Cómo simplificar la CDC con el feed de datos de cambio de Delta Lake
por Surya Sai Turaga y John O'Dwyer
Prueba este notebook en Databricks
Change data capture (CDC) es un caso de uso que vemos que muchos clientes implementan en Databricks. Puedes consultar nuestro análisis anterior en profundidad sobre el tema aquí. Normalmente, vemos que la CDC se utiliza en una arquitectura de ingesta a análisis llamada arquitectura medallion. La arquitectura medallion toma datos sin procesar aterrizados de los sistemas de origen y refina los datos a través de tablas de bronce, plata y oro. La CDC y la arquitectura medallion proporcionan múltiples beneficios a los usuarios, ya que solo es necesario procesar los datos cambiados o añadidos. Además, las diferentes tablas de la arquitectura permiten que diferentes perfiles, como los científicos de datos y los analistas de BI, utilicen los datos correctos y actualizados para sus necesidades. Nos complace anunciar la nueva y emocionante función Change Data Feed (CDF) en Delta Lake, ¡que hace que esta arquitectura sea más fácil de implementar y posible la operación MERGE y el control de versiones de registro de Delta Lake!
Obtén una vista previa temprana del nuevo ebook de O'Reilly para obtener la guía paso a paso que necesitas para empezar a usar Delta Lake.
¿Por qué es necesaria la función CDF?
Muchos clientes utilizan Databricks para realizar CDC, ya que es más fácil de implementar con Delta Lake en comparación con otras tecnologías de Big Data. Sin embargo, incluso con las herramientas adecuadas, la CDC puede seguir siendo difícil de ejecutar. Diseñamos CDF para que la codificación sea aún más sencilla y para abordar los mayores puntos débiles en torno a la CDC, incluyendo:
- Control de calidad: los cambios a nivel de fila son difíciles de obtener entre versiones.
- Ineficiencia: puede ser ineficiente tener en cuenta las filas que no cambian, ya que los cambios de la versión actual son a nivel de archivo y no de fila.
Así es como la implementación de Change Data Feed (CDF) ayuda a resolver los problemas anteriores:
- Simplicidad y conveniencia: utiliza un patrón común y fácil de usar para identificar cambios, lo que hace que tu código sea simple, conveniente y fácil de entender.
- Eficiencia: la capacidad de tener solo las filas que han cambiado entre versiones hace que el consumo posterior de las operaciones Merge, Update y Delete sea extremadamente eficiente.
CDF captura cambios solo de una tabla Delta y es solo prospectivo una vez habilitado.
¡Change Data Feed en acción!
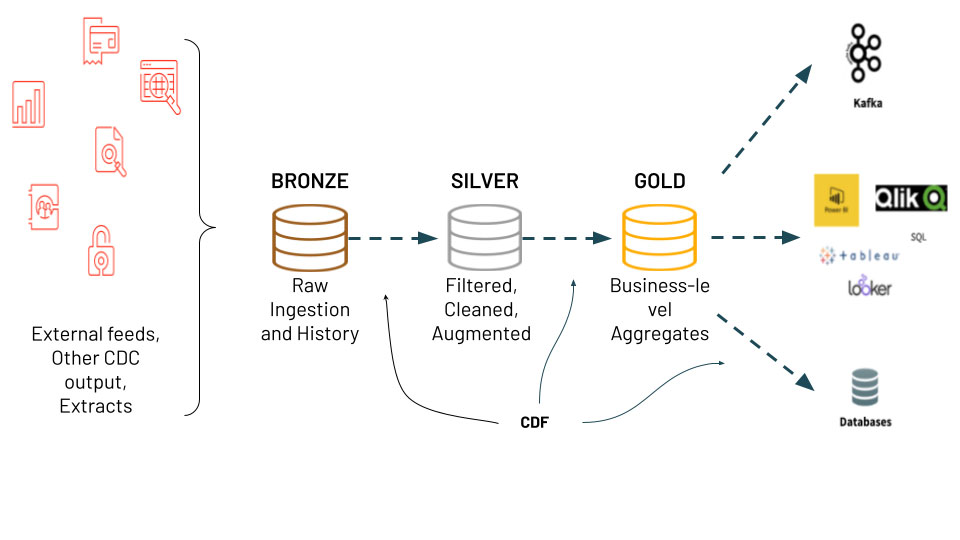
Profundicemos en un ejemplo de CDF para un caso de uso común: predicciones financieras. El notebook referenciado en la parte superior de este blog ingiere datos financieros. Estimated Earnings Per Share (EPS) son datos financieros de analistas que predicen el beneficio por acción trimestral de una empresa. Los datos sin procesar pueden provenir de muchas fuentes diferentes y de múltiples analistas para múltiples acciones.
