Parte 1: Implementación de CI/CD en Databricks usando Databricks Notebooks y Azure DevOps
por Michael Shtelma y Piotr Majer
El código discutido se puede encontrar aquí.
Esta es la primera parte de una serie de dos publicaciones de blog que muestran cómo configurar y crear soluciones de MLOps de extremo a extremo en Databricks con notebooks y la API de Repos. Esta publicación presenta un marco de CI/CD en Databricks, que se basa en Notebooks. La canalización se integra con el ecosistema de Microsoft Azure DevOps para la parte de Integración Continua (CI) y la API de Repos para la Entrega Continua (CD). En la segunda publicación, mostraremos cómo aprovechar la funcionalidad de la API de Repos para implementar un ciclo de vida completo de CI/CD en Databricks y extenderlo a una solución MLOps completa.
CI/CD con Databricks Repos
Afortunadamente, con la nueva funcionalidad proporcionada por Databricks Repos y la API de Repos, ahora estamos bien equipados para cubrir todos los aspectos clave del control de versiones, las pruebas y las canalizaciones que sustentan los enfoques de MLOps. Databricks Repos permite clonar repositorios de git completos en Databricks y, con la ayuda de la API de Repos, podemos automatizar este proceso clonando primero un repositorio de git y luego seleccionando la rama que nos interesa. Los profesionales de ML ahora pueden usar una estructura de repositorio bien conocida de los IDE para estructurar su proyecto, confiando en notebooks o archivos .py para la implementación de módulos (con soporte para formatos de archivo arbitrarios en Repos planificado en la hoja de ruta). Por lo tanto, todo el proyecto está controlado por versiones con una herramienta de su elección (Github, Gitlab, Azure Repos, por nombrar algunos) y se integra muy bien con las canalizaciones comunes de CI/CD. La API de Databricks Repos nos permite actualizar un repo (proyecto Git seleccionado como repo en Databricks) a la última versión de una rama de git específica.
Los equipos pueden seguir el ciclo clásico de Git flow o GitHub flow durante el desarrollo. El repositorio Git completo se puede clonar con Databricks Repos. Los usuarios podrán usar y editar los notebooks, así como archivos Python planos u otros tipos de archivos de texto con soporte para archivos arbitrarios. Esto nos permite usar una estructura de proyecto clásica, importando módulos de archivos Python y combinándolos con notebooks:
- Desarrollar características individuales en una rama de características y probarlas usando pruebas unitarias (por ejemplo, notebooks implementados).
- Enviar cambios a la rama de características, donde la canalización de CI/CD ejecutará la prueba de integración.
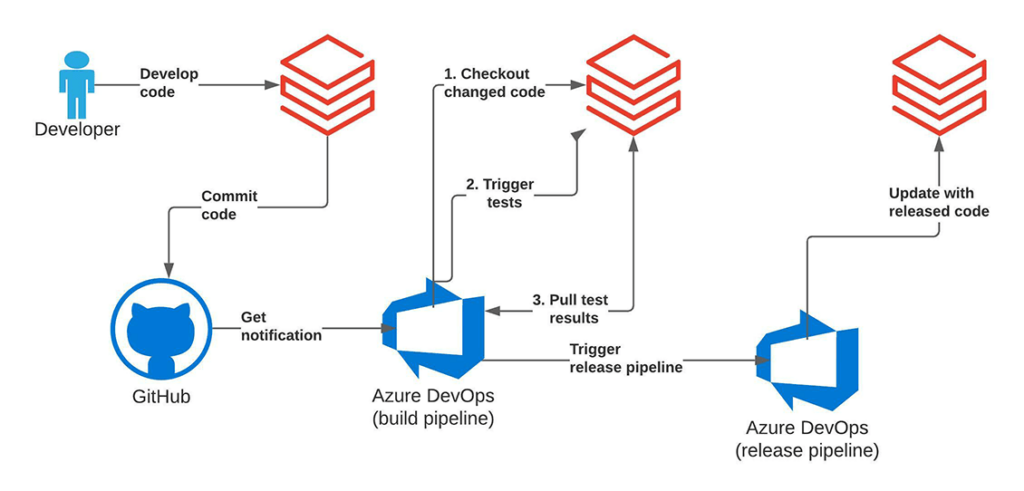
- Las canalizaciones de CI/CD en Azure DevOps pueden activar la API de Databricks Repos para actualizar este proyecto de prueba a la última versión.
