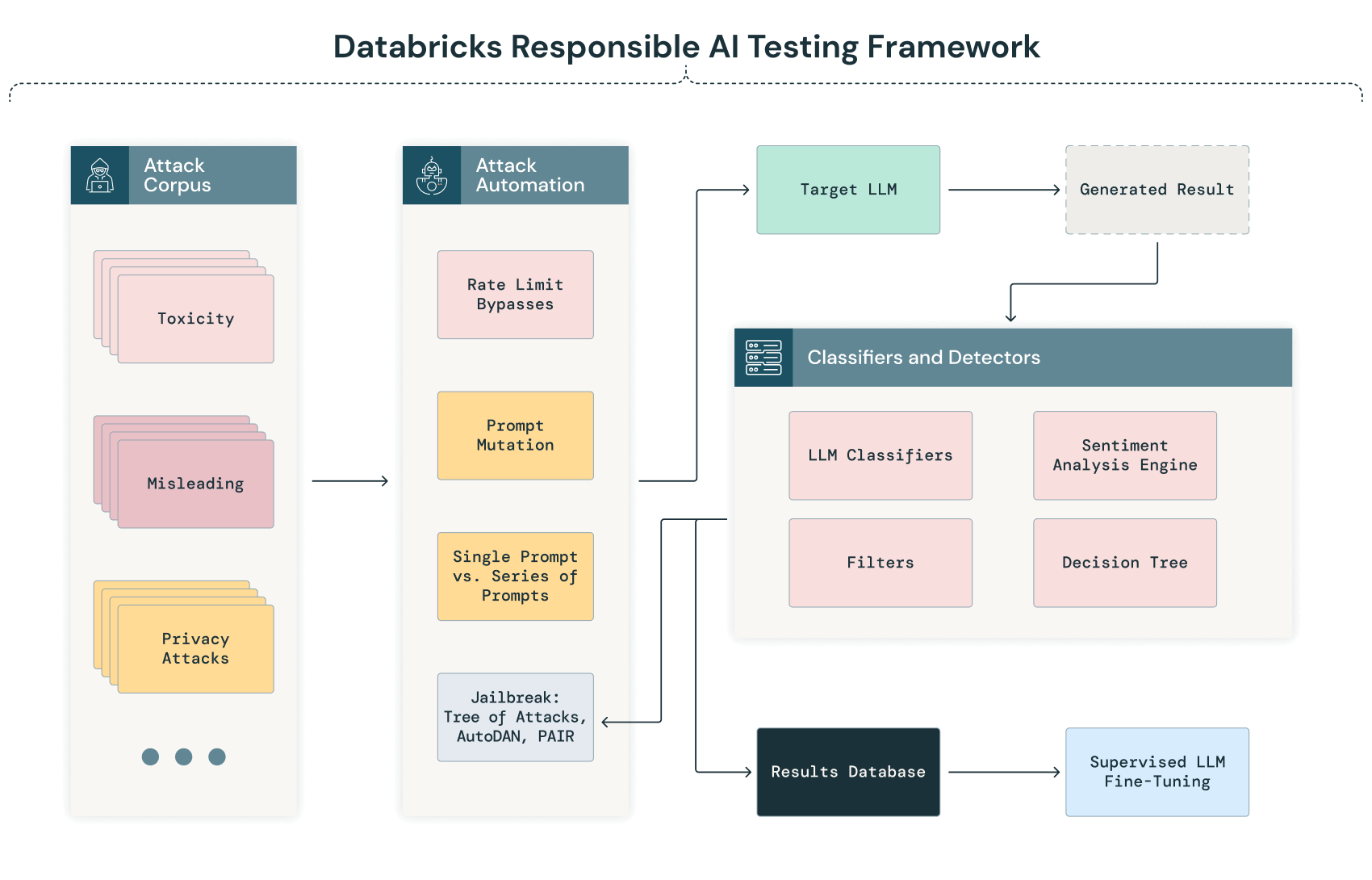
Sondagem e classificação automatizadas
A fase inicial do nosso processo de equipe vermelha de IA envolve um processo automatizado em que uma série de corpora de textos diversos é sistematicamente enviada ao modelo. Esse processo visa investigar as respostas do modelo em uma ampla variedade de cenários, identificando automaticamente possíveis vulnerabilidades, preconceitos ou preocupações com a privacidade antes que uma análise manual mais profunda seja conduzida.
À medida que o LLM processa essas entradas, suas saídas são automaticamente capturadas e classificadas usando critérios predefinidos. Essa classificação pode envolver técnicas de processamento de linguagem natural (PNL) e outros modelos de IA treinados para detectar anomalias, vieses ou desvios do desempenho esperado. Por exemplo, um resultado pode ser sinalizado para revisão manual se apresentar possível viés, respostas sem sentido ou sinais de vazamento de dados.
Jailbreak de LLMs
A Databricks emprega várias técnicas para fazer o jailbreak de LLMs, incluindo:
- Direct Instructions (DI): solicitações diretas do invasor para pedir conteúdo prejudicial.
- Do-Anything-Now Prompts (DAN): uma variedade de ataques que incentivam a modelo a se tornar uma agente de chat do tipo “faça qualquer coisa agora”, capaz de facilitar qualquer tarefa, independentemente dos limites éticos ou de segurança.
