Presentación de las funciones de ventana en Spark SQL
por Yin Huai y Michael Armbrust
En esta publicación de blog, presentamos la nueva característica de funciones de ventana que se agregó en Apache Spark. Las funciones de ventana permiten a los usuarios de Spark SQL calcular resultados como el rango de una fila determinada o un promedio móvil sobre un rango de filas de entrada. Mejoran significativamente la expresividad de las API de SQL y DataFrame de Spark. Este blog primero presentará el concepto de funciones de ventana y luego discutirá cómo usarlas con Spark SQL y la API de DataFrame de Spark.
¿Qué son las funciones de ventana?
Antes de la versión 1.4, había dos tipos de funciones compatibles con Spark SQL que se podían usar para calcular un único valor de retorno. Las funciones integradas o UDF, como substr o round, toman valores de una sola fila como entrada y generan un único valor de retorno para cada fila de entrada. Las funciones de agregación, como SUM o MAX, operan sobre un grupo de filas y calculan un único valor de retorno para cada grupo.
Si bien ambas son muy útiles en la práctica, todavía hay una amplia gama de operaciones que no se pueden expresar utilizando solo estos tipos de funciones. Específicamente, no había forma de operar sobre un grupo de filas y al mismo tiempo devolver un solo valor para cada fila de entrada. Esta limitación dificulta la realización de diversas tareas de procesamiento de datos, como el cálculo de un promedio móvil, el cálculo de una suma acumulada o el acceso a los valores de una fila que aparece antes de la fila actual. Afortunadamente para los usuarios de Spark SQL, las funciones de ventana llenan este vacío.
En esencia, una función de ventana calcula un valor de retorno para cada fila de entrada de una tabla basándose en un grupo de filas, llamado el Marco. Cada fila de entrada puede tener un marco único asociado. Esta característica de las funciones de ventana las hace más potentes que otras funciones y permite a los usuarios expresar diversas tareas de procesamiento de datos que son difíciles (si no imposibles) de expresar sin funciones de ventana de manera concisa. Ahora, veamos dos ejemplos.
Supongamos que tenemos una tabla productRevenue como se muestra a continuación.
