Predicción de series temporales con granularidad fina a escala con Facebook Prophet y Apache Spark
Prueba este cuaderno de pronóstico de series temporales en nuestro Acelerador de Soluciones para Pronóstico de Demanda.
Los avances en el pronóstico de series temporales permiten a los minoristas generar pronósticos de demanda más fiables. El desafío ahora es producir estos pronósticos de manera oportuna y con un nivel de granularidad que permita al negocio realizar ajustes precisos en los inventarios de productos. Aprovechando Apache Spark™ y Facebook Prophet, cada vez más empresas que enfrentan estos desafíos descubren que pueden superar los límites de escalabilidad y precisión de soluciones anteriores.
En esta publicación, discutiremos la importancia del pronóstico de series temporales, visualizaremos algunos datos de series temporales de ejemplo y luego construiremos un modelo simple para mostrar el uso de Facebook Prophet. Una vez que te sientas cómodo construyendo un solo modelo, combinaremos Prophet con la magia de Apache Spark™ para mostrarte cómo entrenar cientos de modelos a la vez, lo que nos permitirá crear pronósticos precisos para cada combinación individual de producto-tienda a un nivel de granularidad que rara vez se ha logrado hasta ahora.
La previsión precisa y oportuna es ahora más importante que nunca
Mejorar la velocidad y la precisión de los análisis de series temporales para pronosticar mejor la demanda de productos y servicios es fundamental para el éxito de los minoristas. Si se coloca demasiado producto en una tienda, el espacio en los estantes y en el almacén puede verse limitado, los productos pueden caducar y los minoristas pueden encontrar que sus recursos financieros están inmovilizados en inventario, lo que les impide aprovechar nuevas oportunidades generadas por los fabricantes o los cambios en los patrones de consumo. Si se coloca muy poco producto en una tienda, los clientes pueden no poder comprar los productos que necesitan. Estos errores de pronóstico no solo resultan en una pérdida inmediata de ingresos para el minorista, sino que con el tiempo la frustración del consumidor puede alejar a los clientes hacia la competencia.
Las nuevas expectativas requieren métodos y modelos de pronóstico de series temporales más precisos
Durante algún tiempo, los sistemas de planificación de recursos empresariales (ERP) y las soluciones de terceros han proporcionado a los minoristas capacidades de pronóstico de demanda basadas en modelos simples de series temporales. Pero con los avances en la tecnología y la creciente presión en el sector, muchos minoristas buscan ir más allá de los modelos lineales y los algoritmos más tradicionales disponibles históricamente para ellos.
Están surgiendo nuevas capacidades, como las proporcionadas por Facebook Prophet, de la comunidad de ciencia de datos, y las empresas buscan la flexibilidad para aplicar estos modelos de aprendizaje automático a sus necesidades de pronóstico de series temporales.
![]()
Este alejamiento de las soluciones de pronóstico tradicionales requiere que los minoristas y otros desarrollen experiencia interna no solo en las complejidades del pronóstico de demanda, sino también en la distribución eficiente del trabajo necesario para generar cientos de miles o incluso millones de modelos de aprendizaje automático de manera oportuna. Afortunadamente, podemos usar Spark para distribuir el entrenamiento de estos modelos, lo que hace posible predecir no solo la demanda general de productos y servicios, sino la demanda única de cada producto en cada ubicación.
Visualización de la estacionalidad de la demanda en datos de series temporales
Para demostrar el uso de Prophet para generar pronósticos de demanda detallados para tiendas y productos individuales, utilizaremos un conjunto de datos disponible públicamente de Kaggle. Consiste en 5 años de datos de ventas diarias para 50 artículos individuales en 10 tiendas diferentes.