- Ataques no estilo Riley Goodside: uma sequência de ataques que pedem diretamente ao modelo para ignorar seu estímulo. Popularizado por Riley Goodside.
- Agency Enterprise PromptInject Corpus: reprodução do corpus Agency Enterprise Prompt Injection, do prêmio de melhor artigo no NeurIPS ML Safety Workshop 2022.
- Prompt Automatic Iterative Refinement (PAIR): um grande modelo de linguagem focado no ataque é usado para refinar o prompt, guiando-o iterativamente em direção a um jailbreak.
- Tree of Attacks With Pruning (TAP): semelhante a um ataque PAIR, mas um LLM adicional, é usado para identificar quando os prompts gerados estão fora do tópico e removê-los da árvore de ataque.
O teste de jailbreak fornece uma compreensão adicional da capacidade do modelo de generalizar e responder a solicitações que são significativamente diferentes dos dados de treinamento ou têm uma forma alternativa de acessar informações protegidas. Ele também nos permite identificar maneiras pelas quais um ataque pode induzir os LLMs a produzir conteúdo prejudicial ou indesejado.
Como esse é um campo em constante evolução, continuaremos a considerar e avaliar técnicas adicionais à medida que o cenário de jailbreak muda.
Validação e análise manual
Após a fase automatizada, o processo de equipe vermelha de IA envolve uma revisão manual dos resultados sinalizados e, para aumentar a probabilidade de identificação de todos os problemas críticos, uma revisão aleatória dos resultados não sinalizados. Essa análise manual permite a interpretação e a validação com nuances dos problemas identificados por meio do processo automatizado.
O processo de equipe vermelha de IA envolve uma quantidade significativa de trabalho manual, no qual as verificações automatizadas podem gerar resultados que não mostram preocupações, mas a avaliação manual pela equipe vermelha pode tentar variantes em que esses prompts podem ser ajustados ou encadeados para encontrar pontos fracos que, caso contrário, não são identificados pelas verificações automatizadas.
Modelo de segurança da cadeia de suprimentos
À medida que nossos esforços de equipe vermelha de IA continuam evoluindo, também incluímos processos para avaliar a segurança da cadeia de suprimentos do modelo de IA, desde o treinamento até a implantação e distribuição. As áreas atuais em avaliação incluem:
- Comprometer os dados de treinamento (envenenamento por adulteração de rótulos ou injeção de dados maliciosos)
- Comprometer a infraestrutura de treinamento (GPU, VM etc.)
- Obter acesso aos LLMs implantados para adulterar pesos e hiperparâmetros
- Manipular filtros e outras camadas defensivas implantadas
- Comprometer a distribuição do modelo. Por exemplo, por meio do comprometimento de terceiros confiáveis, como o Hugging Face.
Ciclo de feedback contínuo
Uma área adicional para nossos esforços de equipe vermelha de AI será um processo para um ciclo de melhoria contínua, que capturaria os entendimentos obtidos tanto com escaneamentos automatizados quanto com análises manuais. Nossa meta para o ciclo de aprimoramento contínuo é promover a evolução de nossos modelos para que se tornem mais robustos e alinhados com os mais altos padrões de desempenho.
Categorias de probes de teste usados pela equipe vermelha da Databricks
A Databricks usa uma série de corpora selecionada (probes) que é enviada ao modelo durante o teste. Os probes são testes ou experimentos específicos projetados para desafiar o sistema de IA de várias maneiras. Para qualquer probe que gere um resultado bem-sucedido e não violador, a equipe vermelha testaria o comportamento inadequado na resposta do modelo tentando outras variantes do mesmo probe. No contexto dos LLMs, os probes usados pela equipe vermelha da Databricks podem ser categorizados da seguinte forma:
Probes de segurança
- Manipulação de entradas: testar a resposta do modelo a entradas alteradas, ruidosas ou maliciosas para identificar vulnerabilidades no processamento de dados.
- Técnicas de evasão: tentativa de contornar as proteções ou os filtros do modelo para induzir resultados prejudiciais ou não intencionais.
- Inversão de modelo: tentativas de extrair informações confidenciais do modelo, comprometendo a privacidade dos dados.
Probes éticos e de viés
- Detecção de viés: avaliação do modelo quanto a preconceitos relacionados a raça, gênero, idade etc., analisando suas respostas a solicitações específicas.
- Dilemas éticos: apresentar ao modelo cenários que testem seu alinhamento com normas e valores éticos.
Probes de robustez e confiabilidade
- Ataques adversários: introdução de entradas ligeiramente modificadas, projetadas para enganar o modelo e levar a saídas incorretas.
- Verificações de consistência: testar a capacidade do modelo de fornecer respostas consistentes e confiáveis em queries semelhantes ou repetidas.
Probes de conformidade e segurança
- Conformidade normativa: testar os resultados e processos do modelo em relação aos regulamentos aplicáveis.
- Cenários de segurança: avaliar o comportamento do modelo em cenários em que a segurança é uma preocupação crítica — para evitar danos ou conselhos perigosos.
- Probes de privacidade: examinar o modelo em relação aos padrões e regulamentos de privacidade de dados, como GDPR ou HIPAA. Esses probes avaliam se o modelo revela indevidamente informações pessoais ou confidenciais em suas saídas ou se ele pode ser manipulado para extrair esses dados.
- Controlabilidade: testar a facilidade com que operadores humanos podem intervir ou controlar as saídas e os comportamentos do modelo.