- Las canalizaciones de CI/CD activan el trabajo de prueba de integración a través de la API de Jobs. Las pruebas de integración se pueden implementar como un notebook simple que primero ejecutará las canalizaciones que queremos probar con configuraciones de prueba. Esto se puede hacer simplemente ejecutando un notebook apropiado ejecutando los módulos correspondientes o activando el trabajo real usando la API de Jobs.
- Examinar los resultados para marcar toda la ejecución de la prueba como exitosa o fallida.
Examinemos ahora cómo podemos implementar el enfoque descrito anteriormente. Como flujo de trabajo ejemplar, nos centraremos en los datos provenientes de la competencia Lending Club de Kaggle. Similar a muchas instituciones financieras, nos gustaría comprender y predecir los datos de ingresos individuales, por ejemplo, para evaluar la puntuación de crédito de una solicitud. Para ello, analizamos varias características y atributos del solicitante, que van desde la ocupación actual, la propiedad de la vivienda, la educación hasta datos de ubicación, estado civil y edad. Esta es la información que un banco ha recopilado (por ejemplo, en solicitudes de crédito anteriores) y ahora se utiliza para entrenar un modelo de regresión.
Además, sabemos que nuestro negocio cambia dinámicamente y hay un gran volumen de nuevas observaciones a diario. Con la ingesta regular de nuevos datos, el reentrenamiento del modelo es crucial. Por lo tanto, el enfoque está en la automatización completa de los trabajos de reentrenamiento, así como de toda la canalización de despliegue continuo. Para garantizar resultados de alta calidad y un alto poder predictivo de un modelo recién entrenado, agregamos un paso de evaluación después de cada trabajo de entrenamiento. Aquí, el modelo de ML se puntúa en un conjunto de datos curado y se compara con la versión de producción actualmente desplegada. Por lo tanto, la promoción del modelo solo puede ocurrir si la nueva iteración tiene un alto poder predictivo.
A medida que un proyecto se desarrolla y se trabaja activamente, las pruebas totalmente automatizadas del nuevo código y la promoción a la siguiente etapa del ciclo de vida utilizan el marco de Azure DevOps para la evaluación unitaria/de integración en solicitudes de push/pull. Las pruebas se orquestan a través del marco de Azure DevOps y se ejecutan en la plataforma Databricks. Esto cubre la parte de CI del proceso, asegurando una alta cobertura de pruebas de nuestra base de código, minimizando la supervisión humana.
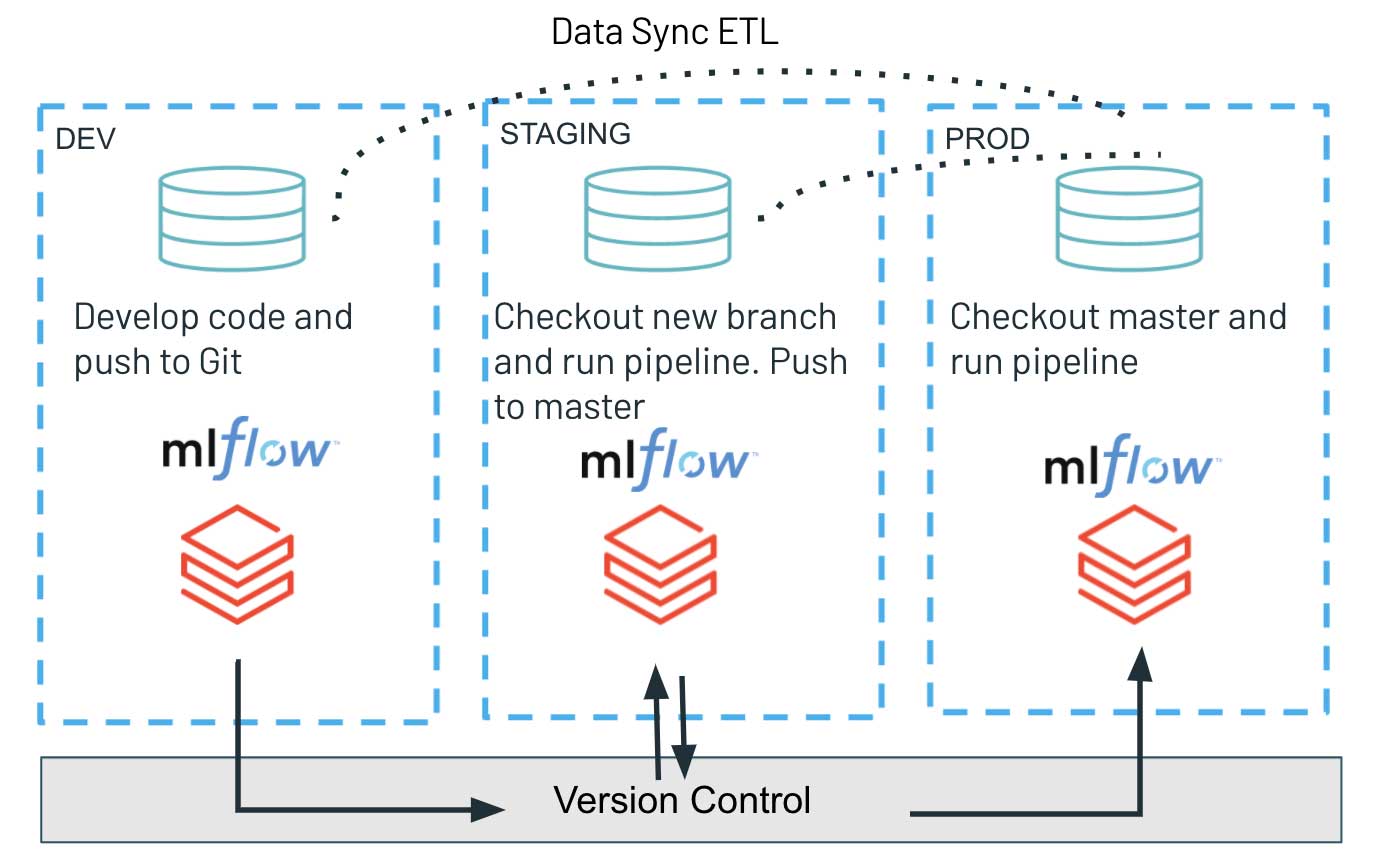