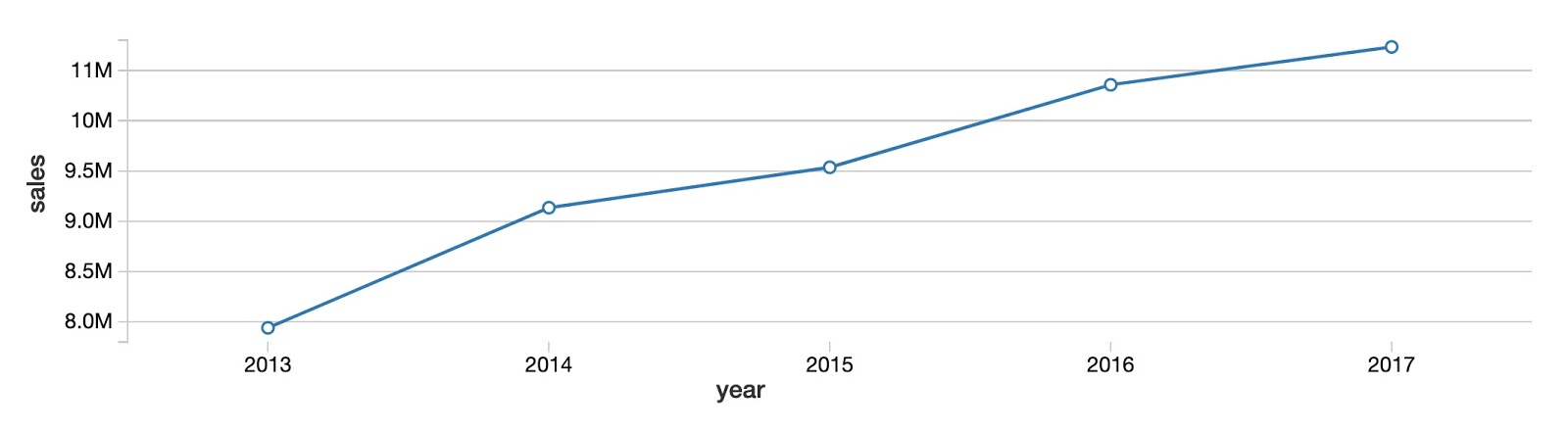
Para empezar, veamos la tendencia general de ventas anuales para todos los productos y tiendas. Como puede ver, las ventas totales de productos están aumentando año tras año sin un signo claro de convergencia alrededor de una meseta.
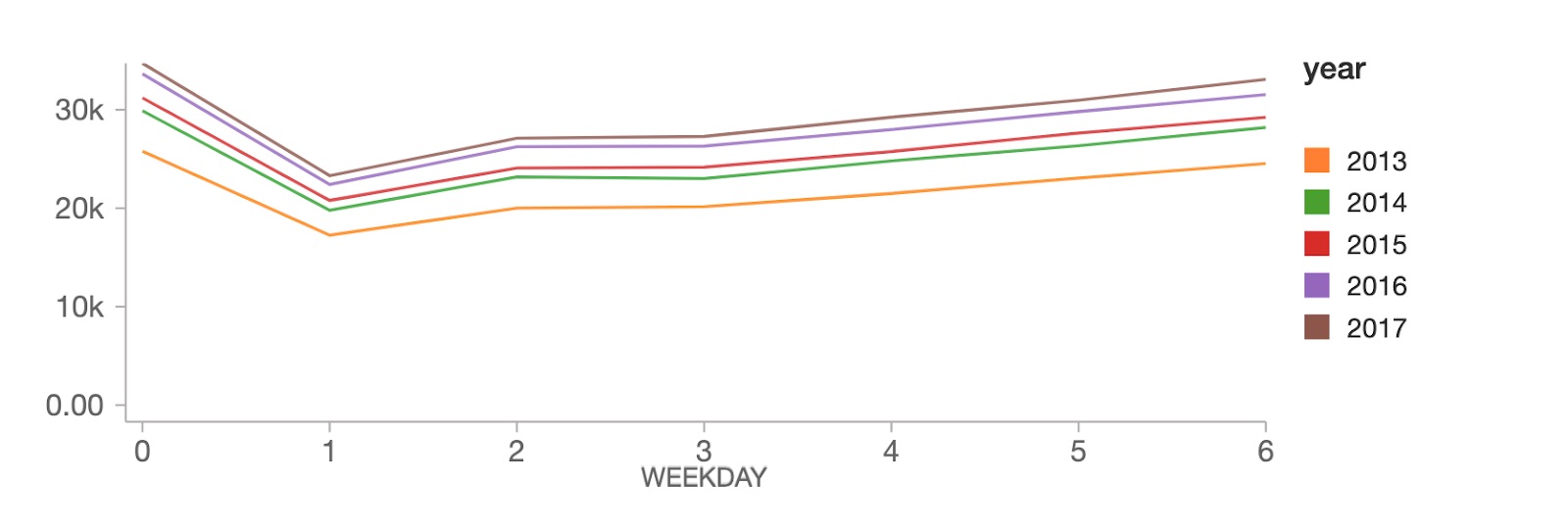
A nivel de día de la semana, las ventas alcanzan su punto máximo los domingos (día de la semana 0), seguidas de una fuerte caída los lunes (día de la semana 1), y luego se recuperan constantemente durante el resto de la semana.