Con la función CDF, los datos simplemente se insertan en la tabla de bronce (ingesta sin procesar), luego se filtran, limpian y aumentan en la tabla de plata y, finalmente, se calculan los valores agregados en la tabla de oro basándose en los datos cambiados en la tabla de plata.
Si bien estas transformaciones pueden volverse complejas, afortunadamente, ahora la función CDF basada en filas es simple y eficiente. Pero, ¿cómo se usa? ¡Vamos a ver!
NOTA: El ejemplo aquí se centra en la versión SQL de CDF y también en una forma específica de usar las operaciones; para evaluar variaciones, consulta la documentación aquí
Habilitación de CDF en una tabla Delta Lake
Para tener la función CDF disponible en una tabla, primero debes habilitar la función en dicha tabla. A continuación, se muestra un ejemplo de habilitación de CDF para la tabla de bronce al crear la tabla. También puedes habilitar CDF en una tabla como una actualización de la tabla. Además, puedes habilitar CDF en un clúster para todas las tablas creadas por el clúster. Para estas variaciones, consulta la documentación aquí.

Change Data Feed es una función prospectiva, capturará cambios una vez que se configure la propiedad de la tabla y no antes.
Consulta de los datos de cambio
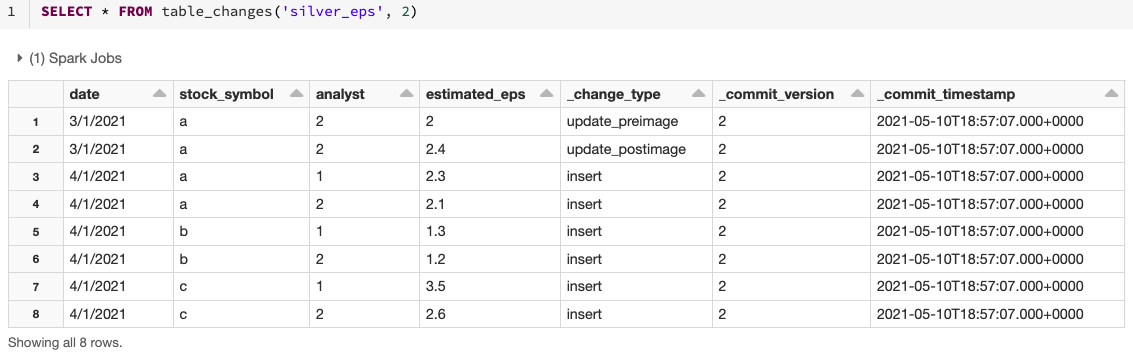
Para consultar los datos de cambio, utiliza la operación table_changes. El siguiente ejemplo incluye filas insertadas y dos filas que representan la imagen previa y posterior de una fila actualizada, para que podamos evaluar las diferencias en los cambios si es necesario. También hay un tipo de cambio delete que se devuelve para las filas eliminadas.