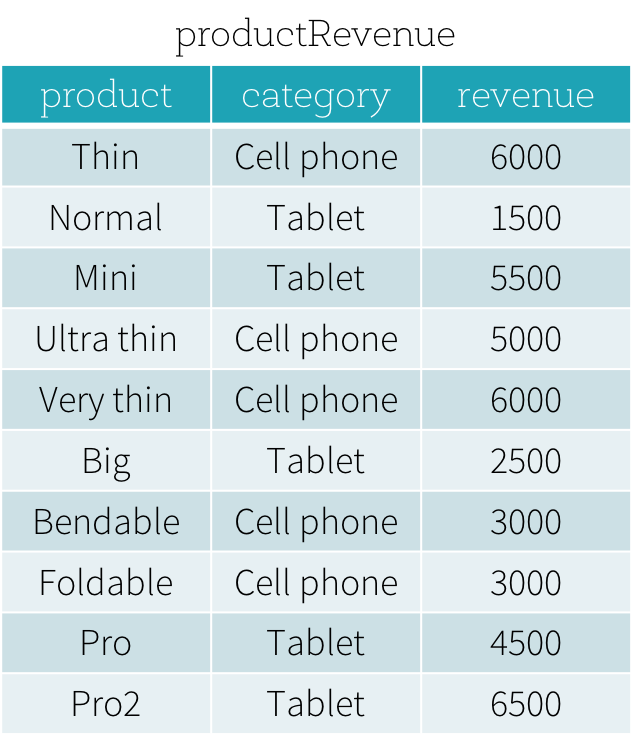
Queremos responder dos preguntas:
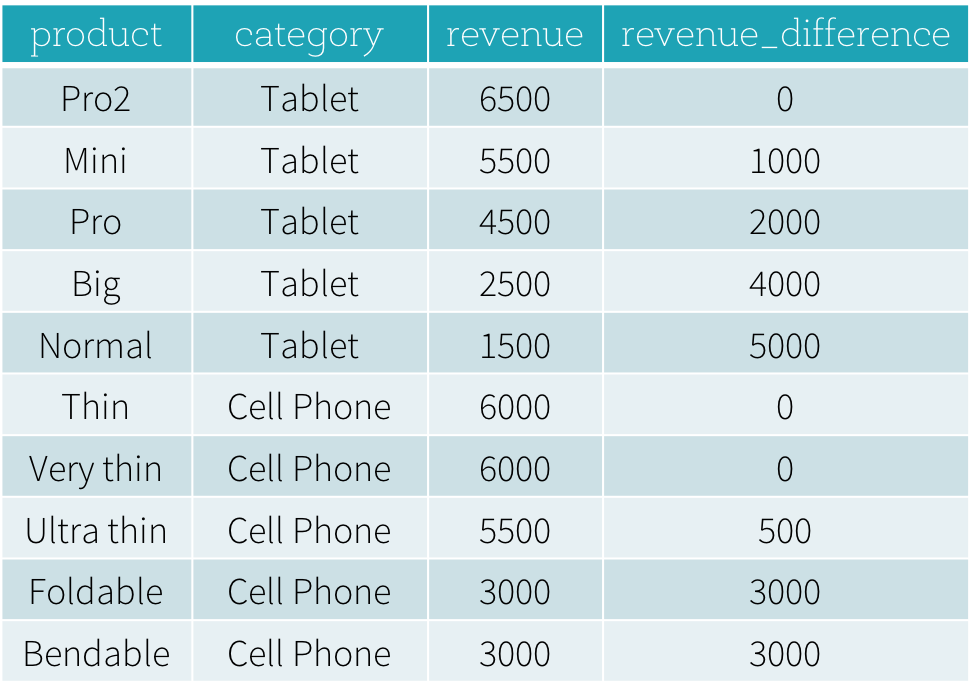
- ¿Cuáles son los productos más vendidos y los segundos más vendidos en cada categoría?
- ¿Cuál es la diferencia entre los ingresos de cada producto y los ingresos del producto más vendido en la misma categoría de ese producto?
Para responder a la primera pregunta “¿Cuáles son los productos más vendidos y los segundos más vendidos en cada categoría?”, necesitamos clasificar los productos en una categoría según sus ingresos y seleccionar los productos más vendidos y los segundos más vendidos según la clasificación. A continuación, se muestra la consulta SQL utilizada para responder a esta pregunta utilizando la función de ventana dense_rank (explicaremos la sintaxis de uso de las funciones de ventana en la siguiente sección).
El resultado de este programa se muestra a continuación. Sin usar funciones de ventana, los usuarios tienen que encontrar todos los valores de ingresos más altos de todas las categorías y luego unir este conjunto de datos derivado con la tabla productRevenue original para calcular las diferencias de ingresos.
Uso de funciones de ventana
Spark SQL admite tres tipos de funciones de ventana: funciones de clasificación, funciones analíticas y funciones de agregación. Las funciones de clasificación y analíticas disponibles se resumen en la siguiente tabla. Para las funciones de agregación, los usuarios pueden usar cualquier función de agregación existente como función de ventana.
| SQL | API de DataFrame | |
| Funciones de clasificación | rank | rank |
| dense_rank | denseRank | |
| percent_rank | percentRank | |
| ntile | ntile | |
| row_number | rowNumber | |
| Funciones analíticas | cume_dist | cumeDist |
| first_value | firstValue | |
| last_value | lastValue | |
| lag | lag | |
| lead | lead |
Para usar funciones de ventana, los usuarios deben marcar que una función se usa como función de ventana ya sea
- Agregando una cláusula OVER después de una función compatible en SQL, por ejemplo,
avg(revenue) OVER (...); o - Llamando al método over en una función compatible en la API de DataFrame, por ejemplo,
rank().over(...).
