¿Qué es MLOps?
Prácticas y herramientas para implementar, monitorear y gobernar modelos de ML en producción, conectando desarrollo y operaciones para lograr sistemas de ML confiables y reproducibles.
- Cubre todo el ciclo de vida del aprendizaje automático, incluyendo el seguimiento de experimentos, el control de versiones de modelos, el almacenamiento de características, las pruebas automatizadas, las canalizaciones de CI/CD, la contenedorización y el registro de modelos para flujos de trabajo reproducibles de desarrollo e implementación.
- Implementa sistemas de monitorización que rastrean las métricas de rendimiento del modelo, la desviación de datos, la latencia de predicción, la utilización de recursos y los KPI empresariales, con alertas automatizadas y activadores de reentrenamiento que mantienen la calidad del modelo de producción.
- Aborda los requisitos de gobernanza mediante registros de auditoría, controles de acceso, seguimiento del linaje de modelos, herramientas de explicabilidad y documentación de cumplimiento normativo, lo que permite prácticas de IA responsables y el cumplimiento normativo.
¿Qué es MLOps?
MLOps significa Operaciones de aprendizaje automático. MLOps es una función fundamental de la ingeniería de Machine Learning, enfocada en agilizar el proceso de llevar los modelos de machine learning a producción y, luego, mantenerlos y monitorearlos. MLOps es una función colaborativa, a menudo compuesta por científicos de datos, ingenieros de DevOps y TI.
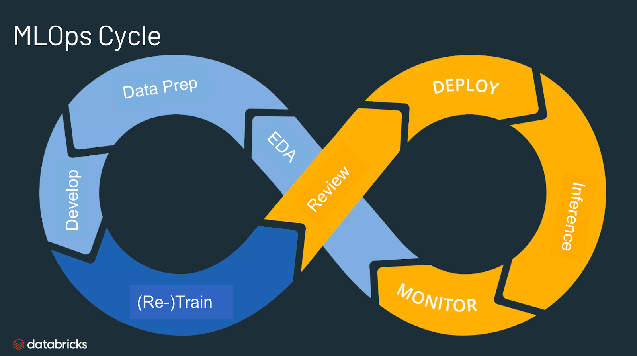
¿Para qué sirve MLOps?
MLOps es un enfoque útil para la creación y la calidad de las soluciones de IA y aprendizaje automático. Al adoptar un enfoque de MLOps, los científicos de datos y los ingenieros de machine learning pueden colaborar y aumentar el ritmo de desarrollo y producción de modelos mediante la implementación de prácticas de integración y despliegue continuos (CI/CD) con un monitoreo, validación y gobernanza adecuados de los modelos de ML.
¿Por qué necesitamos LLMOps?
Poner en producción el aprendizaje automático es difícil. El ciclo de vida del machine learning consta de muchos componentes complejos, como la ingesta de datos, la preparación de datos, el entrenamiento de modelos, el ajuste de modelos, la implementación de modelos, el monitoreo de modelos, la explicabilidad y mucho más. También requiere colaboración y entregas entre equipos, desde ingeniería de datos hasta ciencia de datos e ingeniería de ML. Naturalmente, se requiere un rigor operativo estricto para mantener todos estos procesos sincronizados y funcionando en conjunto. MLOps abarca la experimentación, la iteración y la mejora continua del ciclo de vida del machine learning.
¿Cuáles son los beneficios de LLMOps?
Los principales beneficios de LLMOps son la eficiencia, la escalabilidad y la reducción de riesgos. Eficiencia: MLOps permite a los equipos de datos lograr un desarrollo de modelos más rápido, entregar modelos de ML de mayor calidad y lograr una implementación y producción más rápidas. Escalabilidad: LLMOps también permite una vasta escalabilidad y gestión donde miles de modelos pueden ser supervisados, controlados, administrados y monitoreados para integración continua, entrega continua y despliegue continuo. Específicamente, LLMOps proporciona reproducibilidad de los pipelines de LLM, lo que permite una colaboración más estrechamente acoplada entre equipos de datos, y reduce conflictos con DevOps y TI, y acelera la velocidad de lanzamiento. Reducción de riesgos: Los modelos de machine learning suelen requerir un escrutinio regulatorio y una comprobación de la deriva. MLOps permite una mayor transparencia y una respuesta más rápida a dichas solicitudes, y garantiza un mayor cumplimiento de las políticas de una organización o del sector.