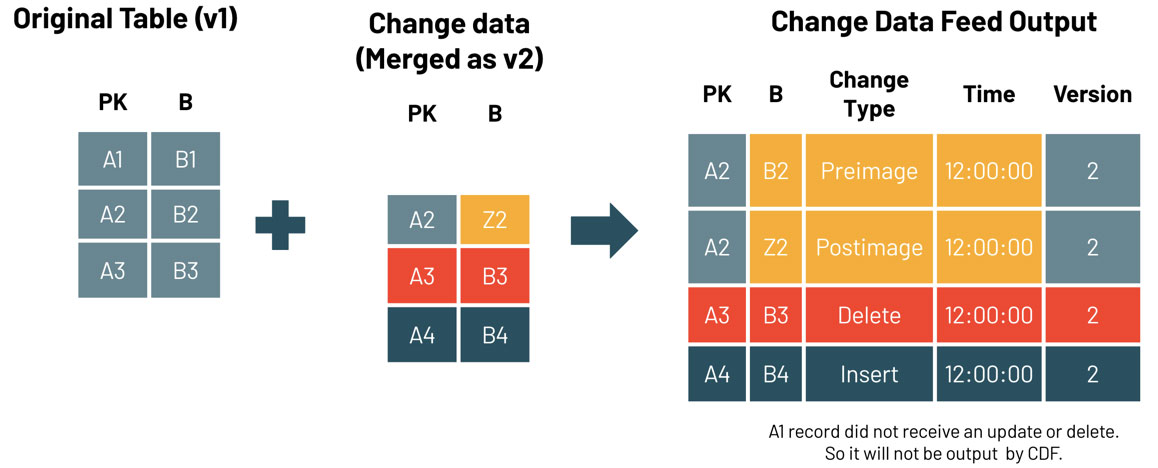
Este ejemplo accede a los registros cambiados basándose en la versión de inicio, pero también puedes limitar las versiones basándote en la versión de fin, así como en las marcas de tiempo de inicio y fin si es necesario. Este ejemplo se centra en SQL, pero también hay formas de acceder a estos datos en Python, Scala, Java y R. Para estas variaciones, consulta la documentación aquí.
Uso de datos de filas de CDF en una declaración MERGE
Las declaraciones MERGE agregadas, como la fusión en la tabla de oro, pueden ser complejas por naturaleza, pero la función CDF hace que la codificación de estas declaraciones sea más simple y eficiente.
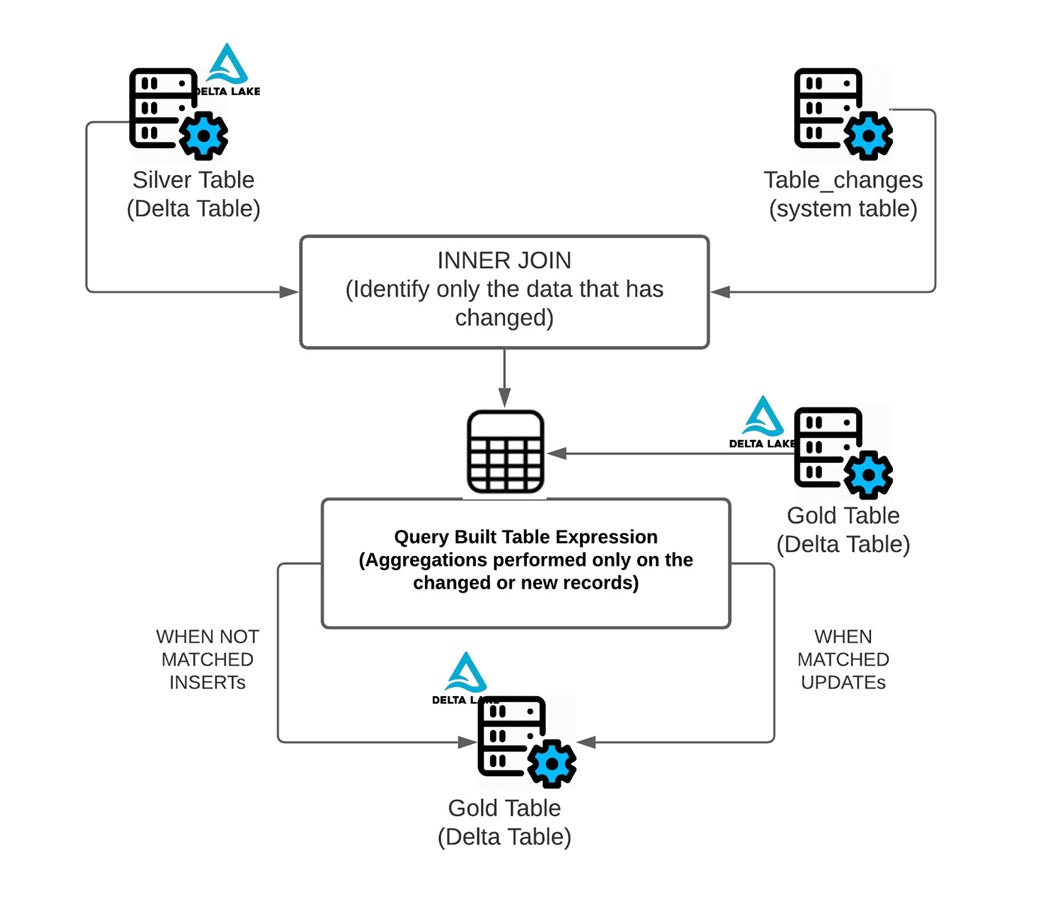
Como se ve en el diagrama anterior, CDF facilita la derivación de qué filas han cambiado, ya que solo realiza la agregación necesaria en los datos que han cambiado o son nuevos