La parte de entrega continua se basa únicamente en la API de Repos, donde utilizamos la interfaz programática para seleccionar la última versión de nuestro código en la rama de Git y desplegar los scripts más recientes para ejecutar la carga de trabajo. Esto nos permite simplificar el proceso de despliegue de artefactos y promover fácilmente la versión de código probada desde los entornos de desarrollo a través de staging hasta producción. Dicha arquitectura garantiza el aislamiento completo de varios entornos y generalmente se prefiere en entornos de mayor seguridad. Las diferentes etapas: desarrollo, staging y producción comparten solo el sistema de control de versiones, minimizando la interferencia potencial con cargas de trabajo de producción de alta criticidad. Al mismo tiempo, el trabajo exploratorio y la innovación están desacoplados, ya que el entorno de desarrollo puede tener controles de acceso más relajados.
Implementar canalización de CI/CD usando Azure DevOps y Databricks
En el siguiente repositorio de código, implementamos el proyecto de ML con una canalización de CI/CD impulsada por Azure DevOps. En este proyecto, usamos notebooks para la preparación de datos y el entrenamiento de modelos.
Veamos cómo podemos probar estos notebooks en Databricks. Azure DevOps es un marco muy popular para flujos de trabajo completos de CI/CD disponibles en Azure. Para obtener más información, consulte la descripción general de las funcionalidades proporcionadas y las integraciones continuas con Databricks.
Estamos utilizando la canalización de Azure DevOps como un archivo YAML. La canalización trata los notebooks de Databricks como archivos Python simples, por lo que podemos ejecutarlos dentro de nuestra canalización de CI/CD. Hemos colocado un archivo YAML para nuestra canalización de CI/CD de Azure dentro de azure-pipelines.yml. La parte más interesante de este archivo es una llamada a la API de Databricks Repos para actualizar el estado del proyecto de CI/CD en Databricks y una llamada a la API de Databricks Jobs para activar la ejecución del trabajo de prueba de integración. Hemos desarrollado ambos elementos en el script/notebook deploy.py. Podemos llamarlo de la siguiente manera dentro de la canalización de Azure DevOps:
Las variables de entorno DATABRICKS_HOST y DATABRICKS_TOKEN son necesarias para que el paquete databricks_cli nos autentique en el espacio de trabajo de Databricks que estamos utilizando. Estas variables se pueden administrar a través de grupos de variables de Azure DevOps.