Una vez que una función se marca como función de ventana, el siguiente paso clave es definir la Especificación de Ventana asociada con esta función. Una especificación de ventana define qué filas se incluyen en el marco asociado con una fila de entrada dada. Una especificación de ventana incluye tres partes:
- Especificación de Partición: controla qué filas estarán en la misma partición con la fila dada. Además, el usuario podría querer asegurarse de que todas las filas con el mismo valor para la columna de categoría se recopilen en la misma máquina antes de ordenar y calcular el marco. Si no se proporciona una especificación de partición, todos los datos deben recopilarse en una sola máquina.
- Especificación de Ordenación: controla la forma en que se ordenan las filas en una partición, determinando la posición de la fila dada en su partición.
- Especificación de Marco: indica qué filas se incluirán en el marco para la fila de entrada actual, basándose en su posición relativa a la fila actual. Por ejemplo, "las tres filas anteriores a la fila actual hasta la fila actual" describe un marco que incluye la fila de entrada actual y tres filas que aparecen antes de la fila actual.
En SQL, las palabras clave PARTITION BY y ORDER BY se utilizan para especificar expresiones de partición para la especificación de partición, y expresiones de ordenación para la especificación de ordenación, respectivamente. La sintaxis SQL se muestra a continuación.
OVER (PARTITION BY ... ORDER BY ...)
En la API de DataFrame, proporcionamos funciones de utilidad para definir una especificación de ventana. Tomando Python como ejemplo, los usuarios pueden especificar expresiones de partición y expresiones de ordenación de la siguiente manera.
Además de la ordenación y la partición, los usuarios deben definir el límite de inicio del marco, el límite final del marco y el tipo de marco, que son tres componentes de una especificación de marco.
Hay cinco tipos de límites, que son UNBOUNDED PRECEDING, UNBOUNDED FOLLOWING, CURRENT ROW, UNBOUNDED PRECEDING y UNBOUNDED FOLLOWING representan la primera fila de la partición y la última fila de la partición, respectivamente. Para los otros tres tipos de límites, especifican el desplazamiento desde la posición de la fila de entrada actual y sus significados específicos se definen según el tipo de marco. Hay dos tipos de marcos, marco ROW y marco RANGE.
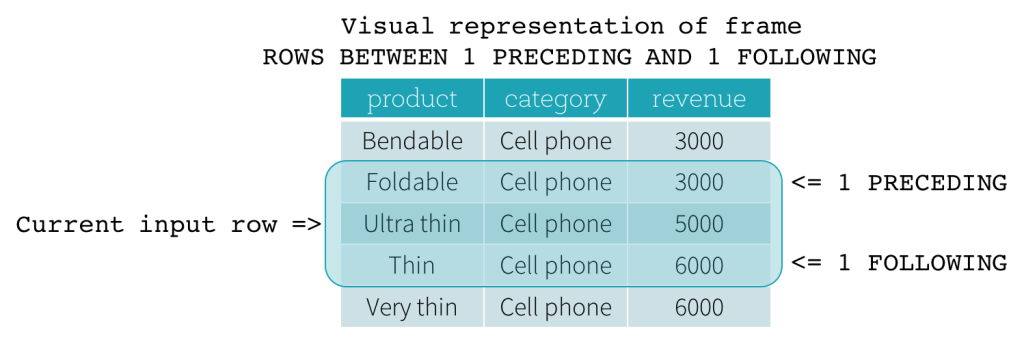
Marco ROW
Los marcos ROW se basan en desplazamientos físicos desde la posición de la fila de entrada actual, lo que significa que CURRENT ROW, CURRENT ROW como límite, representa la fila de entrada actual. 1 PRECEDING como límite de inicio y 1 FOLLOWING como límite de fin (ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING en la sintaxis SQL).