utilizando la operación table_changes. A continuación, puedes ver cómo utilizar los datos cambiados para determinar qué fechas y símbolos de acciones han cambiado.
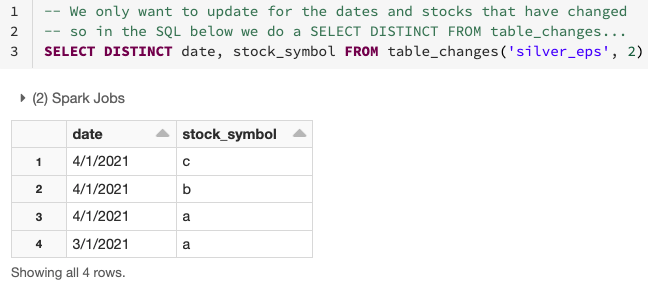
Como se muestra a continuación, puedes usar los datos cambiados de la tabla de plata para agregar solo los datos de las filas que necesitan ser actualizadas o insertadas en la tabla de oro. Para hacer esto, usa INNER JOIN en table_changes('nombre_tabla','versión')
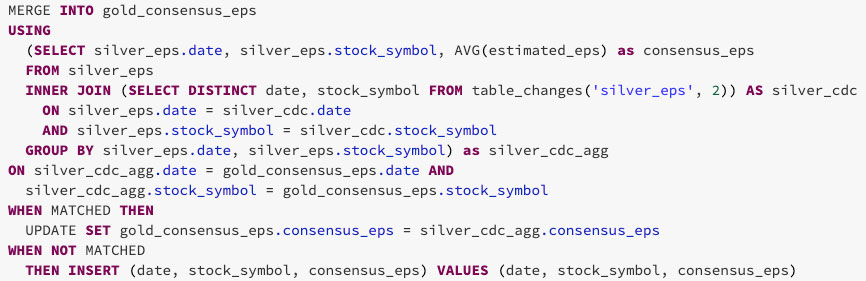
¡El resultado final es una versión clara y concisa de una tabla de oro que puede cambiar incrementalmente con el tiempo!
Casos de uso típicos
Estos son algunos casos de uso y beneficios comunes de la nueva función CDF:
Tablas Silver y Gold
Mejora el rendimiento de Delta procesando solo los cambios después de la comparación inicial de MERGE para acelerar y simplificar las operaciones ETL/ELT.