¿Cuáles son los componentes de LLMOps?
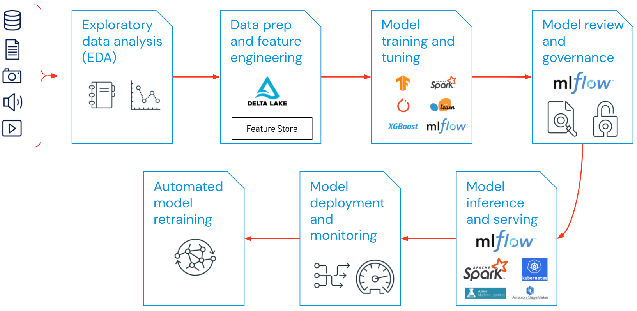
El alcance de LLMOps en proyectos de aprendizaje automático puede ser tan enfocado o amplio como lo requiera el proyecto. En ciertos casos, LLMOps puede abarcar todo, desde la preparación de datos hasta la producción de canalizaciones, mientras que otros proyectos pueden requerir únicamente la implementación del proceso de despliegue del modelo. La mayoría de las empresas aplican los principios de LLMOps en los siguientes ámbitos:
- Análisis exploratorio de datos (EDA)
- Preparación de datos e ingeniería de características
- Entrenamiento y ajuste del modelo
- Revisión y gobernanza de modelos
- Inferencia y servicio de modelos
- Monitoreo de modelos
- Reentrenamiento automatizado de modelos
La guía de IA agéntica para la empresa

¿Cuáles son las mejores prácticas para LLMOps?
Las mejores prácticas para LLMOps pueden delinearse por la etapa en la que se están aplicando los principios de LLMOps.
- Análisis exploratorio de datos (EDA): explora, comparte y prepara iterativamente los datos para el ciclo de vida del aprendizaje automático, al crear conjuntos de datos, tablas y visualizaciones reproducibles, editables y compartibles.
- Preparación de datos e ingeniería de atributos- Transforma, agrega y elimina los duplicados de los datos de forma iterativa para crear atributos refinados. Lo más importante es hacer que las características sean visibles y se puedan compartir entre los equipos de datos, aprovechando un feature store.
- Entrenamiento y ajuste de modelos: usa bibliotecas populares de código abierto como scikit-learn e hyperopt para entrenar y mejorar el rendimiento del modelo. Como una alternativa más simple, use herramientas de aprendizaje automático automatizado como AutoML para realizar ejecuciones de prueba automáticamente y crear código revisable e implementable.
- Revisión y gobernanza de modelos- Haga un seguimiento del linaje y las versiones de los modelos, y gestione sus artefactos y transiciones a lo largo de su ciclo de vida. Descubre, comparte y colabora en modelos de ML con la ayuda de una plataforma MLOps de código abierto como MLflow.
- Inferencia y servicio de modelos: administre la frecuencia de actualización del modelo, los tiempos de solicitud de inferencia y especificaciones de producción similares en pruebas y control de calidad. Utiliza herramientas de CI/CD como repositorios y orquestadores (tomando prestados los principios de DevOps) para automatizar el pipeline de preproducción.
- Implementación y monitoreo de modelos: automatiza los permisos y la creación de clústeres para pasar a producción los modelos registrados. Habilite los endpoints del modelo de la API de REST.
- Reentrenamiento automatizado de modelos: cree alertas y automatizaciones para tomar medidas correctivas en caso de deriva del modelo debido a diferencias entre los datos de entrenamiento y los de inferencia.
¿Cuál es la diferencia entre MLOps y DevOps?