Comenzando con un modelo simple de pronóstico de series temporales en Facebook Prophet
Como se ilustra en los gráficos anteriores, nuestros datos muestran una clara tendencia ascendente interanual en las ventas, junto con patrones estacionales tanto anuales como semanales. Son estos patrones superpuestos en los datos para los que Prophet está diseñado para abordar.
Facebook Prophet sigue la API de scikit-learn, por lo que debería ser fácil de usar para cualquiera con experiencia en sklearn. Necesitamos pasar un pandas DataFrame de 2 columnas como entrada: la primera columna es la fecha y la segunda es el valor a predecir (en nuestro caso, las ventas). Una vez que nuestros datos estén en el formato correcto, construir un modelo es fácil:
Ahora que hemos ajustado nuestro modelo a los datos, usémoslo para construir un pronóstico de 90 días. En el siguiente código, definimos un conjunto de datos que incluye fechas históricas y 90 días adicionales, utilizando el método make_future_dataframe de Prophet:
¡Eso es todo! Ahora podemos visualizar cómo se alinean nuestros datos reales y predichos, así como un pronóstico para el futuro utilizando el método .plot incorporado de Prophet. Como puede ver, los patrones de demanda semanales y estacionales que ilustramos anteriormente se reflejan de hecho en los resultados pronosticados.
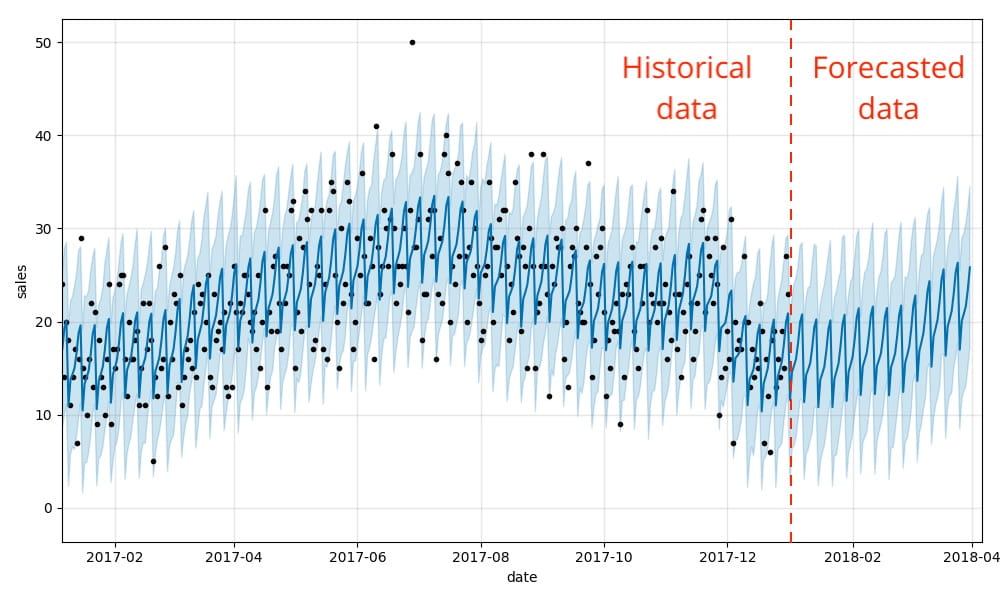
Esta visualización es un poco abrumadora. Bartosz Mikulski proporciona un excelente desglose de ella que vale la pena consultar. En resumen, los puntos negros representan nuestros datos reales, la línea azul más oscura representa nuestras predicciones y la banda azul más clara representa nuestro intervalo de incertidumbre (95%).
Entrenamiento de cientos de modelos de pronóstico de series temporales en paralelo con Prophet y Spark
Ahora que hemos demostrado cómo construir un modelo de pronóstico de series temporales único, podemos usar el poder de Apache Spark para multiplicar nuestros esfuerzos. Nuestro objetivo es generar no un pronóstico para todo el conjunto de datos, sino cientos de modelos y pronósticos para cada combinación de producto-tienda, algo que sería increíblemente lento de realizar como una operación secuencial.
Construir modelos de esta manera podría permitir que una cadena de supermercados, por ejemplo, cree un pronóstico preciso para la cantidad de leche que deberían pedir para su tienda de Sandusky que difiera de la cantidad necesaria en su tienda de Cleveland, basándose en la demanda diferente en esas ubicaciones.
Cómo usar Spark DataFrames para distribuir el procesamiento de datos de series temporales
Los científicos de datos a menudo se enfrentan al desafío de entrenar un gran número de modelos utilizando un motor de procesamiento de datos distribuido como Apache Spark. Al aprovechar un clúster de Spark, los nodos de trabajo individuales en el clúster pueden entrenar un subconjunto de modelos en paralelo con otros nodos de trabajo, lo que reduce significativamente el tiempo total requerido para entrenar toda la colección de modelos de series temporales.