Vistas materializadas
Crea vistas de información actualizadas y agregadas para usar en BI y análisis sin tener que reprocesar las tablas subyacentes completas, actualizando en su lugar solo donde han llegado los cambios.
Transmitir cambios
Envía Change Data Feed a sistemas downstream como Kafka o RDBMS que pueden usarlo para procesar incrementalmente en etapas posteriores de los pipelines de datos.
Tabla de registro de auditoría
Capturar las salidas de Change Data Feed como una tabla Delta proporciona almacenamiento perpetuo y capacidad de consulta eficiente para ver todos los cambios a lo largo del tiempo, incluyendo cuándo ocurren las eliminaciones y qué actualizaciones se realizaron.
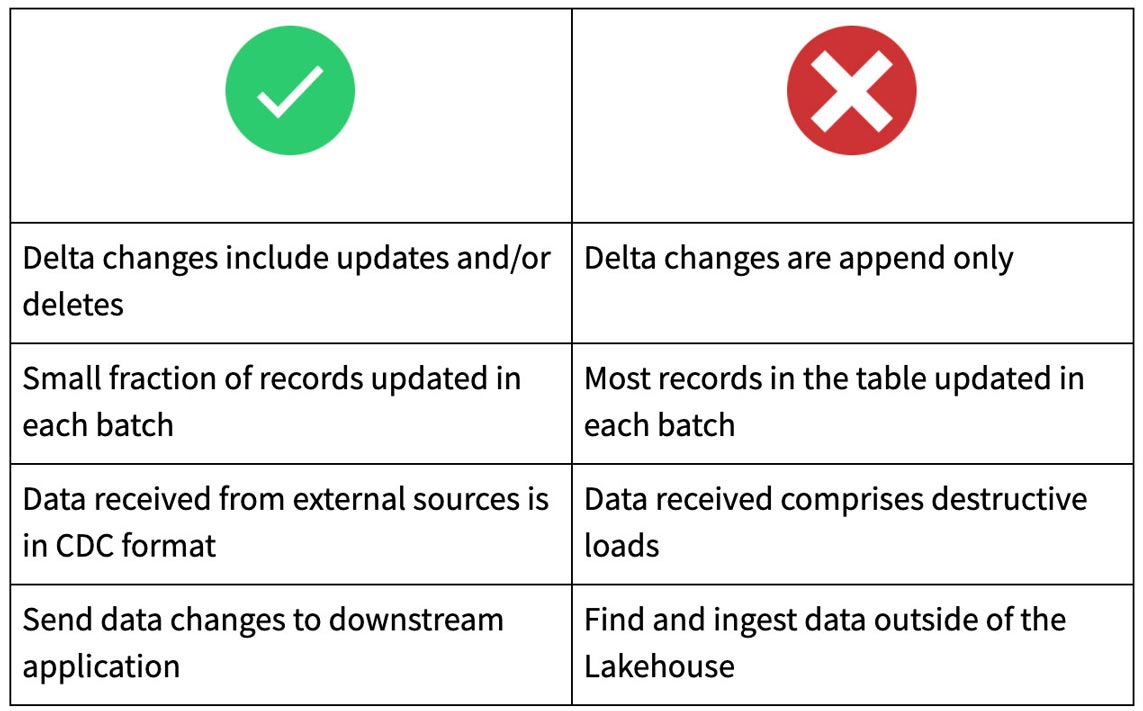
Cuándo usar Change Data Feed
Conclusión
En Databricks, nos esforzamos por hacer posible lo imposible y simplificar lo difícil. CDC, versionado de registros e implementación de MERGE eran prácticamente imposibles a escala hasta que se creó Delta Lake. ¡Ahora lo estamos haciendo más simple y eficiente con la emocionante función Change Data Feed (CDF)!
Prueba este notebook en Databricks
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.