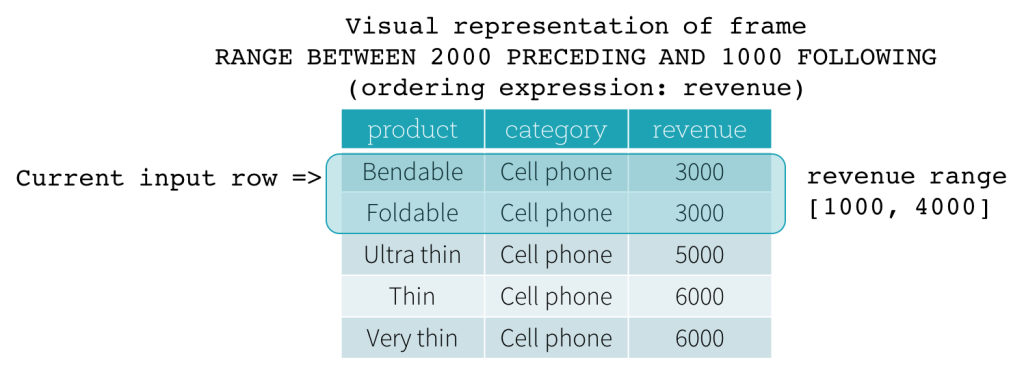
Marco RANGE
Los marcos RANGE se basan en desplazamientos lógicos desde la posición de la fila de entrada actual y tienen una sintaxis similar al marco ROW. Un desplazamiento lógico es la diferencia entre el valor de la expresión de ordenación de la fila de entrada actual y el valor de esa misma expresión de la fila límite del marco. Debido a esta definición, cuando se utiliza un marco RANGE, solo se permite una única expresión de ordenación. Además, para un marco RANGE, todas las filas que tienen el mismo valor de la expresión de ordenación que la fila de entrada actual se consideran como la misma fila en lo que respecta al cálculo del límite.
Ahora, veamos un ejemplo. En este ejemplo, la expresión de ordenación es revenue; el límite de inicio es 2000 PRECEDING; y el límite de fin es 1000 FOLLOWING (este marco se define como RANGE BETWEEN 2000 PRECEDING AND 1000 FOLLOWING en la sintaxis SQL). Las siguientes cinco figuras ilustran cómo se actualiza el marco con la actualización de la fila de entrada actual. Básicamente, para cada fila de entrada actual, basándonos en el valor de los ingresos (revenue), calculamos el rango de ingresos [valor de ingresos actual - 2000, valor de ingresos actual + 1000]. Todas las filas cuyos valores de ingresos caen en este rango están en el marco de la fila de entrada actual.
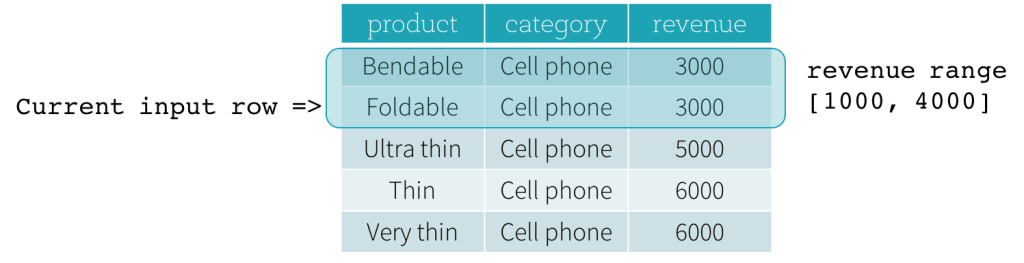
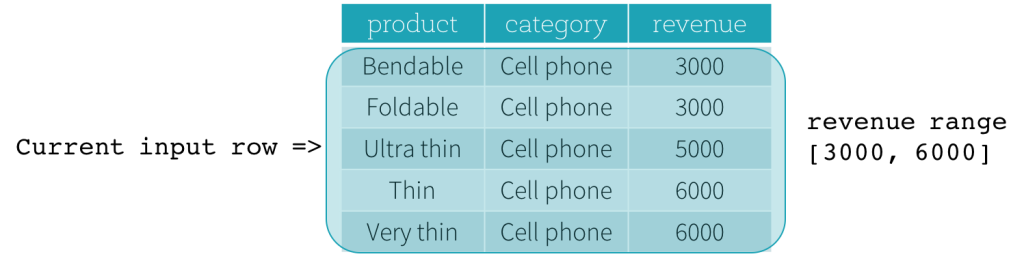
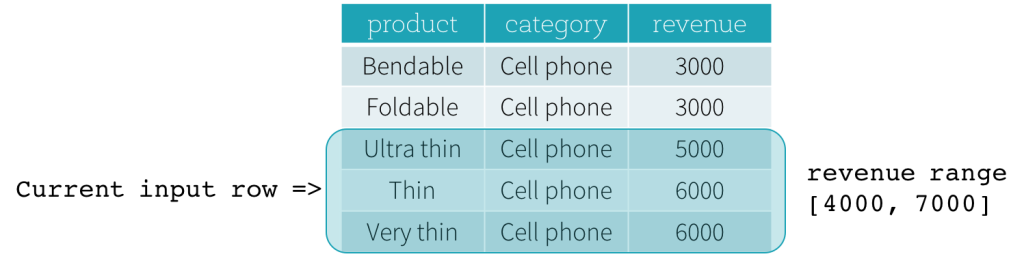
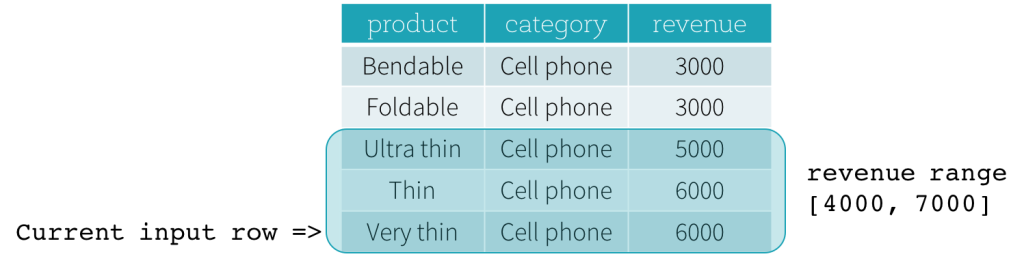
En resumen, para definir una especificación de ventana, los usuarios pueden usar la siguiente sintaxis en SQL.