Examinemos el script deploy.py ahora. Dentro del script, estamos utilizando la API de databricks_cli para trabajar con la API de Databricks Jobs. Primero, tenemos que crear un cliente de API:
Después de eso, podemos crear un nuevo Repo temporal en Databricks para nuestro proyecto y extraer la última revisión de nuestro Repo recién creado:
A continuación, podemos iniciar la ejecución del trabajo de prueba de integración en Databricks:
Finalmente, esperamos a que el trabajo se complete y examinamos el resultado:
Trabajar con múltiples espacios de trabajo
El uso de la API de Databricks Repos para CD puede ser particularmente útil para equipos que buscan un aislamiento completo entre sus entornos de desarrollo/staging y producción. La nueva función permite a los equipos de datos, a través del código fuente en Databricks, implementar la base de código actualizada y los artefactos de una carga de trabajo a través de una interfaz de comandos simple en múltiples entornos. Poder extraer programáticamente la última base de código en el sistema de control de versiones garantiza un proceso de lanzamiento oportuno y sencillo.
Para las prácticas de MLOps, existen numerosas consideraciones importantes sobre la configuración arquitectónica adecuada entre varios entornos. En este estudio, nos centramos solo en el paradigma de aislamiento completo, que también cubriría múltiples instancias de MLflow asociadas con desarrollo/staging/producción. En ese sentido, los modelos entrenados en un entorno de desarrollo no pasarían a la siguiente etapa ya que los objetos serializados se cargan a través de un único Model Registry común. El único artefacto implementado es la nueva base de código del pipeline de entrenamiento que se lanza y ejecuta en el entorno de STAGING, lo que resulta en un nuevo modelo entrenado y registrado con MLflow.
Este principio de no compartir, junto con una estricta gestión de permisos en los entornos de producción/staging, pero patrones de acceso más relajados en desarrollo, permite un desarrollo de software robusto y de alta calidad. Al mismo tiempo, ofrece un mayor grado de libertad en la instancia de desarrollo, acelerando la innovación y la experimentación en el equipo de datos.
Resumen
En esta entrada de blog, presentamos un enfoque de extremo a extremo para pipelines de CI/CD en Databricks utilizando proyectos basados en notebooks. Este flujo de trabajo se basa en la funcionalidad de la API de Repos que no solo permite a los equipos de datos estructurar y controlar versiones de sus proyectos de una manera más práctica, sino que también simplifica enormemente la implementación y ejecución de las herramientas de CI/CD. Mostramos una arquitectura en la que todos los entornos operativos están completamente aislados, lo que garantiza un alto grado de seguridad para las cargas de trabajo de producción impulsadas por ML.
Los pipelines de CI/CD son impulsados por un framework de elección y se integran sin problemas con la Plataforma de Análisis Unificado de Databricks, activando la ejecución del código y el aprovisionamiento de infraestructura de extremo a extremo. La API de Repos simplifica radicalmente no solo la gestión de versiones, la estructuración del código y la parte de desarrollo del ciclo de vida de un proyecto, sino también la entrega continua, permitiendo implementar los artefactos de producción y el código entre entornos. Es una mejora importante que se suma a la eficiencia y escalabilidad generales de Databricks y mejora enormemente la experiencia del desarrollador de software.
El código discutido se puede encontrar aquí.
Referencias:
- https://www.databricks.com/blog/2021/06/23/need-for-data-centric-ml-platforms.html
- Continuous Delivery for Machine Learning, Martin Fowler, https://martinfowler.com/articles/cd4ml.html,
- Overview of MLOps, https://www.kdnuggets.com/2021/03/overview-mlops.html Introducing Azure DevOps, https://azure.microsoft.com/en-us/blog/introducing-azure-devops/
- Continuous integration and delivery on Azure Databricks using Azure DevOps, https://docs.microsoft.com/en-us/azure/databricks/dev-tools/ci-cd/ci-cd-azure-devops
- Lending club Kaggle data set https://www.kaggle.com/wordsforthewise/lending-club
- Repos for Git integration https://docs.databricks.com/repos.html
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.