MLOps es un conjunto de prácticas de ingeniería específicas para los proyectos de aprendizaje automático que se basan en los principios de DevOps de la ingeniería de software, que cuentan con una mayor adopción. Mientras que DevOps aporta un enfoque rápido y continuamente iterativo para la entrega de aplicaciones, MLOps adopta los mismos principios para llevar los modelos de machine learning a producción. En ambos casos, el resultado es una mayor calidad del software, parches y lanzamientos más rápidos y una mayor satisfacción del cliente.
¿El entrenamiento de modelos de lenguaje grandes (LLMOps) difiere del MLOps tradicional?
Si bien muchos de los conceptos de MLOps se siguen aplicando, hay otras consideraciones al entrenar modelos de lenguaje grandes como Dolly. Repasemos algunos de los puntos clave en los que el entrenamiento de los LLM podría diferir del enfoque tradicional de MLOps:
- Recursos de cómputo: el entrenamiento y el ajuste preciso de modelos de lenguaje grande generalmente implica realizar órdenes de magnitud más cálculos en grandes conjuntos de datos. Para acelerar este proceso, se usa hardware especializado, como GPU, que permite realizar operaciones paralelas con datos mucho más rápido. Tener acceso a estos recursos de cómputo especializados se vuelve esencial tanto para el entrenamiento como para el despliegue de modelos de lenguaje grande. El costo de la inferencia también puede hacer que las técnicas de compresión y destilación de modelos sean importantes.
- Aprendizaje por transferencia: a diferencia de muchos modelos tradicionales de ML que se crean o entrenan desde cero, muchos modelos de lenguaje grande parten de un modelo básico y se ajustan con nuevos datos para mejorar el rendimiento en un dominio más específico. El ajuste preciso permite un rendimiento de última generación para aplicaciones específicas empleando menos datos y menos recursos de cálculo.
- Retroalimentación humana: Una de las principales mejoras en el entrenamiento de modelos de lenguaje grandes se ha logrado gracias al aprendizaje por refuerzo a partir de la retroalimentación humana (RLHF). De forma más general, dado que las tareas de los LLM suelen ser muy abiertas, la retroalimentación humana de los usuarios finales de tu aplicación suele ser fundamental para evaluar el rendimiento de los LLM. La integración de este ciclo de retroalimentación en tus pipelines de LLMOps suele aumentar el rendimiento de tu modelo grande de lenguaje entrenado.
- Ajuste de hiperparámetros: en el ML clásico, el ajuste de hiperparámetros a menudo se centra en mejorar la precisión u otras métricas. Para los LLM, el ajuste también es importante para reducir los costos y los requisitos de potencia de cómputo del entrenamiento y la inferencia. Por ejemplo, ajustar el tamaño de los lotes y las tasas de aprendizaje puede cambiar significativamente la velocidad y el costo del entrenamiento. Así, tanto los modelos clásicos de ML como los LLM se benefician del seguimiento y la optimización del proceso de ajuste, pero con diferentes énfasis.
- Métricas de rendimiento: los modelos tradicionales de ML tienen métricas de rendimiento muy claramente definidas, tales como la exactitud, el AUC, el puntaje F1, etc. Estas métricas son bastante sencillas de calcular. Sin embargo, cuando se trata de evaluar LLM (modelos de lenguaje grande), se aplica un conjunto completamente diferente de métricas y puntuaciones estándar, como Bilingual Evaluation Understudy (BLEU) y Recall-Oriented Understudy for Gisting Evaluation (ROUGE), que requieren una consideración adicional al implementarlas.
¿Qué es una plataforma de MLOps?
Una plataforma LLMOps proporciona a científicos de datos e ingenieros de software un entorno colaborativo que facilita la exploración iterativa de datos, capacidades de trabajo conjunto en tiempo real para el seguimiento de experimentos, la ingeniería de indicaciones y la gestión de modelos y pipelines, así como la transición, el despliegue y el monitoreo controlado de modelos para LLM. MLOps automatiza los aspectos operativos y de sincronización del ciclo de vida del machine learning.
Prueba Databricks, un entorno totalmente gestionado para MLflow, la plataforma de MLOps abierta líder en el mundo. https://www.databricks.com/try/databricks-free-ml
Recursos adicionales
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.