OVER (PARTITION BY ... ORDER BY ... frame_type BETWEEN start AND end)
Aquí, frame_type puede ser ROWS (para marco ROW) o RANGE (para marco RANGE); start puede ser cualquiera de UNBOUNDED PRECEDING, CURRENT ROW, end puede ser cualquiera de UNBOUNDED FOLLOWING, CURRENT ROW,
En la API de DataFrame de Python, los usuarios pueden definir una especificación de ventana de la siguiente manera.
¿Qué sigue?
Desde el lanzamiento de Spark 1.4, hemos estado trabajando activamente con miembros de la comunidad en optimizaciones que mejoran el rendimiento y reducen el consumo de memoria del operador que evalúa las funciones de ventana. Algunas de estas se añadirán en Spark 1.5, y otras se añadirán en nuestras futuras versiones. Además del trabajo de mejora del rendimiento, hay dos características que añadiremos en un futuro próximo para hacer que el soporte de funciones de ventana en Spark SQL sea aún más potente. En primer lugar, hemos estado trabajando en añadir soporte para el tipo de dato Interval para los tipos de dato Date y Timestamp (SPARK-8943). Con el tipo de dato Interval, los usuarios pueden usar intervalos como valores especificados en
Para probar estas características de Spark, obtén una prueba gratuita de Databricks o usa la Community Edition.
Agradecimientos
El desarrollo del soporte de funciones de ventana en Spark 1.4 es un trabajo conjunto de muchos miembros de la comunidad de Spark. En particular, nos gustaría agradecer a Wei Guo por contribuir con el parche inicial.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.