Por supuesto, entrenar modelos en un clúster de nodos de trabajo (computadoras) requiere más infraestructura en la nube, y esto tiene un precio. Pero con la fácil disponibilidad de recursos en la nube bajo demanda, las empresas pueden aprovisionar rápidamente los recursos que necesitan, entrenar sus modelos y liberar esos recursos con la misma rapidez, lo que les permite lograr una escalabilidad masiva sin compromisos a largo plazo con activos físicos.
El mecanismo clave para lograr el procesamiento distribuido de datos en Spark es el DataFrame. Al cargar los datos en un Spark DataFrame, los datos se distribuyen entre los trabajadores del clúster. Esto permite que estos trabajadores procesen subconjuntos de los datos de manera paralela, reduciendo la cantidad total de tiempo requerida para realizar nuestro trabajo.
Por supuesto, cada trabajador necesita tener acceso al subconjunto de datos que requiere para hacer su trabajo. Al agrupar los datos por valores clave, en este caso por combinaciones de tienda y artículo, reunimos todos los datos de series temporales para esos valores clave en un nodo de trabajo específico.
Compartimos el código groupBy aquí para subrayar cómo nos permite entrenar muchos modelos en paralelo de manera eficiente, aunque en realidad no entrará en juego hasta que configuremos y apliquemos una UDF a nuestros datos en la siguiente sección.
Aprovechando el poder de las funciones definidas por el usuario (UDF) de pandas
Con nuestros datos de series temporales agrupados correctamente por tienda y artículo, ahora necesitamos entrenar un modelo único para cada grupo. Para lograr esto, podemos usar una Función Definida por el Usuario (UDF) de pandas, que nos permite aplicar una función personalizada a cada grupo de datos en nuestro DataFrame.
Esta UDF no solo entrenará un modelo para cada grupo, sino que también generará un conjunto de resultados que representa las predicciones de ese modelo. Pero mientras la función entrenará y predecirá en cada grupo del DataFrame independientemente de los demás, los resultados devueltos de cada grupo se recopilarán convenientemente en un único DataFrame resultante. Esto nos permitirá generar pronósticos a nivel de tienda-artículo pero presentar nuestros resultados a analistas y gerentes como un único conjunto de datos de salida.
Como puede ver en el código Python abreviado a continuación, la creación de nuestra UDF es relativamente sencilla. La UDF se instancia con el método pandas_udf que identifica el esquema de los datos que devolverá y el tipo de datos que espera recibir. Inmediatamente después, definimos la función que realizará el trabajo de la UDF.
Dentro de la definición de la función, instanciamos nuestro modelo, lo configuramos y lo ajustamos a los datos que ha recibido. El modelo realiza una predicción y esos datos se devuelven como la salida de la función.
Ahora, para unir todo, usamos el comando groupBy que discutimos anteriormente para asegurar que nuestro conjunto de datos esté correctamente particionado en grupos que representan combinaciones específicas de tienda y artículo. Luego, simplemente apply la UDF a nuestro DataFrame, permitiendo que la UDF ajuste un modelo y haga predicciones en cada agrupación de datos.
El conjunto de datos devuelto por la aplicación de la función a cada grupo se actualiza para reflejar la fecha en la que generamos nuestras predicciones. Esto nos ayudará a realizar un seguimiento de los datos generados durante diferentes ejecuciones de modelos a medida que llevamos nuestra funcionalidad a producción.
Próximos pasos
Ahora hemos construido un modelo de pronóstico de series temporales para cada combinación de tienda y artículo. Usando una consulta SQL, los analistas pueden ver los pronósticos personalizados para cada producto. En el gráfico a continuación, hemos trazado la demanda proyectada para el producto n.º 1 en 10 tiendas. Como puede ver, los pronósticos de demanda varían de una tienda a otra, pero el patrón general es consistente en todas las tiendas, como cabría esperar.
A medida que llegan nuevos datos de ventas, podemos generar eficientemente nuevos pronósticos y agregarlos a nuestras estructuras de tabla existentes, lo que permite a los analistas actualizar las expectativas del negocio a medida que evolucionan las condiciones.
Para obtener más información, vea el seminario web bajo demanda titulado Cómo Starbucks pronostica la demanda a escala con Facebook Prophet y Azure Databricks y consulte nuestro Acelerador de Soluciones para Pronóstico de Demanda.

(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.